
Docker环境部署Prometheus+Grafana监控系统
点击“程序员面试吧”,选择“星标🔝”
点击文末“阅读原文”解锁资料!
一、Prometheus简介
Prometheus是由SoundCloud开发的开源监控报警系统和时序列数据库(TSDB)。

Prometheus使用Go语言开发,是Google BorgMon监控系统的开源版本。2016年由Google发起Linux基金会旗下的原生云基金会(Cloud Native Computing Foundation), 将Prometheus纳入其下第二大开源项目。Prometheus目前在开源社区相当活跃。Prometheus和Heapster(Heapster是K8S的一个子项目,用于获取集群的性能数据。)相比功能更完善、更全面。Prometheus性能也足够支撑上万台规模的集群。
1.系统架构图
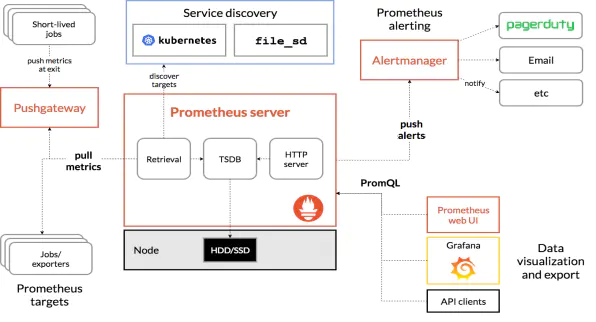
2.基本原理
Prometheus的基本原理是通过HTTP协议周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口就可以接入监控。不需要任何SDK或者其他的集成过程。这样做非常适合做虚拟化环境监控系统,比如VM、Docker、Kubernetes等。输出被监控组件信息的HTTP接口被叫做exporter 。目前互联网公司常用的组件大部分都有exporter可以直接使用,比如Varnish、Haproxy、Nginx、MySQL、Linux系统信息(包括磁盘、内存、CPU、网络等等)。
其大概的工作流程是:
Prometheus server 定期从配置好的 jobs 或者 exporters 中拉 metrics,或者接收来自 Pushgateway 发过来的 metrics,或者从其他的 Prometheus server 中拉 metrics。 Prometheus server 在本地存储收集到的 metrics,并运行已定义好的 alert.rules,记录新的时间序列或者向 Alertmanager 推送警报。 Alertmanager 根据配置文件,对接收到的警报进行处理,发出告警。 在Grafana图形界面中,可视化查看采集数据。
3.Prometheus的特性
多维度数据模型。
灵活的查询语言。
不依赖分布式存储,单个服务器节点是自主的。
通过基于HTTP的pull方式采集时序数据。
可以通过中间网关进行时序列数据推送。
通过服务发现或者静态配置来发现目标服务对象。
支持多种多样的图表和界面展示,比如Grafana等。
4.Prometheus的组件
Prometheus Server 主要负责数据采集和存储,提供PromQL查询语言的支持。
Alertmanager 警告管理器,用来进行报警。
Push Gateway 支持临时性Job主动推送指标的中间网关。
Exporters 输出被监控组件信息的HTTP接口。
Grafana 监控数据展示Web UI。
5.服务发现
由于 Prometheus 是通过 Pull 的方式主动获取监控数据,也就是每隔几秒钟去各个target采集一次metric。所以需要手工指定监控节点的列表,当监控的节点增多之后,每次增加节点都需要更改配置文件,尽管可以使用接口去热更新配置文件,但仍然非常麻烦,这个时候就需要通过服务发现(service discovery,SD)机制去解决。
Prometheus 支持多种服务发现机制,可以自动获取要收集的 targets,包含的服务发现机制包括:azure、consul、dns、ec2、openstack、file、gce、kubernetes、marathon、triton、zookeeper(nerve、serverset),配置方法可以参考手册的配置页面。可以说 SD 机制是非常丰富的,但目前由于开发资源有限,已经不再开发新的 SD 机制,只对基于文件的 SD 机制进行维护。针对我们现有的系统情况,我们选择了静态配置方式。
二、部署PrometheusServer
1. 使用官方镜像运行
由于Prometheus官方镜像没有开启热加载功能,而且时区相差八小时,所以我们选择了自己制作镜像,当然你也可以使用官方的镜像,提前创建Prometheus配置文件prometheus.yml和Prometheus规则文件rules.yml,然后通过如下命令挂载到官方镜像中运行:
$ docker run -d -p 9090:9090 --name=prometheus \
-v /root/prometheus/conf/:/etc/prometheus/ \
prom/prometheus
使用官方镜像部署可以参考我的这篇文章:Docker部署Prometheus实现微信邮件报警。
2. 制作镜像
现在我们创建自己的Prometheus镜像,当然你也可以直接使用我制作的镜像
$ docker pull zhanganmin2017/prometheus:v2.9.0
首先去Prometheus下载二进制文件安装包解压到package目录下,我的Dockerfile目录结构如下:
$ tree prometheus-2.9.0/
prometheus-2.9.0/
├── conf
│ ├── CentOS7-Base-163.repo
│ ├── container-entrypoint
│ ├── epel-7.repo
│ ├── prometheus-start.conf
│ ├── prometheus-start.sh
│ ├── prometheus.yml
│ ├── rules
│ │ └── service_down.yml
│ └── supervisord.conf
├── Dockerfile
└── package
├── console_libraries
├── consoles
├── LICENSE
├── NOTICE
├── prometheus
├── prometheus.yml
└── promtool
5 directories, 26 files
分别创建图中的目录,可以看到conf目录中有一些名为supervisord的文件,这是因为在容器中的进程我们选择使用supervisor进行管理,当然如果不想使用的化可以进行相应的修改。
制作prometheus-start.sh启动脚本,Supervisor启动Prometheus会调用该脚本
#!/bin/bash
/bin/prometheus \
--config.file=/data/prometheus/prometheus.yml \
--storage.tsdb.path=/data/prometheus/data \
--web.console.libraries=/data/prometheus/console_libraries \
--web.enable-lifecycle \
--web.console.templates=/data/prometheus/consoles
制作Prometheus-start.conf启动文件,Supervisord的配置文件
[program:prometheus]
command=sh /etc/supervisord.d/prometheus-start.sh ; 程序启动命令
autostart=false ; 在supervisord启动的时候不自动启动
startsecs=10 ; 启动10秒后没有异常退出,就表示进程正常启动了,默认1秒
autorestart=false ; 关闭程序退出后自动重启,可选值:[unexpected,true,false],默认为unexpected,表示进程意外杀死才重启
startretries=0 ; 启动失败自动重试次数,默认是3
user=root ; 用哪个用户启动进程,默认是root
redirect_stderr=true ; 把stderr重定向到stdout,默认false
stdout_logfile_maxbytes=20MB ; stdout 日志文件大小,默认是50MB
stdout_logfile_backups=30 ; stdout 日志文件备份数,默认是10;
# stdout 日志文件,需要注意当指定目录不存在时无法正常启动,所以需要手动创建目录(supervisord 会自动创建日志文件)
stdout_logfile=/data/prometheus/prometheus.log
stopasgroup=true
killasgroup=tru
制作supervisord.conf启动文件
[unix_http_server]
file=/var/run/supervisor.sock ; (the path to the socket file)
chmod=0700 ; sockef file mode (default 0700)
[supervisord]
logfile=/var/log/supervisor/supervisord.log ; (main log file;default $CWD/supervisord.log)
pidfile=/var/run/supervisord.pid ; (supervisord pidfile;default supervisord.pid)
childlogdir=/var/log/supervisor ; ('AUTO' child log dir, default $TEMP)
user=root
minfds=10240
minprocs=200
[rpcinterface:supervisor]
supervisor.rpcinterface_factory = supervisor.rpcinterface:make_main_rpcinterface
[supervisorctl]
serverurl=unix:///var/run/supervisor.sock ; use a unix:// URL for a unix socket
[program:sshd]
command=/usr/sbin/sshd -D
autostart=true
autorestart=true
stdout_logfile=/var/log/supervisor/ssh_out.log
stderr_logfile=/var/log/supervisor/ssh_err.log
[include]
files = /etc/supervisord.d/*.conf
制作container-entrypoint守护文件,容器启动后执行的脚本
#!/bin/sh
set -x
if [ ! -d "/data/prometheus" ];then
mkdir -p /data/prometheus/data
fi
mv /usr/local/src/* /data/prometheus/
exec /usr/bin/supervisord -n
exit
在conf目录下新建Prometheus.yml配置文件,这个是Prometheus配置监控主机的文件
global:
scrape_interval: 60s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 60s # Evaluate rules every 15 seconds. The default is every 1 minute.
