
Docker 容器监控系统初探
随着线上服务的全面docker化,对docker容器的监控就很重要了。SA的监控系统是物理机的监控,在一个物理机跑多个容器的情况下,我们是没法从一个监控图表里面区分各个容器的资源占用情况的。为了更好的监控容器运行情况,更重要的是为了后续的容器动态调度算法需要的大量运行时数据的搜集,经过调研后,基于CAdvisor + InfluxDB + Grafana搭建了这套容器监控系统。
1 容器监控方案选择
在调研容器监控系统的时候,其实是有很多选择的,比如docker自带的docker stats命令,Scout,Data Dog,Sysdig Cloud,Sensu Monitoring Framework,CAdvisor等。
通过docker stats命令可以很方便的看到当前宿主机上所有容器的CPU,内存以及网络流量等数据。但是docker stats命令的缺点就是统计的只是当前宿主机的所有容器,而获取的监控数据是实时的,没有地方存储,也没有报警功能。
➜ ssj docker statsCONTAINER CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDSf216e9be15bf 0.06% 76.27 MiB / 992.6 MiB 7.68% 5.94 kB / 2.13 kB 16.2 MB / 0 B 7ead53a6166f0 0.00% 8.703 MiB / 992.6 MiB 0.88% 578 B / 578 B 7.01 MB / 0 B 2
而Scout、Sysdig Cloud
,Data Dog虽然都提供了较完善的服务,但是它们都是托管的服务而且都收费,于是也不在考虑范围之内。Sensu Monitoring Framework集成度较高,也免费,但是部署过于复杂。最后,我们选择了CAdvisor做容器监控工具。
CAdvisor谷歌出品,优点是开源产品,监控指标齐全,部署方便,而且有官方的docker镜像。缺点是集成度不高,默认只在本地保存2分钟数据。不过在调研之后发现可以加上InfluxDB存储数据,对接Grafana展示图表,比较便利地搭建好了容器监控系统,数据收集和图表展示效果良好,对系统性能也几乎没有什么影响。
2 容器资源监控-CAdvisor
2.1 部署与运行
CAdvisor是一个容器资源监控工具,包括容器的内存,CPU,网络IO,磁盘IO等监控,同时提供了一个WEB页面用于查看容器的实时运行状态。CAdvisor默认存储2分钟的数据,而且只是针对单物理机。不过,CAdvisor提供了很多数据集成接口,支持InfluxDB,Redis,Kafka,Elasticsearch等集成,可以加上对应配置将监控数据发往这些数据库存储起来。
由于CAdvisor已经容器化,部署和运行很简单,执行如下命令即可:
docker run \--volume=/:/rootfs:ro \--volume=/var/run:/var/run:rw \--volume=/sys:/sys:ro \--volume=/var/lib/docker/:/var/lib/docker:ro \--volume=/dev/disk/:/dev/disk:ro \--publish=8080:8080 \--detach=true \--name=cadvisor \google/cadvisor:latest
运行之后,就可以在浏览器打开``http://ip:8080`查看宿主机的容器监控数据了。
2.2 集成InfluxDB
如前面说到,CAdvisor默认只在本机保存最近2分钟的数据,为了持久化存储数据和统一收集展示监控数据,需要将数据存储到InfluxDB中。InfluxDB是一个时序数据库,专门用于存储时序相关数据,很适合存储CAdvisor的数据。而且,CAdvisor本身已经提供了InfluxDB的集成方法,在启动容器时指定配置即可。我们使用了管理容器来管理CAdvisor,修改后的启动配置如下。主要指定了存储引擎为InfluxDB,以及指定InfluxDB的HTTP API的地址(这里用到了自建DNS的域名 influxdb.service.consul以避免暴露外部端口),还有对应的数据库和用户名密码。
{"binds": ["/:/rootfs:ro","/var/run:/var/run:rw","/sys:/sys:ro","/home/docker/var/lib/docker/:/var/lib/docker:ro"],"image": "forum-cadvisor","labels": {"type": "cadvisor"},"command": " -docker_only=true -storage_driver=influxdb -storage_driver_db=cadvisor -storage_driver_host=influxdb.service.consul:8086 -storage_driver_user=testuser -storage_driver_password=testpwd","tag": "latest","hostname": "cadvisor-{{lan_ip}}"}
