数学模型告诉你:网络社区和“网红们”是怎样形成的?
共
3921字,需浏览
8分钟
·
2022-01-14 02:47
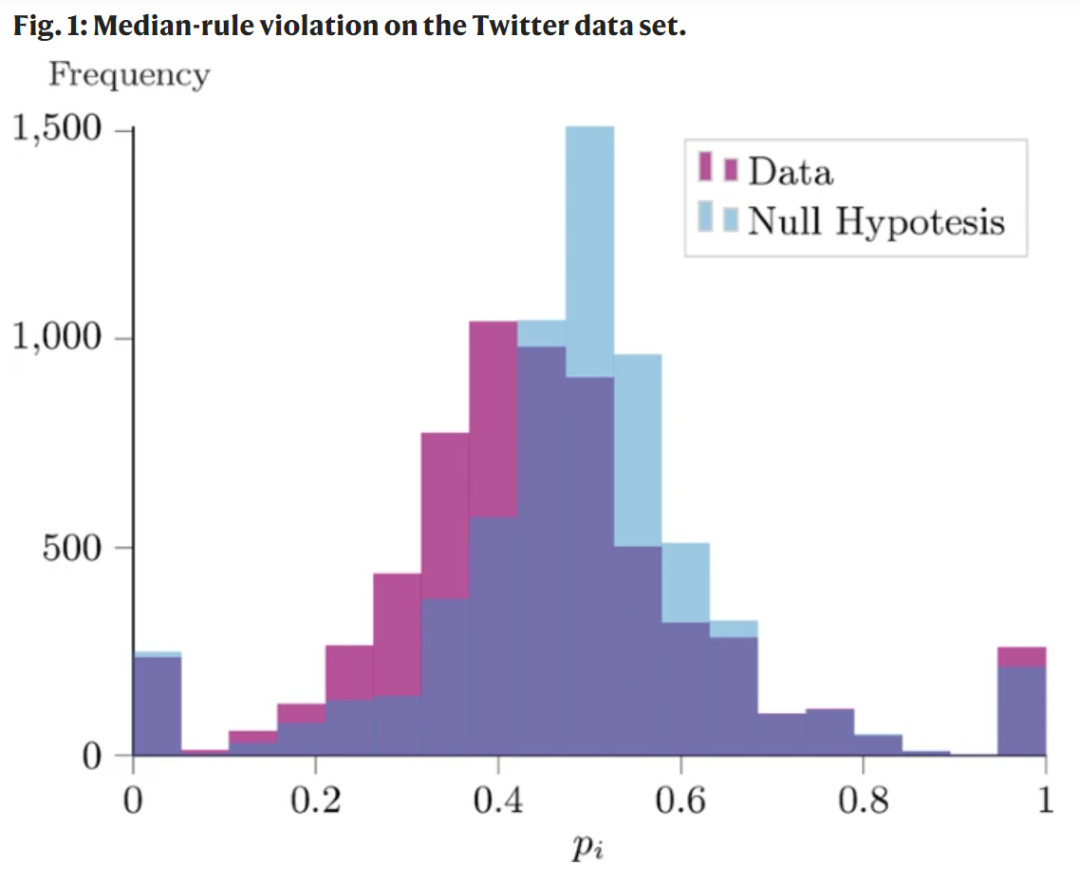
随着研究的快速发展,如今在线社交网络也在演变出了新的形式。与 21 世纪头十年蓬勃发展的 Facebook 和 LinkedIn 这些平台相比,今天最流行的平台,如 Twitter、Instagram 或抖音、快手,明显呈现出了一些不同的特点。最显著的区别之一是,这些新的在线社交平台都是定向网络,不需要用户相互认识或有关联,它们都是基于用户生成内容(User Generated Content ,UGC)。2020 年,每天就有 5 亿推文以及 8000 万 Instagram 图片发出。由于这些平台使用了标签,并整合了搜索引擎,这些社交平台鼓励用户根据自己的兴趣来探索平台的内容。因此,用户倾向于关注现实生活中的陌生人,并创建基于兴趣的社区。鉴于基于 UGC 的在线社交平台对公众意见和经济行为的潜在深远影响,以及其具有高度影响力的节点的传播潜力,我们十分有必要理解 UGC 是如何与“网红”的出现联系起来的,以及理解“网红”产生的网络的属性。最近,研究者们首次提出了一种用于定向网络形成的数学模型。这篇发表于 Nature Communication 的论文题目为 A meritocraticnetwork formation model for the rise of social media influencers。他们从理论和数值上分析了社交网络在不同的相遇概率下的平衡特性:在具有普遍的现实网络特性时,如标度律或小世界效应,该模型预测了网络预期度在质量排名方面遵循 Zipf 定律。值得注意的是,与基于优先相遇模拟的推荐系统相比,该模型具有鲁棒性。这一理论结果通过从 Twitch(在线游戏平台)收集的大量数据得到了验证。直观地说,高质量的作品更有可能吸引用户,因为它具有更高的情感价值。因此,这些平台的网络形成过程取决于一个基本要素,即内容的质量。然而迄今为止,除了用户的相遇概率与个体的适应度属性成比例的适应度模型外,对网络形成研究的大量多学科兴趣,只关注线下社交网络(或模仿它们的在线社交网络,如 Facebook)中的拓扑和社会经济方面,而忽视了内容质量的影响。例如,社会学中的随机面向角色模型和经济学中的战略网络形成模型。假设角色根据基于社会学元素的功利原则来决定互惠或网络闭合关系。这些模型通常会走向以双边社会联系和高传递性为特征的网络。然而,在 Instagram 上,只有 14% 的关系是互惠的,平均聚类系数小于 10%(相比之下,在 Facebook 上的互惠和聚类系数分别为 100% 和 30%)。在随机图形模型中,由 Barábasi 和 Albert 提出的优先推荐模型得到了广泛的认可。虽然这种机制导致了在许多现实世界网络中观察到的无尺度效应,但这种“粉丝越多的人越能吸引其他人的关注”的理论,并不能证明 Instagram 网红的崛起是合理的。