alerting:
alertmanagers:
- static_configs:
- targets: [ '192.168.133.110:9093']
rule_files:
- "rules/host_sys.yml"
scrape_configs:
- job_name: 'Host'
static_configs:
- targets: ['10.1.250.36:9100']
labels:
appname: 'DEV01_250.36'
- job_name: 'prometheus'
static_configs:
- targets: [ '10.1.133.210:9090']
labels:
appname: 'Prometheus'
在conf目录下新建rules目录,编写service_down.yml规则文件,这个也可以等到容器创建后再编写,这里我们就直接写好添加到镜像中
groups:
- name: servicedown
rules:
- alert: InstanceDown
expr: up == 0
for: 1m
labels:
name: instance
severity: Critical
annotations:
summary: " {{ $labels.appname }}"
description: " 服务停止运行 "
value: "{{ $value }}"
制作dockerfile 镜像文件
FROM docker.io/centos:7
MAINTAINER from zhanmin@1an.com
# install repo
RUN rm -rf /etc/yum.repos.d/*.repo
ADD conf/CentOS7-Base-163.repo /etc/yum.repos.d/
ADD conf/epel-7.repo /etc/yum.repos.d/
# yum install
RUN yum install -q -y openssh-server openssh-clients net-tools \
vim supervisor && yum clean all
# install sshd
RUN ssh-keygen -q -N "" -t rsa -f /etc/ssh/ssh_host_rsa_key \
&& ssh-keygen -q -N "" -t ecdsa -f /etc/ssh/ssh_host_ecdsa_key \
&& ssh-keygen -q -N "" -t ed25519 -f /etc/ssh/ssh_host_ed25519_key \
&& sed -i 's/#UseDNS yes/UseDNS no/g' /etc/ssh/sshd_config
# UTF-8 and CST +0800
ENV LANG=zh_CN.UTF-8
RUN echo "export LANG=zh_CN.UTF-8" >> /etc/profile.d/lang.sh \
&& ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime \
&& localedef -c -f UTF-8 -i zh_CN zh_CN.utf8
# install Prometheus
COPY package/prometheus /bin/prometheus
COPY package/promtool /bin/promtool
COPY package/console_libraries/ /usr/local/src/console_libraries/
COPY package/consoles/ /usr/local/src/consoles/
COPY conf/prometheus.yml /usr/local/src/prometheus.yml
COPY conf/rules/ /usr/local/src/rules/
# create user
RUN echo "root:123456" | chpasswd
# supervisord
ADD conf/supervisord.conf /etc/supervisord.conf
ADD conf/prometheus-start.conf /etc/supervisord.d/prometheus-start.conf
ADD conf/container-entrypoint /container-entrypoint
ADD conf/prometheus-start.sh /etc/supervisord.d/prometheus-start.sh
RUN chmod +x /container-entrypoint
# cmd
CMD ["/container-entrypoint"]
Dockerfile中安装了supervisor进程管理工具和SSH服务,指定了字符集和时区。
生成镜像并运行容器服务
$ docker build -t zhanganmin2017/prometheus:v2.9.0 .
$ docker run -itd -h prometheus139-210 -m 8g --cpuset-cpus=28-31 --name=prometheus139-210 --network trust139 --ip=10.1.133.28 -v /data/works/prometheus139-210:/data 192.168.166.229/1an/prometheus:v2.9.0
$ docker exec -it prometheus139-210 /bin/bash
$ supervisorctl start prometheus首先去Prometheus
访问prometheus Web页面 IP:9090
三、部署监控组件Exporter
Prometheus 是使用 Pull 的方式来获取指标数据的,要让 Prometheus 从目标处获得数据,首先必须在目标上安装指标收集的程序,并暴露出 HTTP 接口供 Prometheus 查询,这个指标收集程序被称为 Exporter ,不同的指标需要不同的 Exporter 来收集,目前已经有大量的 Exporter 可供使用,几乎囊括了我们常用的各种系统和软件,官网列出了一份常用Exporter的清单 ,各个 Exporter 都遵循一份端口约定,避免端口冲突,即从 9100 开始依次递增,这里是完整的 Exporter端口列表 。另外值得注意的是,有些软件和系统无需安装 Exporter,这是因为他们本身就提供了暴露 Prometheus 格式的指标数据的功能,比如 Kubernetes、Grafana、Etcd、Ceph 等。
1. 部署主机监控组件
各节点主机使用主机网络模式部署主机监控组件node-exporter,官方不建议将其部署为Docker容器,因为该node_exporter设计用于监控主机系统。需要访问主机系统,而且通过容器的方式部署发现磁盘数据不太准确。二进制部署就去看项目文档吧
$ docker run -d \
--net="host" \
--pid="host" \
-v "/:/host:ro,rslave" \
quay.io/prometheus/node-exporter \
--path.rootfs=/host
容器正常运行后,进入Prometheus容器,在Prometheus.yml 文件中添加node-exporter组件地址
$ docker exec -it prometheus-133-210 /bin/bash
$ vim /data/prometheus/prometheus.yml
global:
scrape_interval: 60s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 60s # Evaluate rules every 15 seconds. The default is every 1 minute.
