在本综述论文中,研究者解释了不同技术的工作原理、评估和比较,还分析了一些实现这些技术的框架。
现代深度学习和人工智能技术的发展涉及使用深度神经网络(DNN)来解决图像、视频、音频、自然语言处理、图像形式的内容生成等各种问题,或生成给定格式主题的文本等任务。俄罗斯斯科尔科沃科学技术研究所、法国里尔大学、波尔多大学、Inria 等科研机构联合发表了一篇论文《Survey on Large Scale Neural Network Training》,它试图解决的问题是:若给定模型和计算平台的情形下,如何训练才是最有效率的。为了使训练高效,其必须可行,最大程度地利用资源的计算能力,在并行情况下,它不能让信息传输成为瓶颈。训练的效率从根本上取决于计算内核在计算资源(CPU、TPU、GPU)上的有效实现以及 GPU 之间和不同内存之间通信的有效实现。
论文链接:https://arxiv.org/abs/2202.10435在这两种情况下,人们为优化计算内核的算术强度,及有效实现硬件网络上的通信做了很多工作。对于使用者来说,已存在强大的分析工具来识别硬件瓶颈,并可用于判定本调查中描述哪些策略可用于解决算术强度、内存和控制交换数据量的问题。该综述研究涵盖了应对这些限制的通用技术。如果由于模型、优化器状态和激活不适合内存而无法先验执行计算,则可以使用内存交换计算(重新实现)或数据转移(激活和权重卸载)。我们还可以通过近似优化器状态和梯度(压缩、修剪、量化)来压缩内存使用。并行方法(数据并行、模型并行、流水线模型并行)也可以将内存需求分布到多个算力资源上。如果计算的算力强度不足以充分利用 GPU 和 TPU,一般是因为 mini-batch 太小,那么上述技术也可以增加 mini-batch 的大小。最后,如果使用数据并行引起的通信开销昂贵到拖累计算速度,则可以使用其他形式的并行(模型并行、流水线模型并行),梯度压缩也可以限制数据交换的数量。在本次调查中,研究者解释了这些不同技术是如何工作的,其中描述了评估和比较所提出方法的文献,还分析了一些实施这些技术的框架。下表 1为文章讨论的不同技术及其对通信、内存和计算效率的影响。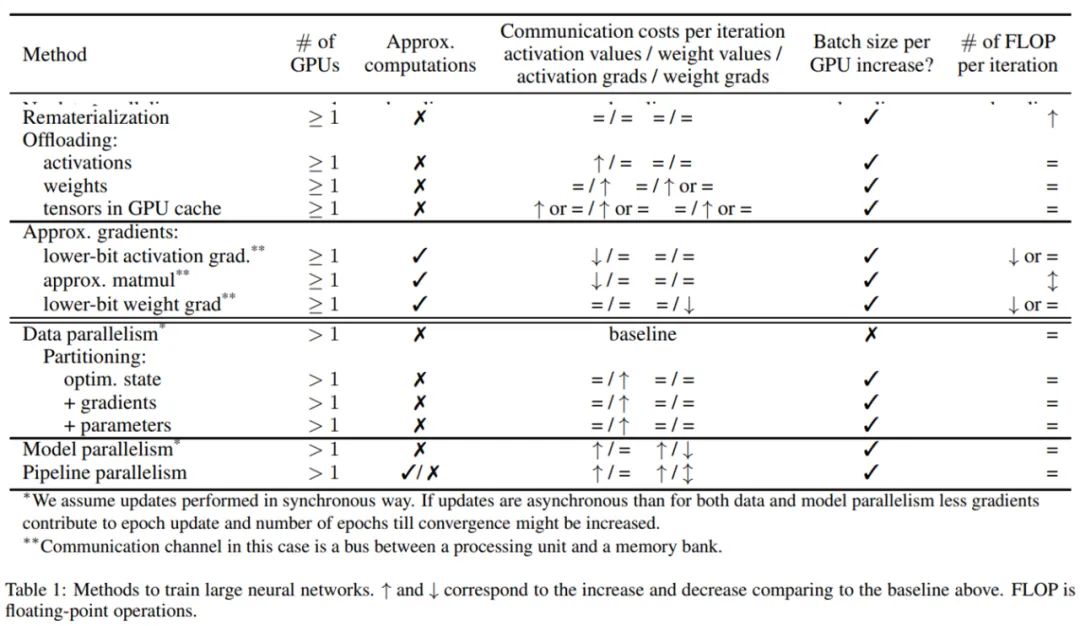
