
我用深度学习做个视觉AI微型处理器!
讲多了算法,如何真正将算法应用到产品领域?本文将带你从0用深度学习打造一个视觉AI的微型处理器。文章含完整代码,知识点相对独立,欢迎点赞收藏,跟着本文做完,你也可以做一个自己的嵌入式AI小产品!
属于AI人的硬核快乐
背景
随着硬件尤其是显卡性能升级,以及Pytorch,TensorFlow深度学习框架日趋完善,视觉AI算法在多个领域遍地开花,其中就包括嵌入式设备。这是一种微型处理器,它的关键单元就是内部小小的计算芯片。嵌入式设备和我们日常用的电脑相比体积小,只包含必要外设。一些针对特定任务的嵌入式设备往往不会运载我们常用的比如Windows、Linux系统,而是直接将代码烧录进去运行。
在嵌入式设备上尝试部署深度学习算法开始较早,1989年一家叫做ALVIVN的公司就将神经网络用在汽车上了。现如今,工程师们将其用在安防、机器人、自动驾驶等领域。因此,懂得如何设计、训练算法,又能将其部署到边缘硬件产品上,能帮我们实现许多产品的想法。
但是,视觉算法部署在产品中仍有许多难点,比如:(1)模型通常需要在CPU/GPU/NPU/FPGA等各种各样不同类型的平台上部署;(2)嵌入式算力/内存/存储空间都非常有限;跑在云端服务器上,需要实时联网又不很优雅;(3)模型训练时可能会使用不同的AI框架(比如Pytorch/TensorFlow等)、不同硬件(比如GPU、NPU),相互适配产生问题[1]。
因此笔者开始思考下列问题:
有什么亲民价格的芯片能处理部署视觉AI算法? 如何将深度学习算法部署到嵌入式设备上?
对第一个问题,在经过调研后,还真有这样的芯片,那就是嘉楠科技的K210芯片。一个芯片几十元,对应的开发板在某宝上两百多就可以买到。根据嘉楠官方的描述,K210具有双核 64-bit RISC-V RV64IMAFDC (RV64GC) CPU / 400MHz(可超频到600MHz),双精度 FPU,8MiB 64bit 片上 SRAM(6MiB通用SRAM+2MiB的AI专用SRAM)。关于这块芯片更详细的介绍可以参考[2] 。

市面上有许多搭载K210的开发板,笔者这里选了雅博一款功能较全的K210开发板,开始了嵌入式AI的折腾之路。

对于第二个问题,方法就多了,不同深度学习框架,不同硬件选型都决定着不同技术路线。基本路线可以为深度学习平台训练 -> 模型剪枝、量化 -> 参数转换 ->转换为硬件平台上能运行的模型 。
对深度学习平台选型,笔者决定选用当下最流行的Pytorch平台。最后一步往往取决于这个硬件的生态,如果没有相关生态支持,可能需要手写C语言代码加载参数运行。调研发现,K210有一个深度网络优化平台NNCASE,能加速深度模型部署。
调研过程中发现在这块板子上部署模型大多数都是从Keras、TensorFlow开始训练并最终部署,而研究者常用的Pytorch竟然没有教程,于是今天就尝试来讲一讲。
接下来,我们将从使用Pytorch训练手写体识别的例子开始,打通从训练到嵌入式平台部署的流程。
01 使用Pytorch训练分类网络模型
必要软件包安装
pip install tensorbay pillow torch torchvision numpy
数据集获取
一个AccessKey获取所有数据集。
我们使用一个开源数据集平台:https://gas.graviti.com ,这个网站汇总了AI开发者常见的公开数据集,调用其SDK就能直接在线训练,而且许多数据集直接在国内网络下连接直接使用,还是非常方便的。
a. 打开本文对应数据集链接 https://gas.graviti.com/dataset/data-decorators/MNIST
b. 右上角注册登录
c. fork数据集
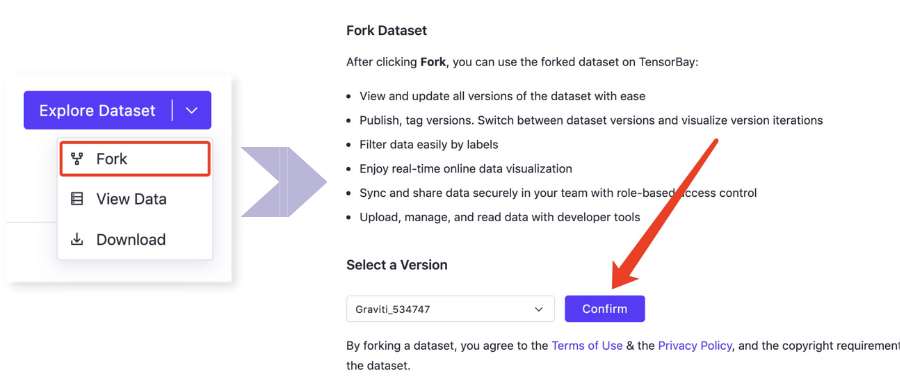
gas_key.py里:KEY = ""
通过AccessKey可以上传数据、读取数据、使用数据,灵活对接模型开发和训练,与数据pipeline快速集成。
e. AccessKey写入后就可以写代码读取数据了,读取后可以使用一行代码自行下载,或者可以开启缓存功能,在读取过后会自动将数据存储到本地。将下载后的数据放在data文件夹下:
import numpy as np
from PIL import Image
from tensorbay import GAS
from tensorbay.dataset import Dataset
from tensorbay.dataset import Segment
def read_gas_image(data):
with data.open() as fp:
image = Image.open(fp)