rule_files:
- "rules/service_down.yml"
scrape_configs:
- job_name: 'Host'
static_configs:
- targets: ['10.1.250.36:9100'] #node-exporter地址
labels:
appname: 'DEV01_250.36' #添加的标签
- job_name: 'prometheus'
static_configs:
- targets: [ '10.2.139.210:9090']
labels:
appname: 'prometheus'
热加载更新Prometheus
$ curl -X POST http://10.1.133.210:9090/-/reload
查看Prometheus的web页面已经可以看到node-exporter,然后我们就可以定义报警规则和展示看板了,这部分内容在后面配置Alertmanager和Grafana上会详细介绍。
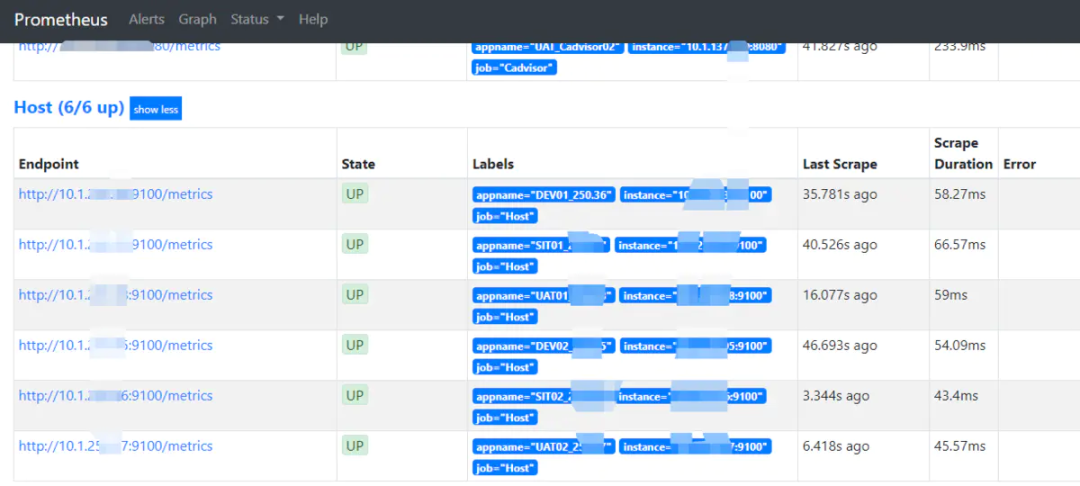
2.部署容器监控组件
各节点主机部署容器监控组件cadvisor-exporter,我这边Docker网络使用的macvlan方式,所以直接给容器分配了IP地址。
# docker run -d -h cadvisor139-216 --name=cadvisor139-216 --net=none -m 8g --cpus=4 --ip=10.1.139.216 --volume=/:/rootfs:ro --volume=/var/run:/var/run:rw --volume=/sys:/sys:ro --volume=/var/lib/docker/:/var/lib/docker:ro --volume=/dev/disk/:/dev/disk:ro google/cadvisor:latest
同样的,容器正常运行后,我们访问Cadvisor的Web页面 IP+8080 端口

现在我们进入Prometheus容器,在prometheus.yml主机文件中添加cadvisor组件
-----------
- job_name: 'Cadvisor'
static_configs:
- targets: [ '10.1.139.216:8080']
labels:
appname: 'DEV_Cadvisor01'
热加载更新Prometheus
$ curl -X POST http://10.1.133.210:9090/-/reload
可以看到,Prometheus添加的cadvisor状态为UP,说明正常接收数据。
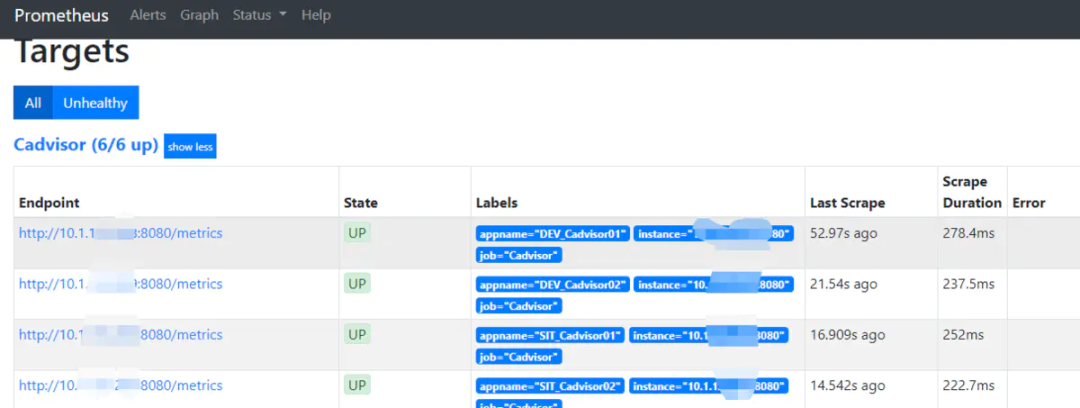
3. 部署Redis监控组件
容器部署Redis服务监控组件redis_exporter,--redis.passwd指定认证口令,如果你的redis访问没有密码那么就无需指定后面参数。
$ docker run -d -h redis_exporter139-218 --name redis_exporter139-218 --network trust139 --ip=10.1.139.218 -m 8g --cpus=4 oliver006/redis_exporter --redis.passwd 123456
在prometheus.yml 添加redis-exporter
---------
- job_name: 'Redis-exporter' #exporter地址
static_configs:
- targets: ['10.2.139.218:9121'']
labels:
appname: 'redis-exporter'
- job_name: 'RedisProxy' #需要监控的redis地址
static_configs:
- targets:
- redis://10.2.139.70:6379
- redis://10.2.139.71:6379
labels:
appname: RedisProxy
metrics_path: /scrape
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 10.2.139.218:9121
然后热加载更新,步骤同上。
4.部署应用监控组件
中间件部署JVM监控组件jmx_exporter, 这种方式是适用于代码中没有暴露应用metrics信息的服务,无需进行代码改动,在应用启动时调用该jar包暴露jmx信息,然后在Prometheus分别指定应用的地址即可。
首先下载jar :https://github.com/prometheus/jmx_exporter(jmx_prometheus_javaagent-0.11.0.jar ) 下载配置文件,有tomcat和weblogic注意区分:https://github.com/prometheus/jmx_exporter/tree/master/example_configs 然后在中间件启动参数添加以下内容,指定配置文件和jar包的路径:
CATALINA_OPTS="-javaagent:/app/tomcat-8.5.23/lib/jmx_prometheus_javaagent-0.11.0.jar=12345:/app/tomcat-8.5.23/conf/config.yaml"
上面我指定暴露metrics信息的端口为12345,所以我们在prometheus.yml文件中添加即可:
---------
- job_name: 'MIDL'
static_configs:
- targets: ['192.168.166.18:12345','192.168.166.19:12345']
labels:
appname: 'ORDER'
- targets: ['10.2.139.111:12345','10.2.139.112:12345']
labels:
appname: 'WEB'
其他步骤同上,Prometheus热加载更新即可。
5. 部署进程监控组件
因为我们容器是使用单独的网络部署的,相当于胖容器的方式,所以需要在监控的容器中部署process-exporter进程监控组件来监控容器的进程,
软件包下载:
wget https://github.com/ncabatoff/process-exporter/releases/download/v0.5.0/process-exporter-0.5.0.linux-amd64.tar.gz
配置文件:process-name.yaml
process_names:
- name: "{{.Matches}}"
cmdline:
- 'redis-shake' #匹配进程,支持正则
启动参数:
$ nohup ./process-exporter -config.path process-name.yaml &
在Prometheus.yml 添加该容器的IP地址,端口号为9256
-----------
- job_name: 'process'
static_configs:
- targets: [ '10.2.139.186:9256']
labels:
appname: 'Redis-shake'
ok,现在我们热加载更新Prometheus的主机文件
