
一条提示词等同于多少个数据点?
数据点(data points)通常用于描述单个信息单位或观测值,在本文中,它被用来量化“提示词”方法相对于传统方法的效率和效果。文章比较了两种训练(微调)机器学习模型的方法:一种是使用提示 (prompts),本文也称之“提示词”,另一种是使用传统的分类器头 (classifier heads),本文也称之为“分类头”。通过比较可以发现,使用提示词的方法通常比使用分类器头的方法更好。
本文由 Hugging Face 的研究员 Teven Le Scao 撰写,并于 2021 年 4 月发表。尽管已经过去了很久,但其中的研究方法和发现仍具有深远的学术价值和实际应用意义,特别是对于理解和使用自然语言提示在机器学习中的角色。
本文原文是以 Hugging Face Space 应用做的展现,对于很多结果可以进行更高级的交互,请在文末查看本文的中英文原文。
当前 NLP 应用的主流方法是针对各式各样的特定任务,分别对预训练语言模型的分类头进行微调。随着语言模型变得越来越大,各种替代方法相继涌现,开始叫板在 BERT、UniLM 以及 GPT 中广泛使用的分类头法。特别地,GPT-3 向大家普及了提示法,该方法通过自然语言输入来引导预训练语言模型依靠自身解决任务,而不再需要额外的分类头。
提示的方式非常独特,用户可以通过它向模型提供信息,这与传统的 ML 监督学习有显著区别。在与 Alexader Rush 合作的 NAACL 2021 论文 中,我们研究了基于提示的微调,该方法可用于替代当前标准的有监督微调法,我们的实验表明提示通常比标准方法更有优势,因此该方法很有前途。在分析这种优势时,我们认为提示为模型带来了额外的信息,这促使我们想用数据点这个指标来量化这种优势,也就是说:提示词可以等同于多少个数据点?
提示词法
为了使预训练语言模型能够完成特定任务,当前的主流方法是用随机初始化的线性分类头替换原模型的最后一层:词预测层。然后使用有监督的任务数据通过反向传播来训练修改后的模型,主要学习这个新分类头的权重,同时也可以更新模型其他层的权重。我们将这种方法称为 分类头 法。
一种与之相竞争的方法是 提示法:这类方法主要尝试使用原语言模型来预测目标类相应的单词来“回答”分类问题,而不是像传统方法那样“预测”类标签。这使得我们可以直接使用语言模型本身来执行分类任务。在这里,提示 就是精心设计的、用于生成所需的答案文本的输入文本。
这听起来可能很抽象,但这其实恰恰就是人类在实际生活中进行文本推理时所使用的非常自然的方法:例如,学校练习往往以一个文本输入(例如,一篇关于火星的文章)加上一个问题(“火星上有生命吗?”)的形式呈现,并期望你提供一个自然语言的答案(“否”1),该答案其实就可以映射到分类任务的某个类别(这里,“否”对应假,“是”对应真,本例就是个二分类问题)。在这种范式中,就像做语法练习一样,我们把特定于任务的数据输入给模型,而模型就像学生一样,需要以固定的方式进行填空。提示法希望能显式利用语言模型中包含的预训练信息,而不是仅以将其隐含表征馈送给线性分类头的方式隐式利用这些信息。
以下是 SuperGLUE 中的 BoolQ 任务的示例,其题型为判断题,每条数据包括一个文本 passage 及其对应的问题 question ,其答案为布尔值,要么为真,要么为假。每条数据可以和 模板(pattern) 一起组装成一个文本序列,该序列只有一个需预测的 掩码词。预测出该掩码词后,预测词会被一个预设的 言语器(verbalizer) 转换为类,也就是说言语器负责输出词与类别之间的映射:比较该词被映射为 真 和 假 的概率,如果 真 的概率高,则最终预测为真,反之则为假。
静态图片不可交互,请阅读原文查看可交互内容版本,本文其他配图均为动态内容。
微调
这样,我们就把通用语言模型转变成了针对特定任务的分类器。这种基于提示的语言模型分类器的用法很多:
预训练模型中保留的语言建模功能允许它们在没有额外数据的情况下执行,这与以随机初始化开始因此初始性能也随机的线性分类头模型相反。因此,许多论文将其用于零样本分类。
为了将有监督的任务数据引入模型,我们可以使用反向传播及语言建模中的交叉熵损失目标来微调:将与正确类别相关联的言语器词作为正确预测。PET 使用了这个方法,T5 也使用了这个目标函数 - 尽管 T5 使用任务前缀来指示任务,而未使用自然语言提示来描述它。
还有一种方法是使用 潜觉(priming),此时,我们需要为当前问题找到若干正确的示例,将其作为原输入文本的前缀一起输入给模型。它没有反向传播,所以永远不会修改语言模型的权重;相反,它主要靠在推理时使用注意力机制去利用正确的示例。GPT3 使用了该方法。
最后,PET 的方法是使用提示模型预测未标注数据的软标签(或称为伪标签),然后将其作为标签去训练线性分类头。
在本文中,为了在提示法和分类头法之间进行公平比较,我们采用了统一的基于反向传播的微调方法。
一个提示可以抵多少条数据?
