
复杂动态环境下的多模态语义SLAM
0. 引言
SLAM算法在自动驾驶、机器人导航、AR、VR等任务中越来越重要,但许多现有的SLAM算法都假定环境是静态的,不能很好地处理动态环境,这就限制了SLAM算法的实际应用。在论文"Multi-modal Semantic SLAM for Complex Dynamic Environments"中,作者提出了一种动态环境中的多模态语义SLAM,并在仓储环境中针对移动的人和AGV车辆进行了算法验证。重要的是,算法已经开源。
1. 论文信息
标题:Multi-modal Semantic SLAM for Complex Dynamic Environments
作者:Han Wang, Jing Ying Ko, Lihua Xie
来源:2022 Robotics
原文链接:https://arxiv.org/abs/2205.04300
代码链接:https://github.com/wh200720041/MMS_SLAM
2. 摘要
同时定位和建图(SLAM)是许多现实机器人应用中最重要的技术之一。大多数SLAM算法都假设静态环境,然而对于大多数应用来说并非如此。语义SLAM的最新工作旨在通过执行基于图像的分割来理解环境中的对象并从场景上下文中区分动态信息。然而,分割结果通常是不完美或不完整的,这可能随后降低建图质量和定位准确性。在本文中,我们提出了一个鲁棒的多模态语义框架来解决复杂和高度动态环境中的SLAM问题。我们建议学习更强大的对象特征表示,并将两次查看和思考的机制部署到主干网络,这导致对我们的基线实例分割模型的更好的识别结果。此外,将仅几何聚类和视觉语义信息相结合,以减少由于小尺度对象、遮挡和运动模糊导致的分割错误的影响。我们已经进行了全面的实验来评估所提出的方法的性能。结果表明,我们的方法可以准确识别缺陷和运动模糊下的动态目标。此外,所提出的SLAM框架能够以超过10 Hz的处理速率有效地构建静态稠密地图,这可以在许多实际应用中实现。
3. 算法分析
如图1所示是作者提出的多模态语义SLAM框架AM框架中,该框架能够在不同的动态环境中提供实时定位,并解决由于误分类、小尺度目标和遮挡造成的分割错误。具体来说,作者修改了现有的主干网络,以学习更强大的对象特征表示,并在主干网络中部署了两次查看和思考的机制,提升了实力分割的性能。此外,作者结合几何聚类和视觉语义信息来减少运动模糊的影响。
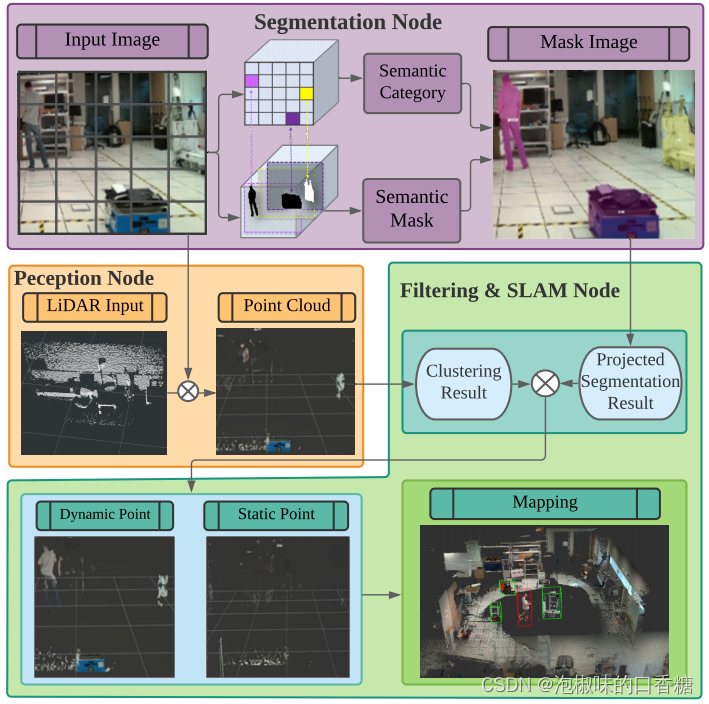
图1 多模态语义SLAM框架概述
作者的主要贡献总结如下:
(1) 作者提出了一个鲁棒快速的多模态语义SLAM框架,旨在解决复杂动态环境中的SLAM问题。具体来说,作者将几何聚类和视觉语义信息相结合,以减少由于小尺度对象、遮挡和运动模糊导致的分割错误的影响。
(2) 作者提出的网络可以学习更强大的对象特征表示,并将两次查看和思考的机制部署到主干网络,这使得实例分割模型获得了更好的识别结果。
(3) 作者对所提出的方法进行了全面的评价。结果表明,该方法能够提供可靠的定位和语义稠密地图。
3.1 框架流程
如图2所示是作者提出的多模态语义SLAM流程图,它主要由四个模块组成,即实例分割模块、多模态融合模块、定位模块和全局优化及建图模块。实例分割模块使用实时实例分割网络来提取RGB图像中存在的所有潜在动态对象的语义信息。卷积神经网络离线训练,然后在线实现,以达到实时性能。同时,多模态融合模块通过传感器融合将相关语义数据传输到激光雷达,并随后使用多模态信息来进一步加强分割结果。在定位模块中使用静态信息来寻找机器人姿态,而在全局优化和建图模块中使用静态信息和动态信息来建立3D稠密语义地图。
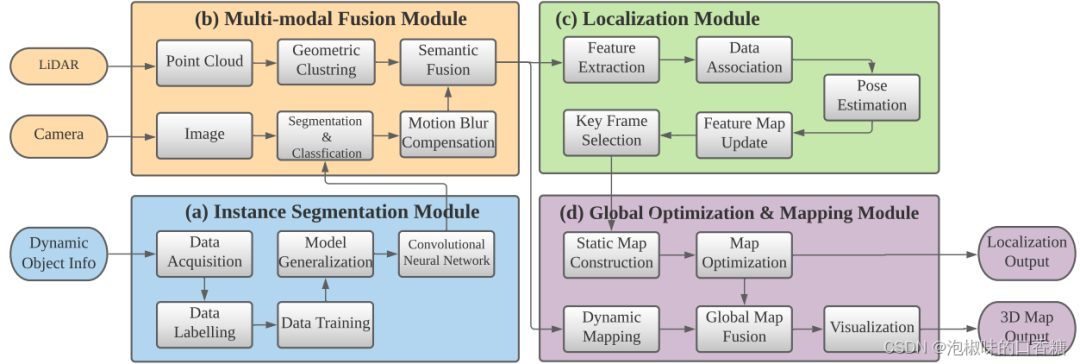
图2 多模态语义SLAM流程图
3.2 实例分割网络
为了降低实例分割的计算成本,作者使用精度较低的轻量级版本SOLOv2来实现实时实例分割。为了提高分割精度,作者将主干架构从最初的特征金字塔网络(FPN)修改为递归特征金字塔网络(RFP)。RFP通过将来自FPN的额外反馈整合到自下而上的主干层中,并灌输了两次或多次查看的思想。这递归地增强了现有的FPN,并提供了越来越强的特征表示。同时,RFP自适应增强和抑制神经元激活的能力使得实例分割网络能够更有效地处理被遮挡的对象。此外,作者使用SAC (Switchable Atrous Convolution)代替主干架构中的卷积层。SAC可以收集不同速率卷积计算的输出,因此能够从SAC中学习最佳系数,并且能够自适应地选择感受野的大小。这使得SOLOv2能够高效地提取重要的空间信息。
实例分割网络的输出是每个动态对象的像素级实例掩码,以及它们对应的边界框和类型。为了更好地将动态信息集成到SLAM算法中,作者将输出的二进制掩码转换为包含场景中所有像素级实例掩码的单个图像,进而区分静态与动态物体。然后将二值掩码应用于语义融合模块,生成一个三维动态掩码。
3.3 多模态融合
为了解决运动模糊效应,作者首先进行形态学膨胀处理,用于逐渐扩展动态对象的区域边界。形态学膨胀结果标记了动态对象周围的模糊边界。作者将动态对象及其边界作为动态信息,进而进行运动模糊补偿。
此外,因为区域之间的模糊像素会导致分割错误。因此,作者结合点云聚类结果和分割结果来更好地细化动态对象。具体来说,作者对几何信息执行连通性分析,并与基于视觉的分割结果融合。