$ curl -X POSThttp://10.2.139.210:9090/-/reload
四、部署Alertmanager报警组件
1. Alertmanager 概述
Alertmanager处理客户端应用程序(如Prometheus服务器)发送的告警。它负责对它们进行重复数据删除,分组和路由,以及正确的接收器集成,例如电子邮件,PagerDuty或OpsGenie。它还负责警报的静默和抑制。
以下描述了Alertmanager实现的核心概念。请参阅配置文档以了解如何更详细地使用它们。
分组(Grouping)
分组将类似性质的告警分类为单个通知。这在大型中断期间尤其有用,因为许多系统一次失败,并且可能同时发射数百到数千个警报。
示例:发生网络分区时,群集中正在运行数十或数百个服务实例。一半的服务实例无法再访问数据库。Prometheus中的告警规则配置为在每个服务实例无法与数据库通信时发送告警。结果,数百个告警被发送到Alertmanager。
作为用户,只能想要获得单个页面,同时仍能够确切地看到哪些服务实例受到影响。因此,可以将Alertmanager配置为按群集和alertname对警报进行分组,以便发送单个紧凑通知。
这些通知的接收器通过配置文件中的路由树配置告警的分组,定时的进行分组通知。抑制(Inhibition)
如果某些特定的告警已经触发,则某些告警需要被抑制。
示例:如果某个告警触发,通知无法访问整个集群。Alertmanager可以配置为在该特定告警触发时将与该集群有关的所有其他告警静音。这可以防止通知数百或数千个与实际问题无关的告警触发。静默(SILENCES)
静默是在给定时间内简单地静音告警的方法。基于匹配器配置静默,就像路由树一样。检查告警是否匹配或者正则表达式匹配静默。如果匹配,则不会发送该告警的通知。在Alertmanager的Web界面中可以配置静默。客户端行为(Client behavior)
Alertmanager对其客户的行为有特殊要求。这些仅适用于不使用Prometheus发送警报的高级用例。#制作镜像方式和Prometheus类似,稍作更改即可,此步省略。
设置警报和通知的主要步骤如下:
设置并配置Alertmanager; 配置Prometheus对Alertmanager访问; 在普罗米修斯创建警报规则;
2. 部署Alertmanager组件
首先需要创建Alertmanager的报警通知文件,我这里使用企业微信报警,其中企业微信需要申请账号认证,方式如下:
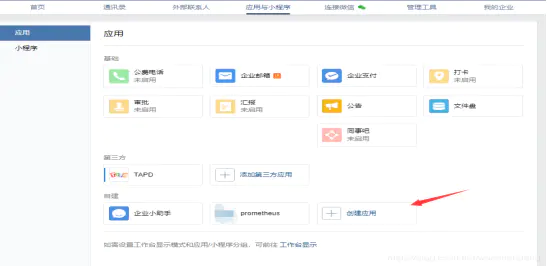
访问网站注册企业微信账号(不需要企业认证)。
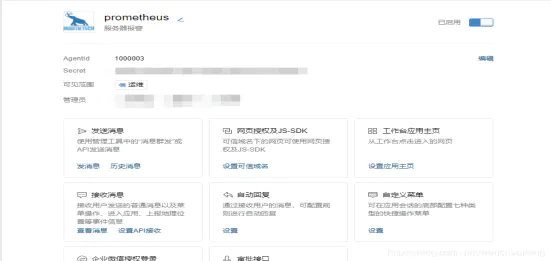
访问apps创建第三方应用,点击创建应用按钮 -> 填写应用信息:
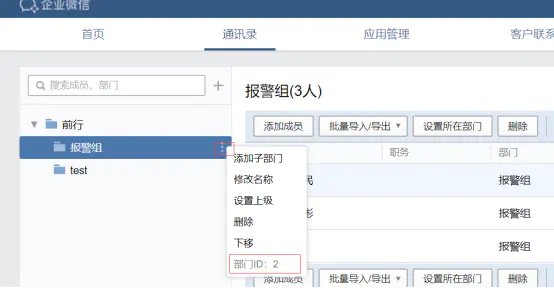
创建报警组,获取组ID:
新建alertmanager.yml报警通知文件
global:
resolve_timeout: 2m
smtp_smarthost: smtp.163.com:25
smtp_from: 15xxx@163.com
smtp_auth_username: 15xxxx@163.com
smtp_auth_password: zxxx
templates:
- '/data/alertmanager/conf/template/wechat.tmpl'
route:
group_by: ['alertname_wechat']
group_wait: 1s
group_interval: 1s
receiver: 'wechat'
repeat_interval: 1h
routes:
- receiver: wechat
match_re:
serverity: wechat
receivers:
- name: 'email'
email_configs:
- to: '8xxxxx@qq.com'
send_resolved: true
- name: 'wechat'
wechat_configs:
- corp_id: 'wwd402ce40b4720f24'
to_party: '2'
agent_id: '1000002'
api_secret: '9nmYa4p12OkToCbh_oNc'
send_resolved: true ## 发送已解决通知
参数说明:
corp_id: 企业微信账号唯一 ID, 可以在我的企业中查看。
to_party: 需要发送的组。
agent_id: 第三方企业应用的 ID,可以在自己创建的第三方企业应用详情页面查看。
api_secret: 第三方企业应用的密钥,可以在自己创建的第三方企业应用详情页面查看。
然后我们创建企业微信的消息模板,template/wechat.tmpl
{{ define "wechat.default.message" }}
{{ range $i, $alert :=.Alerts }}
【系统报警】
告警状态:{{ .Status }}
告警级别:{{ $alert.Labels.severity }}
告警应用:{{ $alert.Annotations.summary }}
告警详情:{{ $alert.Annotations.description }}
触发阀值:{{ $alert.Annotations.value }}
告警主机:{{ $alert.Labels.instance }}
告警时间:{{ $alert.StartsAt.Format "2006-01-02 15:04:05" }}
{{ end }}
{{ end }}
这个报警的模板其中的值是在Prometheus触发的报警信息中提取的,所以你可以根据自己的定义进行修改。
运行Alertmanager容器
$ docker run -d -p 9093:9093 --name alertmanager -m 8g --cpus=4 -v /opt/alertmanager.yml:/etc/alertmanager/alertmanager.yml -v /opt/template:/etc/alertmanager/template docker.io/prom/alertmanager:latest
容器运行完成后查看web页面 IP:9093
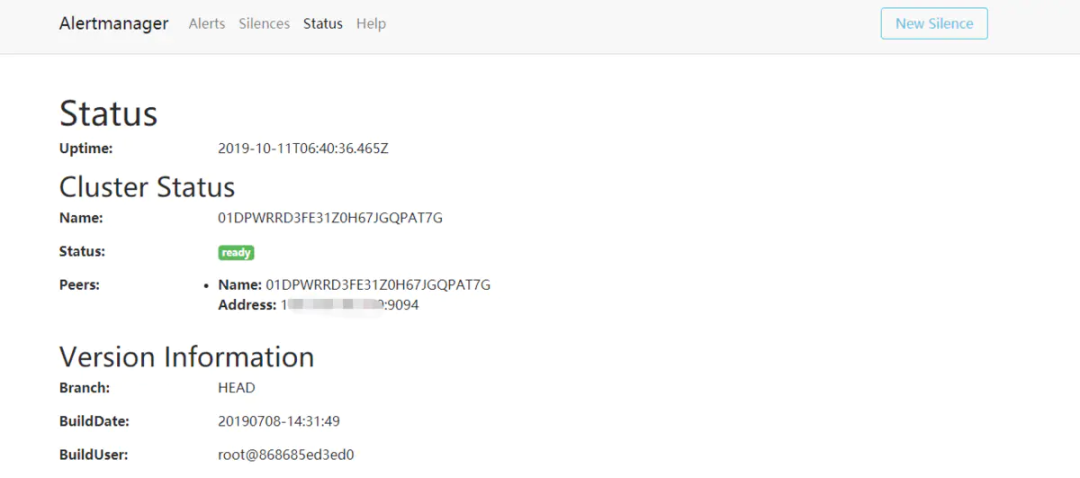
3. 配置报警规则
Prometheus的报警规则通过PromQL语句编写
进入Prometheus容器的rules目录,上面我们制作镜像的时候已经创建好并挂载到了容器中,现在我们编写其他的规则文件
编写主机监控规则文件,rules/host_sys.yml
cat host_sys.yml
groups:
- name: Host
rules:
- alert: HostMemory Usage
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 90
for: 1m
labels:
name: Memory
severity: Warning
annotations:
summary: " {{ $labels.appname }} "
description: "宿主机内存使用率超过90%."