正如我们所看到的,分类头法和提示法都可以用于针对下游任务进行有监督微调。二者的核心区别在于,除了带标注的原始样本外,提示法还给了模型一个用于对特定任务进行粗略描述的句子。从某种意义上说,这句话也是一种监督数据,因为它告诉模型任务的信息,但它在本质上与机器学习中标准的监督数据又截然不同。我们应该如何看待这种新的监督数据?又该如何量化这种方法的“零样本”程度?
我们通过在 SuperGLUE 任务和 MNLI 上比较 分类头法 和 提示法 来尝试回答上面的问题。我们使用的具体方法是:对每个任务,我们通过从数据集中选取样本数不断增加的子集,然后在每个子集上使用这两种方法对 RoBERTa-large 进行微调,同时其他所有配置保持不变,最后对评估各自的微调模型的性能。为了公平起见,我们先调整基线分类头模型的超参,并使它们的性能达到 SuperGLUE 排行榜中 BERT++ 的性能水平,然后在对应的提示法模型中采用相同的超参。
下图绘制了每个任务 2 的最终性能(指标随任务而不同)随数据集大小的变化曲线。有了这个图,我们就能够对两种方法在给定任务上达到一定性能水平所需的数据量进行对比。我们将这种差异称为在该性能水平上其中一个方法相对于其他方法的 数据优势。我们将两种方法都能达到的性能的范围称为 比较窗口。通过在该范围内进行积分,我们可以获得在某任务上一种方法相对于另一种方法的“平均数据优势”。从图上看,这即是两条曲线所夹区域的的面积除以比较窗口的高度。3
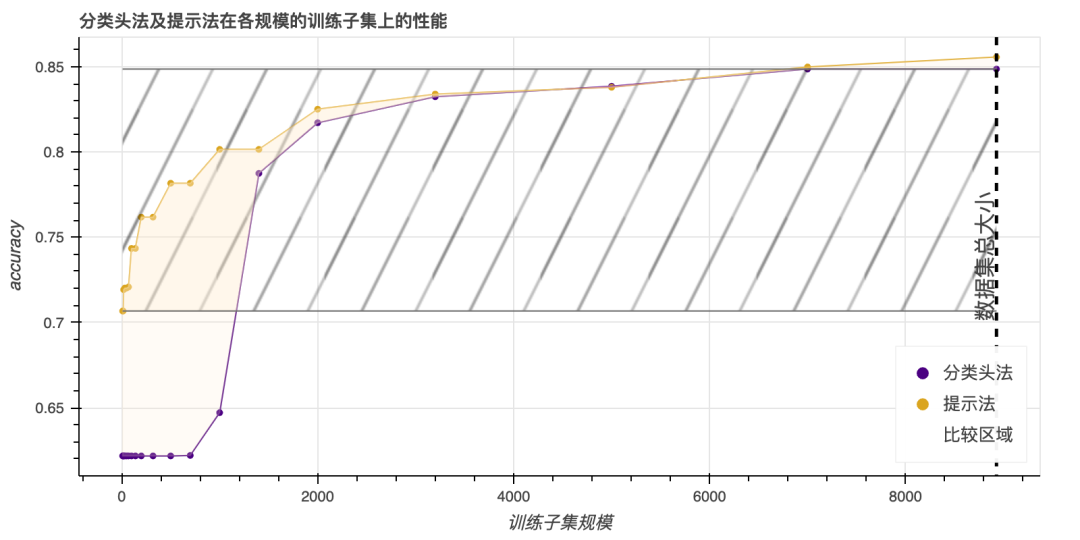
下表总结了在每个任务上提示法相对于分类头法的平均数据优势,其误差范围由自助采样法(bootstrapping)获得,具体做法是对每个数据规模,我们运行 4 次分类头法和 4 次提示法(即每个数据规模共 16 种组合),然后计算这些结果的标准差。不同任务的结果有很大不同;甚至对于同一任务的不同数据集,结果也会有所不同,例如 MNLI 和 RTE,这俩数据集虽然同属蕴涵任务,但结果就很不同。然而,总的趋势也很明显,即:除 WiC 4 之外,提示方法在其他任务中都具有显著的优势。提示提供的附加信息始终大致相当于数百个数据点。
| MNLI | BoolQ | CB | COPA | MultiRC5 | RTE | WiC | WSC | |
|---|---|---|---|---|---|---|---|---|
| 提示法 vs 分类头法 | 3506±536 | 752±46 | 90±2 | 288±242 | 384±378 | 282±34 | -424±74 | 281±137 |
