
广告投放效果分析
共 12635字,需浏览 26分钟
·
2022-02-09 17:32
In [1]:
import pandas as pd
import numpy as np
import random
from matplotlib import pyplot as plt
import seaborn as sns
import time, datetime
from pyecharts import Funnel
分析目的
实现淘宝展示广告精准投放,提高广告投放效果。
数据来源https://tianchi.aliyun.com/dataset/dataDetail?dataId=56
数据说明
原始样本骨架raw_sample
从淘宝网站中随机抽样了114万用户8天内的广告展示/点击日志(2600万条记录),构成原始的样本骨架。
字段说明如下:
(1) user_id:脱敏过的用户ID;
(2) adgroup_id:脱敏过的广告单元ID;
(3) time_stamp:时间戳;
(4) pid:资源位;
(5) noclk:为1代表没有点击;为0代表点击;
(6) clk:为0代表没有点击;为1代表点击;
广告基本信息表ad_feature
本数据集涵盖了raw_sample中全部广告的基本信息。字段说明如下:
(1) adgroup_id:脱敏过的广告ID;
(2) cate_id:脱敏过的商品类目ID;
(3) campaign_id:脱敏过的广告计划ID;
(4) customer_id:脱敏过的广告主ID;
(5) brand:脱敏过的品牌ID;
(6) price: 宝贝的价格
用户基本信息表user_profile
本数据集涵盖了raw_sample中全部用户的基本信息。字段说明如下:
(1) userid:脱敏过的用户ID;
(2) cms_segid:微群ID;
(3) cms_group_id:cms_group_id;
(4) final_gender_code:性别 1:男,2:女;
(5) age_level:年龄层次;
(6) pvalue_level:消费档次,1:低档,2:中档,3:高档;
(7) shopping_level:购物深度,1:浅层用户,2:中度用户,3:深度用户
(8) occupation:是否大学生 ,1:是,0:否
(9) new_user_class_level:城市层级
用户的行为日志behavior_log
本数据集涵盖了raw_sample中全部用户22天内的购物行为(共七亿条记录)。字段说明如下:
(1) user:脱敏过的用户ID;
(2) time_stamp:时间戳;
(3) btag:行为类型, 包括以下四种:
ipv:浏览
cart:加入购物车
fav:喜欢
buy:购买
(4) cate:脱敏过的商品类目;
(5) brand: 脱敏过的品牌词;
(本数据集数据量极大,本次分析只截取部分数据(4百万条记录)来分析)
分析思路
为达到广告精准投放的效果,分别从三方面分析确定:
1.广告投放渠道
2.广告投放时间
3.广告投放目标人群
根据三个方面的不同广告投放效果(1.以页面访问占比,即点击率为指标衡量广告投放效果(CPC相关);2.以用户行为为指标衡量广告投放效果(CPA相关)),找出实现广告精准投放的方案。首先,分析CPC相关。
数据导入
In [2]:
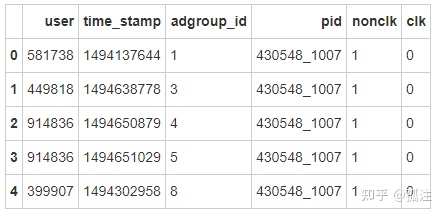
df=pd.read_csv('D:\\raw_sample_0.csv')
df.head()Out [2]:

In [3]:
df.info()
RangeIndex: 4000000 entries, 0 to 3999999
Data columns (total 6 columns):
# Column Dtype
--- ------ -----
0 user int64
1 time_stamp int64
2 adgroup_id int64
3 pid object
4 nonclk int64
5 clk int64
dtypes: int64(5), object(1)
memory usage: 183.1+ MB
In [4]:
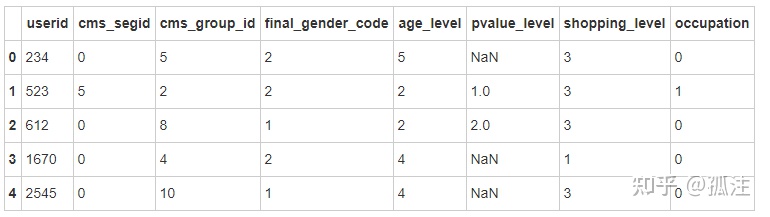
users=pd.read_csv('D:\\user_profile.csv')
users.head()Out [4]:

In [5]:
users.info()
RangeIndex: 1048575 entries, 0 to 1048574
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 userid 1048575 non-null int64
1 cms_segid 1048575 non-null int64
2 cms_group_id 1048575 non-null int64
3 final_gender_code 1048575 non-null int64
4 age_level 1048575 non-null int64
5 pvalue_level 479841 non-null float64
6 shopping_level 1048575 non-null int64
7 occupation 1048575 non-null int64
dtypes: float64(1), int64(7)
memory usage: 64.0 MB
In [6]
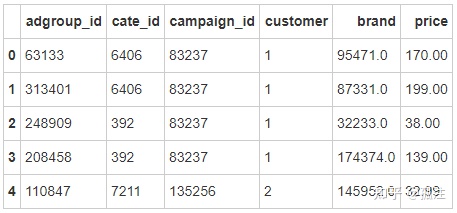
ad=pd.read_csv('D:\\ad_feature.csv')
ad.head()Out [6]:

In [7]:
ad.info()
RangeIndex: 846811 entries, 0 to 846810
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 adgroup_id 846811 non-null int64
1 cate_id 846811 non-null int64
2 campaign_id 846811 non-null int64
3 customer 846811 non-null int64
4 brand 600481 non-null float64
5 price 846811 non-null float64
dtypes: float64(2), int64(4)
memory usage: 38.8 MB
数据预处理
In [8]:
df.drop_duplicates(inplace=True)
df.reset_index(drop=True, inplace=True)
df.info()
RangeIndex: 4000000 entries, 0 to 3999999
Data columns (total 6 columns):
# Column Dtype
--- ------ -----
0 user int64
1 time_stamp int64
2 adgroup_id int64
3 pid object
4 nonclk int64
5 clk int64
dtypes: int64(5), object(1)
memory usage: 183.1+ MB
原始样本骨架raw_sample无重复值和缺失值
In [9]:
users.drop_duplicates(inplace=True)
users.reset_index(drop=True, inplace=True)
users.info()
RangeIndex: 1048575 entries, 0 to 1048574
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 userid 1048575 non-null int64
1 cms_segid 1048575 non-null int64
2 cms_group_id 1048575 non-null int64
3 final_gender_code 1048575 non-null int64
4 age_level 1048575 non-null int64
5 pvalue_level 479841 non-null float64
6 shopping_level 1048575 non-null int64
7 occupation 1048575 non-null int64
dtypes: float64(1), int64(7)
memory usage: 64.0 MB
用户基本信息表user_profile无重复值
In [10]:
ad.drop_duplicates(inplace=True)
ad.reset_index(drop=True, inplace=True)
ad.info()
RangeIndex: 846811 entries, 0 to 846810
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 adgroup_id 846811 non-null int64
1 cate_id 846811 non-null int64
2 campaign_id 846811 non-null int64
3 customer 846811 non-null int64
4 brand 600481 non-null float64
5 price 846811 non-null float64
dtypes: float64(2), int64(4)
memory usage: 38.8 MB
广告基本信息表ad_feature无重复值
缺失值处理
In [11]:
users.replace(np.nan,'数据缺失',inplace=True)
users.info()
RangeIndex: 1048575 entries, 0 to 1048574
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 userid 1048575 non-null int64
1 cms_segid 1048575 non-null int64
2 cms_group_id 1048575 non-null int64
3 final_gender_code 1048575 non-null int64
4 age_level 1048575 non-null int64
5 pvalue_level 1048575 non-null object
6 shopping_level 1048575 non-null int64
7 occupation 1048575 non-null int64
dtypes: int64(7), object(1)
memory usage: 64.0+ MB
In [12]
ad.replace(np.nan,'数据缺失',inplace=True)
ad.info()
RangeIndex: 846811 entries, 0 to 846810
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 adgroup_id 846811 non-null int64
1 cate_id 846811 non-null int64
2 campaign_id 846811 non-null int64
3 customer 846811 non-null int64
4 brand 846811 non-null object
5 price 846811 non-null float64
dtypes: float64(1), int64(4), object(1)
memory usage: 38.8+ MB
RangeIndex: 846811 entries, 0 to 846810
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 adgroup_id 846811 non-null int64
1 cate_id 846811 non-null int64
2 campaign_id 846811 non-null int64
3 customer 846811 non-null int64
4 brand 846811 non-null object
5 price 846811 non-null float64
dtypes: float64(1), int64(4), object(1)
memory usage: 38.8+ MB
数据分析
1.广告投放渠道分析
In [13]:
clk_per=df.clk.sum()/4000000*100
clk_perOut [13]:
5.005025
总页面访问占比(点击率)为5%。
In [14]:
plt.figure(figsize=(6,8))
x = df['pid'].unique()
y = df.groupby(by=['pid'])['clk'].sum()/4000000
sns.barplot(x,y,palette='Oranges_r')Out [14]:

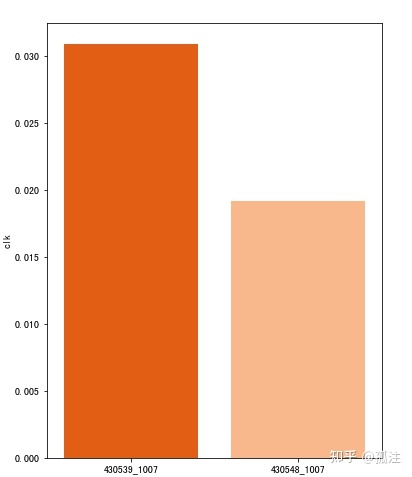
资源位430539_1007的点击率要高于430548_1007,说明第一个广告投放渠道要优于第二个。
2.广告投放时间
In [15]:
df['hour']=pd.to_datetime(df['time_stamp'], unit='s').dt.hour
df['hour']=df.hour.astype('str')
df.info()
RangeIndex: 4000000 entries, 0 to 3999999
Data columns (total 7 columns):
# Column Dtype
--- ------ -----
0 user int64
1 time_stamp int64
2 adgroup_id int64
3 pid object
4 nonclk int64
5 clk int64
6 hour object
dtypes: int64(5), object(2)
memory usage: 213.6+ MB
In [16]:
plt.figure(figsize=(16,8))
x = df['hour'].unique()
y = df.groupby(by=['hour'])['clk'].sum()/4000000
sns.barplot(x,y,palette='Oranges_r')Out [16]:

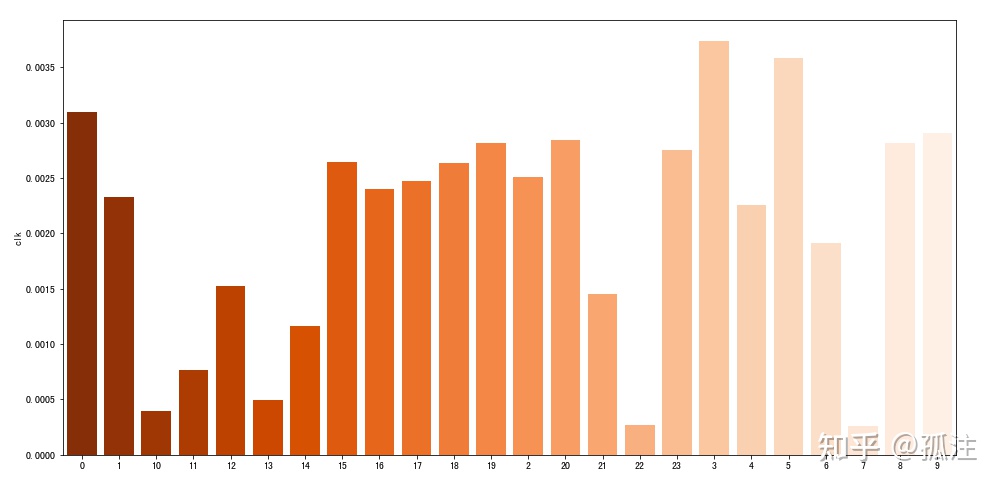
15时到20时的广告点击率都相对较高,7时、10时、22时的点击率极低。这几个时间段的广告投放效果很差。当然,点击率的高低对比也受各时间段的浏览量影响,点击率的低的时间段有可能是由于高浏览量造成,点击率高的时间段也有可能是由于低浏览量造成。具体情况还需要更多数据进一步分析。
In [17]:
df['weekday']=pd.to_datetime(df['time_stamp'], unit='s').dt.weekday
df['weekday']=df.weekday.astype('str')
df.head()Out [17]:

In [18]:
plt.figure(figsize=(12,6))
x = df['weekday'].unique()
y = df.groupby(by=['weekday'])['clk'].sum()/4000000
sns.barplot(x,y,palette='Oranges_r')Out [18]:

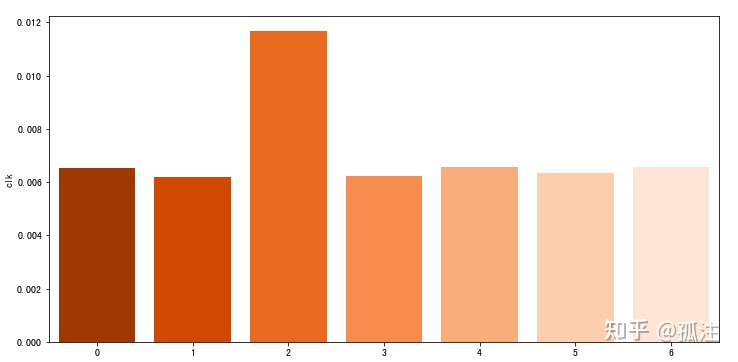
周二的点击率最高,其余时间的点击率很接近。周二的广告投放效果好。
3.广告投放目标人群(有点击行为的用户特征)
连接user_profile和raw_sample两表,筛选出有点击广告行为的用户
In [19]:
df.set_index(["user"], inplace=True)
df.head()Out[19]:

In [20]:
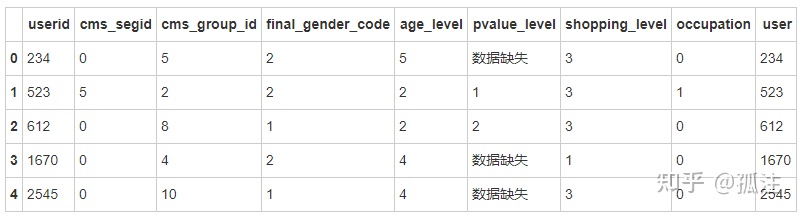
users['user']=users.userid
users.head()Out [20]:

In [21]:
user_ac=pd.merge(df,users,right_on='user',left_index=True,how='outer')In [22]:
user_ac.replace('数据缺失',np.nan,inplace=True)
user_ac.clk.replace(0,np.nan,inplace=True)
user_ac.dropna(inplace=True)
user_ac.info()
Float64Index: 86297 entries, 498395.0 to 726056.0
Data columns (total 16 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 time_stamp 86297 non-null float64
1 adgroup_id 86297 non-null float64
2 pid 86297 non-null object
3 nonclk 86297 non-null float64
4 clk 86297 non-null float64
5 hour 86297 non-null object
6 weekday 86297 non-null object
7 userid 86297 non-null float64
8 cms_segid 86297 non-null float64
9 cms_group_id 86297 non-null float64
10 final_gender_code 86297 non-null float64
11 age_level 86297 non-null float64
12 pvalue_level 86297 non-null float64
13 shopping_level 86297 non-null float64
14 occupation 86297 non-null float64
15 user 86297 non-null int64
dtypes: float64(12), int64(1), object(3)
memory usage: 11.2+ MB
In [23]:
user_ac.clk.replace(0,np.nan,inplace=True)
user_acOut [23]:

a.用户性别
In [24]:
plt.figure(figsize=(6,8))
x = user_ac['final_gender_code'].unique()
y = user_ac.groupby(by=['final_gender_code']).size()
sns.barplot(x,y,palette='Oranges_r')Out [24]:

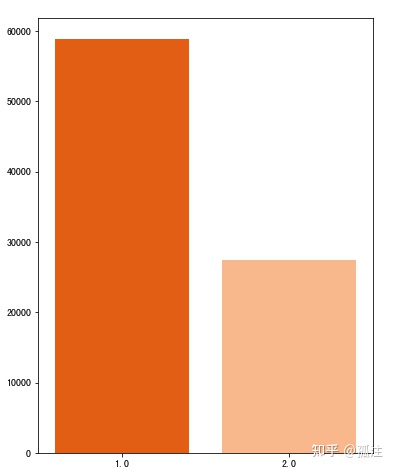
1代表男性,2代表女性,男性的广告点击率高于女性。
b.消费档次
In [25]:
plt.figure(figsize=(6,8))
x = user_ac['pvalue_level'].unique()
y = user_ac.groupby(by=['pvalue_level']).size()
sns.barplot(x,y,palette='Oranges_r')Out [25]:

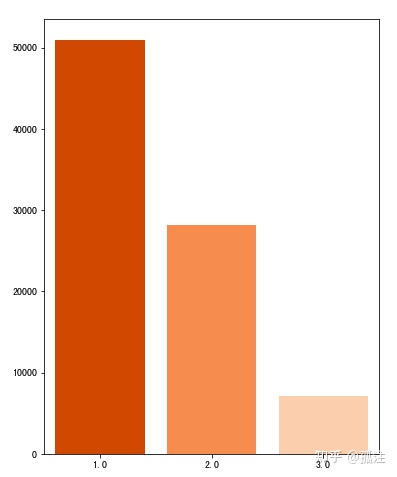
1代表低档,2代表中档,3代表高档,说明随着消费档次的提高,用户打开广告的欲望越低。
c.购物深度
In [26]:
plt.figure(figsize=(6,8))
x = user_ac['shopping_level'].unique()
y = user_ac.groupby(by=['shopping_level']).size()
sns.barplot(x,y,palette='Oranges_r')Out [26]:

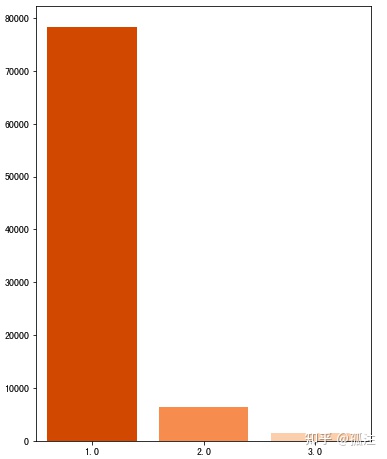
1.代表浅层用户,2代表中度用户,3代表深度用户,说明随着购物深度的增加,用户打开广告的欲望越低,浅层用户更容易被广告吸引。
d.是否大学生
In [27]:
plt.figure(figsize=(6,8))
x = user_ac['occupation'].unique()
y = user_ac.groupby(by=['occupation']).size()
sns.barplot(x,y,palette='Oranges_r')Out [27]:

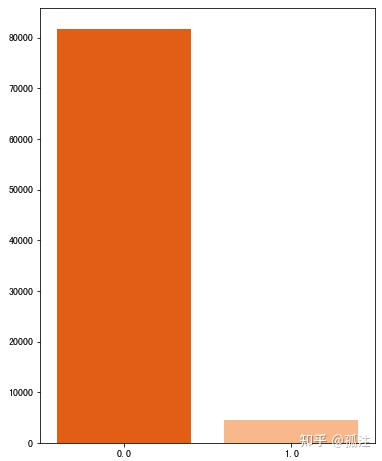
0代表不是大学生,1代表是大学生,广告对大学生吸引较小,非大学生更容易被广告吸引,点击广告。
e.年龄层次
In [28]:
plt.figure(figsize=(6,8))
x = user_ac['age_level'].unique()
y = user_ac.groupby(by=['age_level']).size()
sns.barplot(x,y,palette='Oranges_r')Out [28]:

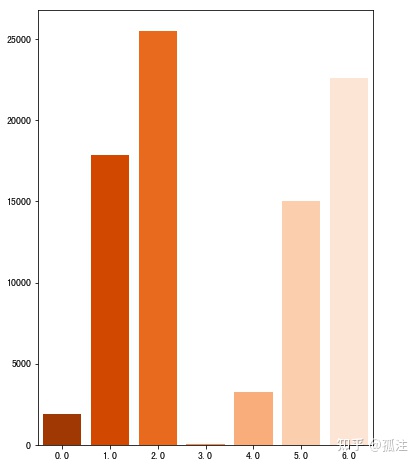
年龄层级2的用户广告点击率最高,1、5、6也很高,0、3、4较低,其中3最低。广告投放目标为用户年龄层级为1256时效果较好,3基本很难被广告吸引。
结论
1.渠道:430539_1007渠道的广告投放效果要好于430548_1007渠道。
2.时间:15时到20时的广告投放效果较好,周二的广告投放效果好。
3.用户:具有男性,地中档的消费档次,浅层购物深度,非大学生,年龄层次在1、2、5、6的用户点击意愿更强。
广告投放时需要参考上述点击率较高的特征变量。
上述分析是基于点击率为指标对比广告效果(CPC相关),如果按用户点击后的行为来作为指标对比广告效果,包括加入购物车率,收藏率和购买率,(CPA相关),做一个各阶段转化率的简单分析。
数据导入
In [29]:
bl=pd.read_csv('D:\\behavior_log_0.csv')
bl.head()Out [29]:

数据预处理
In [30]:
bl.info()
RangeIndex: 4000000 entries, 0 to 3999999
Data columns (total 5 columns):
# Column Dtype
--- ------ -----
0 user int64
1 time_stamp int64
2 btag object
3 cate int64
4 brand int64
dtypes: int64(4), object(1)
memory usage: 152.6+ MB
In [31]:
bl.drop_duplicates(inplace=True)
bl.reset_index(drop=True, inplace=True)
bl.info()
RangeIndex: 3719999 entries, 0 to 3719998
Data columns (total 5 columns):
# Column Dtype
--- ------ -----
0 user int64
1 time_stamp int64
2 btag object
3 cate int64
4 brand int64
dtypes: int64(4), object(1)
memory usage: 141.9+ MB
数据分析
In [32]:
bl
In [33]:
bl.groupby(by=['btag']).size()Out [33]:
btag
buy 49641
cart 88026
fav 51711
pv 3530621
dtype: int64
In [34]:
51711/3530621*100Out [34]:
1.464643188832786
用户点击广告并浏览后收藏广告推送的产品转化率为1.47%。
In [35]:
data = [['pv', 3530621,3530621/3530621], ['cart', 88026,88026/3530621],['buy', 49641,49641/3530621]]
btag = pd.DataFrame(data)
btag.info()
RangeIndex: 3 entries, 0 to 2
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 0 3 non-null object
1 1 3 non-null int64
2 2 3 non-null float64
dtypes: float64(1), int64(1), object(1)
memory usage: 200.0+ bytes
In [36]:
attrs = btag[0].tolist()
attr_value = (np.array(btag[2])* 100).tolist()
funnel = Funnel("交易环节漏斗图", width=600, height=400, title_pos='center')
funnel.add(name="交易环节漏斗图",
attr=attrs,
value = attr_value,
is_label_show=True,
label_formatter='{c}%',
label_pos="inside",
legend_orient='vertical',
legend_pos='left',
is_legend_show=True)
funnel.render()
funnelOut [36]:

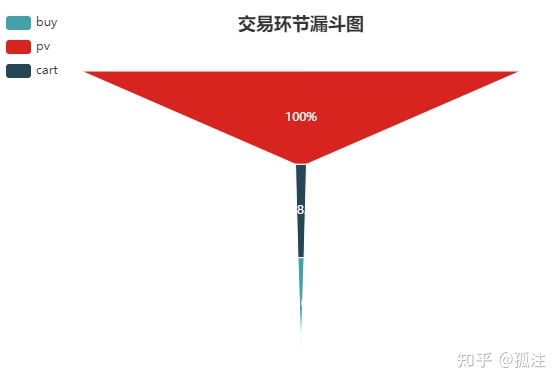
用户在点击广告浏览后,加入购物车的转化率约为2.5%,购买转化率约1.4%,和点击浏览广告后加入收藏的转化率(1.46%)接近。如果是选择CPA作为广告收费计算方式,需要提高用户的加入购物车转化率,购买转化率和收藏转化率。这三个转化率低,是用户在点击广告进入商品详情界面,即着落页后,较难激发购物欲望,说明着落页需要优化,才可以提高转化率,优化广告投放效果。