value: "{{ $value }}"
- alert: HostCPU Usage
expr: sum(avg without (cpu)(irate(node_cpu_seconds_total{mode!='idle'}[5m]))) by (instance,appname) > 0.8
for: 1m
labels:
name: CPU
severity: Warning
annotations:
summary: " {{ $labels.appname }} "
description: "宿主机CPU使用率超过80%."
value: "{{ $value }}"
- alert: HostLoad
expr: node_load5 > 20
for: 1m
labels:
name: Load
severity: Warning
annotations:
summary: "{{ $labels.appname }} "
description: " 主机负载5分钟超过20."
value: "{{ $value }}"
- alert: HostFilesystem Usage
expr: (node_filesystem_size_bytes-node_filesystem_free_bytes)/node_filesystem_size_bytes*100>80
for: 1m
labels:
name: Disk
severity: Warning
annotations:
summary: " {{ $labels.appname }} "
description: " 宿主机 [ {{ $labels.mountpoint }} ]分区使用超过80%."
value: "{{ $value }}%"
- alert: HostDiskio writes
expr: irate(node_disk_writes_completed_total{job=~"Host"}[1m]) > 10
for: 1m
labels:
name: Diskio
severity: Warning
annotations:
summary: " {{ $labels.appname }} "
description: " 宿主机 [{{ $labels.device }}]磁盘1分钟平均写入IO负载较高."
value: "{{ $value }}iops"
- alert: HostDiskio reads
expr: irate(node_disk_reads_completed_total{job=~"Host"}[1m]) > 10
for: 1m
labels:
name: Diskio
severity: Warning
annotations:
summary: " {{ $labels.appname }} "
description: " 宿机 [{{ $labels.device }}]磁盘1分钟平均读取IO负载较高."
value: "{{ $value }}iops"
- alert: HostNetwork_receive
expr: irate(node_network_receive_bytes_total{device!~"lo|bond[0-9]|cbr[0-9]|veth.*|virbr.*|ovs-system"}[5m]) / 1048576 > 10
for: 1m
labels:
name: Network_receive
severity: Warning
annotations:
summary: " {{ $labels.appname }} "
description: " 宿主机 [{{ $labels.device }}] 网卡5分钟平均接收流量超过10Mbps."
value: "{{ $value }}3Mbps"
- alert: hostNetwork_transmit
expr: irate(node_network_transmit_bytes_total{device!~"lo|bond[0-9]|cbr[0-9]|veth.*|virbr.*|ovs-system"}[5m]) / 1048576 > 10
for: 1m
labels:
name: Network_transmit
severity: Warning
annotations:
summary: " {{ $labels.appname }} "
description: " 宿主机 [{{ $labels.device }}] 网卡5分钟内平均发送流量超过10Mbps."
value: "{{ $value }}3Mbps"
编写容器监控规则文件,rules/container_sys.yml
groups:
- name: Container
rules:
- alert: ContainerCPU
expr: (sum by(name,instance) (rate(container_cpu_usage_seconds_total{image!=""}[5m]))*100) > 200
for: 1m
labels:
name: CPU_Usage
severity: Warning
annotations:
summary: "{{ $labels.name }} "
description: " 容器CPU使用超200%."
value: "{{ $value }}%"
- alert: Memory Usage
expr: (container_memory_usage_bytes{name=~".+"} - container_memory_cache{name=~".+"}) / container_spec_memory_limit_bytes{name=~".+"} * 100 > 200
for: 1m
labels:
name: Memory
severity: Warning
annotations:
summary: "{{ $labels.name }} "
description: " 容器内存使用超过200%."
value: "{{ $value }}%"
- alert: Network_receive
expr: irate(container_network_receive_bytes_total{name=~".+",interface=~"eth.+"}[5m]) / 1048576 > 10
for: 1m
labels:
name: Network_receive
severity: Warning
annotations:
summary: "{{ $labels.name }} "
description: "容器 [{{ $labels.device }}] 网卡5分钟平均接收流量超过10Mbps."
value: "{{ $value }}Mbps"
- alert: Network_transmit
expr: irate(container_network_transmit_bytes_total{name=~".+",interface=~"eth.+"}[5m]) / 1048576 > 10
for: 1m
labels:
name: Network_transmit
severity: Warning
annotations:
summary: "{{ $labels.name }} "
description: "容器 [{{ $labels.device }}] 网卡5分钟平均发送流量超过10Mbps."
