
读书笔记之《网络是怎样连接的》
大家好呀,我是小菜~
本文主要分享
《网络是怎样连接的》如有需要,可以参考
如有帮助,不忘 点赞 ❥
微信公众号已开启,菜农曰,没关注的同学们记得关注哦!
今天带来的是 《网络是怎样连接的》 的读书笔记
(文中使用到的例子贴图均出于原书)
在正式进入分享之前,我们想看下这本树的目录架构
网络是怎样连接的

本书共 6 章,156482 个字,篇幅不多,内容较意思,是一本很好的网络基础入门书籍,穿插专业术语的解释和插图,对复杂的网络通信世界能有一定的了解
本书路线:

第一章:浏览器生成消息
1)生成 HTTP 请求
https://www.baidu.com中的 www 是 Web服务器上的一种命名,World Wide Web 不是一个协议的名字,而是 Web 的提出者最早开发的浏览器兼 HTML 编辑器的名称浏览器等网路应用程序实际上并不具备网络控制功能,而是委托操作系统来控制网路
什么是网址?网址准确来说称之为 URL,就是日常生活中以 Http: 开头的一串字符。
我们生活中常用的几种 URL:

虽然 URL 有各种不同的写法,但是开头部分的内容决定了后面部分的写法,也就是定义了某种协议的存在,这样子在使用的过程中并不会造成混乱。
1. 解析URL
当我们输入某一串 URL 时,浏览器需要对 URL 进行解析,然后生成发送给 Web 服务器的请求消息,当然这一步在我们使用的过程中是无感的,因为浏览器帮我们做好了这一切,我们只关心响应的结果。
解析的过程包括以下几步:
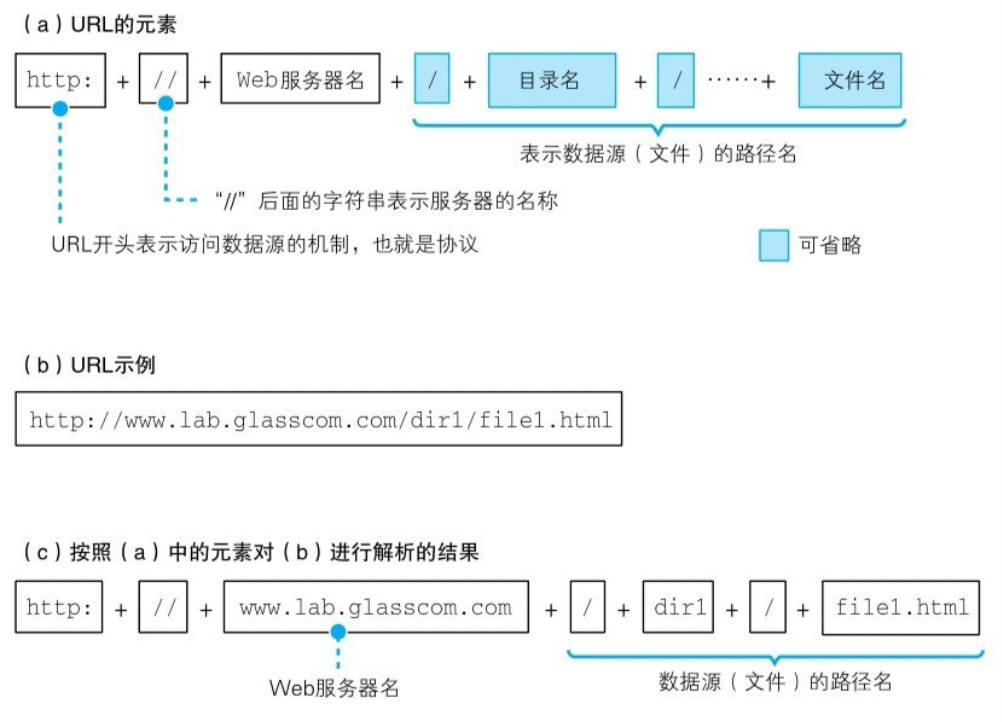
我们先识别出了 HTTP,这说明要访问 Web 服务器,然后我们可以继续往后面拆分,包含了服务器名称、目录名和文件名,到这一步我们就知道了原来用户要访问 dir1 目录下的 file1.html 文件
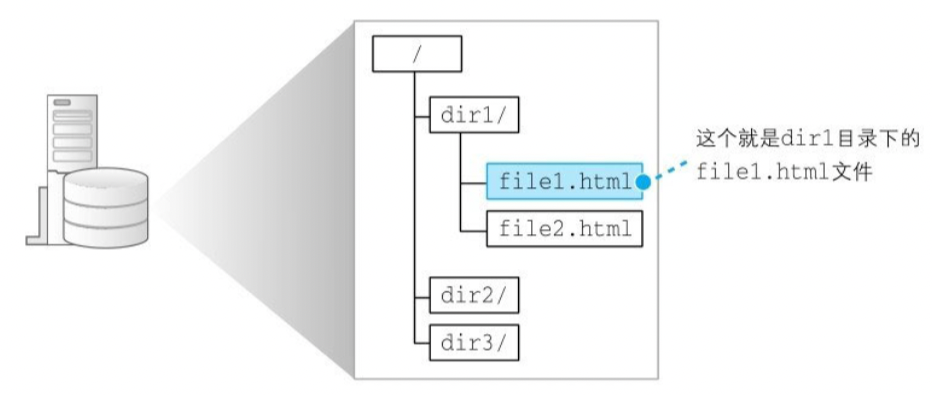
2. 省略文件名
上述我们要访问的 http://www.lab.glasscom.com/dir1/file1.html URL 中清晰的描述了我们访问的是 file1.html 文件,有时可能也会出现类似一些特殊的 URL
http://www.lab.glasscom.com/dir/,其中文件名被省略了,但这不代表我们访问不到文件了,一般来说这种情况会在服务器上事先设置好文件名省略的默认名称,比如index.html或default.html之类的http://www.lab.glasscom.com/,该 URL 中带上了/,表示访问的是根目录,在知道目录名的情况下,我们可以按照情况 1 的方式推测出要访问的文件名http://www.lab.glasscom.com,该 URL 连/都省略了,这种情况就代表访问根目录下事先设置好的默认文件(最早的时候这个文件称之为主页)http://www.lab.glasscom.com/dir,该 URL 末尾没有/,则表示如果 Web 服务器上存在名为 dir 的文件,则将 dir 以文件名的方式处理,如果存在名为 dir 的目录,则以目录名的方式处理
3. 处理的基本思路
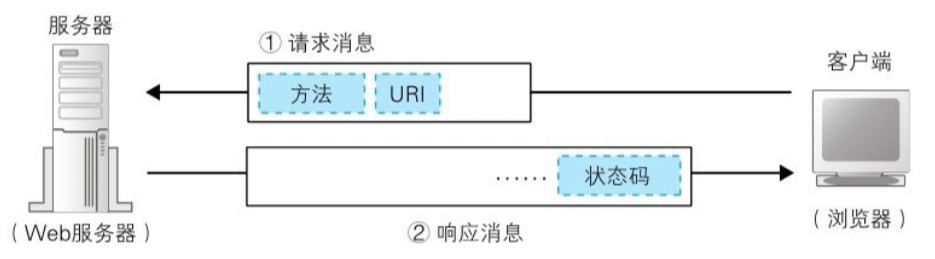
首先,客户端会向服务器发送请求消息(包含 对什么 和 做什么 两个部分)
对什么:指的是 URL 做什么:指的是方法
URL 不做过多的解释,就是发往服务器的那串请求地址,方法我们调接口的时候也不少见,通常有以下几种:
GET:通常用于获取信息。 POST:通常用于新增数据。 PUT:通常用于更新数据。 DELETE:通常用于删除数据。 HEAD:与 GET 基本相同。不过它只返回 HTTP 的消息头,并不返回数据的内容 TRACE:将服务器收到的请求行和头部(header)直接返回给客户端 OPTIONS:用于通知或查询通信选项
4. 响应处理
当请求的消息发出后,Web服务器会返回响应消息。在响应消息中,第一行的内容为 状态码 和 响应短语,用来表示请求的执行结果是成功还是出错。状态码和响应短语表示的内容一致,但用途不同。
状态码是一个数字,用来向程序告知执行的结果,响应短语是一段文字,同样使用来告知执行的结果
状态码概要:
1xx:告知请求的处理进度和情况 2xx:请求成功 3xx:表示要进一步的操作 4xx:客户端错误 5xx:服务端错误
2)向DNS服务器查询Web服务器的IP地址
客户端要向服务端发送请求之前还有一个工作需要完成,那就是查询网址中服务器域名对应的 IP 地址。
因为浏览器本身不具备将消息发送到网络中的功能,而是需要委托操作系统来完成。
