
Loki 和 Fluentd 的那点事儿
正文共:1969字
预计阅读时间:5分钟
前段时间小白发了很多关于 Loki 的实践分享,有同学就问了,我该如何把现在运行在 kubernetes 上的容器日志接入到 Loki 里面呢?那么今天小白在这里就主要跟大家分享下loki跟fluentd结合的一些实践。
为什么是Fluentd
Fluentd是一个由云原生基金会(CNCF)管理的统一日志层数据收集器。它可以从多种数据源里采集、处理日志,并集中将它们存储到文件或者数据库当中。其主要的目的也是让你的基础设施能够实现统一的数据收集和分发,以便业务可以更好的使用和理解数据。作为第六个从CNCF里面毕业的项目,fluentd拥有大量的数据处理插件和生产环境的实践指导,同时还有GKE和AWS这样公有云大厂应用为其背书,小白毅然的选择了fluentd作为我们kubernetes上唯一日志采集器。

Loki插件
Loki为fluetnd提供了一个输出插件fluent-plugin-grafana-loki,它可以将采集到的日志传送到Loki实例当中。当然,在实际的应用当中,还需需要我们自己去构建fluentd的docker镜像, 那么我们需要将下面几行加入到自己的dockerfile里面
# 必要的loki输出插件和kubernetes元数据插件
gem install fluent-plugin-grafana-loki
gem install fluent-plugin-kubernetes_metadata_filter
# 小白建议安装的prometheus,字段修改和tag修改插件
gem install fluent-plugin-prometheus
gem install fluent-plugin-record-modifier
gem install fluent-plugin-rewrite-tag-filter
采集流程
按照Kubernetes上运行应用的日志一般建议
应用不应继续把日志输出到本地文件,而应该输出到 stdout 和 stderr;
集群应该针对容器的 stdout、stderr 提供统一的日志采集,建议使用 Daemonset 而非 Sidecar;
进行日志采集的同时,集群应提供 ES、Loki 或其它类似机制来对日志进行处理,并且其处理和存储能力应该有初步预案;
应用日志应提供分级开关,保证同一镜像在不同环境中可以输出不同数量和级别的日志信息。
小白将fluentd在k8s上的采集流程设计如下: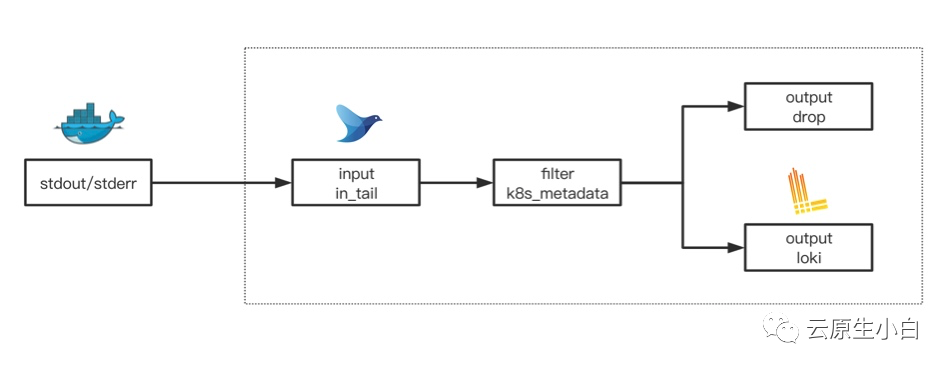
Pre Input阶段
默认情况下docker会将容器的stdout/stderr日志重定向到/var/lib/docker/containers,其日志也为json格式如下
{
"log":"xxxxxxxxxxx",
"stream":"stdout",
"time":"2020-09-15T23:09:04.902156725Z"}
对于将fluentd部署在node上的同学则需要将node的这个目录映射到容器内。
# fluentd的workerload中关于映射容器标准输入的volume
...
volumeMounts:
- mountPath: /var/lib/docker/containers
name: varlibdockercontainers
volumes:
- hostPath:
path: /var/lib/docker/containers
name: varlibdockercontainers
...