value: "{{ $value }}Mbps"
编写redis监控规则文件,redis_check.yml
groups:
- name: redisdown
rules:
- alert: RedisDown
expr: redis_up == 0
for: 1m
labels:
name: instance
severity: Critical
annotations:
summary: " {{ $labels.alias }}"
description: " 服务停止运行 "
value: "{{ $value }}"
- alert: Redis linked too many clients
expr: redis_connected_clients / redis_config_maxclients * 100 > 80
for: 1m
labels:
name: instance
severity: Warning
annotations:
summary: " {{ $labels.alias }}"
description: " Redis连接数超过最大连接数的80%. "
value: "{{ $value }}"
- alert: Redis linked
expr: redis_connected_clients / redis_config_maxclients * 100 > 80
for: 1m
labels:
name: instance
severity: Warning
annotations:
summary: " {{ $labels.alias }}"
description: " Redis连接数超过最大连接数的80%. "
value: "{{ $value }}"
编写服务停止监控规则,rules/service_down.yml
- alert: ProcessDown
expr: namedprocess_namegroup_num_procs == 0
for: 1m
labels:
name: instance
severity: Critical
annotations:
summary: " {{ $labels.appname }}"
description: " 进程停止运行 "
value: "{{ $value }}"
- alert: Grafana down
expr: absent(container_last_seen{name=~"grafana.+"} ) == 1
for: 1m
labels:
name: grafana
severity: Critical
annotations:
summary: "Grafana"
description: "Grafana容器停止运行"
value: "{{ $value }}"
编写报警规则可以参考后面Grafana展示看板后的数据展示语句,需要注意的是,我们容器使用的是胖容器的方式,即当作虚拟机来使用,所以需要添加应用和服务停止的Exporter,如果你的容器守护进程直接就是应用的话,只需要监控容器的启停就可以了。
测试微信报警
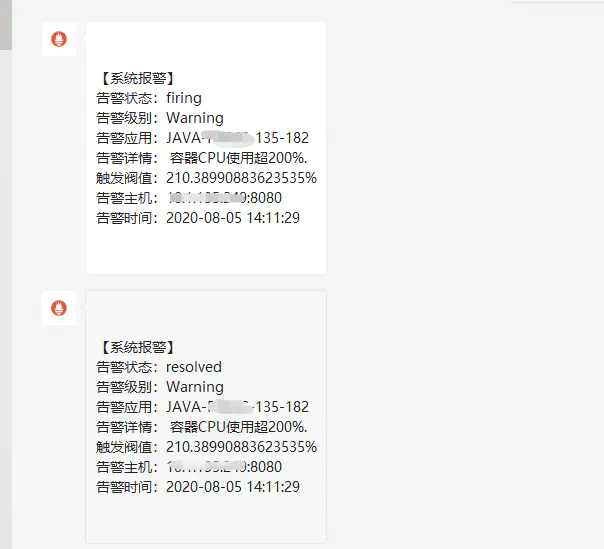
五、Grafana展示组件
虽然 Prometheus 提供的 Web UI 也可以很好的查看不同指标的视图,但是这个功能非常简单,只适合用来调试。要实现一个强大的监控系统,还需要一个能定制展示不同指标的面板,能支持不同类型的展现方式(曲线图、饼状图、热点图、TopN 等),这就是仪表盘(Dashboard)功能。
Prometheus 开发了一套仪表盘系统PromDash,不过很快这套系统就被废弃了,官方开始推荐使用 Grafana 来对 Prometheus 的指标数据进行可视化,这不仅是因为 Grafana 的功能非常强大,而且它和 Prometheus 可以完美的无缝融合。
Grafana是一个用于可视化大型测量数据的开源系统,它的功能非常强大,界面也非常漂亮,使用它可以创建自定义的控制面板,你可以在面板中配置要显示的数据和显示方式,它支持很多不同的数据源,比如:Graphite、InfluxDB、OpenTSDB、Elasticsearch、Prometheus 等,而且它也支持众多的插件 。
1. 部署Grafana服务容器
$ docker run -d -h grafana139-211 -m 8g --network trust139 --ip=10.2.139.211 --cpus=4 --name=grafana139-211 -e "GF_SERVER_ROOT_URL=http://10.2.139.211" -e "GF_SECURITY_ADMIN_PASSWORD=passwd" grafana/grafana
运行后访问IP:3000,user:admin pass:passwd

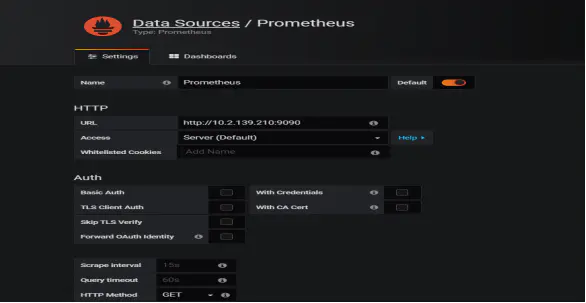
2. 添加Prometheus数据源
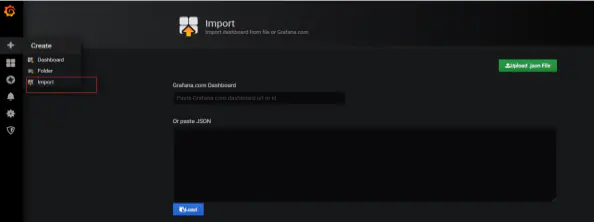
3. 导入监控模板
使用编号导入模板,Grafana服务需要联网,否则需要到Grafana模板下载JSON文件导入。
下面是我使用的几个模板,导入后可以根据自己的情况定义变量值