但是委托操作系统来完成通信的条件就是需要提供通信对象的 IP 地址,而不是域名。
1. 什么是 IP 地址
1. TCP/IP 初知
了解什么是 IP 地址,我们就需要了解 TCP/IP。
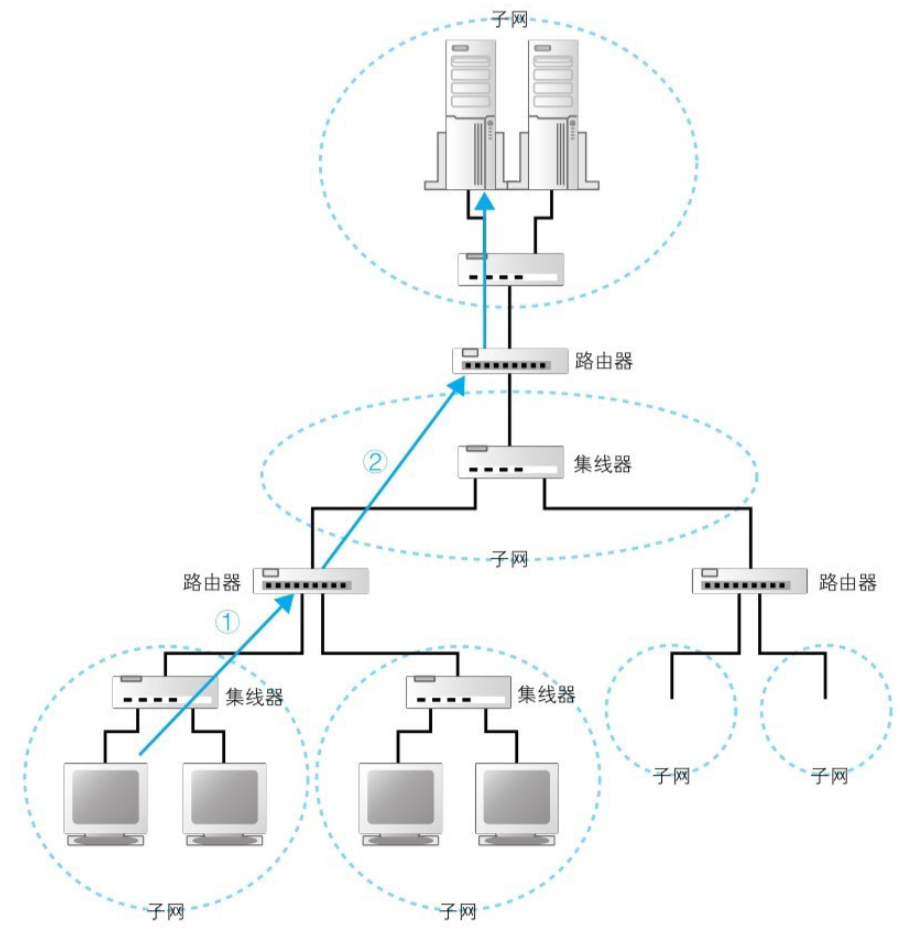
这是一个 TCP/IP 的结构图。TCP/IP 就是由一些小的子网(用集线器连接起来的几台计算器),通过路由器连接起来组成的一个大网络。
在网路中所有设备都会被分配一个地址(相当于我们现实中的xx号xx室),其中 号 是分配给整个子网的(网络号),而 室 是分配给子网中的计算机的(主机号),这就是网络中的地址,整体称之为 IP地址。
那么消息发送的过程就是:
发送者发出的消息首先经过子网中的集线器,然后转发到距离发送者最近的路由器上,路由器会根据消息的目的地判断下一个路由器的位置,然后将消息发送到下一个路由器,多次转发后就到了最终的目的地
2. IP 地址
IP 地址实际上是一串 32 比特的数字,按照 8 比特(1字节)为一组分成4组,分别用十进制表示然后用圆点 . 隔开。

IP 地址是由 网路号 和 主机号 组成的,但是通过这一串数字我们无法得知哪些是网路号,哪些是主机号,因此我们还需要 子网掩码 的帮助。
子网掩码:是一串与 IP 地址长度相同的 32 比特数字,左边一半是1,右边一半是0,其中子网掩码为 1 的部分表示网络号,为 0 的部分表示为主机号,子网掩码表示网络号与主机号之间的边界。
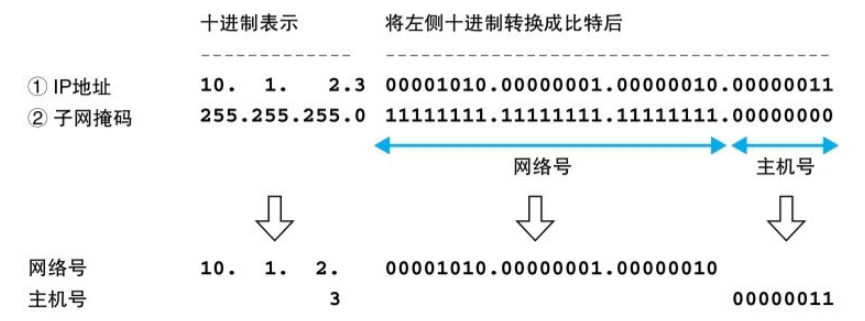
主机号部分的比特全部为 0 或全部为 1 表示两种特殊的含义:
全 0:表示整个子网 全 1:表示向子网上所有设备发送包,即 广播
2. 域名的出现
想要达到最终目的地,我们就需要知道目的地的 IP 地址。但 IP 地址是一串数字,我们每天打交道的网站实在是太多了,那么为了记忆简单,就出现了 域名
为了填补两者之间的障碍,就需要有一个机制能够通过名称来查询 IP 地址,或者通过 IP 地址来查询名称,这个机制就是 DNS
3. Socket 库
浏览器想要发送请求,需要委托操作系统,但是委托操作系统查询,我们需要告知操作系统目的地的IP地址。因此浏览器需要查询域名对应的 IP 地址再告知操作系统,但是浏览器又不具备发送请求的功能,这岂不是死循环了吗?
实际上负责 DNS 查询 IP 地址的操作称之为域名解析,因此负责解析这一操作就叫做解析器。
解析器实际上是一段程序,它包含在操作系统的 Socket 库中,它是一堆通用程序组件的集合,其中包含的程序组件可以让其他的应用程序调用操作系统的网路功能,而解析器就是这个苦衷的一种组件。
4. 解析器
当流程流转到解析器的时候,解析器会生成要发送给 DNS 服务器的查询消息,同样发送消息这个操作并不是由解析器自身来执行,而是要委托给操作系统内部的协议栈来执行(解析器本身也不具备网络收发的能力)
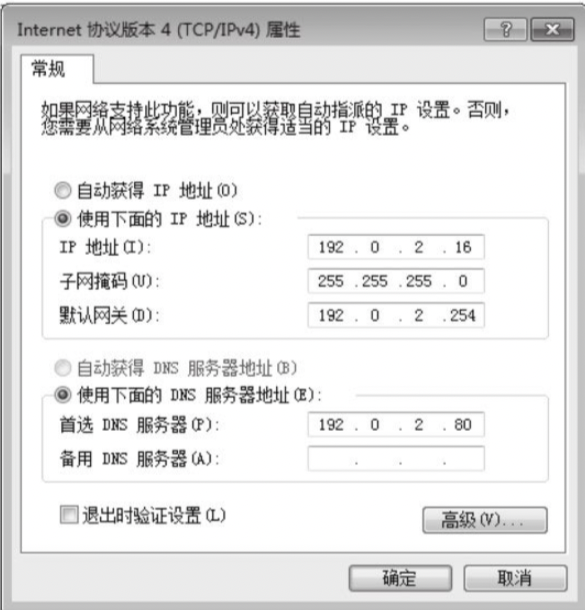
向 DNS 服务器发送消息时,我们也需要知道 DNS 服务器的 IP 地址,不过这个 IP 地址是已经实现设置好的,比如 windows 上的网络设置
3)全世界DNS服务器的大接力
1. 域名的查询
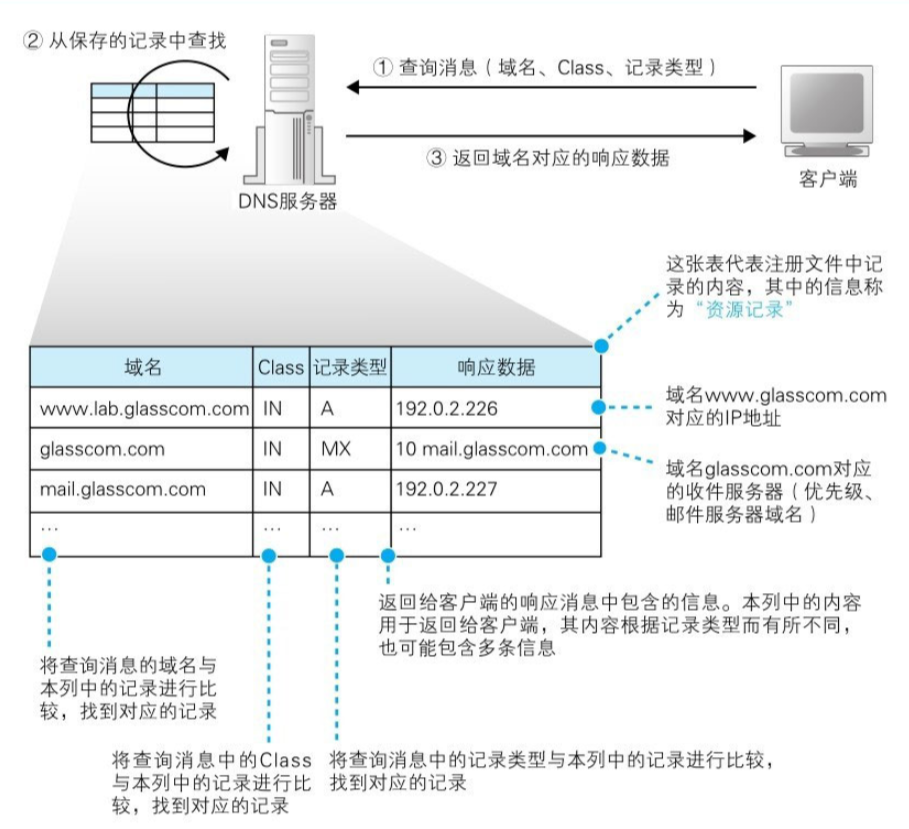
通常客户端想要向 DNS 查询通常包含以下 3 种消息:
域名 Class:用来识别网络的信息,永远是代表互联网的 IN 记录类型:表示域名对应哪种类型的记录。比如,当类型为 A 时,表示域名对应的 IP 地址,为 MX 时,表示对应的是邮件服务器,对于不同的记录类型,服务器向客户端返回的信息也会不同
2. 域名的层次
互联网上存在不计其数的服务器,将这些服务器的信息全部都保存在一台 DNS 服务器上是不可能的,因此就需要将信息分布保存在多台 DNS 服务器中,这些 DNS 相互接力配合,从而查找出要查询的信息。
比如 www.life.cbuc.com,在靠右的位置表示层级越高,这段域名的大致意思为 com 集团 cbuc 部门 life 组的 www。这种具有层次结构的域名信息会被注册到 DNS 服务器中,而每个域都是作为一个整体来处理,也就是不能将一个域拆开存放在多台 DNS 服务器中。
一个域是不可分割的,但我们可以在域的下面创建下级域(子域),然后再将它们分别分配给各个事业集团,比如 life.cbuc.com 可以创建两个子域:a1.life.cbuc.com 和 a2.life.cbuc.com
DNS 查询的结果有点类似树形结果。
