
用 PaddleNLP,快速打造一款像万方数据一样的「论文检索」神器!
业务背景
技术选型和项目实践
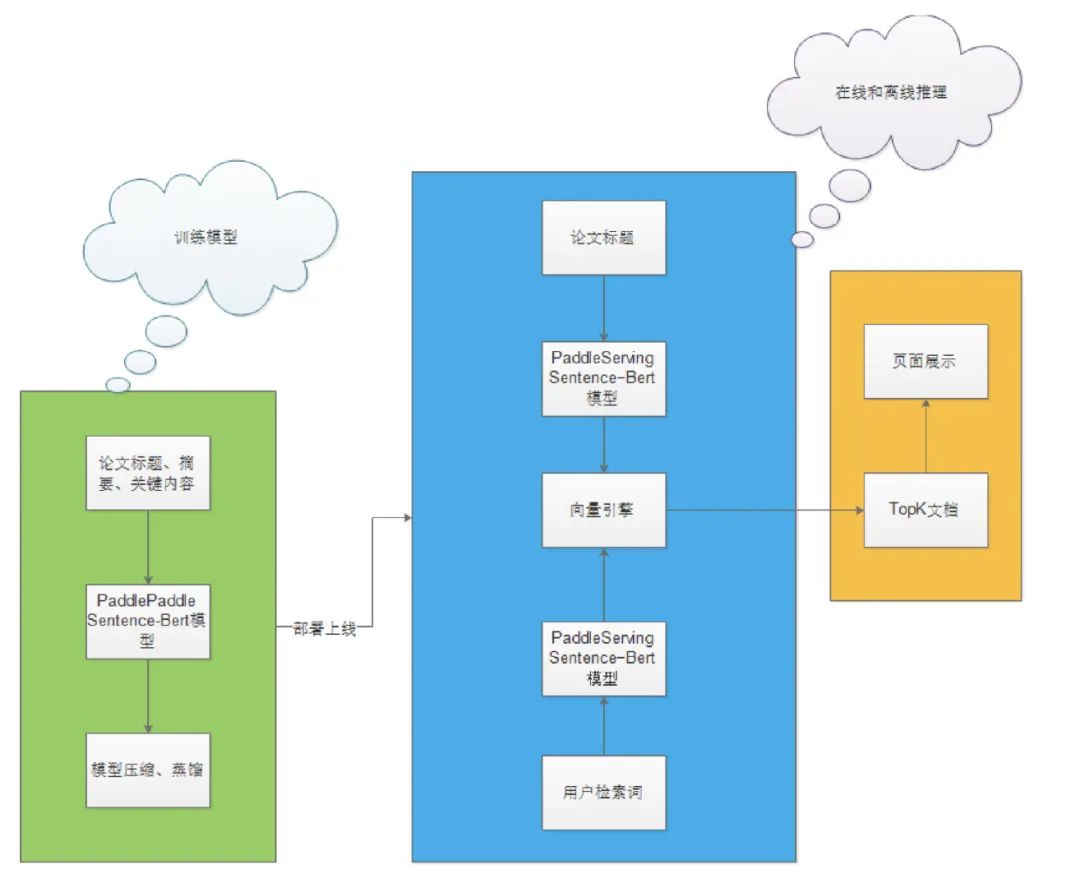 技术方案整体架构图
技术方案整体架构图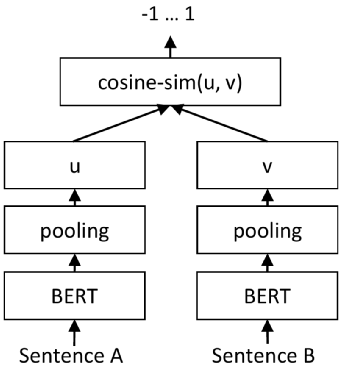
延伸 - 检验场景整体方案
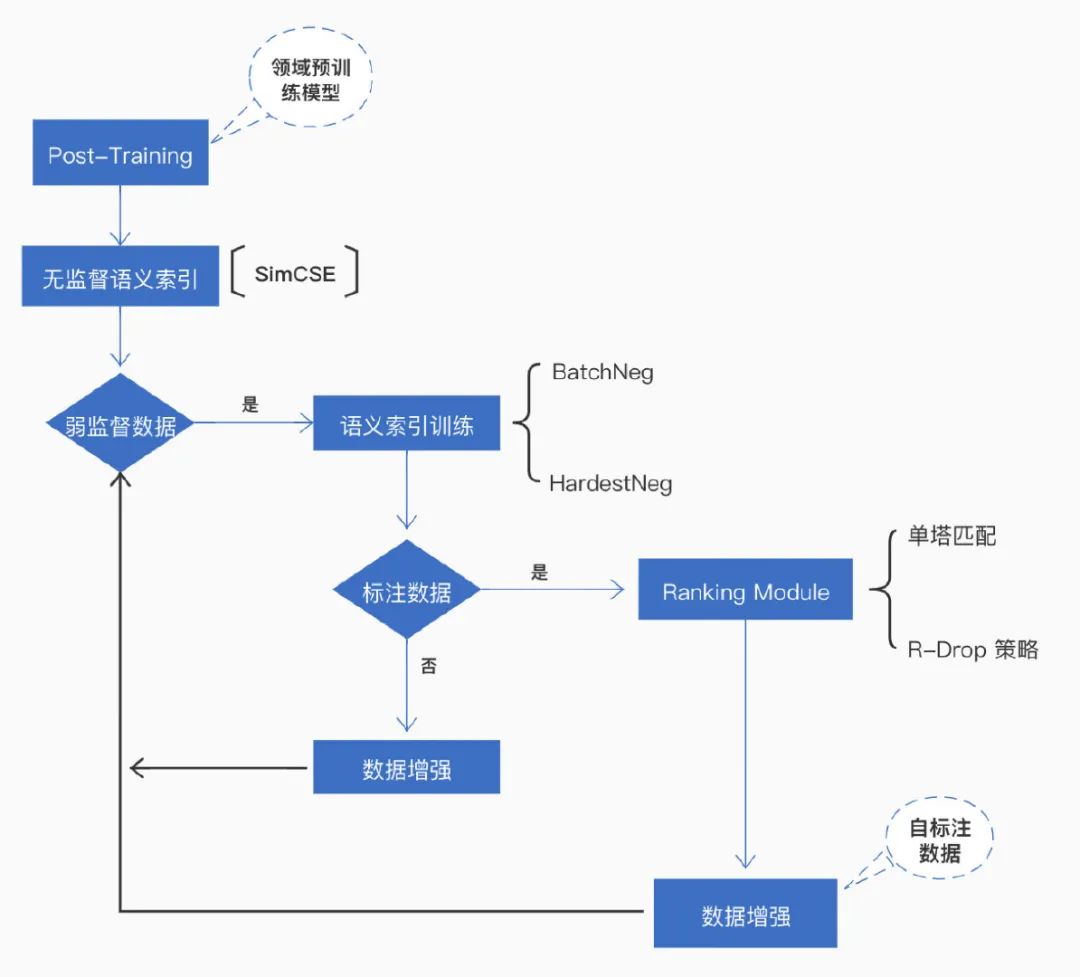
领域预训练是在通用预训练模型基础上,在领域数据上继续预训练,让预训练模型学习更多的领域知识。
语义匹配模块针对存在高质量监督数据的场景,给出了检索系统中排序模型方案。此外,针对高质量标注数据获取成本高,数据量少的问题,语义匹配模块还内置了 R-Drop 数据增强策略,进一步提升小数据量场景下排序模型效果,从而帮助检索系统达到更优的效果。
语义索引模块针对无监督和有监督数据场景,分别给出了无监督语义索引 (SimCSE) 和监督语义索引的方案,即使没有监督数据,也能利用无监督语义索引方案提升检索系统的召回效果。
直播预告
评论