定向的、基于用户内容的社交网络的盛行,以及适当的数学模型的缺乏,启发研究人员从一个前所未有的角度来思考它们的形成过程。在论文中,研究人员提出了一个简单但可预测的网络形成机制,该机制结合了功利主义原则和内容质量。他们假设用户有共同的兴趣,并将其与定义其内容质量的属性联系起来。为了定义一个基于内容的网络的形成过程,他们收集了一个关于复杂网络科学家的纵向 Twitter 数据集。与其他数据集相比,其优势之一是,大多数复杂网络科学家在 Twitter 上都很活跃,因为他们一直在研究社交网络的影响。此外,最受欢迎的节点很容易与该领域的知名研究人员联系在一起。可以说,粉丝的数量可以被视为用户生成内容质量的一个代表。研究人员通过手动检查和标记度最高的节点来支持这一假设。通过分析连接的时间序列,研究发现,定向社交网络的形成过程源于个体对更高质量的内容的持续搜索。为了规范质量模型,研究人员考虑了 N≥2 个 agent 的未加权有向网络,这些 agent 的 UGC 围绕着一个特定的共同兴趣,例如一个特定的旅游目的地。研究人员用 aij∈{0,1} 表示从i到j的有向关系,其中 aij=1 意味着 i 关注了 j。然后,假设不存在自循环,每个 agent i 只能控制它的粉丝 aij,而不能控制她的粉丝 aji。与适应度模型中的方法类似,研究人员赋予每个参与者 i 一个属性 qi,它来自于一个概率分布,例如均匀分布、正态分布、指数分布,它描述了 i 内容的平均质量,例如在旅游目的地拍摄的一张照片。该模型预测是独立于这些质量的数字表示的,并不是主观和任意的。相反,在模型中,只有个体质量的排序才是重要的。因此,与适应度模型相反,底层概率分布的选择不影响以下任何结果。质量 qi 可以被看作是一个伯努利随机变量 qi 的期望,qi 描述了追随者喜欢 agent i 内容的概率。更高的 q 值与更好的 UGC 相关。相反,零值可以用来建模那些不产生任何 UGC 的用户。通过这种设置,该模型可以直接应用于平台,如 YouTube 或 Twitch,其中用户可以被划分为两个类别,即内容创造者和他们的粉丝(或观众)。然后,研究人员考虑一个从空网络开始的顺序动态过程,在每个时间步 t∈{1,2,…},每个参与者 i 从 {1,…,i−1,i+1,…,N} 的概率分布中随机选择另一个不同的参与者 j。在接下来的理论分析中考虑均匀分布。研究人员也在讨论中整合了均匀分布和基于度的优先相遇过程之间的数值比较。他们分析和研究了所提出的网络模型形成的动因,以及在不同的相遇概率函数下的网络在平衡状态下的性质。首先,研究人员发现用户外度分布具有类似于伽马分布的特征,期望等于网络大小的谐波数。此外,由此产生的网络具有现实社会网络的特性,如很小但依然存在的聚类系数,以及由于具有相似兴趣的网络代理的同质性,而且粉丝集合中存在显著重叠。另外,度内分布满足缩放特性,研究人员还发现了一个特定的模式:质量最高的节点拥有的粉丝数量期望是第二的两倍(是第三的三倍)。以此类推。这一经验规律已在许多系统中被验证,并被称为齐夫定律(Zipf’s law)。