
Transformer的中年危机
↑ 点击蓝字 关注极市平台

作者丨rumor
来源丨李rumor
编辑丨极市平台
极市导读
CV圈已经杀疯了的MLP,各位大佬接连发文,transformer被接连质疑,transformer老哥也迎来了它的中年危机。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
卷友们好,我是rumor。最近Transformer被各种「质疑」,上周CV圈已经杀疯了,多个大佬接连发文,把早已过时的MLP又摆了出来:
5月4日,谷歌挂出《MLP-Mixer An all-MLP Architecture for Vision》
5月5日,清华图形学实验室挂出《Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks》
5月5日,清华软院挂出《RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition》
5月6日,牛津挂出《Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet》
好家伙,题目一个比一个扎心。

然而CV圈扎完了,娘家的NLPer也不甘示弱,就在昨天我刷Arxiv的时候,一篇谷歌的文章映入眼帘:

大佬们指出,虽然Transformer老哥的效果确实好,但这个效果到底是模型结构带来的、还是预训练带来的呢? 毕竟之前也没人这么暴力地训过对不对。那既然没人训过,这不idea就来了嘛接下来我脑补了一下模型选择的问题,经典的就那么几个:
MLP:好!但谷歌18年的USE模型已经证明了MLP没Transformer效果好,毕竟NLP还是需要序列信息的
LSTM:不错!用这个把大模型训出来,今年的kpi就算了,明年的可以冲刺一下
CNN:这个好!速度又快又轻便,根据经验来说在简单任务上表现也不差,稳得一批
结果一训真的是,瞬间ACL+1:
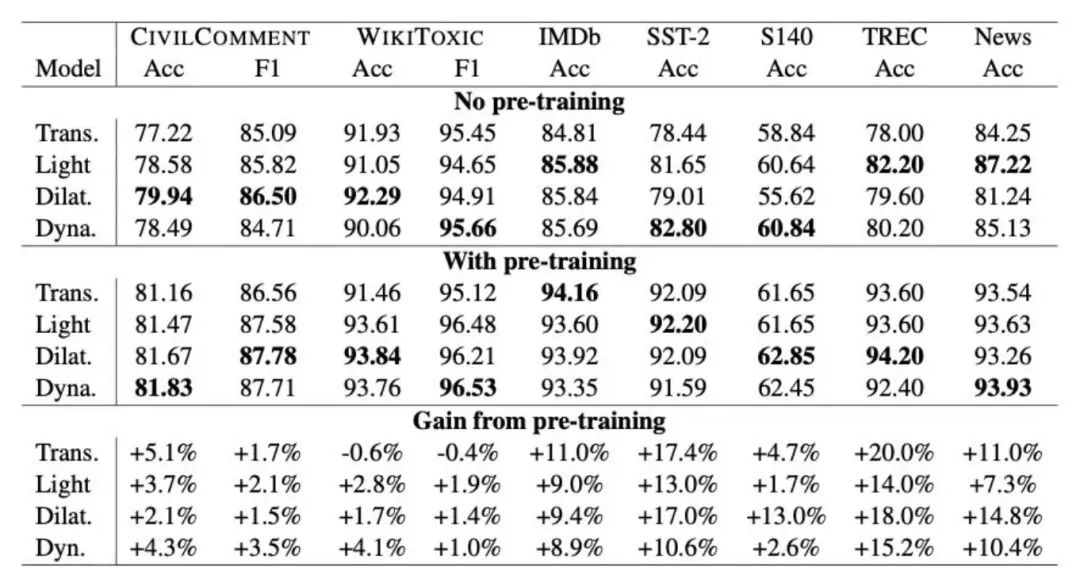
上图中 Lightweight CNN、Dilated CNN、Dynamic CNN 分别是不同的变种,可以得出以下结论:
不管有没有预训练,CNN的一些变种在NLP分类任务上都有比肩Transformer的效果
不只是Transformer,预训练对于CNN网络也是有提升的,在1%-18%之间
Dilated CNN、Dynamic CNN 这两个变种的表现更好
结构、预训练对于最终表现都有影响,可能不预训练的时候A>B,预训练之后A<B
不过,表中数据展示的都是文本分类,虽然附加的一个生成式语义分析上表现也不错,但大佬们也十分清楚CNN在其他更难的任务上表现有限。CNN在设计上没考虑句子间的交互,只抽取了局部特征。比如在句子pair拼接的分类任务上(MultiNLI、SQuAd),就比Transformer甩掉了10-20个点。有趣的是作者在给CNN加了一层cross-attention之后效果就上去了,在MultiNLI把差距缩小到了1个点。同时他们也指出,在双塔式的分类任务上CNN应该有更好的表现(就像USE模型用MLP也能达到不错的效果)。所以,文章读到这里,发现Transformer还是稳坐NLP第一把交椅。这也是它的 🐂 🍺 之处,无论别人怎么搞,都没法在general层面打过它。前段时间谷歌还有篇文章分析了Transformer的各种变种,发现大部分都只是在个别任务有所提升(摊手)。但在做实际落地任务时,还是会有各种速度上的限制,这篇文章就是告诉我们在任务简单、数据量充足、速度受限的情况下可以用CNN及变种来解决问题。TextCNN is all you need。最后再说几个我疑惑的点,欢迎留言讨论:
文章用的都是CNN变种,为什么没尝试最经典的CNN呢?会不会是表现太差了,不能支持结论
文章的预训练模型是参考T5的结构,为什么不用更普遍的BERT结构?还提到T5是「current state-of-the-art」,那20年下的GPT3去哪儿了?难道是写的时间太早?为什么现在才发?
这些问题都不得而知了,所以短期内我还是继续无脑精调BERT吧,做个懒人。
如果觉得有用,就请分享到朋友圈吧!
△点击卡片关注极市平台,获取最新CV干货
公众号后台回复“广东CVPR”获取CSIG-广东省CVPR 2021论文学术报告会回放
极市干货
深度学习环境搭建:个人深度学习工作站配置指南|深度学习主机配置推荐
实操教程:用OpenCV的DNN模块部署YOLOv5目标检测|TensorRT的FP16模型转换教程
算法技巧(trick):17种提高PyTorch“炼丹”速度方法|PyTorch Trick集锦|深度学习调参tricks总结
最新CV竞赛:2021 高通人工智能应用创新大赛|CVPR 2021 | Short-video Face Parsing Challenge|3D人体目标检测与行为分析竞赛开赛,奖池7万+,数据集达16671张!

# CV技术社群邀请函 #
△长按添加极市小助手
添加极市小助手微信(ID : cvmart2)
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
觉得有用麻烦给个在看啦~