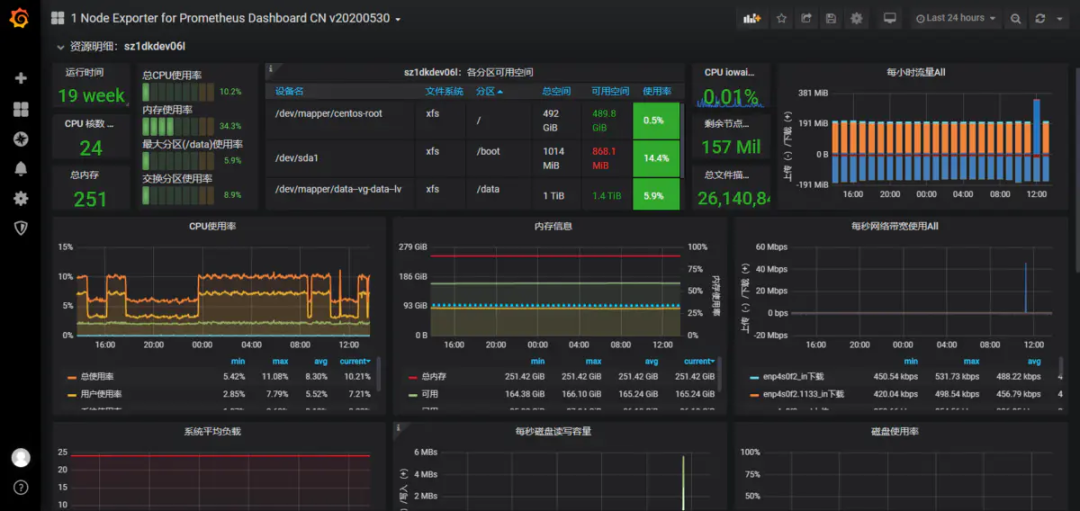
主机监控展示看板Node-exporter导入 8919 模板 容器监控展示看板cadvisor-exporter导入193 模板 应用监控展示看板jmx-exporter导入8563 模板 Redis监控展示看板Redis-exporter导入2751 模板 进程监控展示看板Process-exporter导入249 模板
六、PromQL语句
七、使用Concul HTTP注册方式实现服务发现
一般是用服务发现需要应用需要服务注册,我们这边因为微服务改造还没完成,还有一些tomcat和weblogic中间件,而且选用的注册中心是Eurka,所以为了在代码不改动的情况下使用服务发现,选择了concul 作为注册中心,因为是consul是可以通过http方式注册的。
1. consul 内部原理
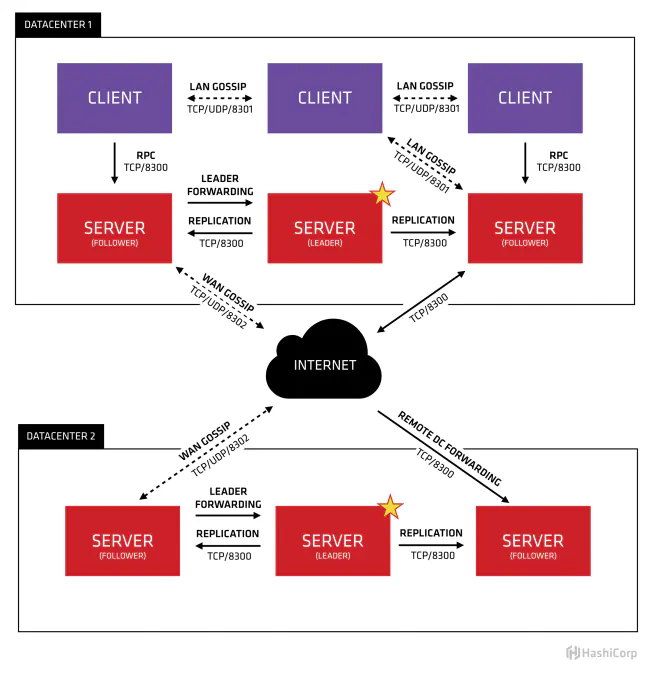
Consul分为Client和Server两种节点(所有的节点也被称为Agent),Server节点保存数据,Client负责健康检查及转发数据请求到Server;Server节点有一个Leader和多个Follower,Leader节点会将数据同步到Follower,Server的数量推荐是3个或者5个,在Leader挂掉的时候会启动选举机制产生一个新的Leader。
集群内的Consul节点通过gossip协议(流言协议)维护成员关系,也就是说某个节点了解集群内现在还有哪些节点,这些节点是Client还是Server。单个数据中心的流言协议同时使用TCP和UDP通信,并且都使用8301端口。跨数据中心的流言协议也同时使用TCP和UDP通信,端口使用8302。
集群内数据的读写请求既可以直接发到Server,也可以通过Client使用RPC转发到Server,请求最终会到达Leader节点,在允许数据轻微陈旧的情况下,读请求也可以在普通的Server节点完成,集群内数据的读写和复制都是通过TCP的8300端口完成。
具体consul的原理及架构请访问:http://blog.didispace.com/consul-service-discovery-exp/
2. 使用docker部署consul 集群
#启动第1个Server节点,集群要求要有3个Server,将容器8500端口映射到主机8900端口,同时开启管理界面
docker run -d --name=consul1 -p 8900:8500 -e CONSUL_BIND_INTERFACE=eth0 consul agent --server=true --bootstrap-expect=3 --client=0.0.0.0 -ui
#启动第2个Server节点,并加入集群
docker run -d --name=consul2 -e CONSUL_BIND_INTERFACE=eth0 consul agent --server=true --client=0.0.0.0 --join 172.17.0.1
#启动第3个Server节点,并加入集群
docker run -d --name=consul3 -e CONSUL_BIND_INTERFACE=eth0 consul agent --server=true --client=0.0.0.0 --join 172.17.0.2
#启动第4个Client节点,并加入集群
docker run -d --name=consul4 -e CONSUL_BIND_INTERFACE=eth0 consul agent --server=false --client=0.0.0.0 --join 172.17.0.2
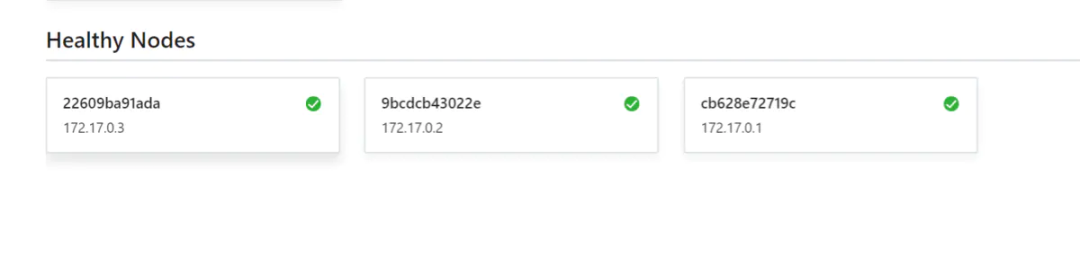
浏览器访问容器映射的8900端口:
3. 服务注册到Consul
使用HTTP API 方式注册node-exporter服务到Consul
curl -X PUT -d '{"id": "192.168.16.173","name": "node-exporter","address": "192.168.16.173","port": ''9100,"tags": ["DEV"], "checks": [{"http": "http://192.168.16.173:9100/","interval": "5s"}]}' http://172.17.0.4:8500/v1/agent/service/register
解注册:
curl --request PUT http://172.17.0.4:8500/v1/agent/service/deregister/192.168.166.14
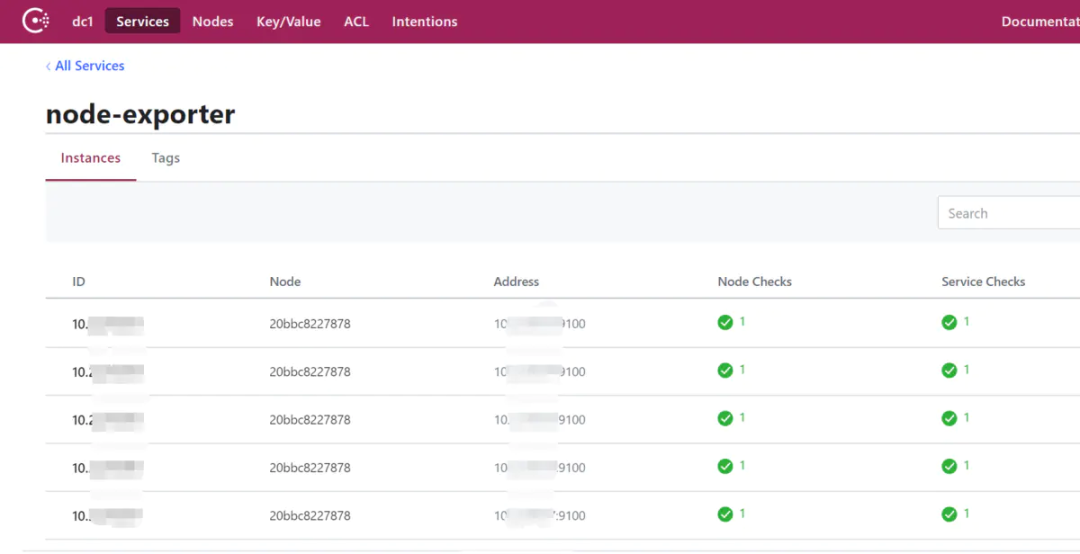
注册多个服务到consul,使用脚本:
#!/bin/bash
all_IP=`cat /opt/ip`
name=cadvisor
port=9100
for I in $all_IP
do