注意到我们使用了一个自己的forum-cadvisor镜像来代替官方的cadvisor镜像,这是为了修复cadvisor一些问题以及基于管理方便性的考虑。
2.3 CAdvisor存在的问题
1)运行报错问题
运行最新的CAdvisor容器的时候,发现容器有如下的错误日志:
E0910 02:20:53.990423 1 fsHandler.go:121] failed to collect filesystem stats - rootDiskErr: <nil>, rootInodeErr: cmd [find /rootfs/home/docker/var/lib/docker/aufs/diff/2575b6816f03eee84c8915442129243fc03e0f5ce35c48dc42eb20a230384069 -xdev -printf .] failed. stderr: find: unrecognized: -printf这个问题是因为没有安装 findutils 工具导致的。
2)统计不到容器内存数据
Debian默认没有开启 CGroup Memory的支持,CAdvisor默认情况下无法统计到容器内存数据,需要修改GRUB启动参数,修改文件/etc/default/grub,加入下面这行:
GRUB_CMDLINE_LINUX=" cgroup_enable=memory"然后更新grub2重启即可。
# sudo update-grub2 && reboot3)网络流量监控数据错误问题
在CAdvisor上线一段时间后,顺安发现容器的网络数据跟实际情况不符,并查找资料后发现问题是因为CAdvisor默认只统计第一个网卡的流量,而在我们的容器中是有多个overlay网络的,需要统计容器中所有的网卡流量。于是我修改了CAdvisor统计网络流量部分的代码并重新编译了一个版本在线上使用,修改的代码在这里。
最后,我们自定义的镜像文件 forum-cadvisor.Dockerfile 是这样的(src/cadvisor是修改后重新编译的cadvisor可执行文件):
FROM google/cadvisor:latestRUN apk add --update findutils && rm -rf /var/cache/apk/*COPY src/cadvisor /usr/bin/cadvisor
2.4 CAdvisor原理简介
CAdvisor运行时挂载了宿主机根目录,docker根目录等多个目录,由此可以从中读取容器的运行时信息。docker基础技术有Linux namespace,Control Group(CGroup),AUFS等,其中CGroup用于系统资源限制和优先级控制的。
宿主机的/sys/fs/cgroup/目录下面存储的就是CGroup的内容了,CGroup包括多个子系统,如对块设备的blkio,cpu,内存,网络IO等限制。Docker在CGroup里面的各个子系统中创建了docker目录,而CAdvisor运行时挂载了宿主机根目录和 /sys目录,从而CAdvisor可以读取到容器的资源使用记录。比如下面可以看到容器b1f257当前时刻的CPU的使用统计。
# cat /sys/fs/cgroup/cpu/docker/b1f25723c5c3a17df5026cb60e1d1e1600feb293911362328bd17f671802dd31/cpuacct.statuser 95191system 5028
而容器网络流量CAdvisor是从/proc/PID/net/dev中读取的,如上面的容器b1f257进程在宿主机的PID为6748,可以看到容器所有网卡的接收和发送流量以及错误数等。CAdvisor定期读取对应目录下面的数据并定期发送到指定的存储引擎存储,而本地会默认存储最近2分钟的数据并提供UI界面查看。
# cat /proc/6748/net/devReceive | Transmitface |bytes packets errs drop fifo frame compressed multicast|bytes packets errs drop fifo colls carrier compressedeth0: 6266314 512 0 0 0 0 0 0 22787 292 0 0 0 0 0 0eth1: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0: 5926805 5601 0 0 0 0 0 0 5926805 5601 0 0 0 0 0 0
3 容器监控数据存储-InfluxDB
3.1 InfluxDB配置和运行