模板与言语器
对言语器进行控制
当前,提示主要被用作零样本分类的工具,这是一个很自然的用法。然而,真正操作起来,零样本一般会很棘手,因为需要对提示和言语器进行完美对齐。在上文中,我们已经表明,提示可以应用到更广泛的场景中,包括在全数据场景中。为了对比提示法的零样本性和自适应性,我们考虑一个 空言语器(null verbalizer),该言语器与任务完全无关。对于只需要填写一个词的任务(因此 COPA 和 WSC 数据集不在此列),我们把其言语映射(例如“是”、“否”、“也许”、“对”或“错”)替换成随机的。这样的话,提示模型就会像分类头模型一样,在没有训练数据的情况下无法使用。我们对空言语器配置进行与上文相同的优势分析,并绘制出相应的曲线,如下:
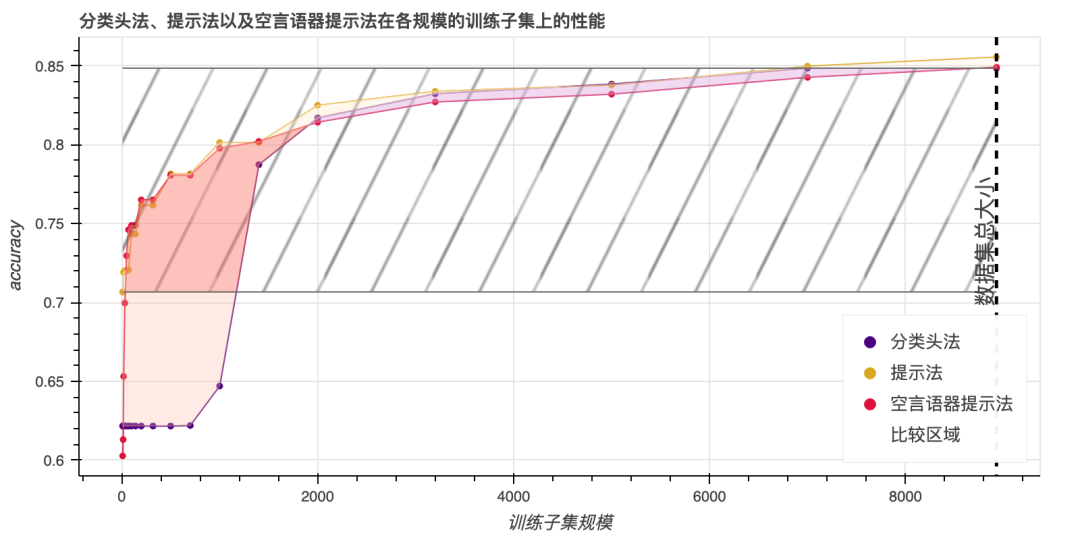
| MNLI | BoolQ | CB | MultiRC5 | RTE | WiC | |
|---|---|---|---|---|---|---|
| 提示法 vs 分类头法 | 3506±536 | 752±46 | 90±2 | 384±378 | 282±34 | -424±74 |
| 提示法 vs 空言语器 | 150±252 | 299±81 | 78±2 | 74±56 | 404±68 | -354±166 |
| 空言语器 vs 分类头法 | 3355±612 | 453±90 | 12±1 | 309±320 | -122±62 | -70±160 |
从结果来看,其数据优势噪声比直接提示法与分类头法的数据优势的噪声更大。然而,我们也发现,即使仅使用空言语器,语言模型也能够适应任务,即使只有几个数据点,其也能凭借恰当的提示取得与分类头模型相当或更好的性能。因此,我们可以认为,即使没有信息丰富的言语器,提示法带来的归纳偏差也是有益的。
模板选择带来的影响
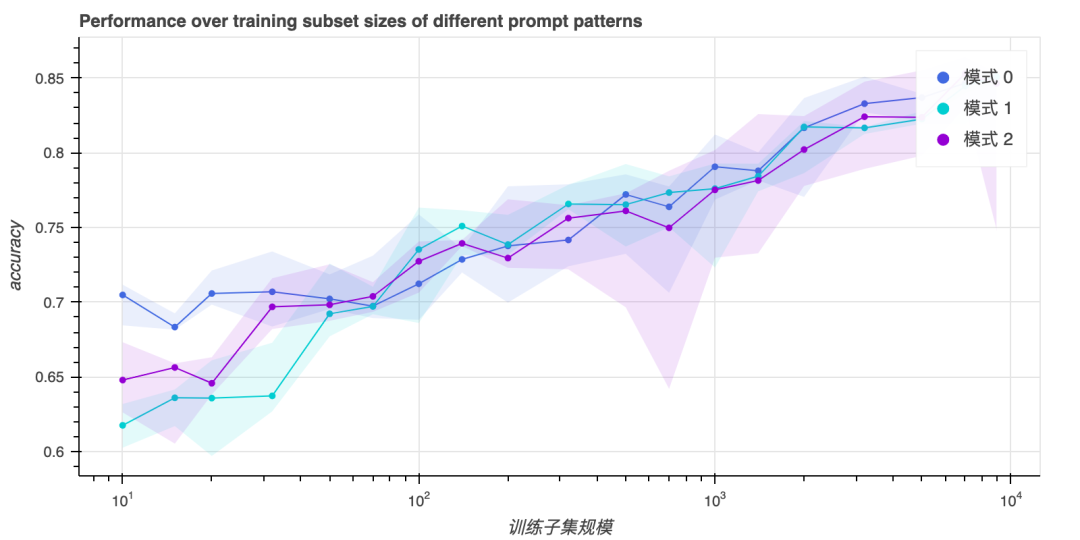
另一个可能影响提示法在零样本分类场景下的成败的因素是:提示模板的选择。这里,我们看一下该因素对我们的影响。我们复用了 PET 中的模板(每个任务有两到三个完全不同的模板),并对每个任务的每种模板进行了实验,结果如下。我们可以看到提示的选择对结果没有显著影响,其方差小于随机种子带来的方差。
最后的话
