
基于Prometheus+Grafana打造企业级Flink监控系统
点击上方蓝色字体,选择“设为星标”
回复”资源“获取更多资源

Prometheus来龙去脉
灵活的数据模型:在Prometheus里,监控数据是由值、时间戳和标签表组成的,其中监控数据的源信息是完全记录在标签表里的;同时Prometheus支持在监控数据采集阶段对监控数据的标签表进行修改,这使其具备强大的扩展能力;
强大的查询能力:Prometheus提供有数据查询语言PromQL。从表现上来看,PromQL提供了大量的数据计算函数,大部分情况下用户都可以直接通过PromQL从Prometheus里查询到需要的聚合数据;
健全的生态: Prometheus能够直接对常见操作系统、中间件、数据库、硬件及编程语言进行监控;同时社区提供有Java/Golang/Ruby语言客户端SDK,用户能够快速实现自定义监控项及监控逻辑;
良好的性能:在性能方面来看,Prometheus提供了PromBench基准测试,从最新测试结果来看,在硬件资源满足的情况下,Prometheus单实例在每秒采集10w条监控数据的情况下,在数据处理和查询方面依然有着不错的性能表现;
更契合的架构:采用推模型的监控系统,客户端需要负责在服务端上进行注册及监控数据推送;而在Prometheus采用的拉模型架构里,具体的数据拉取行为是完全由服务端来决定的。服务端是可以基于某种服务发现机制来自动发现监控对象,多个服务端之间能够通过集群机制来实现数据分片。推模型想要实现相同的功能,通常需要客户端进行配合,这在微服务架构里是比较困难的;
成熟的社区:Prometheus是CNCF组织第二个毕业的开源项目,拥有活跃的社区;成立至今,社区已经发布了一百多个版本,项目在 GitHub 上获得的star数超过了3.8万。

Prometheus架构和组件
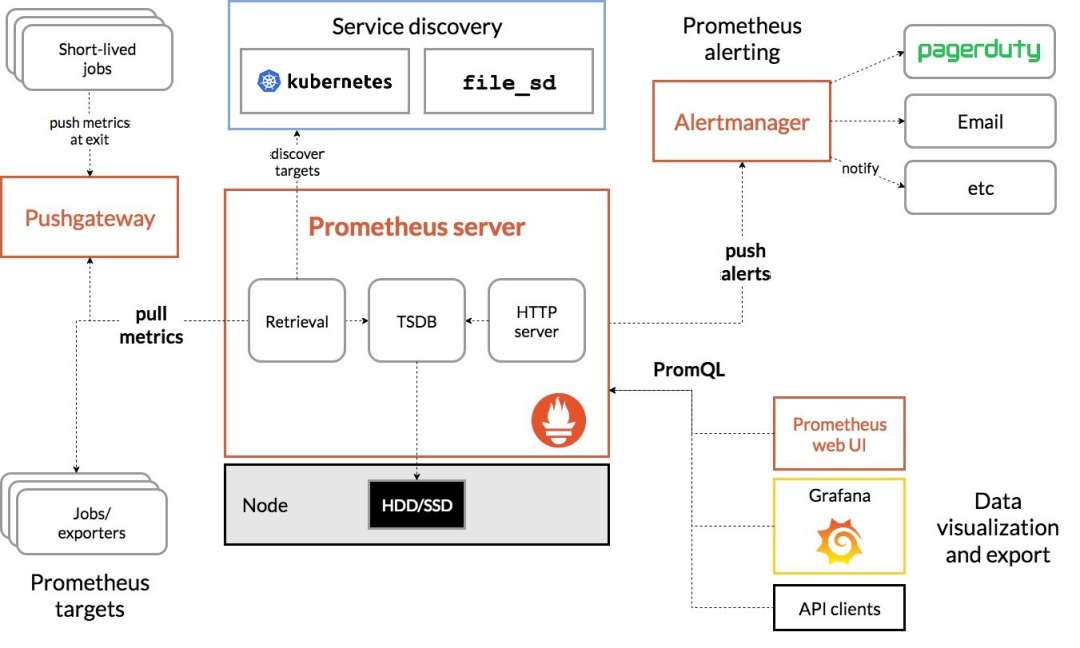