研究者根据目的区分了以下方法:首先讨论减少 GPU 内存使用,随后考虑对不适合 GPU 的模型使用并行训练,最后讨论为训练存储在多个设备上的模型而开发的优化器的设计。在前向传播期间,神经网络存储执行反向传播所需的激活。在某些情况下,这些激活会消耗大量内存,让模型无法训练。减少内存使用的主要方法有两种:重新实现(也称为 checkpointing)和卸载。重新实现的策略仅在前向传播期间存储一小部分激活,并在反向传播期间重新计算其余部分。重新实现方法可以通过它们处理的计算图来区分。第一组来自自动微分(AD),它们为同构顺序网络(多层按顺序执行并具有相同计算和内存成本的 DNN)找到最佳调度。第二组专注于过渡模型,例如异构序列网络(可以是由任意复杂模块组成的任何序列神经网络,如 CNN、ResNet、一些 transformer),它将解决方案从 AD 调整为异构设置。一些方法可以对一般计算图执行重新实现,尽管确切的计算成本可能指数级上升,如下表 2 所示。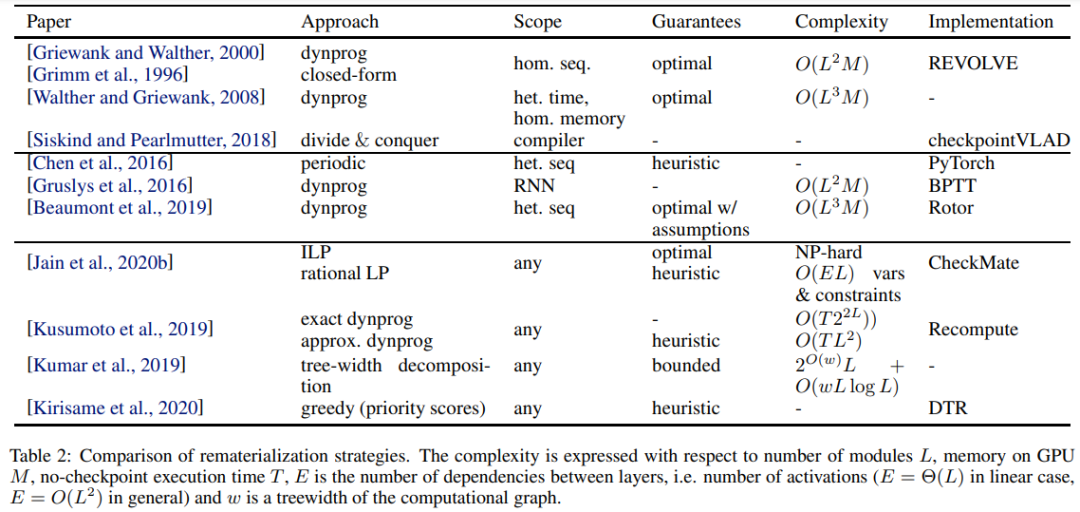
卸载(又被称为内存交换)是一种通过在前向传递期间将激活转移到 CPU 内存并将它们预取回 GPU 内存,以进行相应的向后计算来节省 GPU 内存的技术。由于 CPU 和 GPU 之间 PCI 总线的带宽有限,必须优化选择传输激活,以及何时传输的选择。在 vDNN [Rhu et al., 2016] 研究中,作者通过仅卸载卷积层的输入来遵循对 CNN 有效的启发式方法,然而它不能很好地推广到一般 DNN 上。另有研究 [Le et al., 2018] 考虑了激活生命周期来选择卸载的内容,并使用图搜索方法来识别插入卸载 / 预取操作的时刻。AutoSwap [Zhang et al., 2019] 通过为每个变量分配优先级分数来决定卸载哪些激活。前面提到的很多方法也适用于卸载权重,这是因为卸载权重依赖于适用于任何张量的通用技术,比如 TFLMS、AutoSwap 或者 SwapAdvisor。在模型并行化中,只需要传达激活信息,并且传输只发生在分配给不同处理器的连续层之间。本章节提到的工作如下表 4 所示。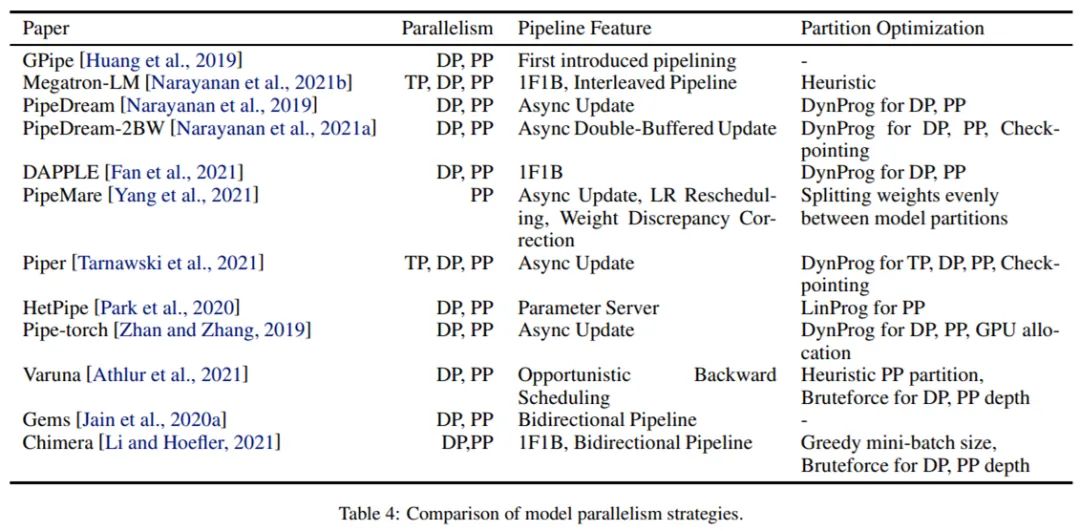
如果多个小批量被 pipeline 化 ,则可以加快模型并行化中的执行速度,从而同时激活了多个训练迭代,具体可见 [Huang et al., 2019]。一旦在所有这些小批量上计算了前向和后向阶段,权重就会更新。这种方法实现起来相当简单,但也导致计算资源大部分处于空置状态。[Narayanan et al., 2019] 中提出的 PipeDream 方法仅强制前向和后向任务针对给定的小批量使用相同的模型权重,改进了这一训练过程。减少执行更新的频率也已被证明有助于限制权重过期(Narayanan et al., 2021a)。[Yang et al., 2021] 提出的 PipeMare 根据 pipeline 阶段向后调整学习率和模型权重。