负责管理下级域的 DNS 服务器的 IP 地址注册到它们上级 DNS 服务器中,然后上级 DNS 服务器的 IP 地址再注册到更上一级的 DNS 服务器中,以此类推。也就是说,负责管理 life.cbuc.com 这个域的 DNS 服务器的IP地址需要注册到 cbuc.com 域的DNS服务器中,而 cbuc.com 域的 DNS 服务器的 IP 地址又需要注册到 com 域的 DNS 服务器中,这样,就可以通过上级 DNS 服务器查询出下级 DNS 服务器的 IP 地址,也就可以向下级服务器发送查询请求了。
3. 根域的存在
经过上面的讲解,如果觉得 com、cn 这类就属于顶级域的话就错了。
实际上还有 根域 的存在,一般在书写的时候会被省略,如果要明确表示根域,则需要在域名的最后面加上 . 如 www.baidu.com. ,虽然书写的时候不写,但根域确是真实存在的,根域的 DNS 保管着 com、cn 等 DNS 服务器的信息,所以我们解析域名的时候需要从根域开始一路往下找到任意一个域的 DNS 服务器
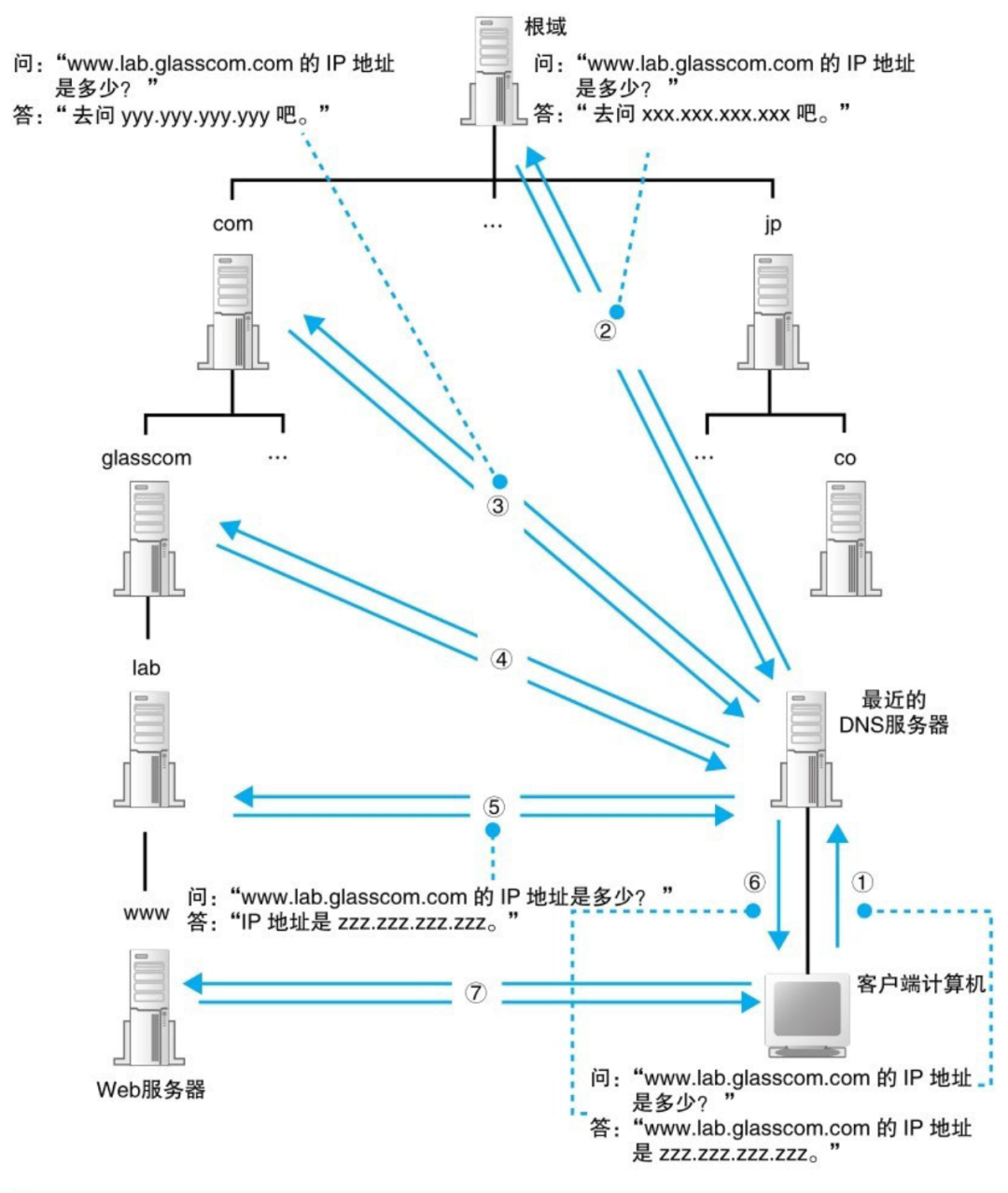
4. 缓存加快响应
有时候并不需要从最上级的根域开始查找,因为 DNS 服务器有一个缓存的功能,可以记住之前查询过的域名,如果要查询到域名和相关信息已经在缓存中,那么就可以直接返回响应。
同理,当要查询到域名不存在时,“不存在”这一响应结果也会被缓存。
缓存都具备有效期,当缓存中的信息超过有效期后,数据就会从缓存中删除。而且,在对查询进行响应时,DNS服务器也会告知客户端这一响应的结果是来自缓存中还是来自负责管理该域名的DNS服务器。
4)委托协议栈发送消息
当获得了 IP 地址之后,操作系统就可以进行消息收发了,消息实际上是一种 数字信息, 这一操作不仅限于浏览器,对于各种使用网络的应用程序来说都是共通的。
向操作系统内部的协议栈发出委托时,需要按照指定的顺序来调用 Socket 库中的组件。
在进行收发数据之前,双方需要先建立一条管道,建立管道的关键在于 管道两端数据的出入口,这些出入口就称为 套接字,然后将套接字连接起来就形成了管道,数据沿着这条通道流动(双向),最终到达目的地。
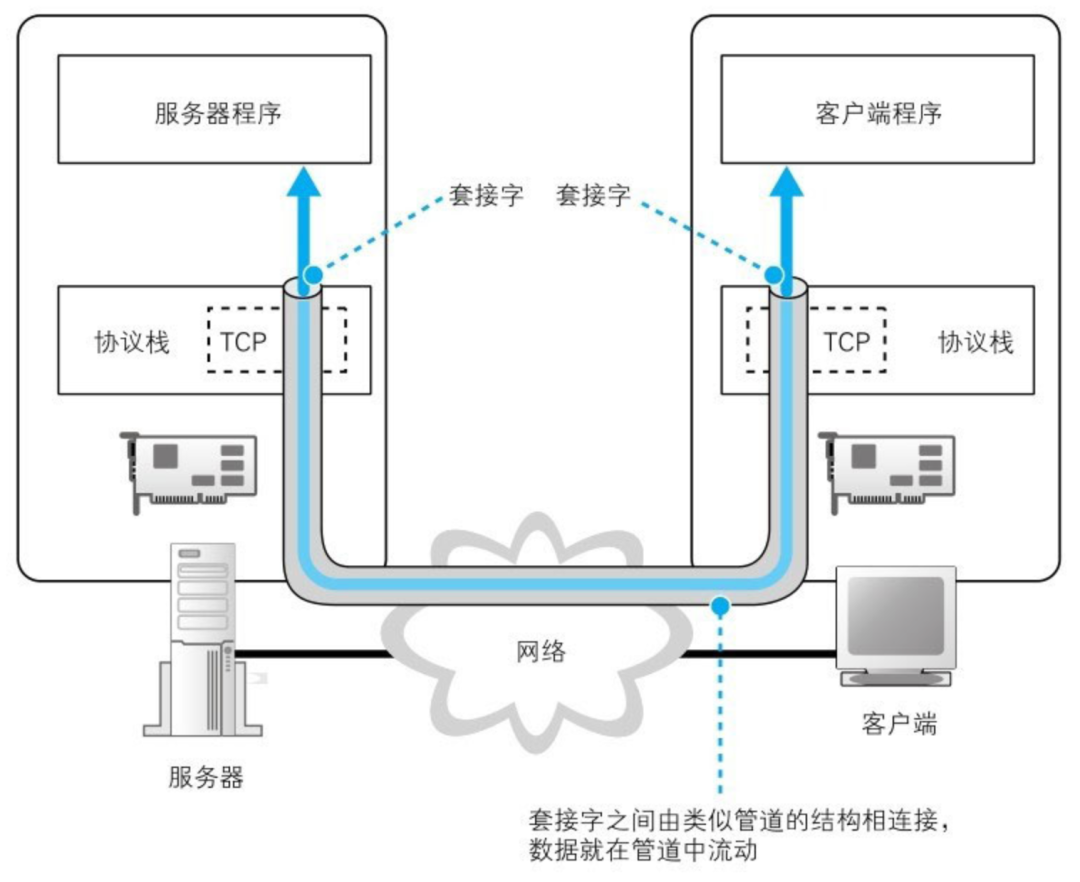
当数据全部发送完毕之后,连接的管道将会断开,管道在连接时是由客户端发起的,但在断开的时可以由任意一方发起。
总结,收发数据的大致操作如下:
创建套接字阶段:创建套接字 连接阶段:将管道连接到服务器端的套接字上 通信阶段:收发数据 断开阶段:断开管道并删除套接字
第二章:用电信号传输 TCP/IP 数据

1)创建套接字
1. 协议栈的内部结构
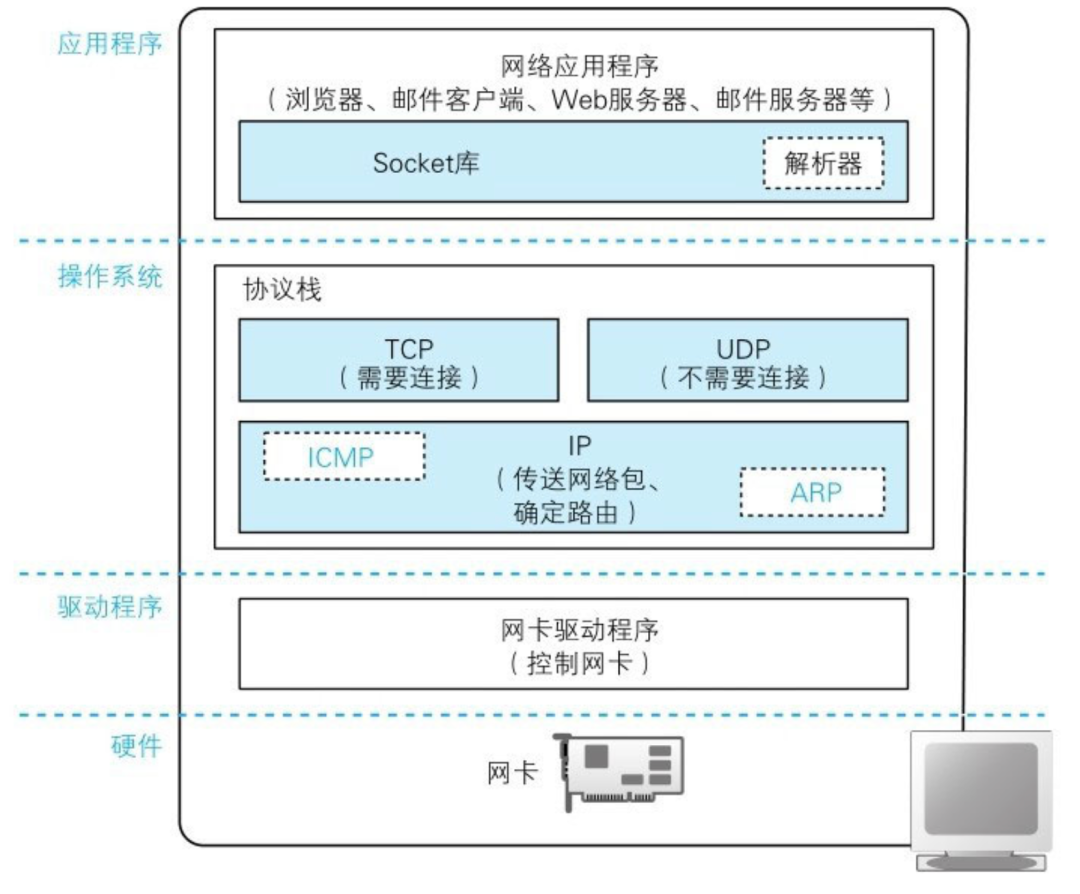
图的结构也是一种层级关系,上层会向下层逐层委派工作。
最上面的部分是网络应用程序,也就是浏览器、电子邮件客户端、Web服务器、电子邮件服务器等程序,它们会将收发数据等工作委派给下层的部分来完成。
应用程序的下层是 Socket 库,其中包括解析器,解析器用来向DNS服务器发出查询。
再下面就是操作系统内部了,其中包括协议栈。协议栈的上半部分有两块
负责用 TCP 协议收发数据的部分
负责用 UDP 协议收发数据的部分
下面一半是用 IP 协议控制网路包收发操作的部分。在互联网上传送数据,数据会被切分成一个一个的网络包,而将网络包发送给通信对象的操作就是由 IP 来负责。此外,IP 中还包括 ICMP 协议(用于告知网络包传送过程中产生的错误以及各种控制消息)和 ARP 协议(用于根据IP地址查询相应的以太网MAC地址)
IP 下面的网卡驱动程序负责控制网卡硬件 最下面的网卡则负责完成实际的收发操作,也就是对网线中的信号执行发送和接收操作
2. 套接字的概念
套接字就是一个概念,并没有实际意义上的实体,但它具备了例如通信对象的IP地址、端口号、通信操作的进行状态等。协议栈在执行操作的时候会查询这些控制信息。
它的作用就是:记录了用于控制通信操作的各种控制信息,协议栈则需要根据这些信息判断下一步的行动
2)连接服务器
创建了套接字之后,应用程序就会调用 connect,随后协议栈会将本地的套接字与服务器的套接字进行连接。这里的连接指的是通信双方交换信息的操作过程。
1. 保存控制信息的头部
控制信息可以分为两类
客户端和服务器相互联络时交换的控制信息。这些信息不仅连接时需要,数据收发和断开连接都需要。 保存在套接字中,用来控制协议栈操作的信息。应用程序传递来的信息以及从通信对象接收到的信息都会保存在这里,还有收发数据操作的执行状态等信息也会保存在这里。
2. 连接的实际过程
连接是从应用程序调用 Socket 库的 connect 开始的
connect(<描述符>, <服务器IP地址和端口号>,...)
