
悲观锁和乐观锁的那些事儿
本文公众号来源:鄙人薛某
作者:很懒的程序员
本文已收录至我的GitHub
线程安全
线程安全是程序开发中非常需要我们注意的一环,当程序存在并发的可能时,如果我们不做特殊的处理,很容易就出现数据不一致的情况。
通常情况下,我们可以用加锁的方式来保证线程安全,通过对共享资源 (也就是要读取的数据) 的加上"隔离的锁",使得多个线程执行的时候也不会互相影响,而悲观锁和乐观锁正是并发控制中较为常用的技术手段。
乐观锁和悲观锁
什么是悲观锁?什么是乐观锁?其实从字面上就可以区分出两者的区别,通俗点说,
悲观锁
悲观锁就好像一个有迫害妄想症的患者,总是假设最坏的情况,每次拿数据的时候都以为别人会修改,所以每次拿数据的时候都会上锁,直到整个数据处理过程结束,其他的线程如果要拿数据就必须等当前的锁被释放后才能操作。
使用案例
悲观锁的使用场景并不少见,数据库很多地方就用到了这种锁机制,比如行锁,表锁,读锁,写锁等,都是在做操作之前先上锁,悲观锁的实现往往依靠数据库本身的锁功能实现。Java程序中的Synchronized和ReentrantLock等实现的锁也均为悲观锁。
在数据库中,悲观锁的调用一般是在所要查询的语句后面加上 for update,
select * from db_stock where goods_id = 1 for update当有一个事务调用这条 sql 语句时,会对goods_id = 1 这条记录加锁,其他的事务如果也对这条记录做 for update 的查询的话,那就必须等到该事务执行完后才能查出结果,这种加锁方式能对读和写做出排他的作用,保证了数据只能被当前事务修改。
当然,如果其他事务只是简单的查询而没有用 for update的话,那么查询还是不会受影响的,只是说更新时一样要等待当前事务结束才行。
值得注意的是,MySQL默认使用autocommit模式,也就是说,当你执行一个更新操作后,MySQL会立刻将结果进行提交,就是说,如果我们不仅要读,还要更新数据的话,需要手动控制事务的提交,比如像下面这样:
set autocommit=0;//开始事务begin;//查询出商品id为1的库存表数据select * from db_stock where goods_id = 1 for update;//减库存update db_stock set stock_num = stock_num - 1 where goods_id = 1 ;//提交事务commit;
虽然悲观锁能有效保证数据执行的顺序性和一致性,但在高并发场景下并不适用,试想,如果一个事务用悲观锁对数据加锁之后,其他事务将不能对加锁的数据进行除了查询以外的所有操作,如果该事务执行时间很长,那么其他事务将一直等待,这无疑会降低系统的吞吐量。
这种情况下,我们可以有更好的选择,那就是乐观锁。
乐观锁
乐观锁的思想和悲观锁相反,总是假设最好的情况,认为别人都是友好的,所以每次获取数据的时候不会上锁,但更新数据那一刻会判断数据是否被更新过了,如果数据的值跟自己预期一样的话,那么就可以正常更新数据。
场景
这种思想应用到实际场景的话,可以用版本号机制和CAS算法实现。
CAS
CAS是一种无锁的思想,它假设线程对资源的访问是没有冲突的,同时所有的线程执行都不需要等待,可以持续执行。如果遇到冲突的话,就使用一种叫做CAS (比较交换) 的技术来鉴别线程冲突,如果检测到冲突发生,就重试当前操作到没有冲突为止。
原理
CAS的全称是Compare-and-Swap,也就是比较并交换,它包含了三个参数:V,A,B,V表示要读写的内存位置,A表示旧的预期值,B表示新值
具体的机制是,当执行CAS指令的时候,只有当V的值等于预期值A时,才会把V的值改为B,如果V和A不同,有可能是其他的线程修改了,这个时候,执行CAS的线程就会不断的循环重试,直到能成功更新为止。
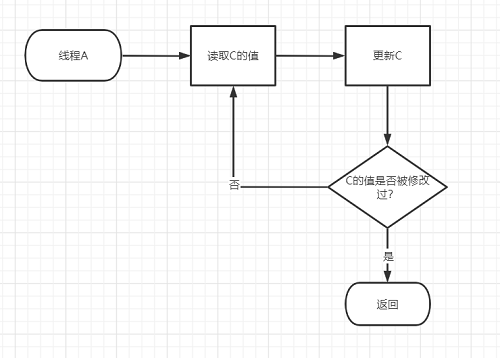
正是基于这样的原理,CAS即时没有使用锁,也能发现其他线程对当前线程的干扰,从而进行及时的处理。
缺点
CAS算是比较高效的并发控制手段,不会阻塞其他线程。但是,这样的更新方式是存在问题的,看流程就知道了,如果C的结果一直跟预期的结果不一样的话,线程A就会一直不断的循环重试,重试次数太多的话对CPU也是一笔不小的开销。