curl -X PUT -d '{"id": "'$I'","name": "'$name'","address": "'$I'","port": '$port',"tags": ["cadvisor"], "checks": [{"http": "http://'$I':'$port'/","interval": "5s"}]}' http://172.17.0.4:8500/v1/agent/service/register
done
4. Prometheus 配置consul 服务发现
consul 可以使用的元标签:
__meta_consul_address:目标的地址
__meta_consul_dc:目标的数据中心名称
__meta_consul_tagged_address_<key>:每个节点标记目标的地址键值
__meta_consul_metadata_<key>:目标的每个节点元数据键值
__meta_consul_node:为目标定义的节点名称
__meta_consul_service_address:目标的服务地址
__meta_consul_service_id:目标的服务ID
__meta_consul_service_metadata_<key>:目标的每个服务元数据键值
__meta_consul_service_port:目标的服务端口
__meta_consul_service:目标所属服务的名称
__meta_consul_tags:标记分隔符连接的目标的标记列表
修改Prometheus.yml 文件,使用relabel将consul的元标签重写便于查看
- job_name: 'consul'
consul_sd_configs:
- server: '192.168.16.173:8900'
services: [] #匹配所有service
relabel_configs:
- source_labels: [__meta_consul_service] #service 源标签
regex: "consul" #匹配为"consul" 的service
action: drop # 执行的动作
- source_labels: [__meta_consul_service] # 将service 的label重写为appname
target_label: appname
- source_labels: [__meta_consul_service_address]
target_label: instance
- source_labels: [__meta_consul_tags]
target_label: job
Prometheus 热加载更新
curl -X POST http://192.168.16.173:9090/-/reload
访问Prometheus web页面
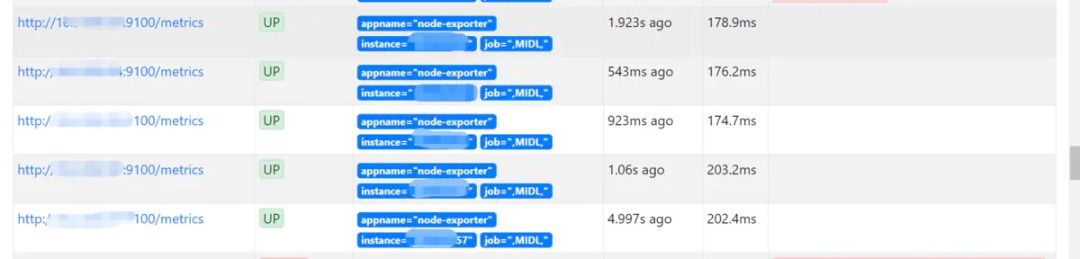
应用注册到consul
在不需要开发修改代码的前提下,我们可以使用Prometheus的jmx-exporter收集应用的相关指标,在应用中间件tomcat/weblogic等调用jmx-exporter,具体方式查看https://www.jianshu.com/p/dfd6ba5206dc
启动应用后会启动12345端口暴露jvm数据,现在我们要做的就是将这个端口注册到Consul上,然后Prometheus会从consul 拉取应用主机。
使用脚本实现
$ cat ip
TEST 192.168.166.10 192.168.166.11
UNMIN 192.168.166.12 192.168.166.13
---------------
$ cat consul.sh
#!/bin/bash
port=12345
while read app
do
echo ${app}
app_tmp=(${app})
echo ${app_tmp[0]}
length=${#app_tmp[@]}
echo ${length}
for((k=1;k<${length};k++));
do
echo ${app_tmp[k]}
curl -X PUT -d '{"id": "'${app_tmp[k]}'","name": "'${app_tmp[0]}'","address": "'${app_tmp[k]}'","port": '$port',"tags": ["MIDL"],"checks": [{"http": "http://'${app_tmp[k]}':'$port'/","interval": "5s"}]}' http://172.17.0.4:8500/v1/agent/service/register
done
done < ip
执行脚本注册到consul
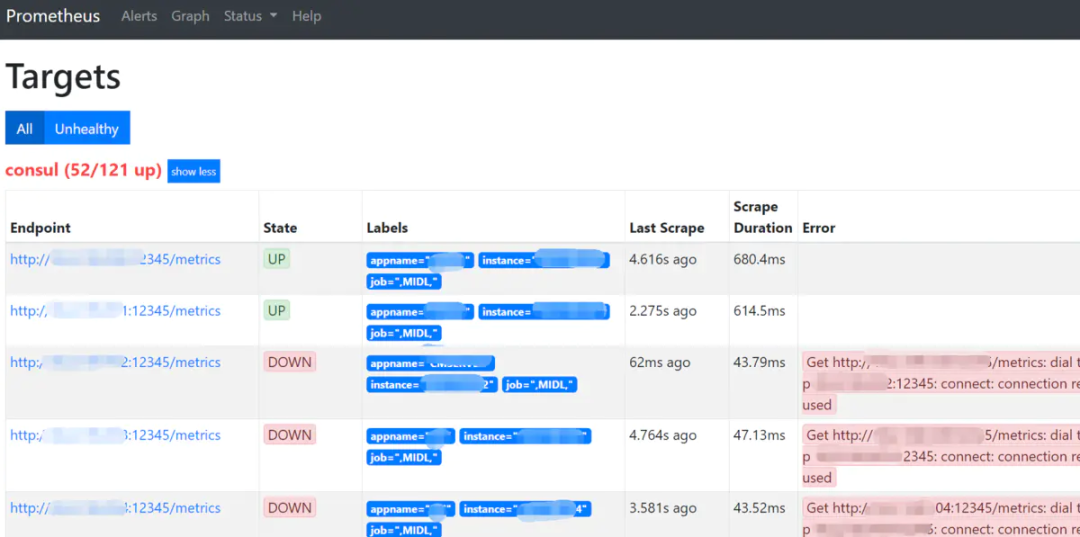
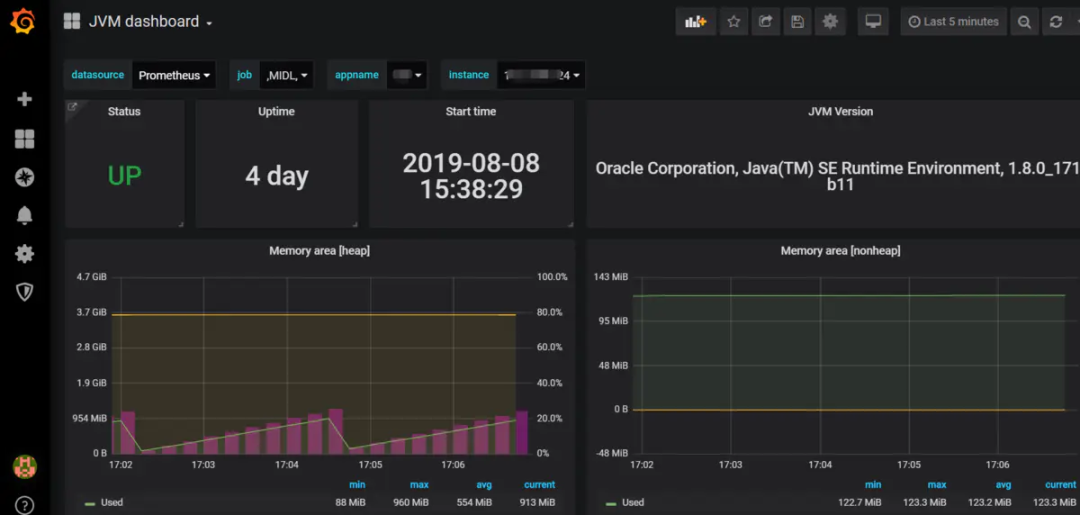
配置Grafana JVM 监控模板
Load 8563模板
原文链接:https://www.jianshu.com/p/dde0dc1761ec
文章转自:DevOps技术栈
(版权归原作者所有,侵删)

资料专区:Prometheus官方中文文档

这份Prometheus官方中文文档既适合小白入门也适合有一定基础的同学进阶提升。这份文档共分为7大部分,141页,点击文末阅读原文免费领取!(资料整理自网络,侵删歉)
点击阅读原文解锁资料!