return np.array(image)
KEY = "用你的Key替换掉这个字符串"
# Authorize a GAS client.
gas = GAS(KEY)
# Get a dataset.
dataset = Dataset("MNIST", gas)
# 开启下行语句在当前路径下的data目录缓存数据
# dataset.enable_cache("data")
# List dataset segments.
segments = dataset.keys()
# Get a segment by name
segment = dataset["train"]
for data in segment:
# 图片数据
image = read_gas_image(data)
# 标签数据
label = data.label.classification.category
怎么把这个数据集集成到Pytorch里呢?官方文档也为此写了不少例子[4]。笔者尝试过觉得挺方便,在为不同任务训练嵌入式AI模型时,只需更换数据集的名字,就能集成,不用再打开浏览器、等待下载以及处理很久了。有了数据集之后,我们接下来用其训练一个分类任务模型。
深度网络模型选型
结合硬件特点设计网络。
在考虑硬件部署的任务时,网络的设计就要受到些许限制。
首先,大而深的模型是不行的,K210的RAM是6M,这意味着模型+程序都要烧到这个空间。当然我们可以放到内存卡中,但实时性要受影响。
其次,还要考虑AI编译器对特定算子的优化,以K210 NNCASE为例[3],其支持TFLite、Caffe、ONNX共三个平台的算子。
打开对应平台,能够到具体有哪些算子已经实现了低层优化。可以看到对ONNX算子优化还是比较多的。如果所选用的网络算子较新,抑或是模型太大,都要在本步多加思考与设计。
如果如果最后部署不成功,往往需要回到这一步考虑网络的设计。为了尽可能减少算子的使用,本文设计一个只基于卷积+ReLU+Pool的CNN:
代码文件名:models/net.py
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(2)
self.conv3 = nn.Conv2d(16, 32, 4)
self.relu3 = nn.ReLU()
self.conv4 = nn.Conv2d(32, 64, 1)
self.relu4 = nn.ReLU()
self.conv5 = nn.Conv2d(64, 32, 1)
self.relu5 = nn.ReLU()
self.conv6 = nn.Conv2d(32, 10, 1)
self.relu6 = nn.ReLU()
def forward(self, x):
y = self.conv1(x)
y = self.relu1(y)
y = self.pool1(y)
y = self.conv2(y)
y = self.relu2(y)
y = self.pool2(y)
y = self.conv3(y)
y = self.relu3(y)
y = self.conv4(y)
y = self.relu4(y)
y = self.conv5(y)
y = self.relu6(y)
y = self.conv6(y)
y = self.relu6(y)
y = y.view(y.shape[0], -1)
return y网络训练
设计好模型后,使用如下脚本进行训练。接下来脚本文件大致浏览一下,明白其中的工作原理即可。
代码文件名:1.train.py
注意将其中的ACCESS_KEY替成你自己的AccessKey。
from __future__ import print_function
import argparse
import torch
import torch.nn.functional as F
import torch.optim as optim
from torch.optim.lr_scheduler import StepLR
from models.net import Net
from PIL import Image
from torch.utils.data import DataLoader, Dataset
from torchvision import transforms
from tensorbay import GAS
from tensorbay.dataset import Dataset as TensorBayDataset
class MNISTSegment(Dataset):
"""class for wrapping a MNIST segment."""