而且,CAS的操作范围也比较局限,只能保证一个共享变量的原子操作,如果需要一段代码块的原子性的话,就只能通过Synchronized等工具来实现了。
除此之外,CAS机制最大的缺陷就是"ABA"问题。
ABA问题
前面说过,CAS判断变量操作成功的条件是V的值和A是一致的,这个逻辑有个小小的缺陷,就是如果V的值一开始为A,在准备修改为新值前的期间曾经被改成了B,后来又被改回为A,经过两次的线程修改对象的值还是旧值,那么CAS操作就会误任务该变量从来没被修改过,这就是CAS中的“ABA”问题。
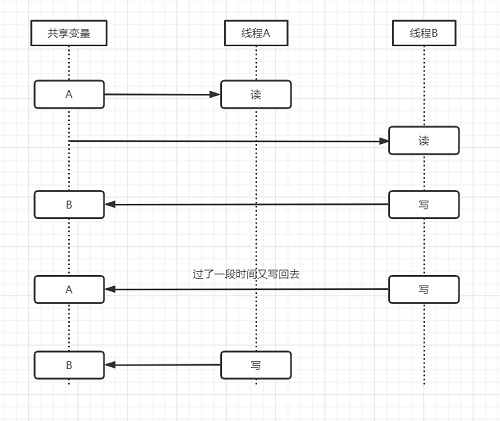
看完流程图相信也不用我说太多了吧,线程多发的情况下,这样的问题是非常有可能发生的,那么如何避免ABA问题呢?
加标志位,例如搞个自增的字段,没操作一次就加一,或者是一个时间戳,每次更新比较时间戳的值,这也是数据库版本号更新的思想(下面会说到)
在Java中,自JDK1.5以后就提供了这么一个并发工具类AtomicStampedReference,该工具内部维护了一个内部类,在原有基础上维护了一个对象,及一个int类型的值(可以理解为版本号),在每次进行对比修改时,都会先判断要修改的值,和内存中的值是否相同,以及版本号是否相同,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
private static class Pair{ final T reference;final int stamp;private Pair(T reference, int stamp) {this.reference = reference;this.stamp = stamp;}staticPair of(T reference, int stamp) { return new Pair(reference, stamp); }}
适用场景
CAS一般适用于读多写少的场景,因为这种情况线程的冲突不会太多,也只有线程冲突不严重的情况下,CAS的线程循环次数才能有效的降低,性能也能更高。
版本号机制
版本号机制是数据库更新操作里非常实用的技巧,其实原理很简单,就是获取数据的时候会拿一个能对应版本的字段,然后更新的时候判断这个字段是否跟之前拿的值是否一致,一致的话证明数据没有被别人更新过,这时就可以正常实现更新操作。
还是上面的那张表为例,我们加上一个版本号字段version,然后每次更新数据的时候就把版本号加1,
select goods_id,stock_num,version from db_stock where goods_id = 1update db_stock set stock_num = stock_num - 1,version = version + 1 where goods_id = 1 and version = #{version}
这样的话,如果有两个事务同时对goods_id = 1这条数据做更新操作的话,一定会有一个事务先执行完成,然后version字段就加1,另一个事务更新的时候发现version已经不是之前获取到的那个值了,就会重新执行查询操作,从而保证了数据的一致性。
这种锁的方式也不会影响吞吐量,毕竟大家都可以同时读和写,但高并发场景下,sql更新报错的可能性会大大增加,这样对业务处理似乎也不友好。
这种情况下,我们可以把锁的粒度缩小,比如说减库存的时候,我们可以这么处理:
update db_stock set stock_num = stock_num - 1 where goods_id = 1 and stock_num > 0这样一来,sql更新冲突的概率会大大降低,而且也不用去单独维护类似version的字段了。
最后
关于悲观锁和乐观锁的例子介绍就到这儿了,当然,本文也只是略微讲解,更多的知识点还要靠大家研究,而且,除了这两种锁,并发控制中还有很多其他的控制手段,像什么Synchronized、ReentrantLock、公平锁,非公平锁之类的都是很常见的并发知识,不管是为了日常开发还是应付面试,掌握这些知识点还是很有必要的,而且,并发编程的知识思想是共通的,知道一块知识点后很容易就能延伸去学习其他的知识点。
添加我的微信进一步交流和学习
如果显示频繁,微信手动搜索【sanwaiyihao】添加即可
点亮在看和转发是我持续更新的动力,对我真的很重要!