
NeurIPS 2021 | 寻MixTraining: 一种全新的物体检测训练范式

来源:专知 本文附论文,建议阅读5分钟 物体检测是计算机视觉中的基础课题。

论文链接:
https://www.zhuanzhi.ai/paper/b52468c0ddce3d49f7740cfd1528a7a0
代码链接(即将开源):
https://github.com/MendelXu/MixTraining
物体检测是计算机视觉中的基础课题。经典的物体检测器通常采用单一的数据增强策略,并简单地使用人工标注的物体包围盒来进行训练,这种训练策略也被称为 SiTraining 范式。在本篇论文中,微软亚洲研究院的研究员们提出了一种全新的物体检测训练范式:MixTraining。该范式通过引入 Mixed Training Targets(混合训练目标)与 Mixed Data Augmentation(混合数据增广),可以有效提升现有物体检测器性能,并且不会在测试阶段增加任何额外的开销。如表4所示,MixTraining 能够将基于 ResNet-50 的 Faster R-CNN 的检测精度从41.7mAP 提升至44.3 mAP,并将基于 Swin-S 的 Cascade R-CNN 的检测精度从 50.9mAP 提升至 52.8mAP。
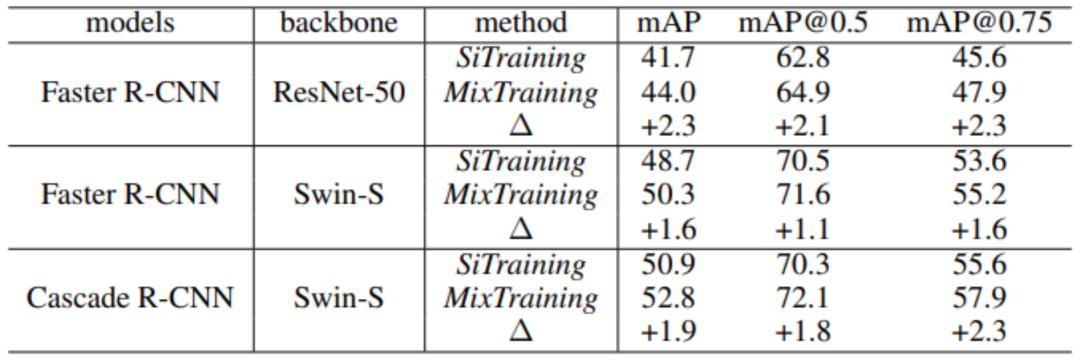
表4:MixTraining 可以有效提升多种现有检测器的检测性能
除了良好的系统级性能提升以外,研究员们还对该范式为何有效进行了深入详尽的分析与研究。研究员们首先对 Mixed Training Targets (混合训练目标)的工作机理进行了分析。Mixed Training Targets (混合训练目标)采用了老师-学生 (Teacher-Student)架构来生成高质量的检测结果,并将这些检测结果作为伪标注(Pseudo ground-truth)再与真实的人类标注 (Human-annotated ground-truth)结合起来共同作为网络的训练标注。研究员们发现这种使用混合标注有两种好处:1)可以避免漏标的物体(missing label) ;2)可以降低标注中的定位噪声(box loc noise) 。分析结果如表5所示。
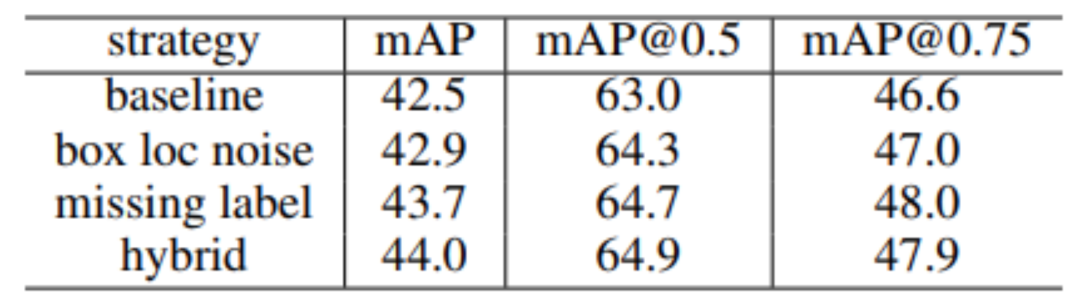
表5:对混合训练目标的消融实验
其次,研究员们还对 Mixed Data Augmentation(混合数据增广)进行了进一步的研究。研究员们猜测不同的训练实例可能需要不同强度的数据增广,而不能一概而论地对所有训练示例使用统一的简单或者过强的数据增广,否则反而有可能会损害训练性能,结果如表6所示。
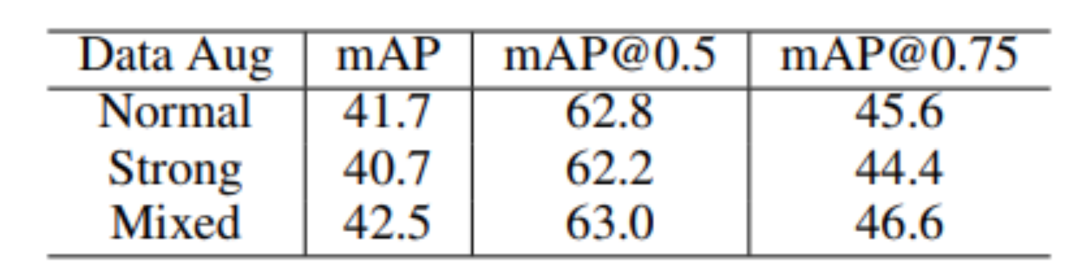
表6:对混合数据增广的消融实验
与此同时,研究员们还发现 MixTraining 可以在更长的训练轮数中获得更大的收益,结果如表7所示。
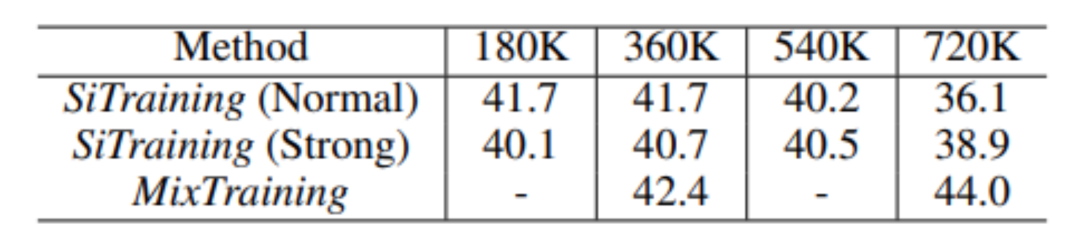
表7:MixTraining 可以在更长的训练轮数中获得更大的收益