Prometheus Server: 用于收集和存储时间序列数据。
Client Library: 客户端库,为需要监控的服务生成相应的 metrics 并暴露给 Prometheus server。当 Prometheus server 来 pull 时,直接返回实时状态的 metrics。
Push Gateway: 主要用于短期的 jobs。由于这类 jobs 存在时间较短,可能在 Prometheus 来 pull 之前就消失了。为此,这次 jobs 可以直接向 Prometheus server 端推送它们的 metrics。这种方式主要用于服务层面的 metrics,对于机器层面的 metrices,需要使用 node exporter。
Exporters: 用于暴露已有的第三方服务的 metrics 给 Prometheus。
Alertmanager: 从 Prometheus server 端接收到 alerts 后,会进行去除重复数据,分组,并路由到对收的接受方式,发出报警。常见的接收方式有:电子邮件,pagerduty,OpsGenie, webhook 等。
一些其他的工具。
Prometheus通过配置文件中指定的服务发现方式来确定要拉取监控指标的目标(Target)。
接着从要拉取的目标(应用容器和Pushgateway),发起HTTP请求到特定的端点(Metric Path),将指标持久化至本身的TSDB中,TSDB最终会把内存中的时间序列压缩落到硬盘。
Prometheus会定期通过PromQL计算设置好的告警规则,决定是否生成告警到Alertmanager,后者接收到告警后会负责把通知发送到邮件或企业内部群聊中。
Prometheus的数据模型和核心概念
指标名称和标签
样本
指标(metric):指标名称和描述当前样本特征的 labelsets;