def __init__(self, gas, segment_name, transform, cache=True):
super().__init__()
self.dataset = TensorBayDataset("MNIST", gas)
if cache:
self.dataset.enable_cache("data")
self.segment = self.dataset[segment_name]
self.category_to_index = self.dataset.catalog.classification.get_category_to_index()
self.transform = transform
def __len__(self):
return len(self.segment)
def __getitem__(self, idx):
data = self.segment[idx]
with data.open() as fp:
image_tensor = self.transform(Image.open(fp))
return image_tensor, self.category_to_index[data.label.classification.category]
def create_loader(key):
to_tensor = transforms.ToTensor()
normalization = transforms.Normalize(mean=[0.485], std=[0.229])
my_transforms = transforms.Compose([to_tensor, normalization])
train_segment = MNISTSegment(GAS(key), segment_name="train", transform=my_transforms)
train_dataloader = DataLoader(train_segment, batch_size=4, shuffle=True, num_workers=0)
test_segment = MNISTSegment(GAS(key), segment_name="test", transform=my_transforms)
test_dataloader = DataLoader(test_segment, batch_size=4, shuffle=True, num_workers=0)
return train_dataloader, test_dataloader
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
if args.dry_run:
break
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.cross_entropy(output, target, reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
def main():
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=14, metavar='N',
help='number of epochs to train (default: 14)')
parser.add_argument('--lr', type=float, default=1.0, metavar='LR',
help='learning rate (default: 1.0)')
parser.add_argument('--gamma', type=float, default=0.7, metavar='M',
help='Learning rate step gamma (default: 0.7)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--dry-run', action='store_true', default=False,
help='quickly check a single pass')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--save-model', action='store_true', default=False,
help='For Saving the current Model')
args = parser.parse_args()
use_cuda = not args.no_cuda and torch.cuda.is_available()
torch.manual_seed(args.seed)
device = torch.device("cuda" if use_cuda else "cpu")
train_kwargs = {'batch_size': args.batch_size}
test_kwargs = {'batch_size': args.test_batch_size}
if use_cuda:
cuda_kwargs = {'num_workers': 1,
'pin_memory': True,
'shuffle': True}
train_kwargs.update(cuda_kwargs)
test_kwargs.update(cuda_kwargs)
ACCESS_KEY = 'Accesskey-4669e1203a6fa8291d5d7744ba313f91'
train_loader, test_loader = create_loader(ACCESS_KEY)
model = Net().to(device)
optimizer = optim.Adadelta(model.parameters(), lr=args.lr)
scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma)
for epoch in range(1, args.epochs + 1):
train(args, model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)
scheduler.step()
if args.save_model:
torch.save(model.state_dict(), "outputs/mnist.pt")
if __name__ == '__main__':
main()
运行方式:
打开终端
mkdir -p outputs
python 1.train.py --save-model
运行结果:
Train Epoch: 1 [0/60000 (0%)] Loss: 2.305400
Train Epoch: 1 [640/60000 (1%)] Loss: 1.359776
....