最后,为了提高分割网络的工作效率,作者首先对激光雷达采集到的三维点云进行降维处理以减少数据规模,并将其作为点云聚类的输入。然后将实例分割结果投影到点云坐标上标记每个点,当大多数点(90%)是动态标记点时,点云聚类将被视为动态聚类。当静态点靠近动态点聚类时,静态点将被重新标记为动态标签。并且当附近没有动态点云时,动态点将被重新标记。
3.4 定位及位姿估计
应用多模态动态分割后,算法将点云分为动态点云和静态点云,静态点云被用于定位和建图模块。与LOAM相比,作者提出的框架能够支持30Hz的实时性能。与ORB-SLAM和VINS-MONO,它能抵抗照明变化。
然后进行数据关联和姿态估计,即通过最小化点到边和点到平面距离计算最终机器人姿态,并通过最小化点对平面和点对边的残差之和来计算最终的机器人姿态。在非线性最小二乘的求解上,作者使用高斯-牛顿方法,并基于静态信息推导出一个最优的机器人姿态。
最后进行特征图更新和关键帧选择。一旦导出最佳姿态,特征将分别更新为局部边缘图和局部平面图,用于下一帧的数据关联。为了降低计算成本,全局静态映射将根据关键帧进行更新。关键帧的生成策略为:当机器人姿态的平移变化大于预定义的平移阈值,或机器人姿态的旋转变化大于预定义的旋转阈值时,将生成一个关键帧。
3.5 全局地图构建
语义地图分为静态地图和动态地图,具体来说,视觉信息可以通过将三维点重新投影到图像平面上来实现。每次更新后,通过使用三维体素化网格对映射进行降采样,以防止内存溢出。动态地图由动态点云构建,并用于显示动态对象。生成的动态地图可用于运动规划等高级任务。
4. 实验
在实验设备方面,作者选用ROS作为语义模块和SLM算法的接口,传感器采用英特尔RealSense雷达相机L515捕捉RGB图像和点云,数据处理在英特尔i7 CPU和RTX 2080 Ti GPU上进行。
在动态物体的选择上,作者主要识别仓储环境中的人体以及AGV车辆,如图3所示是作者用于训练网络的不同AGV车辆模型。此外,为了解决小数据集问题,作者使用随机尺度抖动等数据增强方法,提高网络的鲁棒性。

图3 训练集中不同类型的agv
(a)机械臂AGV;(b)叉车AGV;(c)扫描AGV;(d)先锋机器人;(e)带输送带的运输AGV;(f)仓库环境;
4.1 实例分割性能评估
作者首先在COCO数据集上分别从分割损失和平均精度(mAP)两方面评估分割性能。在网络搭建上,作者基于MMDetection 2.0构建实例分割网络Solo v2,并在由81个类组成的COCO数据集上训练。同时选择ResNet-50作为主干架构,并使用在ImageNet上预训练的ResNet-50,结果如表1所示。
表1 实例分割的性能对比