InfluxDB是一个开源的分布式时序数据库,使用GO语言开发。特别适合用于时序类型数据存储,CAdvisor搜集的容器监控数据用InfluxDB存储就很合适,而且CAdvisor本身就提供了InfluxDB的支持,集成起来非常方便。
由于线上服务都docker化了,所以InfluxDB我们也是选择用容器来跑,通过容器管理系统统一管理。容器运行时的核心配置如下,主要挂载了数据库目录,以及配置了consul的服务注册,这样,CAdvisor由于和InfluxDB处于同一个overlay子网中,不需要再开放端口给外部访问,CAdvisor直接通过influxdb.service.consul:8086即可连接到InfluxDB。
{"binds": ["{{volume_dir}}/influxdb/data:/var/lib/influxdb"],"environment": {"SERVICE_INFO": {"Name": "influxdb","Address": "{{register_ip}}","Port": 8086,},},"image": "influxdb","name": "influxdb-{{namespace}}","tag": "latest"}
为了存储CAdvisor的数据,需要预先创建好数据库并配置用户名密码以及相关权限。InfluxDB提供了一套influx的CLI,跟mysql client很相似。另外,InfluxDB的数据库操作语言InfluxQL跟SQL语法也基本一致。进入InfluxDB容器,运行下面命令创建数据库和用户密码并授权。
influxConnected to http://localhost:8086 version 1.3.5InfluxDB shell version: 1.3.5create database cadvisor ## 创建数据库cadvisorshow databasesname: databasesname----_internalcadvisorCREATE USER testuser WITH PASSWORD 'testpwd' ## 创建用户和设置密码GRANT ALL PRIVILEGES ON cadvisor TO testuser ## 授权数据库给指定用户CREATE RETENTION POLICY "cadvisor_retention" ON "cadvisor" DURATION 30d REPLICATION 1 DEFAULT ## 创建默认的数据保留策略,设置保存时间30天,副本为1
配置成功后,可以看到CAdvisor会通过InfluxDB的HTTP API自动创建好数据表,并将数据发送到InfluxDB存储起来。
:/# influxConnected to http://localhost:8086 version 1.3.1InfluxDB shell version: 1.3.1use cadvisordatabase cadvisorshow measurements # 显示数据表与SQL略有不同,用的是关键字measurementsname: measurementsname----cpu_usage_per_cpucpu_usage_systemcpu_usage_totalcpu_usage_userfs_limitfs_usageload_averagememory_usagememory_working_setrx_bytesrx_errorstx_bytestx_errorsselect * from rx_bytes order by time desc limit 2;name: rx_bytestime container_name game machine namespace type value-------------- ---- ------- --------- ---- -----1504685259707223192 consul-agent-dev cadvisor-10.x.x.x dev consul-agent 178587816331504685257769130660 manager-agent-dev cadvisor-10.x.x.x dev manager-agent 1359398
3.2 InfluxDB重要概念
influxdb有一些重要概念:database,timestamp,field key, field value, field set,tag key,tag value,tag set,measurement, retention policy ,series,point,下面简要说明一下:
database:数据库,如之前创建的数据库 cadvisor。InfluxDB不是CRUD数据库,更像是一个CR-ud数据库,它优先考虑的是增加和读取数据而不是更新删除数据的性能。
timestamp:时间戳,因为InfluxDB是时序数据库,它的数据里面都有一列名为time的列,存储记录生成时间。如 rx_bytes 中的 time 列,存储的就是时间戳。