训练完毕,在outputs文件下有mnist.pt模型文件。
02 参数转换
Pytorch模型导出为ONNX
“各家都有一套语言,换到一个标准再说话”。
开放神经网络交换(Open Neural Network Exchange,简称ONNX)是微软和Facebook提出用来表示深度学习模型的开放格式。所谓开放就是ONNX定义了一组和环境,平台均无关的标准格式,来增强各种AI模型的可交互性。
换句话说,无论你使用何种训练框架训练模型(比如TensorFlow /Pytorch /OneFlow /Paddle),在训练完毕后你都可以将这些框架的模型统一转换为ONNX这种统一的格式进行存储。注意ONNX文件不仅仅存储了神经网络模型的权重,同时也存储了模型的结构信息以及网络中每一层的输入输出和一些其它的辅助信息。
ONNX开源在了[5],笔者也为大家准备了一些参考学习资料,可参考[5-10]进行学习。
Pytorch平台训练好模型后,使用下列脚本将模型转化为ONNX:
首先安装用到的包为:
pip install onnx coremltools onnx-simplifier
脚本名称:2.pt2onnx.py
from models.net import Net
import torch.onnx
import os
def parse_args():
import argparse
parser = argparse.ArgumentParser(description='PyTorch pt file to ONNX file')
parser.add_argument('-i', '--input', type=str, required=True)
return parser.parse_args()
def main():
args = parse_args()
dummy_input = torch.randn(1, 1, 28, 28)
model = Net()
print("Loading state dict to cpu")
model.load_state_dict(torch.load(args.input, map_location=torch.device('cpu')))
name = os.path.join(os.path.dirname(args.input), os.path.basename(args.input).split('.')[0] + ".onnx")
print("Onnx files at:", name)
torch.onnx.export(model, dummy_input, name)
if __name__ == '__main__':
main()
运行方式:
python3 2.pt2onnx.py -i outputs/mnist.pt
运行结果:
Loading state dict to cpu
Onnx files at: outputs/mnist.onnx
运行完毕,在outputs文件可发现已将pt模型转为mnist.onnx模型文件。
ONNX模型转化成KModel
使用NNCASE将ONNX模型转为K210上能运行的KModel,由于NNCASE环境配置较为依赖环境,我们使用Docker完成环境配置,对于docker只需要安装并正确配置即可,不熟悉的可以参考我写的Docker教程[12]。
代码文件:3.onnx2kmodel.py
import os
import onnxsim
import onnx
import nncase
def parse_args():
import argparse
parser = argparse.ArgumentParser(description='ONNX file to KModel')
parser.add_argument('-i', '--input', type=str, required=True)
return parser.parse_args()
def parse_model_input_output(model_file):
onnx_model = onnx.load(model_file)
input_all = [node.name for node in onnx_model.graph.input]
input_initializer = [node.name for node in onnx_model.graph.initializer]
input_names = list(set(input_all) - set(input_initializer))
input_tensors = [node for node in onnx_model.graph.input if node.name in input_names]
# input
inputs = []