通过这项工作,我们研究了一种新的、基于自然语言提示的微调方法,其目的是通过单词预测显式地利用预训练模型的语言建模能力,而不是通过基于模型中间表征的线性分类器隐式地利用它。为了公平比较,我们把问题建模为用反向传播来微调基于提示的分类器语言模型,我们发现提示法通常优于使用标准微调线性分类头的方法。我们用数据点来估计这种优势,以衡量人类通过提示提供的附加信息,并发现编写提示始终抵得上数百个数据点。此外,即使没有言语器带来的信息量(即使用空言语器),这种优势仍然存在,并且这种方法对于提示的选择相当鲁棒。
对于从业人员而言,我们相信基于提示的微调不仅应当成为一种标准工具,而且将会成为如此。特别是对于中小型的特定任务数据集,通过自行设计提示,只需付出很小的努力就能获得显著的数据优势。而对于研究人员而言,我们认为这个领域还有很多问题尚待探索:为什么相同的提示在 MNLI 数据集上抵得上 3500 个样本,而在 RTE 数据集上却只抵得上 282 个样本?提示与标准 ML 监督有何关系?由于它们具有一些零样本特性,因此它们对对抗样本或领域外样本的反应是否有所不同?
1:或者严格点说,至少据我们所知为否。
2:眼尖的读者会注意到所有这些曲线都是单调的。我们为每个实验执行了 4 次运行(即对每个任务的每个数据规模,分别各运行分类头法和提示法 4 次,并用得到的模型测试)。为了清楚起见,并且由于两种方法的微调有时都会失败,从而导致负异常值,因此针对每个数据规模我们报告在此数据规模或更小的数据规模下获得的最大性能,我们将其称为 累积最大 聚合。除了减少方差之外,这不会对报告的数据优势产生太大影响,且即使对于非单调曲线,对图形的解读仍然成立。
3:在计算每个指标的数据优势时,我们为每个数据赋予相同的权重;我们还可以针对每个任务重新参数化 y 轴。这种做法到底是会对提示法相对于分类头法的数据优势起促进作用还是阻碍作用不好说,与数据集相关。举个例子,强调接近收敛时的增益会增加 CB 和 MNLI 上的提示法的数据优势,但会降低 COPA 或 BoolQ 上的优势。
4:有趣的是,PET 已经发现提示对该数据集无效。
5:MultiRC 的比较窗口太小,因为分类头基线模型无法学习到多数类之外知识;我们使用整个区域来获得实际结果的下界。
英文原文:
中文版本:
https://hf.co/spaces/teven-projects/how_many_data_points
原文作者:Teven Le Scao
https://hf.co/spaces/MatrixYao/how_many_data_points_zh
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。