
借助Transformer,DeepMind新模型自动生成CAD草图,网友:建筑设计要起飞了
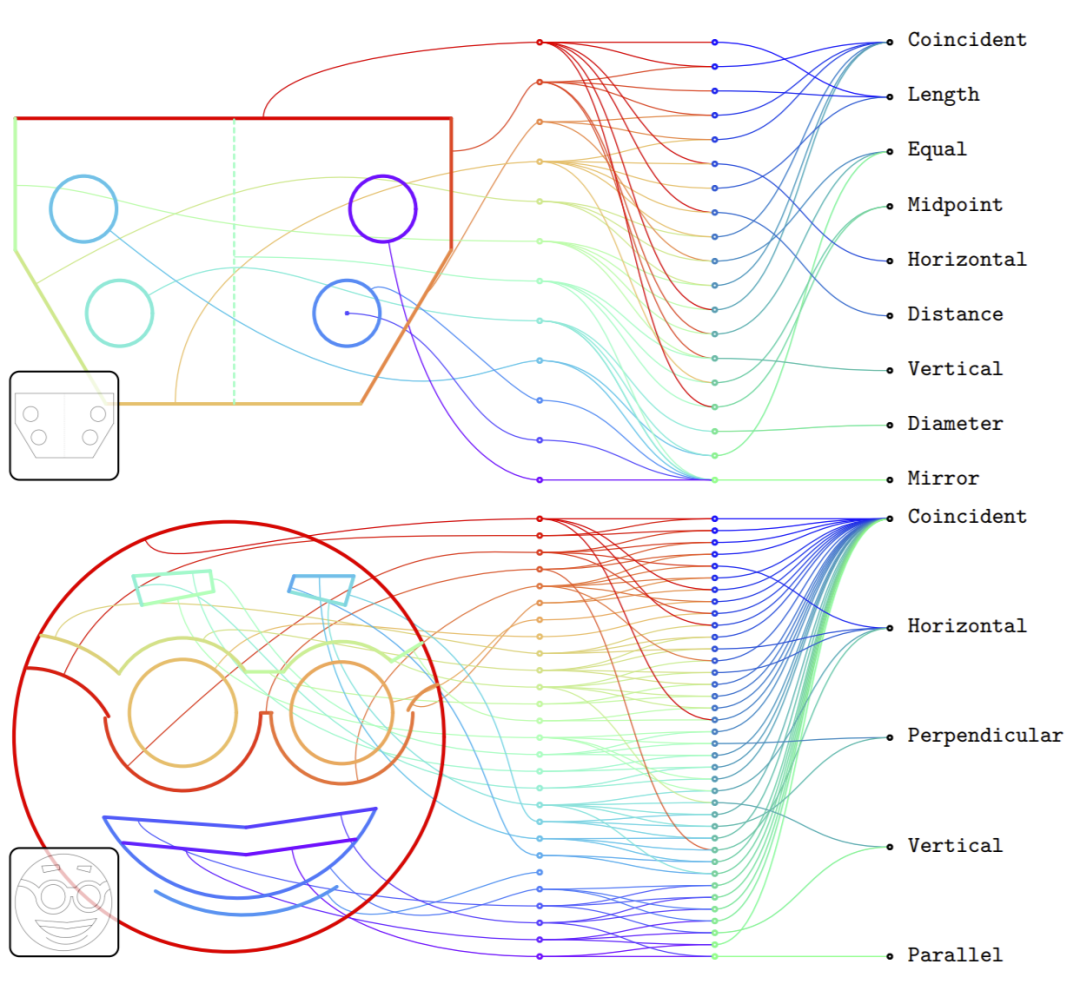
深度学习的灵活性恰好适合于复杂的 CAD 设计,DeepMind 的研究者基于 CAD 草图与自然语言建模的相似性,提出了自动生成 CAD 草图的机器学习模型。