对 pipeline 方法中激活导致的存储成本进行建模是一项艰巨的任务(Beaumont et al., 2021b)。例如,[Fan et al., 2021] 中的 DAPPLE 、 [Li and Hoefler, 2021] 中的 Chimera 使用 1F1B(One-Forward-One-Backward)调度来减少与激活相关的内存消耗。1F1B 是一种同步权重更新技术,尽可能早地安排每个微批次的反向传递,以释放激活占用的内存。有些论文专门处理具有挑战性的拓扑。比如,为了解决高通信成本和异构网络能力的问题,[Zhan and Zhang, 2019] 中的 Pipe-torch 提出了一种更新的动态规划策略,该策略假设计算和通信之间没有重叠。[Park et al., 2020] 中的 Pipe 解决了异构 GPU 的其他问题,采用的方法是将这些异构 GPU 分成虚拟 worker,并在每个虚拟 worker 中运行 pipeline 并行化,同时依赖 worker 之间的数据并行化。2020 年, Rajbhandari, S. 等人在论文《 ZeRO: Memory Optimizations toward Training Trillion Parameter Models》中提出了零冗余优化器(Zero Redundancy Optimizer, ZeRO),将它作为一种减少内存使用的数据并行化实现。根据在设备上划分的张量,该算法具有三个阶段,即阶段 1 - 优化器状态、阶段 2 - 优化器状态和梯度和阶段 3 - 优化器状态、梯度和模型超参数。2021 年, Ren, J. 等人在论文《 ZeRO-Offload: Democratizing Billion-Scale Model Training》中将 ZeRO 与 Zero-Offload 内部参数更新的 CPU 端计算统一起来,其中梯度被迁移至存储参数副本的 CPU,更新的权重迁移回 GPU。为了进一步减少内存使用,低精度优化器(low-precision optimizer)有了用武之地。这些方法使用低精度格式拉力表示优化器状态以及状态的辅助向量。并且,误差补偿技术可以被用来维持跟踪统计的近似准确率。2021 年, Dean, J. 等人在论文《Large Scale Distributed Deep Networks》中提出了一种将 Adam 优化器存储在 8-bit 的方法,同时在使用 32-bit 格式时保持整体性能不变。2020 年, Sun, X. 