值得注意的是,这个结果与推荐系统(它增加了流行节点的可见性)的影响相比是稳定的。作者强调的是,尽管人们普遍认为齐夫定律在对象增长的系统中普遍存在,但它的起源的原则是一个开放的研究问题,论文的质量规则解释了一个直观的、精英管理的机制。最后,为了验证这一模型,研究人员从热门在线游戏平台 Twitch 收集了 3 组数据。与理论预测的成功比较表明,该模型虽然简单,但已经成功找到了几个现实网络的属性。为了验证基于质量的模型的统计结果,研究人员在 Twitch 上收集了三个数据集。
Twitch 是一个专注于视频流的在线社交媒体平台,在游戏玩家中非常受欢迎。Twitch 用户可以创建自己的专用频道来直播游戏。他们的质量内容可以根据特定游戏的类别进行浏览。因此,用户可以观看他人的流媒体内容,并最终成为粉丝。处理复杂的现实网络会带来几个问题。特别是,系统不仅在网络联系方面不断变化,而且随着新的节点(用户)加入和离开网络而不断变化。为了具体验证模型结果,研究人员首先需要确定一个共同兴趣的合适类别,第二需要重建对这个类别感兴趣的用户之间的社交网络。根据建模假设,系统对于用户集是封闭的,网络的形成过程是用户对某一特定主题感兴趣的结果。在 Twitch 的背景下,这要求用户对一款(且只有一款)特定游戏或主题的兴趣是固定的。为了最小化用户兴趣不稳定的可能性,研究人员将爬虫设置限制在以下三种类型的用户:象棋、扑克和艺术中的一种。此外,通过语言过滤数据,只保留绝大多数的英语用户。这样,就避免了多个重叠连贯数据集的可能性。研究人员使用兴趣指数来保留那些始终在选定的类别中进行流媒体的用户,并过滤掉那些可能因为在其他类别中进行流媒体而积累了大量用户的用户。根据这一标准的结果,研究人员决定排除与艺术类别相关的数据集。然后研究人员设置了两个基于国际象棋和扑克类别的 Twitch 数据。在 Twitch 上,并非所有用户都提供他们的 UGC,因此节点可以分为两类:主播以及观众。由于两个分区严重不平衡,该网络可以近似地认为是一个准二部网络,其中观众之间几乎没有联系,主播之间的联系很少(绝对数量上),而且大多数联系都是由观众直接指向主播的。结果显示,这种特定的网络结构,即类二部网络,与模型预测是一致的。总而言之,这项研究提出了一个描述社交网络形成的数学模型,在这个模型中,用户会根据他们的兴趣和内容质量决定是否关注某一个人。然后,在一个由 6,000 多名科学家组成的网络中,他们针对 Twitter 数据测试了这个模型。结果表明,用户的目标是提高他们接收到的内容质量,并会持续不断地发现最优质内容的提供者。论文团队发现,制作最高质量内容的用户,其粉丝数量往往是次优用户的两倍,而且这个差距是可以依此类推的。最后,作者使用 Twitch 的数据集验证了他们的模型。他们认为,该模型比以前的模型更真实地反映了流行度和网络结构的演变。这些发现为了解社交网络社区和 KOL 的形成机制提供了见解。
点赞
评论
收藏
分享

手机扫一扫分享
举报
点赞
评论
收藏
分享
手机扫一扫分享
举报


 下载APP
下载APP