时间戳(timestamp):一个精确到毫秒的时间戳;
样本值(value):一个 folat64 的浮点型数据表示当前样本的值。
指标类型
Counter:代表一种样本数据单调递增的指标,即只增不减,通常用来统计如服务的请求数,错误数等。
Gauge:代表一种样本数据可以任意变化的指标,即可增可减,通常用来统计如服务的CPU使用值,内存占用值等。
Histogram 和 Summary:用于表示一段时间内的数据采样和点分位图统计结果,通常用来统计请求耗时或响应大小等。
Prometheus的安装
tar xvfz prometheus-*.tar.gz
cd prometheus-*
$ cd prometheus/
// 查看版本
$ ./prometheus --version
// 运行server
$ ./prometheus --config.file=prometheus.yml
rpm -ivh grafana-6.5.2-1.x86_64.rpm
service grafana-server start
$ tar xvfz node_exporter-xxx.tar.gz
// 进入解压出的目录
$ cd node_exporter-xxx
// 运行监控采集服务
$ ./node_exporter
Prometheus+Grafana+nodeManager+pushgateway打造企业级Flink平台监控系统
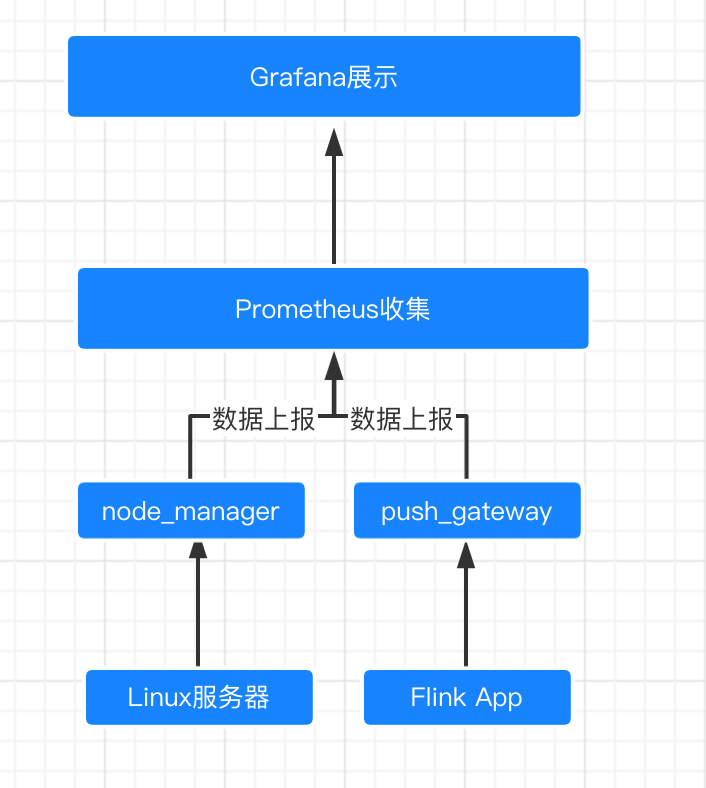
Flink App :这是我们需要监控的数据来源
Pushgateway+nodeManger : 都是Prometheus 生态中的组件,pushGateway服务收集Flink的指标,nodeMnager负责监控运行机器的状态
Prometheus : 我们监控系统的主角
Grafana:可视化展示
