
聊一聊分布式事务及其解决方案
关注我们,设为星标,每天7:30不见不散,架构路上与您共享 回复"架构师"获取资源

A(Atomicity):指单个事务中的操作要不都执行,要不都不执行
C(Consistency):指事务前后数据的完整性必须保持一致
I(Isolation):指多个事务对数据可见性的规则
D(Durability):指事务提交后,就会被永久存储下来
准备阶段,协调者分别给每个参与者发送Prepare消息,每个参与者收到消息后,进行“预提交”操作(不是实际的提交操作),把操作的结果(成功或失败)返回给协调者。
提交阶段,协调者根据准备阶段收到的参与者的返回结果进行判断,如果所有的参与者都返回成功,那么分别给每个参与者发送Commit消息,否则发送Rollback消息。
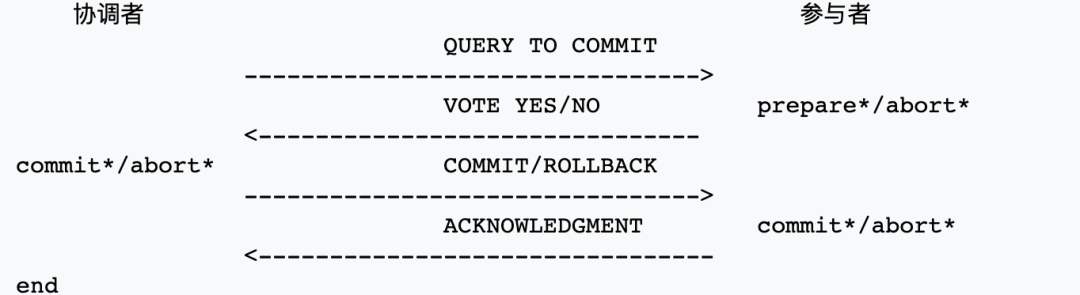
同步阻塞,2PC的两个阶段中,协调者和参与者的通信都是同步的,这会导致整个事务的长时间阻塞
Coordinator的单点问题
数据不一致,在Commit阶段,可能存在只有部分参与者收到Commit消息(或处理成功)的情况