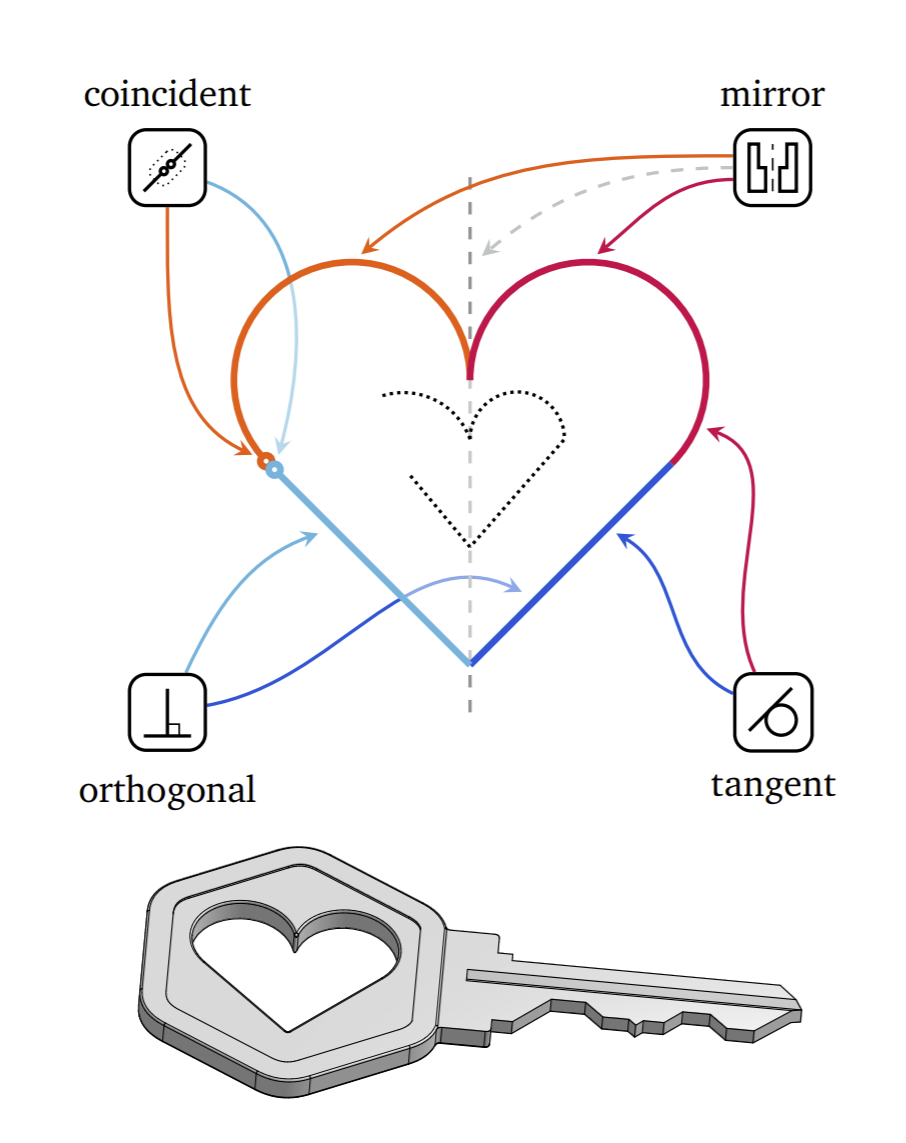
使用 PB(Protocol Buffer)设计了一种描述结构化对象的方法,并展示了其在自然 CAD 草图领域的灵活性;
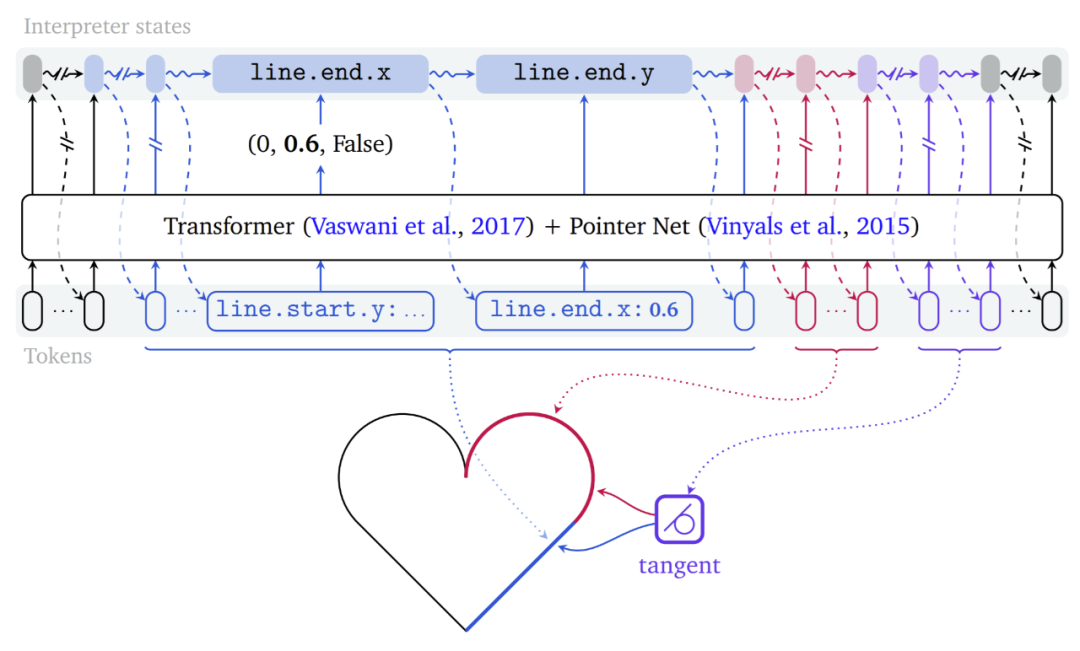
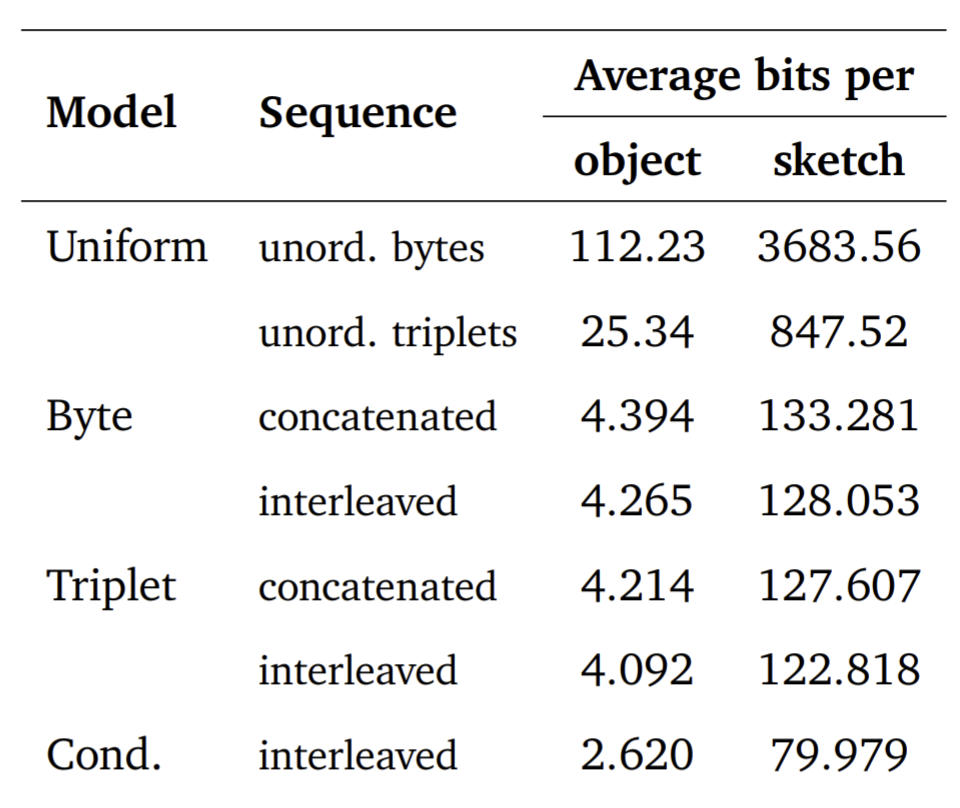