等人在论文《Ultra-Low Precision 4-bit Training of Deep Neural Networks》中提出了更激进的精度降低,其中开发了处理 4-bit 表示的特定路径。另一种加速大规模深度学习模型的方法是减少节点之间的通信时间以及在适当局部最小值收敛所需的 epoch 数量。关于通信成本的降低。在将梯度在计算节点之间迁移之前对它们进行压缩已经出现了不同的方法,具体有三类,分别是分裂(sparsification)、量化(quantization)和低秩(low-rank)方法。分裂方法只迁移完整梯度元素的一些子集,并在参数向量中更新相应的元素。这种近似方法能够显著降低通信成本,同时保持训练模型的性能,代表工作有 2017 年 Aji, A. F. 和 Heafield, K 的论文《 Sparse Communication for Distributed Gradient Descent 》和 2019 年 Alistarh, D. 等的论文《The Convergence of Sparsified Gradient Methods》。另一种方法是基于迁移梯度的量化,该方法只迁移一定数量的 bit、从这些 bit 中重建整个梯度向量并更新参数向量的所有元素。这种方法对于一些神经网络架构和实验设置得到了不错的结果,代表工作有 Alistarh, D. 等人 2017 年的论文《QSGD: Communication-Efficient SGD via Gradient Quantization and Encoding》。最后一种降低通信成本的方法是低秩方法,其中在更新参数向量之前构建、迁移和使用梯度的低秩近似来恢复完整格式的梯度。低秩近似可以通过块能量(block power)方法或者最小化策略来构建,各自的代表工作分别是 Vogels et al., 2019 和大批量训练。另一种加速优化器收敛的方法是针对每个批使用大量的样本。这种训练设置可以减少每个 epoch 中的迭代次数,并提升 GPU 的利用率。在 Goyal, P 等人 2017 年的论文《Accurate, Large Minibatch SGD》中,研究者提出使用线性缩放规则来更新学习率和批大小。这一设置可以稳定优化过程,并将模型的最终性能收敛至相同。往期精彩:
《机器学习:公式推导与代码实现》1-7章PPT下载
《机器学习 公式推导与代码实现》随书PPT示例
时隔一年!深度学习语义分割理论与代码实践指南.pdf第二版来了!
新书首发 | 《机器学习 公式推导与代码实现》正式出版!
《机器学习公式推导与代码实现》将会配套PPT和视频讲解!
 下载APP
下载APP