
提高数据科学效率的 8 个Python神库!
在进行数据科学时,可能会浪费大量时间编码并等待计算机运行某些东西。所以我选择了一些 Python 库,可以帮助你节省宝贵的时间。
1、Optuna
2、ITMO_FS
>>> from sklearn.linear_model import SGDClassifier
>>> from ITMO_FS.embedded import MOS
>>> X, y = make_classification(n_samples=300, n_features=10, random_state=0, n_informative=2)
>>> sel = MOS()
>>> trX = sel.fit_transform(X, y, smote=False)
>>> cl1 = SGDClassifier()
>>> cl1.fit(X, y)
>>> cl1.score(X, y)
0.9033333333333333
>>> cl2 = SGDClassifier()
>>> cl2.fit(trX, y)
>>> cl2.score(trX, y)
0.9433333333333334
3、shap-hypetune
4、PyCaret
# load dataset
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# init setup
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# compare models
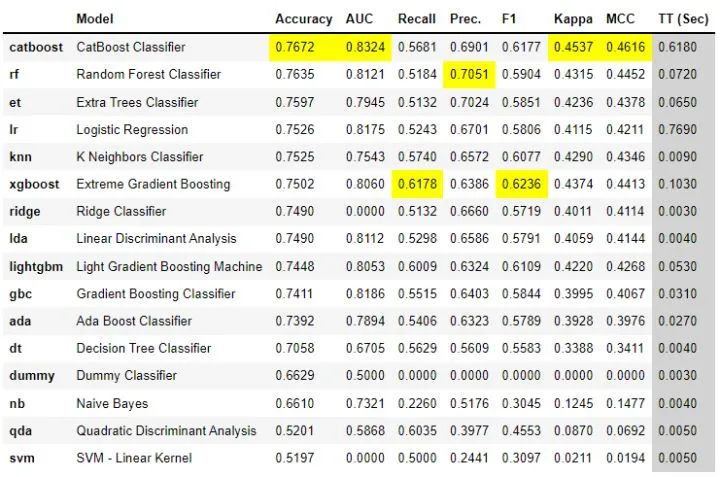
best = compare_models()
from pycaret.datasets import get_data
juice = get_data('juice')
from pycaret.classification import *
exp_name = setup(data = juice, target = 'Purchase')
lr = create_model('lr')
create_app(lr)
from pycaret.datasets import get_data
juice = get_data('juice')
from pycaret.classification import *
exp_name = setup(data = juice, target = 'Purchase')
lr = create_model('lr')
create_api(lr, 'lr_api')
create_docker('lr_api')
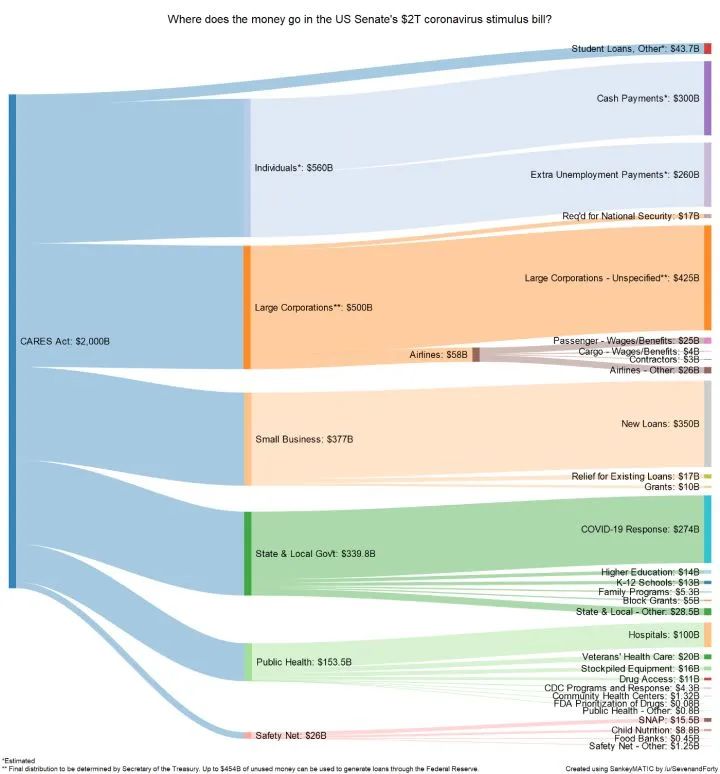
5、floWeaver
6、Gradio
7、Terality
8、torch-handle
from collections import OrderedDict
import torch
from torchhandle.workflow import BaseConpython
class Net(torch.nn.Module):
def __init__(self, ):
super().__init__()
self.layer = torch.nn.Sequential(OrderedDict([
('l1', torch.nn.Linear(10, 20)),
('a1', torch.nn.ReLU()),
('l2', torch.nn.Linear(20, 10)),
('a2', torch.nn.ReLU()),
('l3', torch.nn.Linear(10, 1))
]))
def forward(self, x):
x = self.layer(x)
return x
num_samples, num_features = int(1e4), int(1e1)
X, Y = torch.rand(num_samples, num_features), torch.rand(num_samples)
dataset = torch.utils.data.TensorDataset(X, Y)
trn_loader = torch.utils.data.DataLoader(dataset, batch_size=64, num_workers=0, shuffle=True)
loaders = {"train": trn_loader, "valid": trn_loader}
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = {"fn": Net}
criterion = {"fn": torch.nn.MSELoss}
optimizer = {"fn": torch.optim.Adam,
"args": {"lr": 0.1},
"params": {"layer.l1.weight": {"lr": 0.01},
"layer.l1.bias": {"lr": 0.02}}
}
scheduler = {"fn": torch.optim.lr_scheduler.StepLR,
"args": {"step_size": 2, "gamma": 0.9}
}
c = BaseConpython(model=model,
criterion=criterion,
optimizer=optimizer,
scheduler=scheduler,
conpython_tag="ex01")
train = c.make_train_session(device, dataloader=loaders)
train.train(epochs=10)
加入知识星球【我们谈论数据科学】
500+小伙伴一起学习!
· 推荐阅读 ·
评论