上述连接的信息会传递给TCP模块,然后 TCP 会与该 IP 地址对应的通信对象进行交换控制信息。大致过程为以下几个步骤:
在 TCP 模块处创建表示连接控制信息的头部
通过 TCP 头部找到要连接的套接字
将信息传递给 IP 模块并委托它进行发送
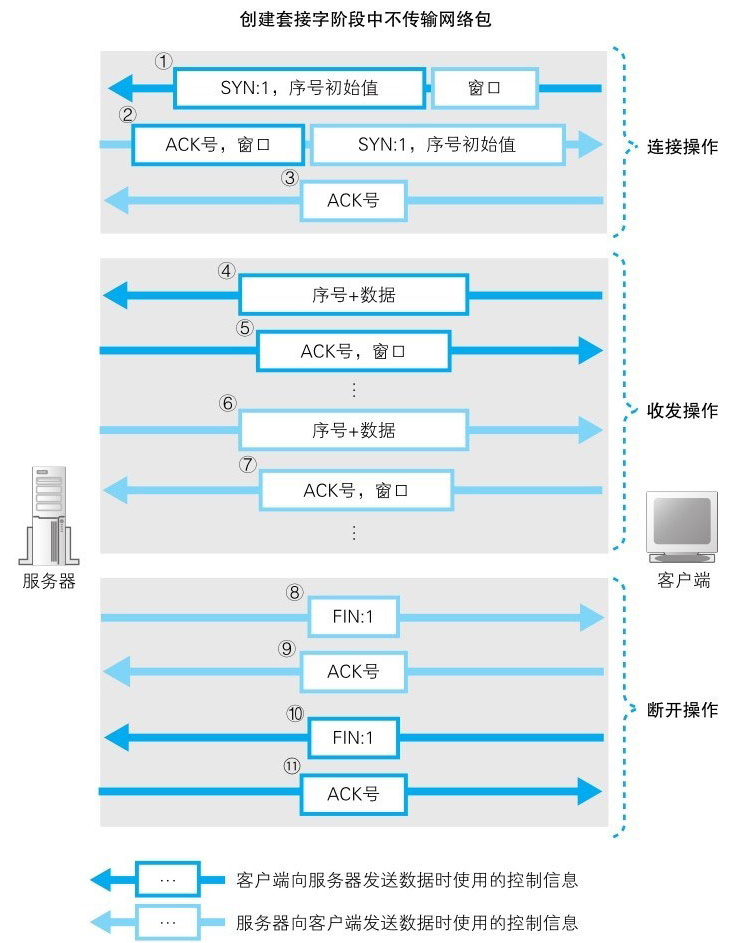
这期间其实还涉及到TCP 三次握手的过程
3)收发数据
1. 将消息交给协议栈
当控制流程从 connect 回到应用程序之后,接下来就进入到数据收发阶段。
数据收发操作是从应用程序调用 write 将要发送的数据交给协议栈开始的。
协议栈并不是一收到数据就马上发送出去,而是将数据存放在内部的发送缓冲区中,并等待应用程序的下一段数据。这样做的好处是协议栈发送的数据长度由应用程序本身决定。而什么时候是否才发出去有以下几个因素决定:
MTU:一个网络包的最大长度,以太网中一般为 1500 字节
MSS:除去头部之后,一个网路包所能容纳的TCP数据的最大长度
时间:当应用程序发送数据的频率不高的时候,如果每次都等到长度接近 MSS 时再发送,可能会因为等待时间太长而造成发送延迟,这种情况下,即便缓冲区中的数据长度没有达到MSS,也应该果断发送出去,为此协议栈内部有个计时器,当经过一定时间之后,就会把网路包发送出去

2. 数据拆分
发送缓冲区中的数据超出 MSS 的长度时,需要以 MSS 的长度为单位进行拆分,拆分出来的每块数据都会被放进单独的网络包汇总,根据发送缓冲区的数据拆分情况,当判断需要发送这些数据时,就在每一块数据前面加上TCP头部,并根据套接字中记录的控制信息标记发送方和接收方的端口号,然后交给 IP 模块进行发送
4)从服务器断开并删除套接字
和服务器的通信结束之后,用来通信的套接字也就不会再使用了,这时我们就可以删除这个套接字了,不过套接字并不会马上被删除,而是会等待一段时间之后再被删除,等待一段时间的原因是为了防止误操作。
具体等待多长的时间与包重传的操作方式有关。网络包丢失之后会进行重传,这个操作通常会持续几分钟,如果重传了几分钟之后依然无效,则停止重传。
1. 收发操作小结
数据收发操作第一步便是创建套接字,一般来说服务器一方的应用程序在启动时就会创建好套接字并进入等待连接的状态。客户端则一般是在用户触发特定动作,需要访问服务器的时候才创建套接字
创建好套接字之后,客户端会向服务器发起连接操作,也就是经典的 TCP 三次握手操作
建立完连接之后便进入了数据收发操作
5)IP与以太网的包收发操作
1. 包的基本知识
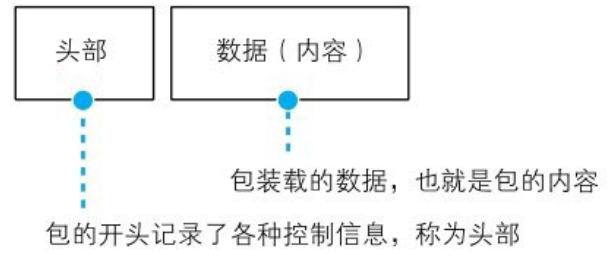
包是有头部和数据两部分构成的
头部:包含目的地址等控制信息,相当于快递包裹的面单 数据:发送给对方的内容,相当于快递包裹中的货物
网络中有 路由器 和 集线器 两种不同的转发设备
路由器:根据目标地址判断下一个路由器的位置 集线器:在子网中将网络包传输到下一个路由
实际上,集线器是按照 以太网规则 传输包的设备,而路由器是按照 IP 规则 传输包的设备,因此可以得出一个结论:
IP 协议:根据目标地址判断下一个 IP 转发设备的位置 以太网协议:在子网中将包传输到下一个转发设备
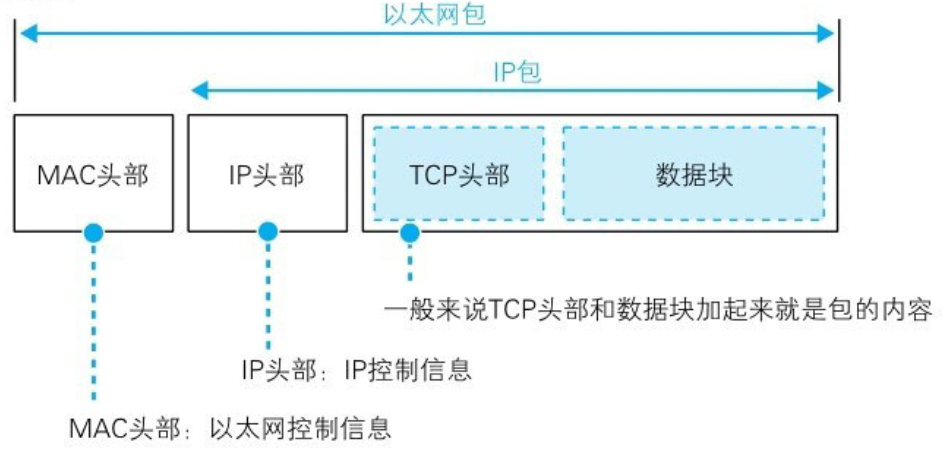
在 TCP/IP 中包含两个头部
MAC 头部:用于以太网协议 IP 头部:用于 iP协议
2. 包的收发操作
实际上将包从发送方传输到接收方的工作是由集线器、路由器等网络设备来完成的,因此 IP 模块仅仅是整个包传输过程的入口而已。
IP 模块负责添加两个头部:
MAC 头部:以太网用的头部,包含 MAC 地址 IP 头部:IP 用的头部,包含 IP 地址
接下来封装好的包会交给网络硬件(网卡),网路硬件会将这些数字信息转换为电信号或光信号,并通过网线(光纤)发送出去,然后这些信号就会到达集线器、路由器等转发设备,再由转发设备一步一步地送达接收方。
无论要收发的包是控制包还是数据包,IP 对各种类型的包的收发操作都是相同的
3. 生成 IP 头部
IP 并不知道接收方的IP 地址,这个地址是由应用程序指定的。IP 头部中除了接收方的 IP 地址,还需要填写发送发的 IP 地址,这里 IP 地址并不是指计算机的 IP 地址,而是网卡的 IP 地址,因为一个计算机中可能存在多张网卡。
4. 生成 MAC 头部
IP 头部中的接收方 IP 地址表示网络包的目的地,通过这个地址我们就可以判断要将包发送到哪里,但在以太网的世界中, TCP/IP 的这个思路是行不通的,以太网在判断网络包目的地时和 TCP/IP 的方式不同,因此必须采用 相匹配 的方式才能在以太网中将包发往目的地,而 MAC 头部就是干这个用的