for _, e in enumerate(input_tensors):
onnx_type = e.type.tensor_type
input_dict = {}
input_dict['name'] = e.name
input_dict['dtype'] = onnx.mapping.TENSOR_TYPE_TO_NP_TYPE[onnx_type.elem_type]
input_dict['shape'] = [(i.dim_value if i.dim_value != 0 else d) for i, d in zip(
onnx_type.shape.dim, [1, 3, 224, 224])]
inputs.append(input_dict)
return onnx_model, inputs
def onnx_simplify(model_file):
onnx_model, inputs = parse_model_input_output(model_file)
onnx_model = onnx.shape_inference.infer_shapes(onnx_model)
input_shapes = {}
for input in inputs:
input_shapes[input['name']] = input['shape']
onnx_model, check = onnxsim.simplify(onnx_model, input_shapes=input_shapes)
assert check, "Simplified ONNX model could not be validated"
model_file = os.path.join(os.path.dirname(model_file), 'simplified.onnx')
onnx.save_model(onnx_model, model_file)
return model_file
def read_model_file(model_file):
with open(model_file, 'rb') as f:
model_content = f.read()
return model_content
def main():
args = parse_args()
model_file = args.input
target = 'k210'
# onnx simplify
model_file = onnx_simplify(model_file)
# compile_options
compile_options = nncase.CompileOptions()
compile_options.target = target
compile_options.dump_ir = True
compile_options.dump_asm = True
compile_options.dump_dir = 'tmp'
# compiler
compiler = nncase.Compiler(compile_options)
# import_options
import_options = nncase.ImportOptions()
# import
model_content = read_model_file(model_file)
compiler.import_onnx(model_content, import_options)
# compile
compiler.compile()
# kmodel
kmodel = compiler.gencode_tobytes()
name = os.path.basename(model_file).split(".")[0]
with open(f'{name}.kmodel', 'wb') as f:
f.write(kmodel)
if __name__ == '__main__':
main()
运行方式:
为简化部署方式,在部署好NNCASE的Docker镜像中直接运行Python脚本。首先用Docker拉取NNCASE镜像,再进入到镜像中运行Python代码
# 拉取镜像
docker pull registry.cn-hangzhou.aliyuncs.com/kendryte/nncase:latest
# 进入到容器内部
docker run -it --rm -v `pwd`:/mnt -w /mnt registry.cn-hangzhou.aliyuncs.com/kendryte/nncase:latest /bin/bash -c "/bin/bash"
# 运行
python3 3.onnx2kmodel.py -i outputs/mnist.onnx运行结果:
1. Import graph...
2. Optimize target independent...