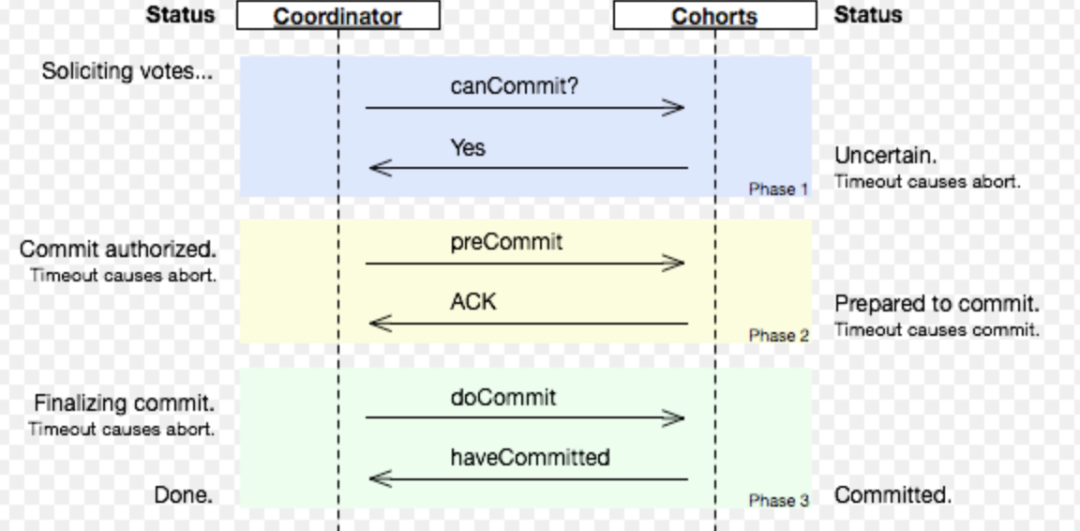
事务发起方把要处理的业务事务和写消息表这两个操作放在同一个本地事务里
事务发起方有一个定时任务轮询消息表,把没处理的消息发送到消息中间件
事务被动方从消息中间件获取消息后,返回成功
事务发起方更新消息状态为已成功
把业务处理和写消息表放在同一个事务是为了失败/异常后可以同时回滚
为什么不直接发消息,而是先写消息表?试想,如果发送消息超时了,即不确定消息中间件收到消息没,那么你是重试还是抛异常回滚事务呢?回滚是不行的,因为可能消息中间件已经收到消息,接收方收到消息后做处理,导致双方数据不一致了;重试也是不行的,因为有可能会一直重试失败,导致事务阻塞。
基于上述分析,消息的接收方是需要做幂等操作的
消息数据和业务数据耦合,消息表需要根据具体的业务场景制定,不能公用。就算可以公用消息表,对于分库的业务来说每个库都是需要消息表的。
只适用于最终一致的业务场景。例如在 A -> B场景下,在不考虑网络异常、宕机等非业务异常的情况下,A成功的话,B肯定也会成功的。
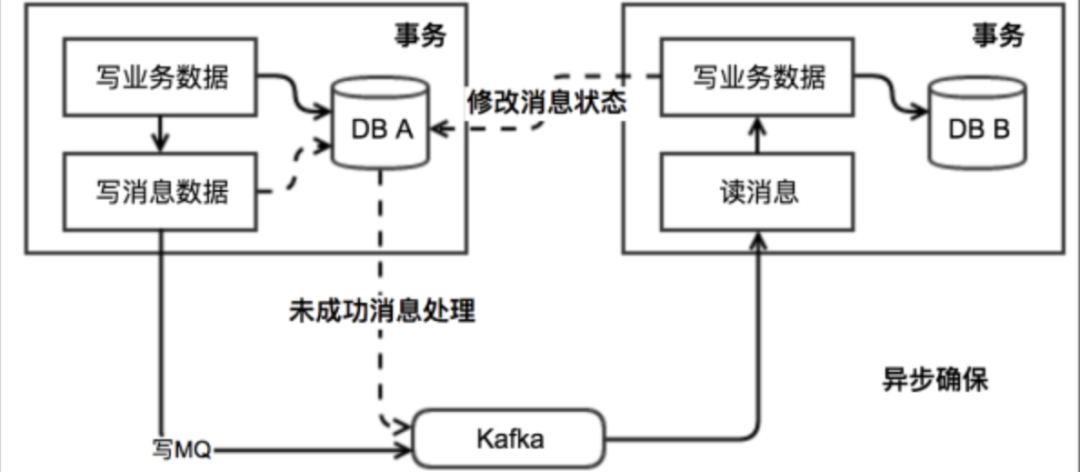
