
幻读是啥,会有什么问题?如何解决?
微信公众号:欢少的成长之路,来个 点赞,转发,在看!
大家好,我是Leo,上篇文章大概介绍了为什么查询一条记录性能慢的原因。今天我们介绍一下幻读的一些相关知识,以及幻读相关的间隙锁,间隙锁死锁的解决方案。

概念
可重复读
两个事务进行数据操作他们是互不干扰的 ,事务先A进行数据查询,事务B进行一次事务修改并进行数据提交,事务A再进行一次查询,数据是不改变的
提交读
两个事务进行数据操作,事务先A进行数据查询,事务B进行一次事务修改并进行数据提交,事务A再进行一次查询,数据是B修改后的数据。
案例
幻读是什么
如下图所示,我们一起分析一下。
sessionA首先开启了一个事务并且在T1时刻给d为5的数据加上了写锁
sessionB没有开启事务。修改了id为0的数据,把d改成了5
sessionA继续执行了d=5的数据加上了写锁
sessionC插入了一条数据115
sessionA再次查询数据就发现数据一直在变,一直在多
这种从事务开启到事务结束,如果同一个数据看到不同的结果。我们就称为幻读。
for update 加了写锁都是 当前读。而当前读的规则就是看到所有已经提交过的数据。
幻读有什么问题
如下图所示,我们继续分析一下
session B 的第二条语句 update t set c=5 where id=0,语义是“我把 id=0、d=5 这一行的 c 值,改成了 5”。
由于在 T1 时刻,session A 还只是给 id=5 这一行加了行锁, 并没有给 id=0 这行加上锁。因此,session B 在 T2 时刻,是可以执行这两条 update 语句的。这样,就破坏了 session A 里 Q1 语句要锁住所有 d=5 的行的加锁声明。
session C 也是一样的道理,对 id=1 这一行的修改,也是破坏了 Q1 的加锁声明。
以上是语义上的问题。下面还有数据一致性上的问题
我们知道,锁的设计是为了保证数据的一致性。而这个一致性,不止是数据库内部数据状态在此刻的一致性,还包含了数据和日志在逻辑上的一致性。
如下图,我们继续分析会有什么问题。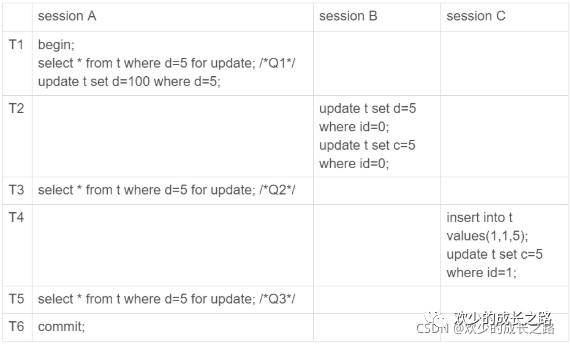
为了说明这个问题,我给 session A 在 T1 时刻再加一个更新语句,即:update t set d=100 where d=5。
update跟for update的含义是一样的。都是给d为5的数据加锁。然后修改成d为100
sessionA在T1时刻,会给d为5的数据加锁。并且修改d为100(不提交)
sessionB在T2时刻,会修改id为0的数据改成d,c为5。(提交)
回到了sessionA的T3时刻,再次查询加写锁
sessionC在T4时刻,执行了插入语句,修改id为1的数据c为5.(提交)
这样看好像也没啥逻辑和一致性问题。再来看一下binlog日志
update t set d=5 where id=0; /*(0,0,5)*/
update t set c=5 where id=0; /*(0,5,5)*/
insert into t values(1,1,5); /*(1,1,5)*/
update t set c=5 where id=1; /*(1,5,5)*/
update t set d=100 where d=5;/*所有d=5的行,d改成100*/
你会发现在执行这三行结果都变成了(0,5,100)、(1,5,100) 和 (5,5,100)。也就说有两条数据被改了。
那么我们应该怎么改?如下图,加了锁的
由于 session A 把所有的行都加了写锁,所以 session B 在执行第一个 update 语句的时候就被锁住了。需要等到 T6 时刻 session A 提交以后,session B 才能继续执行。
这样对于 id=0 这一行,在数据库里的最终结果还是 (0,5,5)。在 binlog 里面,执行序列是这样的:
insert into t values(1,1,5); /*(1,1,5)*/
update t set c=5 where id=1; /*(1,5,5)*/
update t set d=100 where d=5;/*所有d=5的行,d改成100*/
update t set d=5 where id=0; /*(0,0,5)*/
update t set c=5 where id=0; /*(0,5,5)*/
上图的binlog数据不一致的问题算是解决了。数值也是对的了。那么还有一个问题!
