
5个步骤实现目标检测
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转自:磐创AI
【导读】目标检测技术是当今计算机视觉领域的发展趋势。在场景图像和视频中,有许多方法被用来检测物体。在资源和执行时间方面,每种技术都有自己的优势和局限性。检测视频中的物体也需要大量的技术知识和资源。

因此,人们一直在寻找一种简单、快速的目标检测方法。在本文中,我们将演示如何检测视频中看到的对象,只需5个步骤。
我们将在本任务中使用pixellib库,该库使用实例分割检测对象。我们还将使用预训练Mask R-CNN模型来识别视频中看到的物体。
在这个实现中,我们将检测交通视频中的车辆对象。
实例分割是计算机视觉中的一种技术,它利用图像分割的方法进行目标检测。它在像素级识别图像或视频中存在的每个对象实例。
在图像分割中,视觉输入被分割成若干段,通过形成像素集合来表示对象或对象的一部分。实例分割识别图像中每个对象的每个实例,而不是像语义分割那样对每个像素进行分类。
Mask R-CNN是由Kaiming He等人在Facebook人工智能研究所提出的深层神经网络的变体。该模型用于解决计算机视觉中的对象实例分割问题。
它检测图像中的对象,同时为每个实例生成一个高质量的分割掩码。它是Faster R-CNN的一个扩展,它增加了一个预测目标掩码的分支,与现有的边界盒识别分支并行。
下面给出了用于实例分割的Mask R-CNN框架。
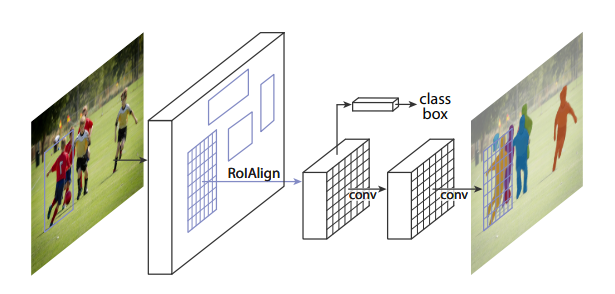
现在,我们将讨论在视频中检测物体的步骤。
1.安装库和依赖项
在第一步中,我们需要安装pixellib库及其依赖项。
!pip install pixellib
2.加载预先训练的Mask RCNN权重
由于我们将使用Mask R-CNN模型来检测目标,我们将下载其预训练的权重。
!wget --quiet https://github.com/matterport/Mask_RCNN/releases/download/v2.0/mask_rcnn_coco.h5
3.导入库
现在,我们将导入已安装的pixellib库。我们还将导入instance_segmentation 类,因为我们将使用实例分割方法检测对象。
import pixellib
from pixellib.instance import instance_segmentation
4.实例化实例分割模型并加载MASK R-CNN权重
在这一步中,我们将实例化pixellib提供的instance_segmentation类,并使用其预训练的权重加载Mask R-CNN模型。
segment_video = instance_segmentation()
segment_video.load_model("mask_rcnn_coco.h5")
5.检测物体
在这一步中,我们将通过在视频中MASK R-CNN来处理目标检测任务。我们会用随机使用一段交通视频
视频:https://analyticsindiamag.com/wp-content/uploads/2020/07/traffic_vid2.mp4?_=1
在这种方法中,我们设置每秒帧数,即视频输出每秒的帧数。
segment_video.process_video("traffic_vid2.mp4", show_bboxes = True, frames_per_second= 15, output_video_name="object_detect.mp4")




最后,我们将在工作目录中获得输出视频。这个过程的时间取决于视频的长度和大小。你应该使用GPU来加快处理速度。对于上面的交通视频,结果为
视频:https://analyticsindiamag.com/wp-content/uploads/2020/07/Object_Detect.mp4?_=2
你可以定义一个函数来从YouTube获取视频并将其直接传递给上面的函数。
因此,利用以上步骤,我们可以讨论一种非常简单的方法来实现视频中的目标检测任务。刚入门计算机视觉的可以用这种方法检测物体。
原文链接:https://analyticsindiamag.com/hands-on-guide-to-detect-objects-in-video-in-5-steps/
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~