3. Optimize target dependent...
5. Optimize target dependent after quantization...
6. Optimize modules...
7.1. Merge module regions...
7.2. Optimize buffer fusion...
7.3. Optimize target dependent after buffer fusion...
8. Generate code...
WARN: Cannot find a decompiler for section .rdata
WARN: Cannot find a decompiler for section .text
SUMMARY
INPUTS
0 input.1 f32[1,1,28,28]
OUTPUTS
0 18 f32[1,10]
MEMORY USAGES
.input 3.06 KB (3136 B)
.output 40.00 B (40 B)
.data 313.00 KB (320512 B)
MODEL 4.58 MB (4802240 B)
TOTAL 4.89 MB (5125928 B)
运行完毕,在outputs文件下有mnist.kmodel文件,这个文件。
代码讲解:
(1)首先使用onnx-simplifier简化ONNX模型
为什么要简化?这是因为在训练完深度学习的pytorch或者tensorflow模型后,有时候需要把模型转成 onnx,但是很多时候,很多节点比如cast节点,Identity 这些节点可能都不需要,我们需要进行简化[11],这样会方便我们后续在嵌入式平台部署。onnx-simplifier的开源地址见[9]。
主要代码为
def onnx_simplify(model_file):
onnx_model, inputs = parse_model_input_output(model_file)
onnx_model = onnx.shape_inference.infer_shapes(onnx_model)
input_shapes = {}
for input in inputs:
input_shapes[input['name']] = input['shape']
onnx_model, check = onnxsim.simplify(onnx_model, input_shapes=input_shapes)
assert check, "Simplified ONNX model could not be validated"
model_file = os.path.join(os.path.dirname(model_file), 'outputs/simplified.onnx')
onnx.save_model(onnx_model, model_file)
return model_file
(2)使用NNCASE转换ONNX参数,核心代码为
model_content = read_model_file(model_file)
compiler.import_onnx(model_content, import_options)
# compile
compiler.compile()
# kmodel
kmodel = compiler.gencode_tobytes()
这一步时,离部署到嵌入式不远了,那么我们继续来看K210的部分。
03 K210开发环境
开发这个K210的姿势总结如下有三种:(1)使用Micropython固件开发 (2)使用standalone SDK 进行开发 (3)使用FreeRTOS进行开发。
K210是支持好几种编程环境的,从最基本的cmake命令行开发环境 ,到IDE开发环境,到Python脚本式开发环境都支持,这几种开发方式没有优劣之分,有的人喜欢用命令行+vim,有的人喜欢IDE图形界面,也有的人根本不关心编译环境,觉得人生苦短只想写Python。
一般来说越基础的开发方式自由度越大,比如C语言+官方库,能充分发挥出芯片的各种外设功能,但同时开发难度比较高,过程很繁琐;越顶层的开发方式比如写脚本,虽然十分地便捷,甚至连下载程序的过程都不需要了,但是程序功能的实现极度依赖于MicroPython的API更新,且很多高级系统功能无法使用[2]。
为降低大家在开发中的不友好度,本文介绍第一种开发方法,以后有机会可以介绍使用C SDK直接进行开发。不管用什么系统都能进行K210的开发,我们需要完成下列内容的准备:
(1)将K210通过USB连入你的电脑
(2)CH340驱动已安装
(3)cmake
(4)kflash或kflash GUI,一个烧录程序用以将编译好的.bin文件烧录到硬件中。前者命令行,后者图形界面
(5)Micropython固件