全部加锁解决了每个数据的正确性,那么新数据就无法保证正确性了。现在就不是读写锁可以解决的了。
如何解决幻读?间隙锁!
今天我们聊一下间隙锁。简单介绍一下。比如一个表中有6行数据。那么就会加7个间隙锁。这7个锁就分布在每条记录的前后。
当你执行 select * from t where d=5 for update 的时候。就不止是给数据库中已有的 6 个记录加上了行锁,还同时加了 7 个间隙锁。这样就确保了无法再插入新的记录。
数据行是可以加上锁的实体,数据行之间的间隙,也是可以加上锁的实体。
行锁,间隙锁,读锁,写锁
行锁分为:读锁,写锁。
间隙锁是单独的一个锁。
也就是说,跟行锁有冲突关系的是“另外一个行锁”。
跟间隙锁存在冲突关系的,是“往这个间隙中插入一个记录”这个操作。间隙锁之间都不存在冲突关系。
举例说明一下
sessionA开启一个事务 并且给c为7的数据加了一个读锁。
session B 并不会被堵住。因为表 t 里并没有 c=7 这个记录,因此 session A 加的是间隙锁 (5,10)。而 session B 也是在这个间隙加的间隙锁。它们有共同的目标,即:保护这个间隙,不允许插入值。但,它们之间是不冲突的。
间隙锁和行锁合称 next-key lock,每个 next-key lock 是前开后闭区间
那么我们在使用for update的时候也就是加了7 个 next-key lock,分别是 (-∞,0]、(0,5]、(5,10]、(10,15]、(15,20]、(20, 25]、(25, +supremum]。
supremum:因为 +∞是开区间。实现上,InnoDB 给每个索引加了一个不存在的最大值 supremum,这样才符合我们前面说的“都是前开后闭区间”。
回到案例
间隙锁和 next-key lock 的引入,帮我们解决了幻读的问题,但同时也带来了一些“困扰”。
我们先引一个逻辑出来继续理论!
**业务逻辑 **是这样的:任意锁住一行,如果这一行不存在的话就插入,如果存在这一行就更新它的数据
begin;
select * from t where id=N for update;
/*如果行不存在*/
insert into t values(N,N,N);
/*如果行存在*/
update t set d=N set id=N;
commit;
这个逻辑一旦有并发,就会碰到死锁。你一定也觉得奇怪,这个逻辑每次操作前用 for update 锁起来,已经是最严格的模式了,怎么还会有死锁呢?
如下图,假设N=9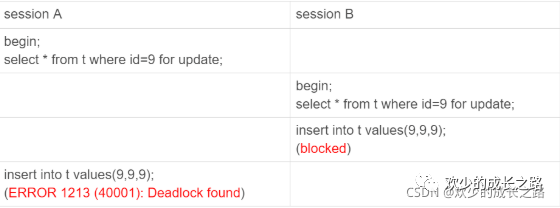
session A 执行 select … for update 语句,由于 id=9 这一行并不存在,因此会加上间隙锁 (5,10);
session B 执行 select … for update 语句,同样会加上间隙锁 (5,10),间隙锁之间不会冲突,因此这个语句可以执行成功;
session B 试图插入一行 (9,9,9),被 session A 的间隙锁挡住了,只好进入等待;
session A 试图插入一行 (9,9,9),被 session B 的间隙锁挡住了。
至此,两个 session 进入互相等待状态,形成死锁。当然,InnoDB 的死锁检测马上就发现了这对死锁关系,让 session A 的 insert 语句报错返回了。
结论:间隙锁的引入,可能会导致同样的语句锁住更大的范围,这其实是影响了并发度的
业务权衡
一开始我们就提到了,幻读只会出现在可重复隔离级别情况下。间隙锁是在可重复读隔离级别下才会生效的。
所以,你如果把隔离级别设置为读提交的话,就没有间隙锁了。但同时,你要解决可能出现的数据和日志不一致问题,需要把 binlog 格式设置为 row。这,也是现在不少公司使用的配置组合。
总结
生产库上会经常出现由于间隙锁导致的死锁现象。行锁确实比较直观,判断规则也相对简单,间隙锁的引入会影响系统的并发度,也增加了锁分析的复杂度,但也有章可循