metrics.reporter.promgateway.class: org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter
metrics.reporter.promgateway.host: node1
metrics.reporter.promgateway.port: 9091
metrics.reporter.promgateway.jobName: flinkjobs
metrics.reporter.promgateway.randomJobNameSuffix: false
metrics.reporter.promgateway.deleteOnShutdown: true
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
labels:
instance: 'prometheus'
- job_name: 'linux'
static_configs:
- targets: ['localhost:9100']
labels:
instance: 'localhost'
- job_name: 'pushgateway'
static_configs:
- targets: ['localhost:9091']
labels:
instance: 'pushgateway'
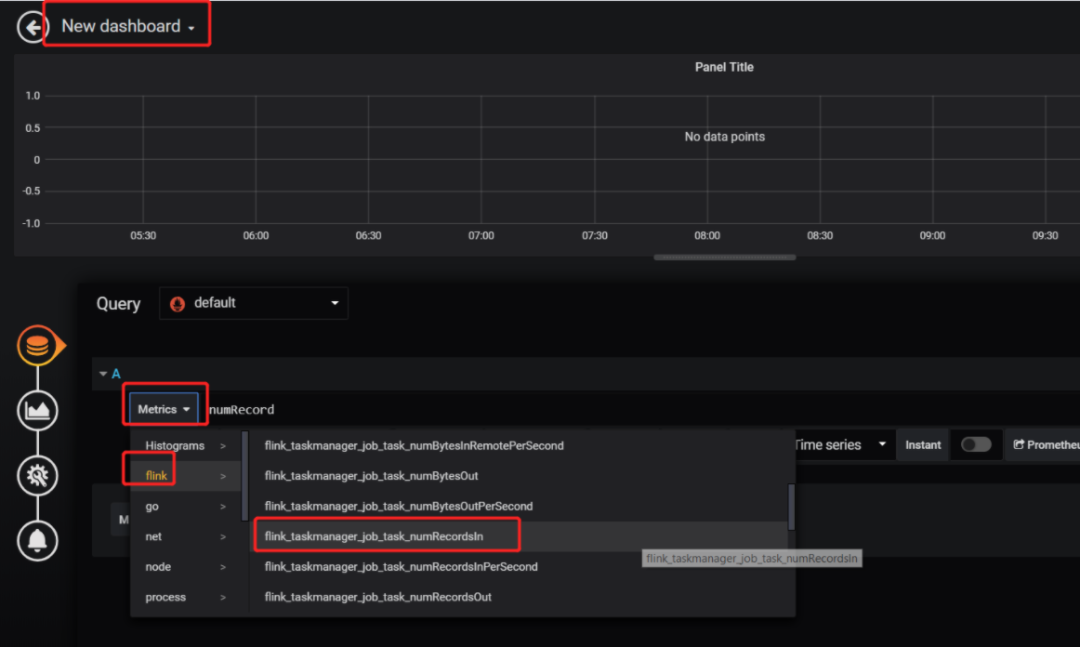
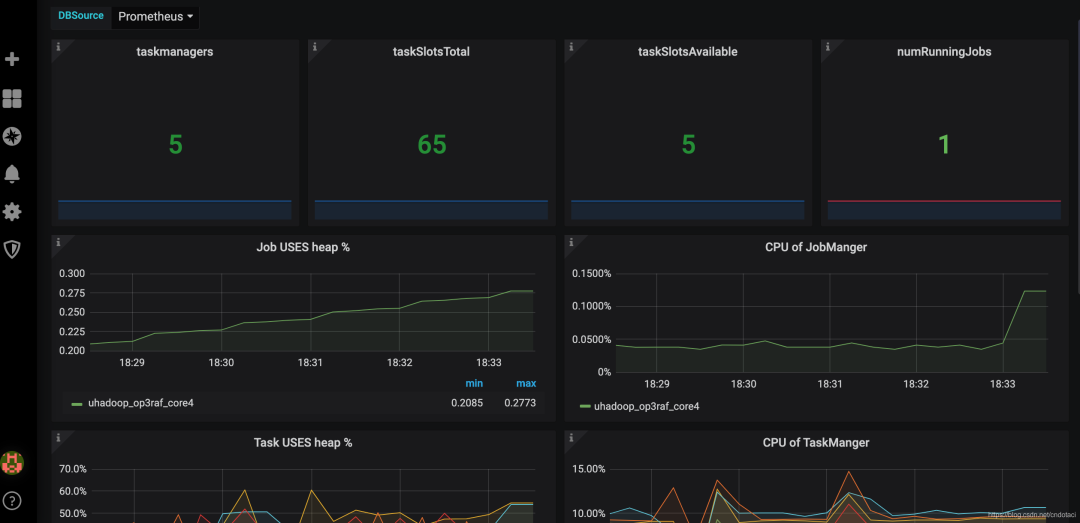
业界典型应用
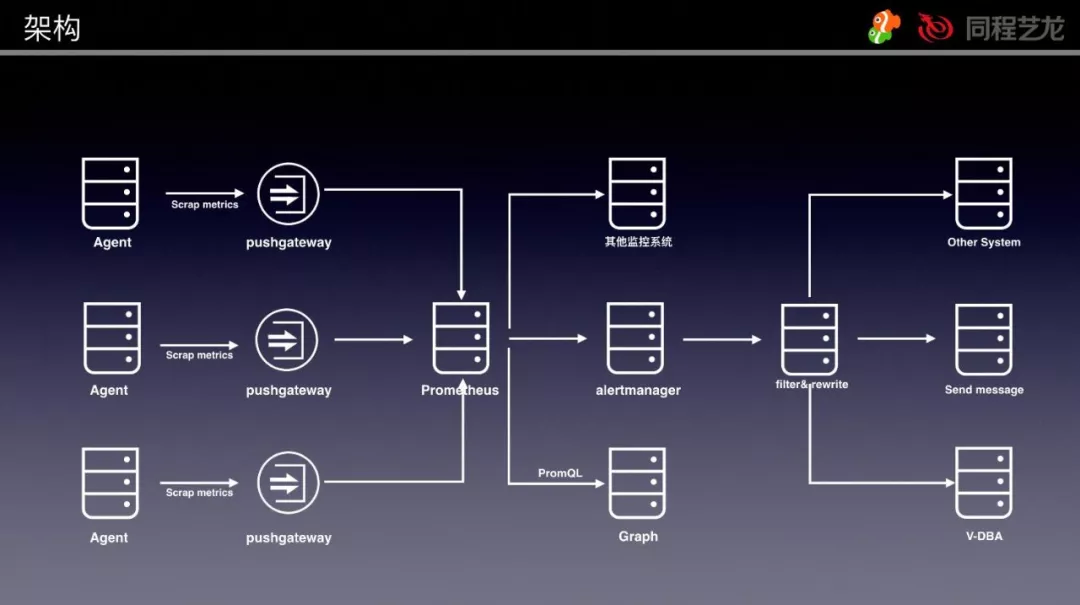

利用InfluxDB+Grafana搭建Flink on YARN作业监控大屏
干掉ELK | 使用Prometheus+Grafana搭建监控平台