发起方发送半事务消息会给RocketMQ ,此时消息的状态prepare,接受方还不能拉取到此消息
发起方进行本地事务操作
发起方给RocketMQ确认提交消息,此时接受方可以消费到此消息了
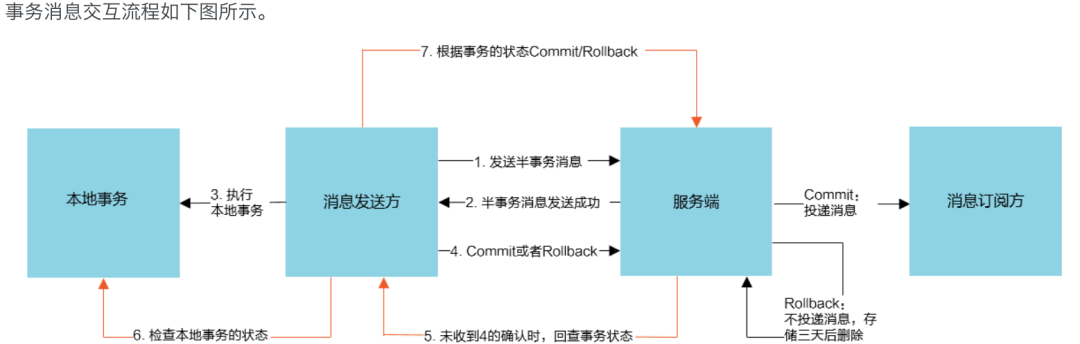
Try阶段,对业务资源进行检测和预留
Confirm阶段,对Try阶段预留的资源进行确认提交,Try阶段执行成功是Confirm阶段执行成功的前提
Cancel阶段,对Try阶段预留的资源进行撤销或释放
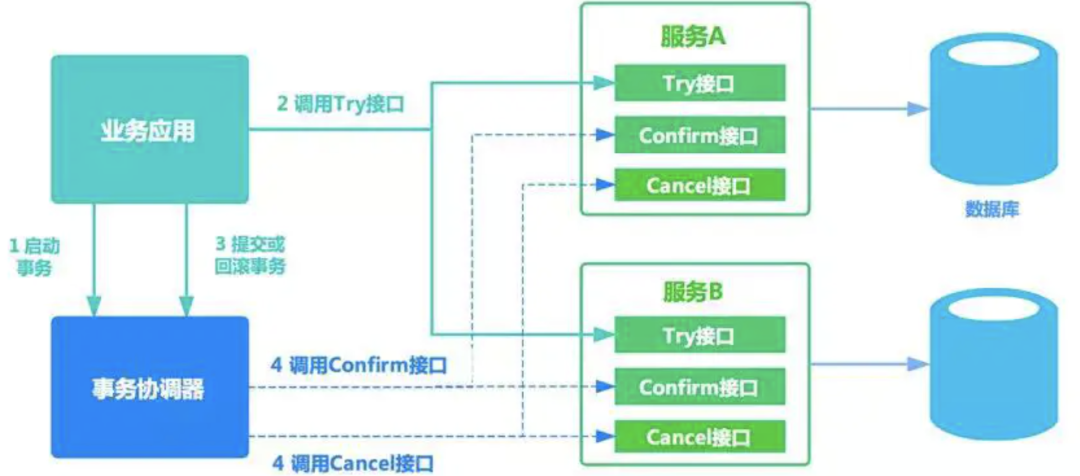
如果Try成功了,那么Confirm阶段异常了就一直重试,直到成功
Try、Confirm、Cancel三个阶段都有相应的资源及事务日志,应用根据日志(异步)来做重试或补偿
TCC的实现依赖底层数据库,异常后直接利用数据库的事务机制回滚
允许空回滚,在Try没有真正执行的情况下,触发了Cancel操作,这时要允许Cancel成功
防悬挂控制,Cancel操作比Try操作先执行(网络延迟原因),后面的Try操作不能执行成功
幂等控制
对于Confirm和Cancel阶段失败后要完全靠业务应用自己去处理