第一步 下载Micropython固件。到https://dl.sipeed.com/shareURL/MAIX/MaixPy/release/master 下载一个bin文件,这里笔者使用的是minimum_with_kmodel_v4_support
wget https://dl.sipeed.com/fileList/MAIX/MaixPy/release/master/maixpy_v0.6.2_72_g22a8555b5/maixpy_v0.6.2_72_g22a8555b5_minimum_with_kmodel_v4_support.bin
第二步 查看K210的串口号。以笔者使用的MacOS为例:
ls /dev/cu.usbserial-*
# /dev/cu.usbserial-14330
第三步 烧录。
使用命令行进行烧录示例:
kflash -p /dev/cu.usbserial-14330 -b 115200 -t maixpy_v0.6.2_72_g22a8555b5_minimum_with_kmodel_v4_support.bin
笔者比较懒,不想每次指定串口号,所以直接用/dev/cu.usbserial-* 。如果你电脑只有一个以/dev/cu.usbserial 开头的串口,那就不用指定,直接用我这种方法:
kflash -p /dev/cu.usbserial-* -b 115200 -t *.bin
到这里,如果没有问题的话,说明你已经成功在K210上部署了。怎么使用其进行编程呢?笔者建议读完[16],更多信息可以从参考Micropython的文档[14]和Github[15]。
04 硬件平台部署
KModel制作好,接下来需要把KModel部署到硬件 。有两种方式,下面分别介绍,任选一种即可。
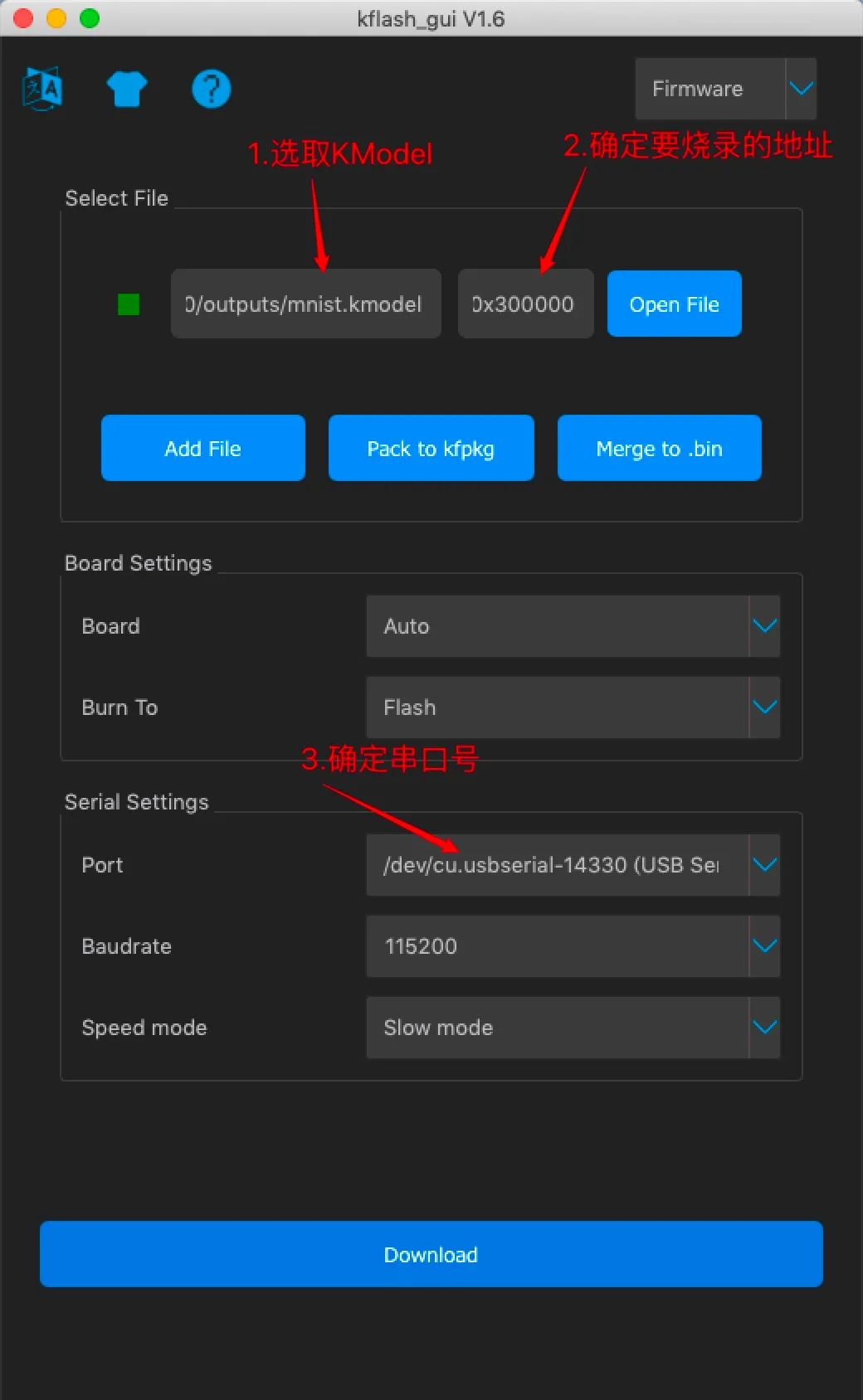
方法一:将Model烧录到Flash中
打开Kflash GUI,配置如下烧录到0x300000地址
方法二:将KModel放在SD卡中
直接将KModel放在SD卡中即可,注意TF卡需要是MBR 分区 FAT32 格式[17]。如果不是这个格式,是加载不到SD卡的。在Mac中,可以打开磁盘管理工具–>选择对应磁盘–>抹掉–>格式–>MS-DOS(FAT)直接一步格式化。

最终运行
代码文件:4.k210_main.py
import sensor, lcd, image
import KPU as kpu
lcd.init(invert=True)
sensor.reset()
sensor.set_pixformat(sensor.RGB565)
sensor.set_framesize(sensor.QVGA)
sensor.set_windowing((224, 224)) # set to 224x224 input
sensor.set_hmirror(0) # flip camera
task = kpu.load(0x300000) # load model from flash address 0x200000
a = kpu.set_outputs(task, 0, 10, 1, 1)
sensor.run(1)
while True:
img = sensor.snapshot()
lcd.display(img, oft=(0, 0)) # display large picture
img1 = img.to_grayscale(1) # convert to gray
img2 = img1.resize(32, 32) # resize to mnist input 32x32
a = img2.strech_char(1) # preprocessing pictures, eliminate dark corner
lcd.display(img2, oft=(240, 32)) # display small 32x32 picture
a = img2.pix_to_ai(); # generate data for ai
fmap = kpu.forward(task, img2) # run neural network model
plist = fmap[:] # get result (10 digit's probability)
pmax = max(plist) # get max probability
max_index = plist.index(pmax) # get the digit
lcd.draw_string(224, 0, "%d: %.3f" % (max_index, pmax), lcd.WHITE, lcd.BLACK)
运行方式:
有多种方式,下面介绍两种,更多方式可参考:https://wiki.sipeed.com/soft/maixpy/zh/get_started/get_started_upload_script.html
