
聊聊数据分析的权重思维:找女票身材 > 相貌 > 涵养?
大家好,我是宝器
实际分析工作和生活中,经常会遇到各种权重问题:
想计算一个销售综合增速得分,那2019年增速和2020年增速分别赋权多少合适?
用户和商品互动有多种形式,如果要构造一个商品综合互动指数,浏览、收藏、加购、支付这些行为分别对应的权重是多少?
要找女朋友,相貌、身材、涵养、家庭背景重要度应该怎么量化排序?
今天我特意肝了篇文章,给大家介绍几种常见又简单粗暴的权重确定方法。
艺术确定法
艺术确定法,顾名思义,乃拍脑袋确定法。
之所以称之为艺术,是因为它内部不确定性像艺术一样抽象。且艺术程度,会随着使用者工作年限和级别的不同而不同。
拿文章开头“想计算一个销售综合增速得分,2019年增速和2020年增速分别赋权多少合适?”的问题来说。
实习生:数据量太有限了,从重要度来说,我觉得19年增速权重可以是0.4,20年权重可以是0.6
业务:你觉得?那为什么19年权重不是0.38,20年权重不是0.62?不要什么都这么主观!
高级分析:上次类似的业务场景,我们给19年的增速赋权是0.3,20年增速赋权0.7,我觉得业务场景没有发生本质变化,可以沿用。
业务:有点道理,也许可以凑合着用。
BOSS:基于我的多年行业经验和二八法则等经典理论,我认为,19年和20年增速的权重,分别是0.2和0.8。既是经典理论的实战运用,又是我们不念过往辉煌,一心向前,只看重最近增长速度的力证。

业务:老板牛逼!老板就是老板!老板不愧是老板!
权值因子判表法
权值因子判表法,也是属于主观赋权法的一种。
和艺术确定法相比,这种方法在专家意见、多方权衡和相对量化几个方面有一定的优势,结论可信度也更强。
举一个具体的案例:
要找女朋友,相貌、身材、涵养、家庭背景重要度应该怎么量化排序?
数据不吹牛婚恋公司召集了最最最权威的4个情感专家,要通过权值因子判表法来解决这个问题。
首先,结合背景的3个考量维度,为每个专家制定判别表:
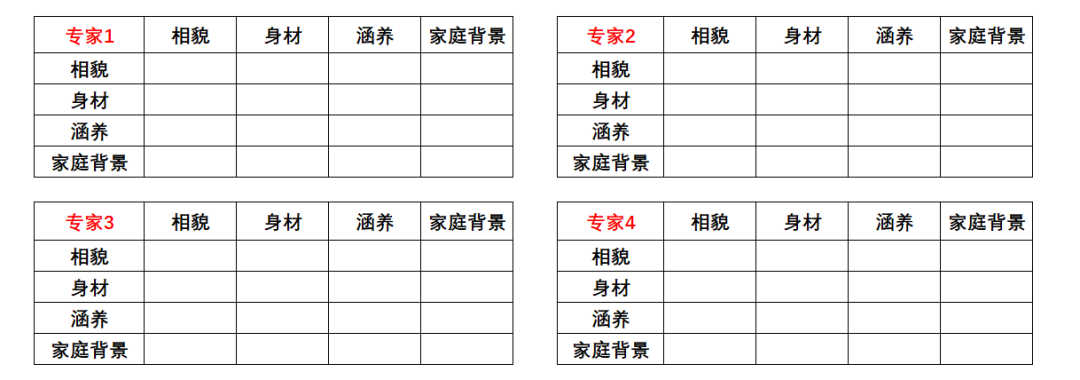
接着,把每个表分发至专家,让其独立完成打分。打分逻辑很简单,用行的属性和列的属性做比较,如果认为行属性比对应的列属性更重要,则填上1,否则填0。
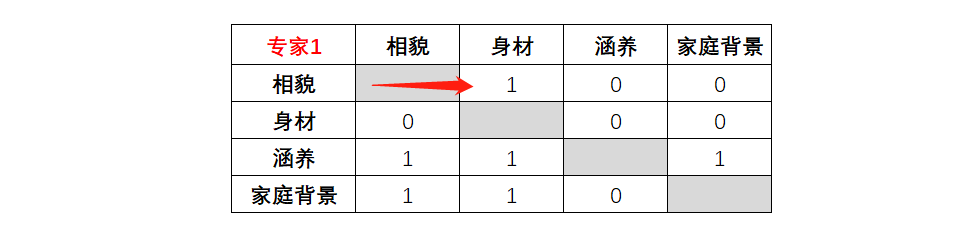
这些属性不会和自身相比,所以对角线一栏是空值,我们重点对右上角区域进行打分,因为左下角的打分直接是右上角的逻辑对称(但也会参与计算)。
比如认为相貌比身材重要,打1分,身材对应的肯定没有相貌重要,在身材和相貌对比的单元格,打0分。
根据专家1的打分表,显而易见:
相貌比身材重要,相貌没有涵养和家庭背景重要
身材自然也没有涵养和家庭背景重要
而涵养比家庭背景重要
综合来看,专家1认为,涵养 > 家庭背景 > 相貌 > 身材。
其他专家打分也是一样的逻辑,打完分后我们行向求和,得到每位的分值汇总:
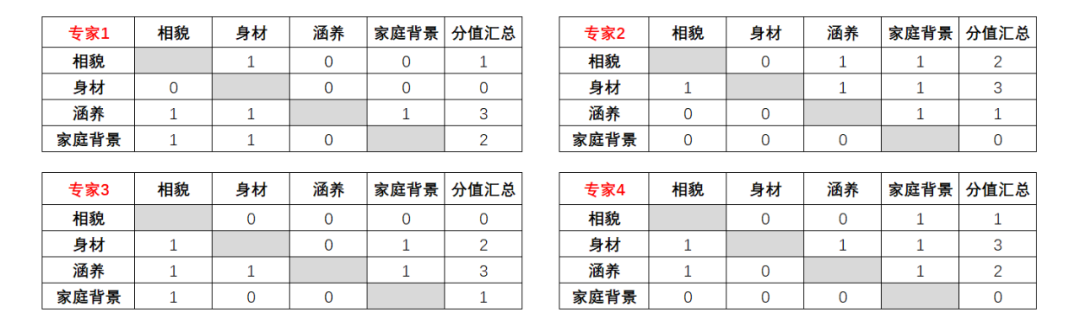
最后,结合4位专家的打分,求平均值,例如相貌平均分:

其他平均分逻辑完全一样:

由于权重之和一般是1,计算各属性对应的权重,用其平均得分 除以 平均得分之和即可:

从不吹牛请的这4位专家角度来看,找女票,涵养 > 身材 > 相貌 > 家庭背景。
“这专家一点都不专业!看来权值因子判表法,在专家选择上,非常重要!”软饭硬吃的小A愤愤不平。
变异系数法
讲了两个常见的主观赋权法,再聊聊客观赋权法中,比较常见和易于理解的变异系数法。
变异系数法的核心,是用数据波动来确定权重。变异系数的计算很简单,就是用标准差 除以 平均值,变异系数越大,则数据的偏离程度越大。
变异系数法的思想中,某个指标偏离程度越大,说明该指标难以实现,是反应所评对象差距的关键指标,应赋予更高的权重。
我们拿到了一份成绩单,如何通过变异系数法来确定各科的权重呢?
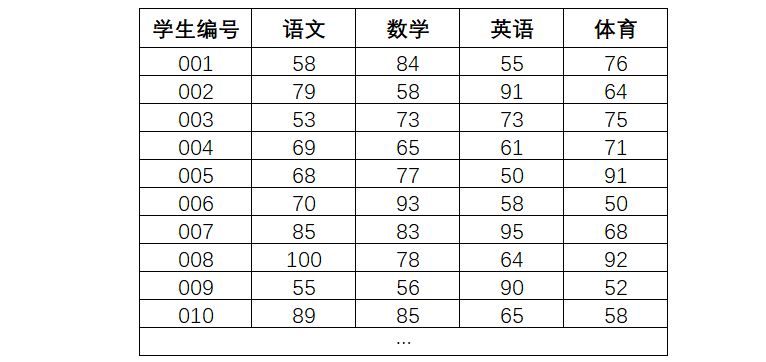
先计算各科目的平均数、标准差,在此基础上计算变异系数:
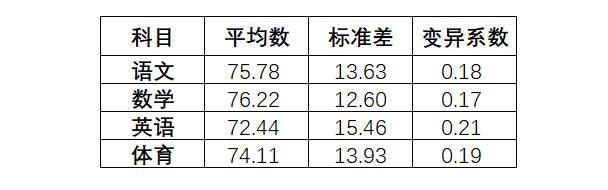
然后求各科变异系数值的占比,即为权重:
例:语文权重 = 0.18 / (0.18 + 0.17 + 0.21 +0.19)
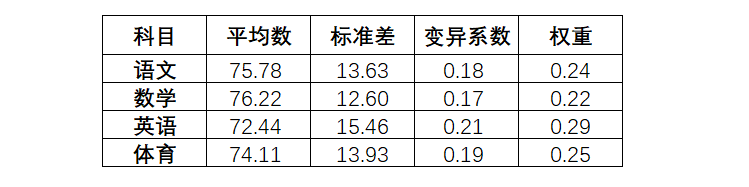
这样,我们通过变异系数法,求得了各科的权重,也知道了英语成绩是这次拉开差异的主要科目。
篇幅有限,小z讲了几个基础的权重确定方法,想做更多了解,还有层次分析法、德尔菲法、优序图法、熵值法等方法。当然,不要被这么多方法所迷惑,了解对应的使用场景和优缺点,适合业务场景的才是最好的。

推荐阅读
欢迎长按扫码关注「数据管道」