Input阶段
在采集阶段, 利用fluentd的in_tail插件对docker标准输出采集即可,参照如下:
@type tail
@id input.containers.out
path /var/log/containers/*.log
exclude_path ["/var/log/containers/*fluentd*.log"]
pos_file /var/log/fluentd/container.out.pos
limit_recently_modified 86400
read_from_head true
tag kubernetes.*
@type json
time_key time
time_format %Y-%m-%dT%H:%M:%S.%NZ
utc true
Fluentd可以通过定义
@type tail
@id input.containers.out.0
path /var/log/containers/*[0-7].log
exclude_path ["/var/log/containers/*fluentd*.log"]
pos_file /var/log/fluentd/container.out.pos.0
limit_recently_modified 86400
read_from_head true
tag kubernetes.*
@type json
time_key time
time_format %Y-%m-%dT%H:%M:%S.%NZ
utc true
@type tail
@id input.containers.out.1
path /var/log/containers/*[8-f].log
exclude_path ["/var/log/containers/*fluentd*.log"]
pos_file /var/log/fluentd/container.out.pos.1
limit_recently_modified 86400
read_from_head true
tag kubernetes.*
@type json
time_key time
time_format %Y-%m-%dT%H:%M:%S.%NZ
utc true
提醒,默认情况下docker没有对容器标准输出的日志存储空间做限制。但实际情况下,我们为了避免生产环境容器日志占满服务器磁盘,会通过修改docker daemon的启动参数
--log-opt=10G来限制容器的最大输出日志空间。这里对于fluentd来说,如果在采集停滞时间内容器的日志桶被完全轮转,那么就会出现日志丢失的风险。对于该如何调整参数,小白建议按照大家自己公司情况合理规划即可。
Filter阶段
Filter阶段主要用来处理日志采集之后的kubernetes元数据标注以及修改、提取自定义字段,这里面主要用了两个插件fluent-plugin-kubernetes_metadata_filter和fluent-plugin-record-modifier来处理以上逻辑。
kubernetes_metadata主要作用为提取tag中的关键信息来向kubernetes查询Pod和Namespace上的Label,并将其添加到日志的json结构体内,它的配置可参照如下:
>
@type kubernetes_metadata
@id kubernetes_metadata_container_out
skip_container_metadata true
skip_master_url true
cache_size 3000
cache_ttl 1800
>
metadata插件有Cache的机制,大家根据自己集群的规模合理调整cache的容量和cache的过期时间。正常情况下,metadata插件会watch k8s api来更新cache,如果出现新部署的容器日志没有相关标签,那么你可能需要
再等一会或者重启fluentd客户端可以解决
record_modifier主要用于提取和修改kubernetes元数据标签,修改成我们自定义的字段,这些字段可以为后面存储在Loki的里面的Label提前建立好索引规则。这部分可参考小白下面的配置:
>
@type record_modifier
@id label.container.out
tag ${record.dig('k8s_std_collect') ? 'loki.kubernetes.var.log.containers' : 'dropped.var.log.containers'}
>
k8s_container_id ${record.dig("docker", "container_id")}
k8s_cloud_cluster "#{ENV['CLOUD_CLUSTER'] || 'default'}"
k8s_node ${record.dig('kubernetes', 'host')}
k8s_container_name ${record.dig('kubernetes', 'container_name')}
k8s_app_name ${record.dig('kubernetes', 'labels', 'app_kubernetes_io/name')}
k8s_svc_name ${record.dig('kubernetes', 'labels', 'app')}
k8s_pod_name ${record.dig('kubernetes', 'pod_name')}
k8s_namespace_name ${record.dig('kubernetes', 'namespace_name')}
k8s_image_version ${record.dig('kubernetes', 'labels', 'app_image_version')}
k8s_std_collect ${record.dig("kubernetes", "labels", "log-collect") or false}
formated_time "${Time.at(time).to_datetime.iso8601(9)}"
fluentd_worker "#{worker_id}"
>
remove_keys docker,kubernetes //删除原生metadata字段
>
大部分情况下,我们对运行在kubernetes里面的workerload都有自己特定的labels规范,并且这部分内容通常被CD系统集成在发布模板当中。这里大家可以按照自己公司情况构建日志索引结构,当然你可以参考小白定的label规范:
...
metadata:
labels:
app: //组件名
app.kubernetes.io/name: //应用名
app.kubernetes.io/version: //应用版本
spec:
template:
metadata:
labels:
app:
app.image.version:
app.kubernetes.io/name:
log-collect: "true" //日志采集开关
...
注意:
log-collect可以灵活控制容器是否需要做日志采集,如果不需要控制,可以忽略此标签,同时还需修改record_modifier中的tag处理逻辑如下tag loki.kubernetes.var.log.containers
Output阶段
在此阶段,基本上由fluentd采集的日志已经完成了索引构建,我们只需匹配相关的tag将其转发指定的上游数据服务即可,这里我们当然用fluent-plugin-grafana-loki插件将日志抓发给Loki存储。
loki插件提供了比较丰富label和buffer参数调试,这里关于Loki的label小白可以直接采用按照前面自定义规则里面的标签即可,参照如下:
>
@type loki
@id loki.output
url "http://loki:3100"
remove_keys topic,k8s_std_collect,formated_time,k8s_container_id
drop_single_key true
>
stream
k8s_cloud_cluster
k8s_container_name
k8s_node
k8s_app_name
k8s_svc_name
k8s_pod_name
k8s_image_version
k8s_namespace_name
>
>
@type file
path /var/log/fluentd-buffers/loki.buffer
flush_mode interval
flush_thread_count 4
flush_interval 3s
retry_type exponential_backoff
retry_wait 2s
retry_max_interval 60s
retry_timeout 12h
chunk_limit_size 8M
total_limit_size 5G
queued_chunks_limit_size 64
overflow_action drop_oldest_chunk
>
>
关于Buffer的配置,大部分情况下我们可以不用关心,不过你还记得前面小白说的关于docker日志桶的参数配置不当引起丢失日志的风险吗?这里的buffer配置可以根据情况缓解这类问题
走到这里我们基本完成了在k8s上较为云原生方式的日志采集架构。另外值得一提的是,Loki本身支持对多租户日志分级存储,如若你的kubernetes平台是基于多租户管理的,那么你可以将租户信息提取出来引入到loki当中。
K8S进阶训练营,点击下方图片了解详情