MAC 头部的开头是接收方和发送方的 MAC 地址,不过 IP 地址是 32 比特,而 MAC 地址是 48 比特。
发送方的 MAC 地址好知道,但是接收方的 MAC 地址却比较麻烦,我们需要根据 IP 地址查询对应的 MAC 地址
5. ARP 查询 MAC地址
以太网中,有一种叫作广播的方法,可以把包发给连接在同一个以太网中的所有设备。
ARP 就是利用广播对所有设备提问:“xx 这个 IP 地址是谁的,请把你的 MAC 地址告诉我”

同样 ARP 中存在缓存,在发送的时候会先查询 ARP 缓存。
6. 以太网的基本知识
以太网是一种为多台计算机能够彼此自由和廉价相互通信而设计的通信技术。
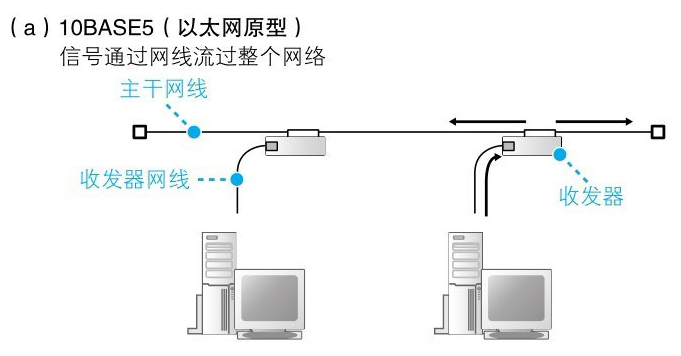
这种网路的本质其实就是一根网线,借助一种叫作收发器的小设备,它的功能只是将不同网线之间的信号连接起来。
当一台计算机发送信号时,信号就会通过网线流过整个网络,最终到达所有的设备,而这个时候需要在信号的开头加上接收者的信息,才能判断一个信号到底是发给谁的
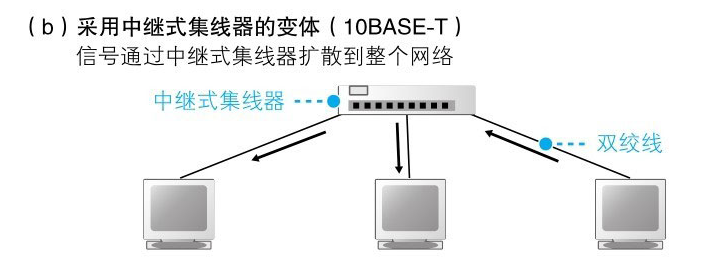
随着后来的发展,之前的原型转换成了一个中继集线器,将收发器网线替换成了双绞线,网络的结构虽然发生变化,但是信号会发送给所有设备这一基本性质并没有变
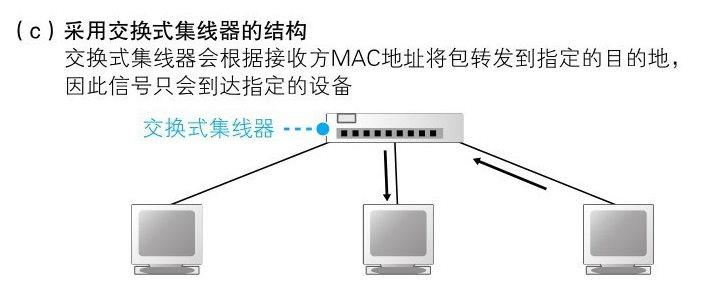
到了后面采用交换式集线器的时候,信号就不会发送给所有设备了,而是发送给指定 MAC 地址的设备
总结来说就是三个特性:
将包发送到 MAC 头部的接收方 用发送方 MAC 地址识别发送方 用以太类型识别包的内容
7. 向集线器发送网络包
我们可以将包通过网线发送出去,发出信号的操作分为两种
使用集线器的半双工模式
为了避免信号碰撞,首先要判断网线中是否存在其他设备发送的信号,如果有则需要阻塞等待
使用交换机的全双工模式
发送和接受可以同时进行,不会发生碰撞
8. 接受返回包
在使用集线器的半双工模式以太网中,一台设备发送的信号会到达连接在集线器上的 所有设备, 将信号全都接收后,便会进行 FCS 和 MAC 校验,如果校验通过,则将包放入缓冲区中,然后网卡会通知计算机收到了一个包。
通知计算机的操作会使用一个叫做 中断 的机制,需要打断计算机正在执行的任务,让计算机注意到网卡中发生的事情
6)UDP 协议的收发操作
1. 控制用的短数据
像 DNS 查询等交换控制信息的操作基本上都可以在一个包的大小范围内解决,这种场景就可以用 UDP 来代替 TCP。
2. 音频和视频数据
在发送音频和视频数据的时候,必须在规定的时间内送达,一旦送达完晚了,就会错过播放时机,导致声音和图像卡顿。因此通常会采用 UDP 来达到更高的传输效果,因为就算缺少了某些包并不会产生严重问题,知识会产生一些失真或卡顿。
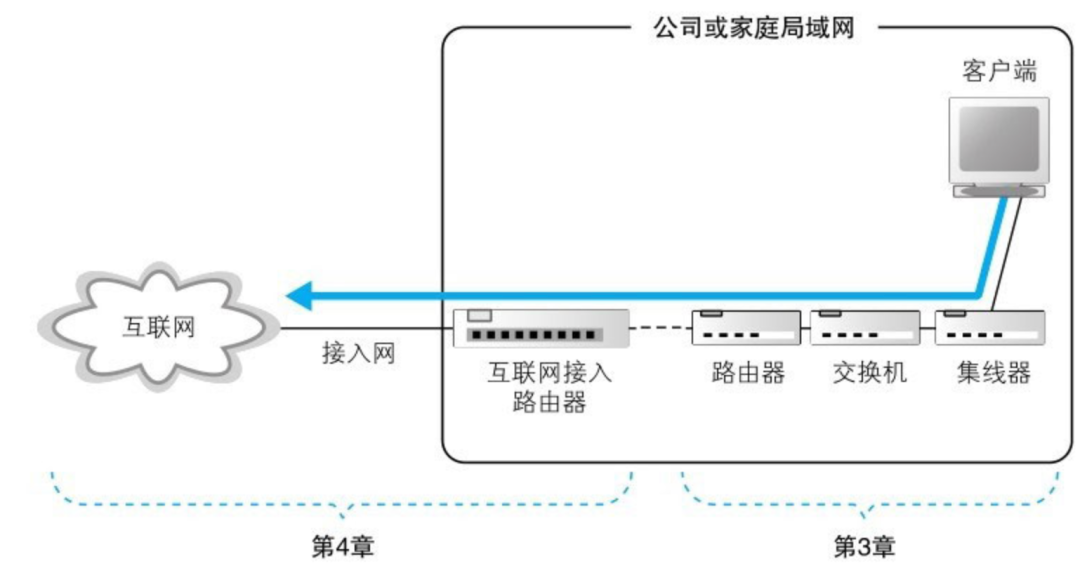
第三章:从网线到网络设备

1)信号在网线和集线器中传输
网络包从客户端计算机发出之后,要经过集线器、交换机和路由器最终进入互联网。实际上我们家用的路由器已经集成了 集线器 和 交换机 的功能
2)防止网线中的信号衰减很重要
信号到达集线器的时候斌不是跟刚发出去的是哦户一模一样,集线器收到的信号有时会出现衰减,信号在网络传输过程中能量会逐渐损失,网线越长,信号衰减越严重
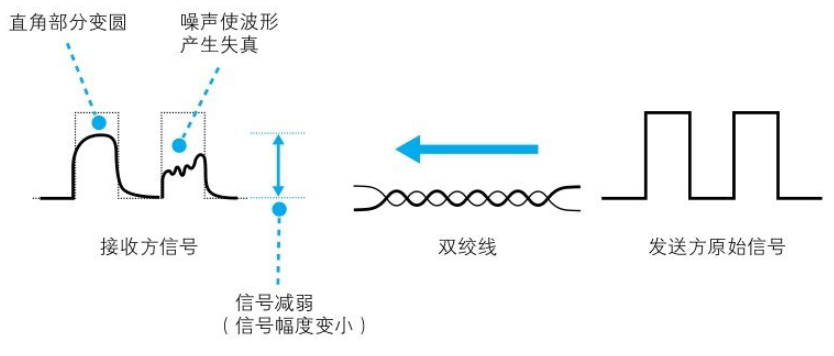
即便线路条件很好,没有噪声,信号在传输过程中依然会发生失真,如果再加上噪声的影响,失真就会更厉害。
3)双绞是为了抑制噪声
双绞线中双绞的意思是以两根信号线为一组缠绕在一起,这种拧麻花一样的设计就是为了抑制噪声的影响。
产生噪声的原因:
网线周围存在电磁波,当电磁波接触到金属等导体时,在其中就会产生电流。由于信号本身也是一种带有电压变化的电流,其本质和噪声产生的电流是一样的,所以信号和噪声的电流就会混杂在一起,是导致信号的波形发生失真,这就是噪声的影响
电磁波的种类:
由电机、荧光灯、CRT 显示器灯设备泄露出来的电磁波,这种电磁波来自网线之外的其他设备
要抑制这种电磁波,首先信号线是用金属做的,当电磁波接触到信号线时,会沿着电磁波传播传播的右旋方向产生电流,这种电流会导致波形发生失真,如果将信号线缠绕在一起,信号线就会变成螺旋形,其中两根信号线中产生的噪声电流防线就会相反,从而使得噪声电流相互抵消,噪声就得到了抑制
从网线中相邻的信号线泄露出来
这种噪声的强度并不大,但是距离比较近。抑制这种噪声的方式就在于双绞线的缠绕,在一根网线中,每一对信号线的扭绞节距都有一定的差异,这使得在某些地方正信号线距离近,另一些地方则是负信号线距离近。由于正负信号线产生的噪声影响是相反的,所以两者就会相互抵消