fields: 包括field key,field value和field set几个概念。field key是字段名,在rx_bytes表中,字段名为 value。field value是字段值,如
17858781633,1359398等。而field set是字段集合,由field key和field value构成,如rx_bytes中的字段集合如下:value = 17858781633
value = 1359398在InfluxDB表中,字段必须存在,而且字段是没有索引的。所以,字段相当于传统数据库中没有索引的列。
tags:包括tag key, tag value, tag set几个概念。tag key是标签名,在rx_bytes表中,
container_name, game, machine, namespace,type都是标签。tag value就是标签的值了。tag set就是标签集合,由tag key和tag value构成。InfluxDB中标签是可选的,不过标签是有索引的。如果查询中经常用的字段,建议设置为标签而不是字段。标签相当于传统数据库中有索引的列。retention policy: 数据保留策略,cadvisor的保留策略为
cadvisor_retention,存储30天,副本为1。一个数据库可以有多个保留策略。measurement:类似传统数据看的表,是字段,标签以及time列的集合。
series:共享同一个retention policy,measurement以及tag set的数据集合。
point:同一个series中具有相同时间的字段集合,相当于SQL中的数据行。
3.3 InfluxDB的特色功能
InfluxDB作为时序数据库,相比传统数据库它有很多特色功能,比如独有的一些特色函数和连续查询功能。关于InfluxDB的更多详细内容可以参见官方文档。
特色函数:有一些聚合类函数如FILL()用于填充数据, INTEGRAL()计算字段所覆盖的曲面面积,SPREAD()计算表中最大与最小值的差值, STDDEV()计算字段标准差,MEAN()计算平均值, MEDIAN()计算中位数,SAMPLE()函数用于随机取样以及DERIVATIVE()计算数据变化比等。
连续查询:InfluxDB独有的连续查询功能可以定期的缩小取样,就原数据库的数据缩小取样后存储到指定的新的数据库或者新的数据表中,在历史数据统计整理时特别有用。
4 容器监控数据可视化-Grafana
通过CAdvisor搜集容器的监控数据,存储到InfluxDB中,接下来就剩数据可视化的问题了。毕竟,一个可视化的图表可以很方便快速的看到容器的一些问题。图表展示我选择的是Grafana。
Grafana是一个开源的数据监控分析可视化平台,支持多种数据源配置(支持的数据源包括InfluxDB,MySQL,Elasticsearch,OpenTSDB,Graphite等)和丰富的插件及模板功能,支持图表权限控制和报警。
Grafana同样也是以容器方式运行,容器启动配置如下,主要是挂载了grafana的数据和日志目录,设置了管理员的密码,并开放了8888端口作为grafana的访问端口:
{"binds": ["{{volume_dir}}/grafana/data:/var/lib/grafana","{{volume_dir}}/grafana/log:/var/log/grafana"],"environment": {"GF_SECURITY_ADMIN_PASSWORD": "testpwd"},"image": "grafana/grafana","name": "grafana-{{namespace}}","port_bindings": {"3000": 8888},"ports": [3000],"tag": "latest"}
启动之后就可以在http://IP:8888/页面去配置数据源了,一个示例如下:
Grafana数据源配置
配置完数据源,就可以添加Panel来实现数据可视化了。Grafana的图表功能十分强大,在配置数据查询语句的时候也是十分智能,会对数据源,数据表,数据字段自动提示,而且对InfluxDB的所有函数都有分类可以直接选取配置。需要注意的一点就是在配置字节类数据(比如网卡接收流量 rx_bytes 和 内存使用量 memory_usage)的时候单位要选 data(IEC)这个类别。
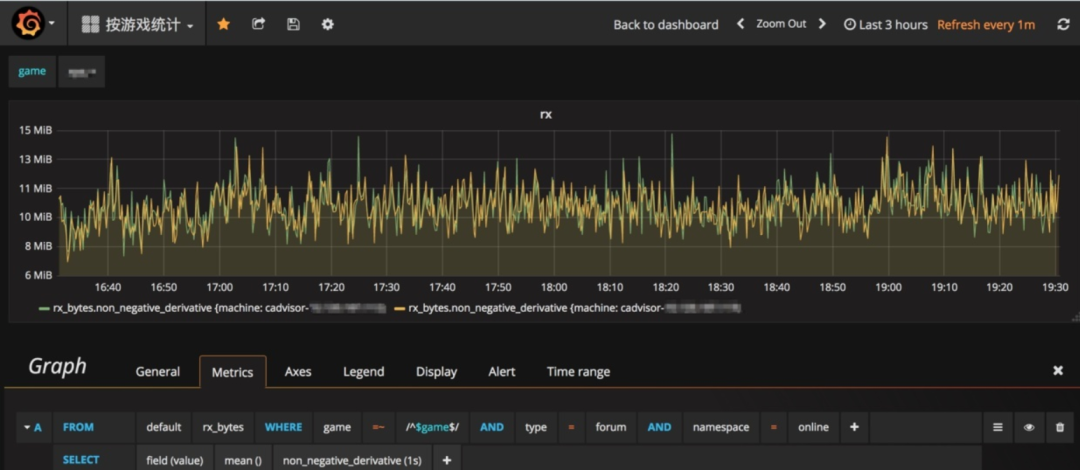
Grafana配置图表示例
5 总结
使用CAdvisor+InfluxDB+Grafana构建容器资源监控系统,是可行而且是较为简便的方式。这三个组件全部以容器的方式运行,也符合我们线上服务皆为容器的理念。目前已经全面上线该监控系统,运行正常,数据可视化效果良好。除了用于可视化监控之外,这些数据后续还会用于系统异常检测算法和容器智能调度算法中。
有收获,点个在看