方式1:rshell
正如使用 linux 终端一样, 使用 rshell 的 cp 命令即可简单地复制文件到开发板
按照 rshell 项目主页的说明安装好 rshell
sudo apt-get install python3-pip
sudo pip3 install rshell
rshell -p /dev/ttyUSB1 # 这里根据实际情况选择串口
Copy
ls /flash
cp ./test.py /flash/ #复制电脑当前目录的文件 test.py
方式2:SD 卡自动拷贝到 Flash 文件系统
为了方便将 SD 卡的内容拷贝到 Flash 文件系统, 只需要将要拷贝到 Flash 文件系统的文件重命名为cover.boot.py 或者cover.main.py, 然后放到SD卡根目录, 开发板断电插入SD卡,然后开发板上电, 程序就会自动将这两个文件拷贝到/flash/boot.py或者/flash/main.py,这样就算后面取出了SD卡,程序已经在 /flash/boot.py或者/flash/main.py了
看看部署到K210的识别效果:

五、总结
本文是笔者折腾嵌入式AI的一篇实践,涵盖以下内容:
视觉模型的数据准备、网络设计、训练 ONNX基本知识与ONNX的简化 使用AI编译器NNCASE将ONNX转化为KModel Micropython + KModel在K210上的部署
本文方法由于在Micropython上进行模型加载,在系统资源调用以及软件适配上会有许多限制。做成产品时建议用C+K210 SDK开发。由于篇幅限制,下篇将探索使用C语言对模型进行部署,欢迎关注更新!由于个人能力有限,如有疑问以及勘误欢迎和笔者进行交流:Github/QiangZiBro!
本文使用到的代码都托管在这个仓库里,大家可以自由查看:https://github.com/QiangZiBro/pytorch-k210.git
参考资料(5-10是为读者准备的参考学习资料)
[ 1 ] : 模型部署的场景、挑战和技术方案 https://zhuanlan.zhihu.com/p/387575188
[ 2 ] : 嵌入式AI从入门到放肆【K210篇】-- 硬件与环境 https://zhuanlan.zhihu.com/p/81969854
[ 3 ] : encase https://github.com/kendryte/nncase
[ 4 ] : How to integrate MNIST with Pytorch https://tensorbay-python-sdk.graviti.com/en/stable/integrations/pytorch.html
[ 5 ] : ONNX Github https://github.com/onnx/onnx
[ 6 ] : ONNX学习笔记 https://zhuanlan.zhihu.com/p/346511883
[ 7 ] : ONNX 教程 https://github.com/onnx/tutorials
[ 8 ] : ONNX 预训练SOTA模型 https://github.com/onnx/models
[ 9 ] : ONNX简化器 https://github.com/daquexian/onnx-simplifier
[ 10 ] : nncase Github https://github.com/kendryte/nncase
[ 11 ] : https://mp.weixin.qq.com/s/OTUSDSqGTgTJ6-KA-o0rQw
[ 12 ] : https://github.com/QiangZiBro/learn-docker-in-a-smart-way
[ 13 ] : 训练好的深度学习模型原来这样部署的!https://mp.weixin.qq.com/s/tqSmFcR-aQjDhaEyQBzeUA
[ 14 ] : https://wiki.sipeed.com/soft/maixpy/zh/index.html
[ 15 ] : https://github.com/sipeed/MaixPy
[ 16 ] : 编辑并执行文件 https://wiki.sipeed.com/soft/maixpy/zh/get_started/get_started_edit_file.html
[ 17 ] : https://wiki.sipeed.com/soft/maixpy/zh/others/maixpy_faq.html#Micro-SD-%E5%8D%A1%E8%AF%BB%E5%8F%96%E4%B8%8D%E5%88%B0
[ 18 ] : https://wiki.sipeed.com/soft/maixpy/zh/get_started/get_started_upload_script.html