4)集线器将信号发往所有线路
当信号到达集线器后,会被广播到整个网络中。以太网的基本架构[插图]就是将包发到所有的设备,然后由设备根据接收方MAC地址来判断应该接收哪些包,而集线器就是这一架构的忠实体现,它就是负责按照以太网的基本架构将信号广播出去
2)交换机根据地址表进行转发
交换机的设计是将网络包原样转发到目的地。
当信号到达网线接口,并由 PHY(MAU)模块进行接收,这一部分和集线器是相同的,PHY(MAU)模块会将网线中的信号转换为通用模式,然后传递给 MAC 模块,MAC 模块会将信号转换为数字信号,然后通过包末尾的 FCS 校验错误,如果没有问题则存放到缓冲区中。
这部分的操作和网卡基本相同,可以认为交换机的每个网线接口后面都是一块网卡,与网卡不同的是,交换机的端口不具有 MAC 地址
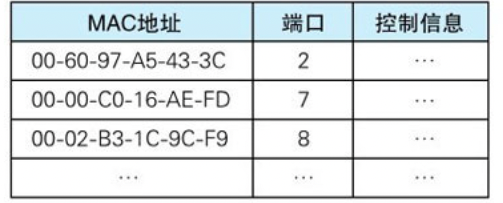
当包存入缓冲区后,就需要查询这个包的接收方 MAC 地址是否已经在 MAC 地址表有记录了,然后通过交换电路将包发送到响应的端口
当网路包通过交换电路到达发送端口时,端口中的 MAC 模块和 PHY(MAU)模块会执行发送操作,将信号发送到网线中,这部分和网卡发送信号的过程是一样的。
3)MAC 地址表的维护
交换机在转发包的过程中,还需要对 MAC 地址表的内容进行维护,维护分为两种:
在收到包时,将发送方 MAC 地址以及其输入端口号写入 MAC 地址表 删除地址表中的某条记录的操作,防止设备移动时产生的问题(比如当我们把计算机从办公桌移动到会议室时,设备就发生了移动,端口也会发生变化)。为了防止终端设备移动产生的问题,需要将一段时间不使用的过时记录从地址表中删除就可以了
4)全双工模式
全双工模式是交换机特有的工作模式,它可以同时进行发送和接收操作,集线器不具备这样的特性
5)自动协商:确定最优的传输速率
自动协商指的是在相互连接的双方探测对方是否支持全双工模式,并支持切换成相应的工作模式,并且除了能自动切换工作模式之外,还能探测对方的传输速率并进行自动切换。
3)路由器的包转发操作
1. 路由器的基本知识
网线包经过集线器和交换机之后,便会到达路由器。
路由器是基于 IP 设计的,交换机是基于以太网设计的。路由器包括 转发模块 和 端口模块
转发模块:负责判断包的转发目的地(类似 IP 模块) 端口模块:负责包的收发操作(类似网卡)
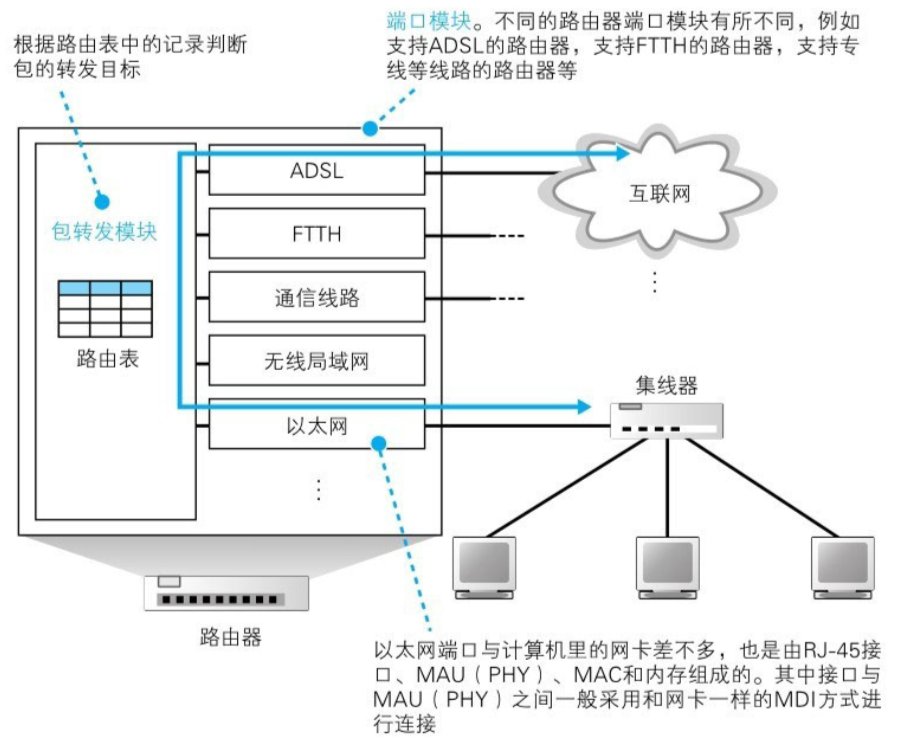
路由器基本原理:
路由器在转发包时,首先会通过端口将发过来的包接收进来,这一步的工作过程取决于端口对应的通信技术。对于以太网端口来说,就是按照以太网规范进行工作,而无线局域网端口则按照无线局域网的规范工作,总之就是委托端口的硬件将包接收进来。接下来转发模块会根据接收到的包的 IP 头部中记录的接收方 IP 地址,在路由表中进行查询,以此判断转发目标,然后转发模块将包转移到转发目标对应的端口,端口再按照硬件的规则将包发送出去,也就是转发模块委托端口模块将包发送出去。
第四章:通过接入网进入互联网内部

1)ADSL 接入网的结构和工作方式
1. 互联网的基本结构和家庭、公司网络是相同的
互联网也是通过路由器来转发包的,我们可以将互联网理解为家庭、公司网路的一个放大版。
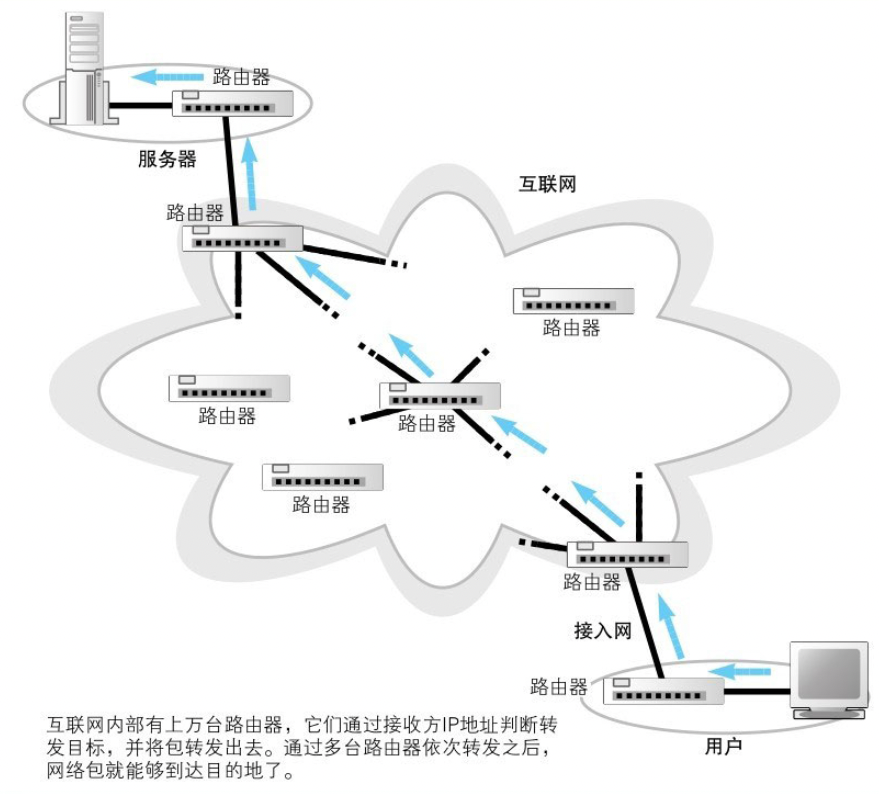
而互联网与家庭、公司网络之间最主要的两个不同点在于:距离的不同 和 路由的维护方式不同
2. 连接用户与互联网的接入网
所谓接入网,就是指连接互联网与家庭、公司网络的通信线路。一般家用的接入网包括 ADSL、FTTH、CATV、电话线、ISDM等,公司则还可能使用专线。
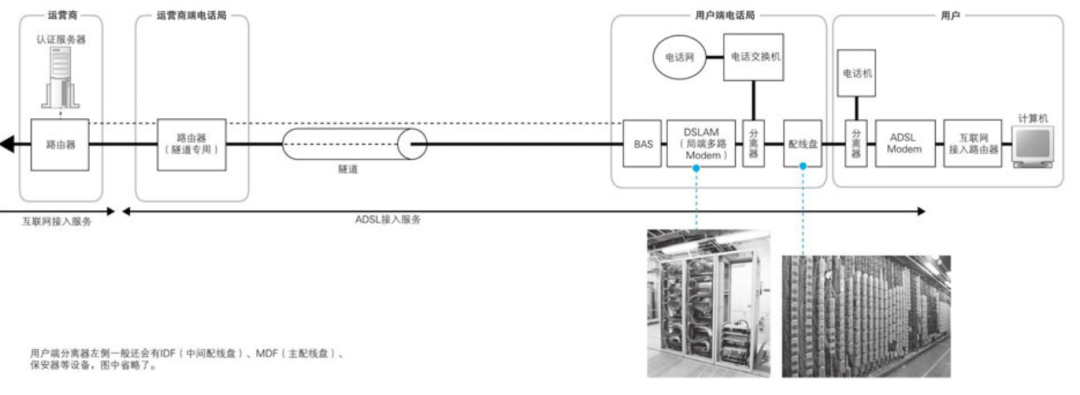
3. ADSL Modem 将包拆分成信元
在这张图中网络包是从右往左传输的。用户端路由器发出的网络包通过 ASDL Modem 和电话线达到电话局,然后到达 ADSL 的网络运营商(ISP)。
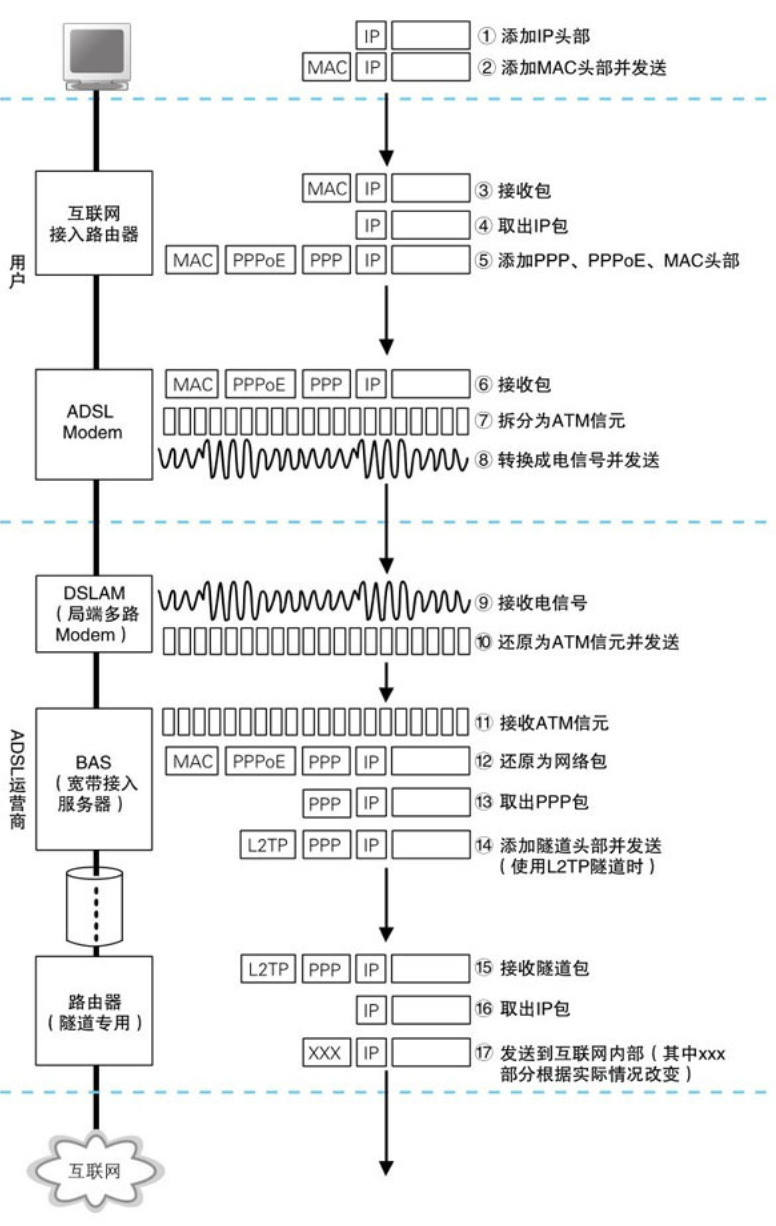
客户端生成的网络包先经过集线器和交换机到达互联网接入路由器,并在此从以太网中取出 IP 包并判断转发目标。在这里网络包会加上 MAC 头部、PPPoE 头部、PPP 头部总共3种头部,然后按照以太网规则转换成电信号后被发送给 ADSL Modem,然后 ADSL Modem 会把包拆分成很多个小格子,每一个小格子称为一个信元。
4. ADSL 将信元调制成信号