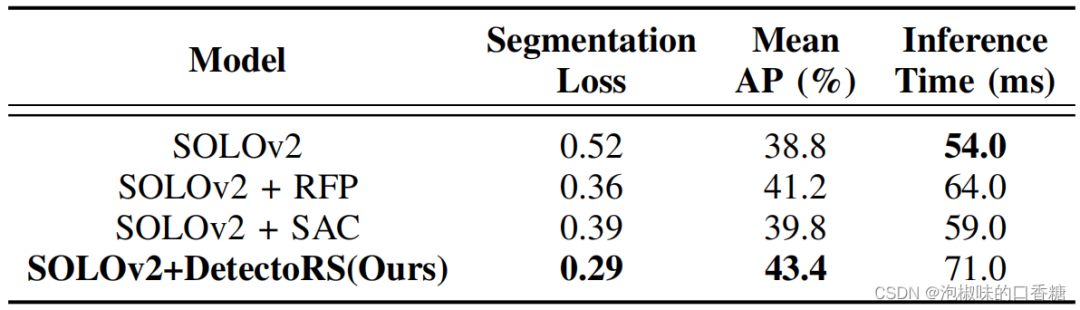
结果显示,通过在Solo v2上部署SAC和RFP网络,分割性能进一步提高了5.9%,而时间仅增加了17 ms。总的来说,Solo v2通过自适应感受野学习两次查看图像,因此它能够突出实例分割网络的重要语义信息。分割的可视化结果如图4所示,验证了作者提出的方法实现了更高的准确性。

图4 原始Solo v2与作者方法的对比
4.2 稠密建图和动态跟踪
在具体实验中,当人类操作员在仓库中频繁走动时,手动控制AGV移动并同时建立仓库环境地图。定位结果如图5所示。其中作者比较了真值、作者使用的SLAM方法和原始SLAM。可以看出,作者提出的多模态语义SLAM比传统SLAM更加鲁棒和稳定。建图结果如图6所示,该方法能够有效地识别出潜在的动态对象,并将其从静态地图中分离出来。建图结果显示,尽管操作人员经常走在机器人前面,但他们未在静态地图中出现。所有潜在的动态对象都被包围在边界框中,并被添加到最终的语义地图中,以实时可视化每个对象的状态,其中移动的人被着色为红色,而AGV被着色为绿色。此外,作者提出的方法能够在复杂的动态环境中识别和定位多个目标。
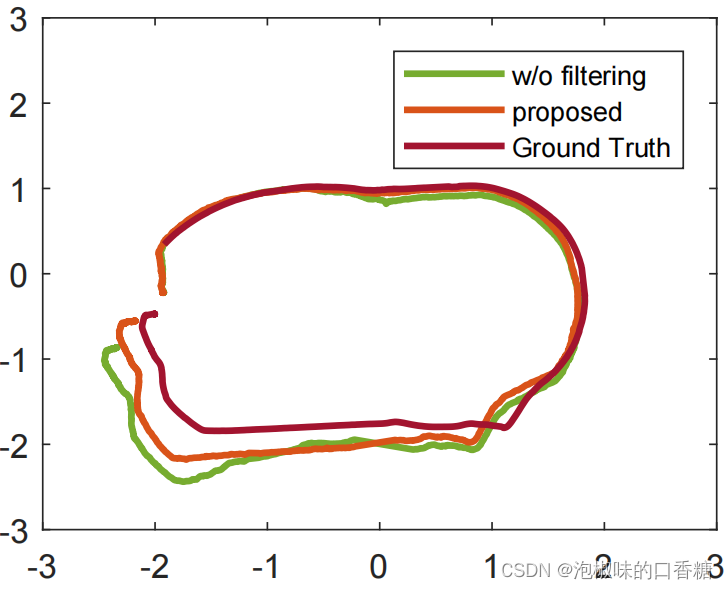
图5 动态环境中的定位结果对比

图6 静态地图创建和最终语义建图结果
(a)由所提出的SLAM框架构建的静态地图;(b)最终的语义建图结果
4.3 消融实验
作者比较了不同动态滤波方法的定位漂移。首先从SLAM中移除语义识别模块,并对其性能进行评估。然后,使用视觉语义识别(Solo v2)来移除动态信息,将结果与提出的语义多模态SLAM进行比较。具体实验方法为,首先让机器人保持静止,并让一名人类操作员在机器人前面频繁行走,记录定位漂移,以便评估在动态对象下的性能。然后计算平均平移漂移误差(ATDE)和最大平移漂移误差(MTDE)来验证定位,定量结果如表2所示,可视化结果如图7所示。可以看出,与原始SLAM相比,作者提出的方法显著降低了定位漂移。
表2 动态环境下的定位漂移消融实验


图7 定位漂移的消融实验
(a)原始图像;(b)视觉语义识别结果;(c) 由于运动的对象的定位漂移,局部漂移用红色圆圈突出显示
5. 结论
在论文"Multi-modal Semantic SLAM for Complex Dynamic Environments"中,作者提出了一个语义多模态框架来解决动态环境中的SLAM问题,能够有效地减少复杂动态环境中动态对象的影响,并进行稠密建图。作者还在用于智能制造的仓储AGV上进行了评估,实验结果表明作者提出的方法显著提高了现有SLAM算法的鲁棒性和准确性。