
独家 | 使用TensorFlow 2创建自定义损失函数

作者:Arjun Sarkar
翻译:陈之炎
校对:欧阳锦
均方误差;
均方对数误差;
二元交叉熵;
分类交叉熵;
稀疏分类交叉熵。
model.compile (loss = ‘binary_crossentropy’,optimizer = ‘adam’, metrics = [‘accuracy’])from tensorflow.keras.losses importmean_squared_errormodel.compile(loss = mean_squared_error,optimizer=’sgd’)
from tensorflow.keras.losses import mean_squared_errormodel.compile (loss=mean_squared_error(param=value),optimizer = ‘sgd’)
利用现有函数创建自定义损失函数:
def loss_function(y_true, y_pred):***some calculation***return loss
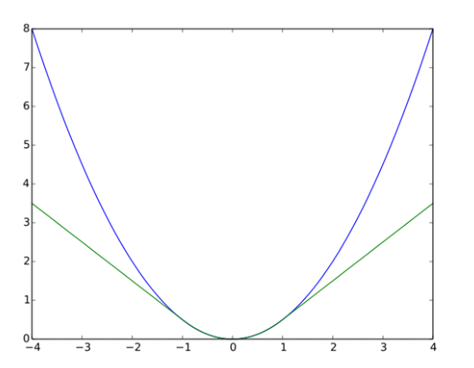
创建均方误差损失函数 (RMSE):
误差:真实标签与预测标签之间的差异。
sqr_error:误差的平方。
mean_sqr_error:误差平方的均值。
sqrt_mean_sqr_error:误差平方均值的平方根(均方根误差)。

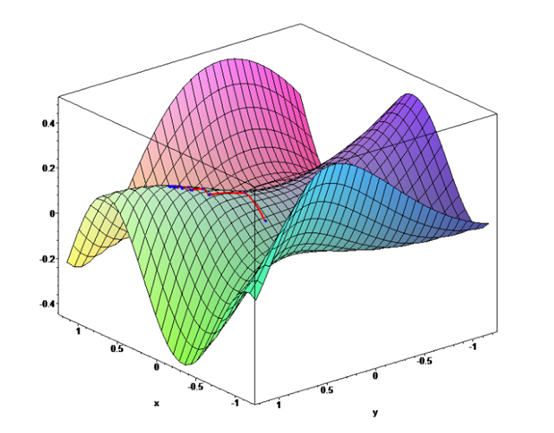
创建Huber损失函数:


使用封装后的Huber损失函数


使用类实现Huber损失函数(OOP)

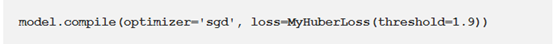
创建对比性损失(用于Siamese网络):
使用封装器函数实现对比损失函数:

结论
译者简介

陈之炎,北京交通大学通信与控制工程专业毕业,获得工学硕士学位,历任长城计算机软件与系统公司工程师,大唐微电子公司工程师,现任北京吾译超群科技有限公司技术支持。目前从事智能化翻译教学系统的运营和维护,在人工智能深度学习和自然语言处理(NLP)方面积累有一定的经验。业余时间喜爱翻译创作,翻译作品主要有:IEC-ISO 7816、伊拉克石油工程项目、新财税主义宣言等等,其中中译英作品“新财税主义宣言”在GLOBAL TIMES正式发表。能够利用业余时间加入到THU 数据派平台的翻译志愿者小组,希望能和大家一起交流分享,共同进步。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。
点击“阅读原文”拥抱组织