以太网采用的是用方波信号表示 0 和 1 的方式,ADSL 会比较复杂,它是采用一种用 圆滑波形(正弦波)对信号进行合成来表示 0 和 1,这种技术称为 调制。
调制的方式有很多种,ADSL 采用的调制方式是 振幅调制(ASK) 和 相位调制(PSK) 相结合的正交振幅调制(QAM)方式

5. ADSL 通过使用多个波来提高速率
信号不一定要限制在一个评率,不同频率的波可以合成,因此可以使用多个频率合成的波来传输信号,这样能表示的比特数就可以成倍提高了,ADSL 就是利用了这一性质,通过多个波增加能表示的比特数来提高速率。
6. 分离器的作用
ADSL Modem 将信元转换为电信号之后,信号会进入一个叫做分离器的设备,然后 ADSL 信号会和电话的语音信号混合在一起从电话线传输出去。
分离器的作用其实在相反的方向,也就是信号从电话线传入的时候,需要将电话和 ADSL 的信号进行分离。
分离器的功能是将一定频率以上的信号过滤掉,也就是过滤掉了ADSL使用的高频信号,这样一来,只有电话信号才会传入电话机,但对于另一头的ADSL Modem,则是传输原本的混合信号给它。
7. 从用户到电话局
从分离器出来就是插电话线的接口,信号从这里出来之后,会通过室内电话线,然后到达大楼的 IDF 和 MDF。由于电话局附近的地下电缆很多,集中埋设电缆的地方就形成了一条地道,这部分称为电缆隧道。通过电缆隧道进入电话局后,电缆会逐根连接到电话局的MDF上。
2)光纤接入网
1. 光纤的基本知识
接入网技术除了上述说到的 ADSL ,还有一种称为 FTTH,是一种基于光纤的接入网技术。FTTH 的关键在于对光纤的使用。
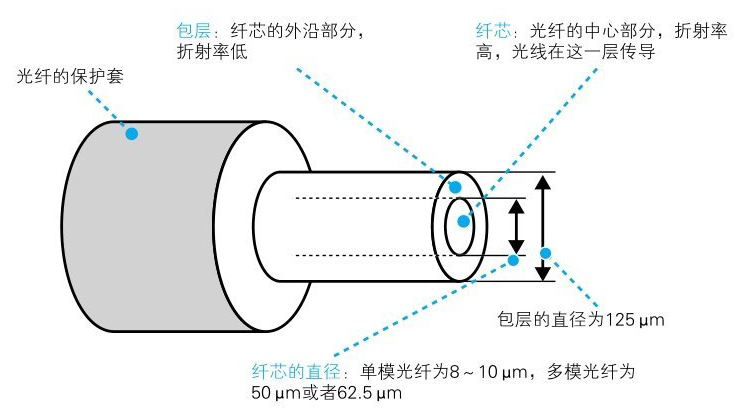
光纤是由一种双层结构的纤维状透明材质(玻璃和塑料)构成的,通过在里面的纤芯中传导光信号来传输数字信息。亮表示 1,暗表示 0
2. 单模与多模
光纤通信的关键技术就是能够传导光信号的光纤。光纤可以分成几种类型,大体上包括较细的单模光纤(8~10 um)和较粗的多模光纤(50 um或62.5 um)
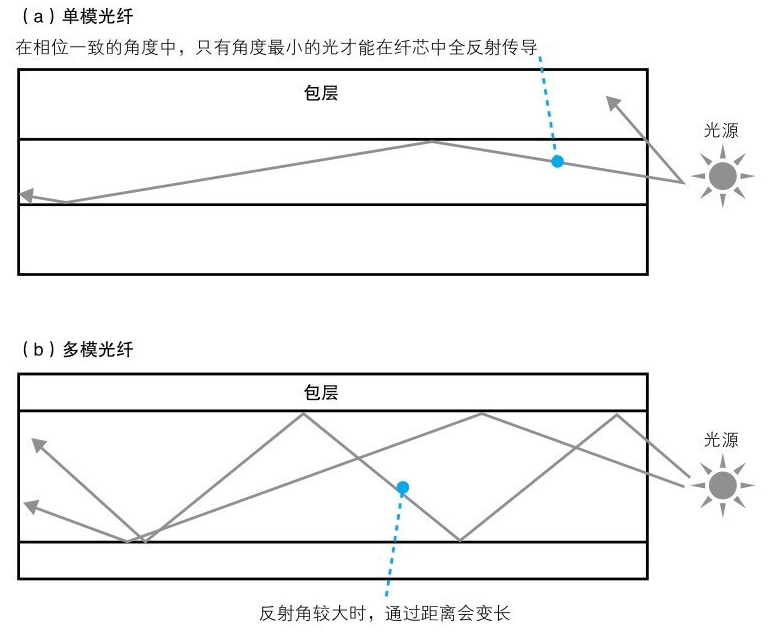
多模光纤: 可以传导多条光线,意味着通过的光线较多,对光源和兴敏元件的性能要求也就较低,从而可以降低光源和光敏元件的性能要求
单模光纤: 只能传导一条光线,能通过的光线较少,对光源和兴敏元件的性能要求较高
单模光纤的失真小,可以比多模光纤更长,因此多模光纤主要用于一座建筑物里面的连接,单模光纤则用于距离较远的建筑物之间的连接
3)接入网中使用的 PPP 和隧道
1. 用户认证和配置下发
ADSL和FTTH接入网中,都需要先输入用户名和密码,登录之后才能访问互联网,而BAS就是登录操作的窗口。BAS使用PPPoE方式来实现这个功能。
PPP 工作方式:
首先,用户向运营商的接入点拨打电话,电话接通后输入用户名和密码进行登录操作。用户名和密码通过RADIUS协议从RAS发送到认证服务器,认证服务器校验这些信息是否正确。当确认无误后,认证服务器会返回IP地址等配置信息,并将这些信息下发给用户。
2. 在以太网上传输 PPP 消息
ADSL 和 FTTH 接入方式也需要为计算机分配公有地址才能上网,这一点和拨号上网是相同的。
PPP协议中没有定义以太网中的报头和FCS等元素,也没有定义信号的格式,因此无法直接将PPP消息转换成信号来发送。要传输PPP消息,必须有另一个包含报头、FCS、信号格式等元素的“容器”,然后将PPP消息装在这个容器里才行。于是,在拨号接入中PPP借用了HDLC协议作为容器,而HDLC协议原本是为在专线中传输网络包而设计的,拨号接入方式对这一规格进行了一些修正。对于 ADSL 和 FTTH ,并不能使用 HDLC ,但可以使用以太网包代替 HDLC 来转载 PPP 协议,并且为了弥补这些问题就设计了一个新的规格,就是 PPPoE
3. 通过隧道将网络包发送给运营商
BAS除了作为用户认证的窗口之外,还可以使用隧道方式来传输网络包
隧道就类似于套接字之间建立的 TCP 连接,将包含头部在内的整个包从隧道的一头扔进去,这个包就会原封不动地从隧道的另一头出来,就好像在网络中挖了一条滴到,网络包从这个地道穿过去。
隧道的实现方式:
类似 TCP 连接,需要在网路上的两台隧道路由器之间建立 TCP 连接,然后将连接两端的套接字当做是路由器的端口,并从这个端口来收发数据。 基于封装的隧道实现方式。将包含头部在内的整个包装入另一个包中传输到隧道的另一端。这种方式下,包本身可以原封不动地到达另一端的出口。
4)网络运营商的内部
1. POP 和 NOC