从最近的语言建模消除冗余数据中吸取灵感,提出了几种捕捉序列化 PB 对象分布的技术;
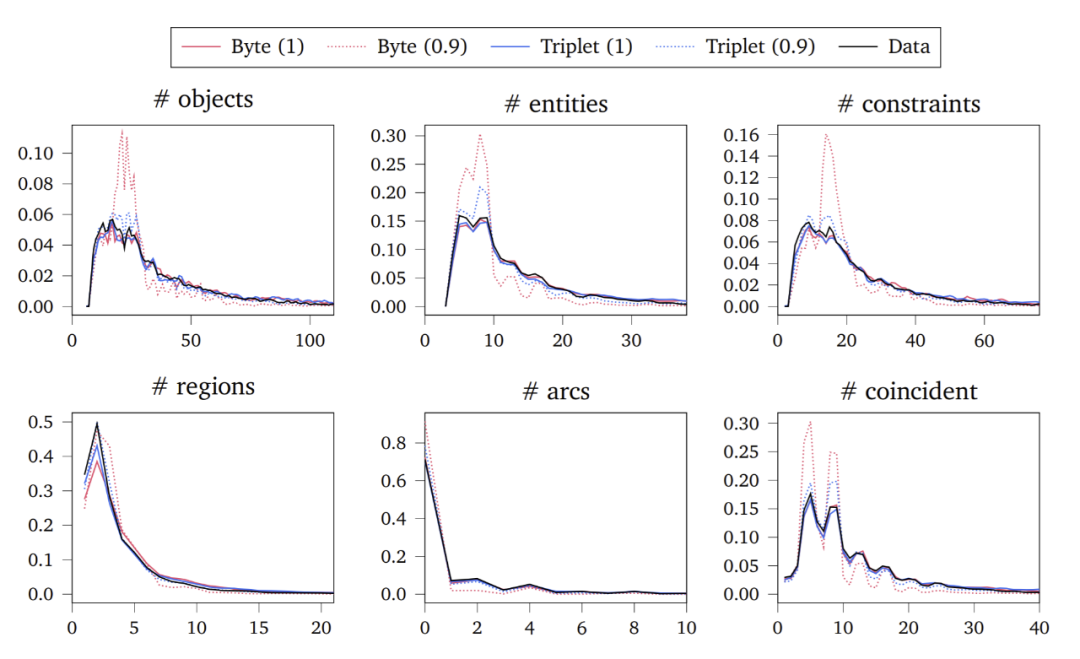
使用超过 470 万精心预处理的参数化 CAD 草图作为数据集,并使用此数据集来验证提出的生成模型。事实上,无论是在训练数据量还是模型能力方面,实际的实验规模都比这更多。




评论