每个业务都需要实现Try、Confirm、Cancel三个接口,代码量比较多
如果是基于现有的业务想使用TCC会比较困难。一是对于原来的接口要拆分为三个接口,入侵性比较大;二是因为要做“预留”资源的操作,有可能需要对原来的业务模型进行改造。
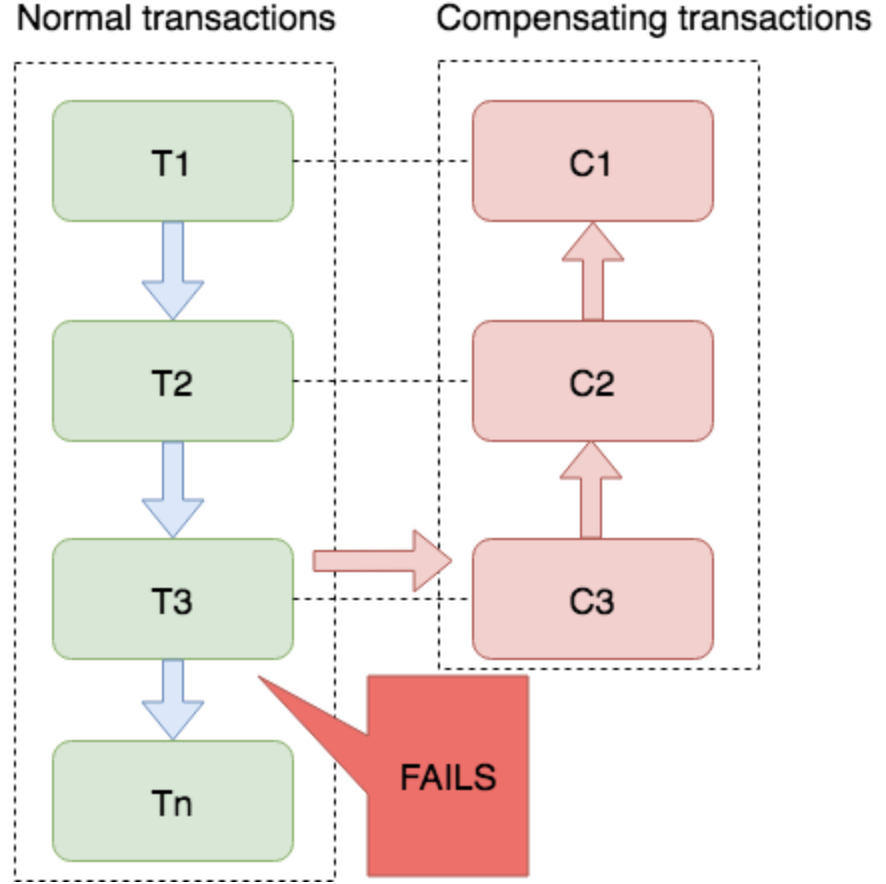
TCC适用于执行时间确定且较短、对一致性要求比较高、数据隔离强的业务
Saga适用于业务流程长、业务流程多的业务,在银行业金融机构使用广泛
TCC对现有业务改造较大,Saga则相对少点
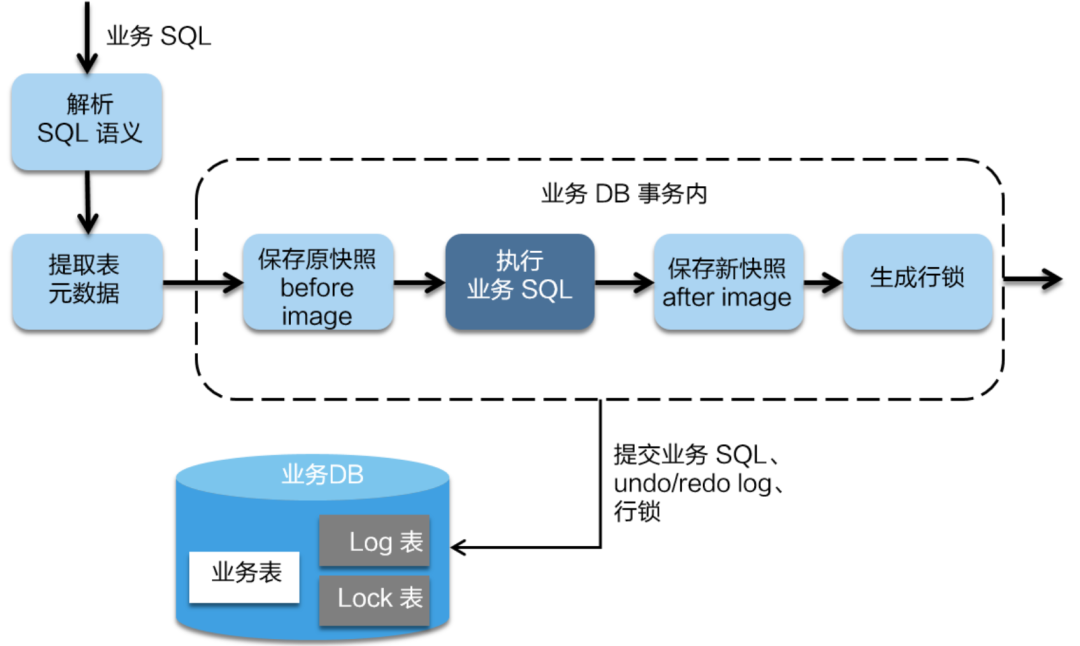
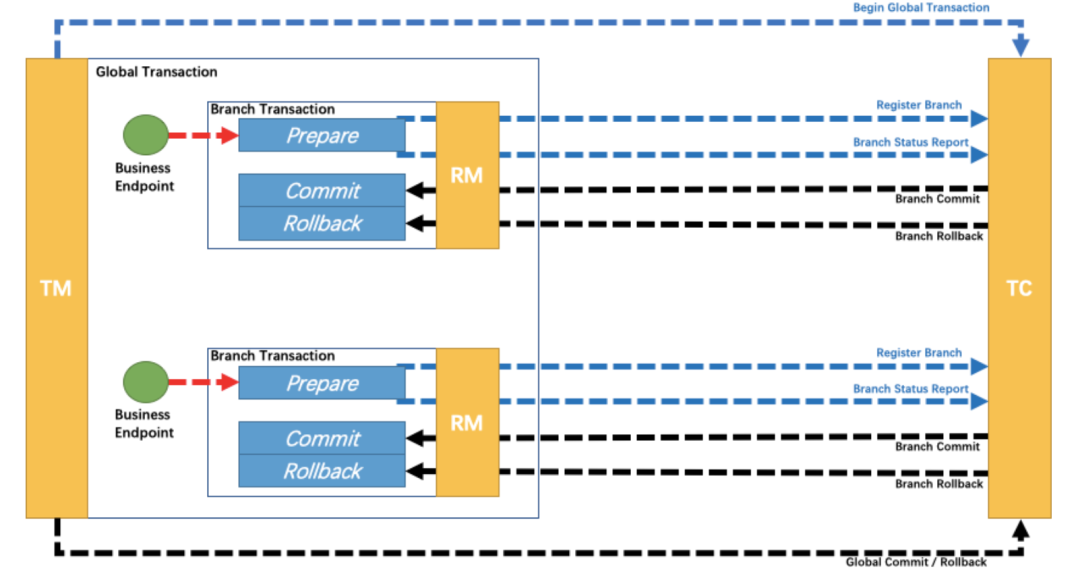
文章来源:https://javajgs.com/archives/7901

到此文章就结束了。如果今天的文章对你在进阶架构师的路上有新的启发和进步,欢迎转发给更多人。欢迎加入架构师社区技术交流群,众多大咖带你进阶架构师,在后台回复“加群”即可入群。
这些年小编给你分享过的干货
《不花钱的IDEA 2020.3.1 最新激活教程,有效期到2099年!》

转发在看就是最大的支持❤️