互联网是由多个运营商网络相互连接组成的。ADSL、FTTH等接入网是与用户签约的运营商设备相连的,这些设备称为 POP,也就是互联网的入口。
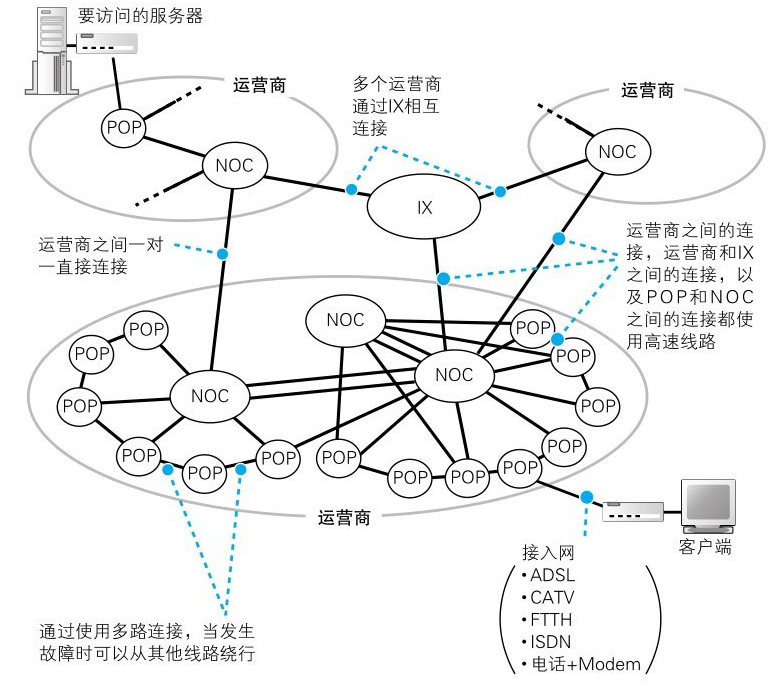
POP 的结构根据接入网类型以及运营商的业务类型不同而不同。
5)跨越运营商的网络包
1. 运营商之间的连接
当网络包到达 POP 路由器之后,如果最终目的地 Web 服务器和客户端连接在同一个运营商中,那么 POP 路由器的路由表中应该有相应的转发目标。运营商的路由器可以和其他路由器交换路由信息,从而自动更新自己的路由表,实现了自动化管理。
如果服务器的运营商和客户端的运营商是不同的,那么需要先发到服务器的运营商,这些信息也可以在路由表找到,因为运营商的路由器也在和其他运营商的路由器交换信息。
2. 运营商之间的路由信息交换

只要让相连的路由器告知路由信息就可以了,只要获得了对方的路由信息,就可以知道对方路由器连接的所有网络,将这些信息写入自己的路由表,也可以向那些网络发送包了。这个路由信息交换使用的机制成为 BGP。
这种路由交换可分为两类:
将互联网中的路由全部告知对方 两个运营商之间仅将与各自网络相关的路由信息告知对方,这样双方之间的网络可以互相收发网络包,这种方式称为非转接,也叫对等。
第五章:服务器端的局域网中有什么玄机

1)Web 服务器的部署地点
1. 在公司里部署Web服务器
传统的部署方式:服务器直接部署在公司网络上,并且可以从互联网直接访问。这种情况下,网络包通过最近的 POP 中的路由器、接入网以及服务器端路由器之后,就到达了服务器。
这种方式存在弊端:
IP 地址不足。这种方式需要为公司网络中的所有设备,包括服务器和客户端计算机,都分配各自的公有地址。 安全问题。互联网中的网络包会无节制进入服务器。
2. 将Web服务器部署在数据中心
服务器可以放在网络运营商管理的数据中心,或直接租用运营商提供的服务器。
数据中心是与运营商核心部分 NOC 直接连接的,或是与运营商之间的枢纽IX直
接连接的。可以通过高速线路直接连接到互联网的核心部分,因此将服务器部署
在这里可以获得很高的访问速度,
2)防火墙的结构和原理
1. 主流的包过滤方式
无论服务器部署在哪里,都会在前面部署一个防火墙。如果包无法通过防火墙,就无法到达服务器。
2. 如何设置包过滤的规则
网路包的头部包含了用于控制通信操作的控制信息,只要检查这些信息,就可以获得很多有用的内容。
在这是包过滤规则时,首先要观察包是如何流动的。通过接收方 IP 地址和发送方 IP 地址,可以判断出包的起点和终点,并将IP地址设为判断条件。
3. 通过端口号限定应用程序
当我们要限定某个应用程序时,可以在判断条件中加上 TCP 头部或者 UDP 头部中的端口号作为判断条件。
4. 通过控制位判断连接方向
通过上述两个条件,可以限定到某个具体的应用程序,但还是没办法阻止 Web 服务器访问互联网,Web 使用的 TCP 协议是双向收发网络包的,因此如果单纯地阻止从 Web 服务器发往互联网的包,则从互联网访问 Web 服务器的操作也会收到影响而而无法进行。因此单判断包的流向还不够,还需要根据访问的方向来进行判断,这里就需要用到 TCP 头部的控制位。
3)内容分发服务
1. 利用内容分发服务分担负载
当缓存服务器部署在服务端并不能减少流量,因此如果将缓存服务器部署在客户端就可以不受或者少受某些拥塞点的影响,让网络流量更稳定。但如果部署在客户的函,Web服务器的育婴师并不能控制它,无法扩缩容数量。因此可以将缓存服务器部署在互联网的边缘
三种部署方式:
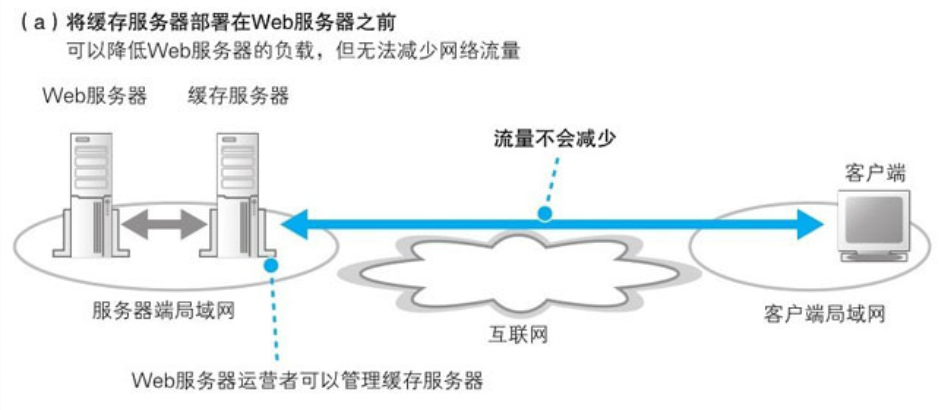
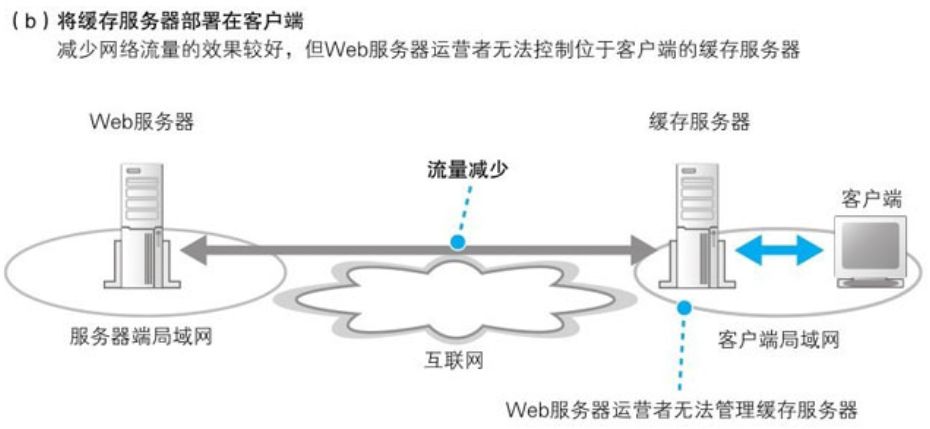
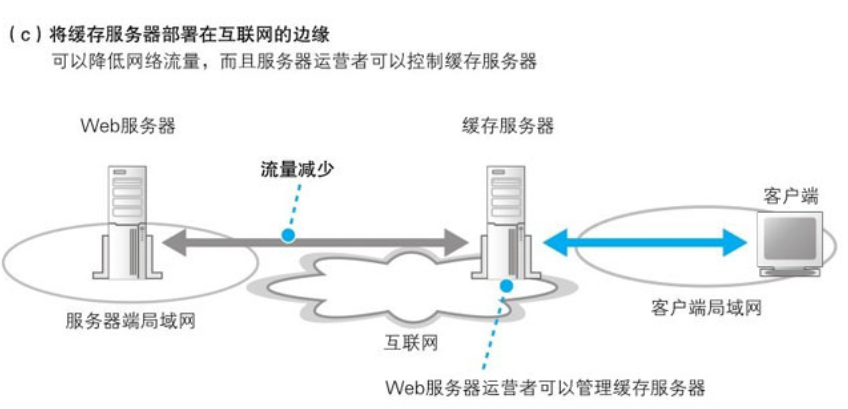
作为Web 服务器运营商如果自己部署服务器,在一定程度上还是吃不消的,因此出现了专门提供这种服务(内容分发服务)的厂商称为 CDSP.
2. 如何找到最近的缓存服务器
利用 DNS 服务器来分配访问,它们可以通过相互接力来处理 DNS 查询。但 DNS 只能以轮询的方式按照顺序返回 IP 地址,完全不考虑客户端与缓存服务器的远近,因此可能会返回离客户端较远的缓存服务器IP地址。
如果要访问到最近的缓存服务器,不应采用轮询,而是应该判断客户端与缓存服务器的距离,并返回距离客户端最近的缓存服务器 IP 地址。
不要空谈,不要贪懒,和小菜一起做个吹着牛X做架构的程序猿吧~点个关注做个伴,让小菜不再孤单。咱们下文见!
今天的你多努力一点,明天的你就能少说一句求人的话!
我是小菜,一个和你一起变强的男人。
💋微信公众号已开启,菜农曰,没关注的同学们记得关注哦!