
盘点一个网络爬虫中常见的一个错误
回复“书籍”即可获赠Python从入门到进阶共10本电子书
大家好,我是皮皮。
一、前言
前几天在Python白银交流群有个叫【雨就是雨】的粉丝问了一个Python网络爬虫的问题,这里拿出来给大家分享下,一起学习下。
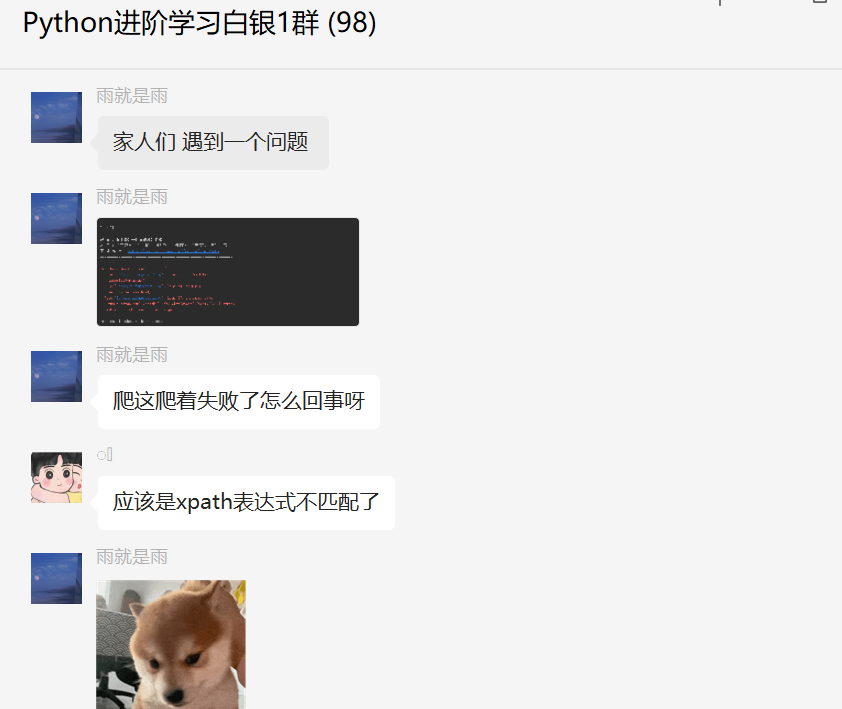
问题如下:
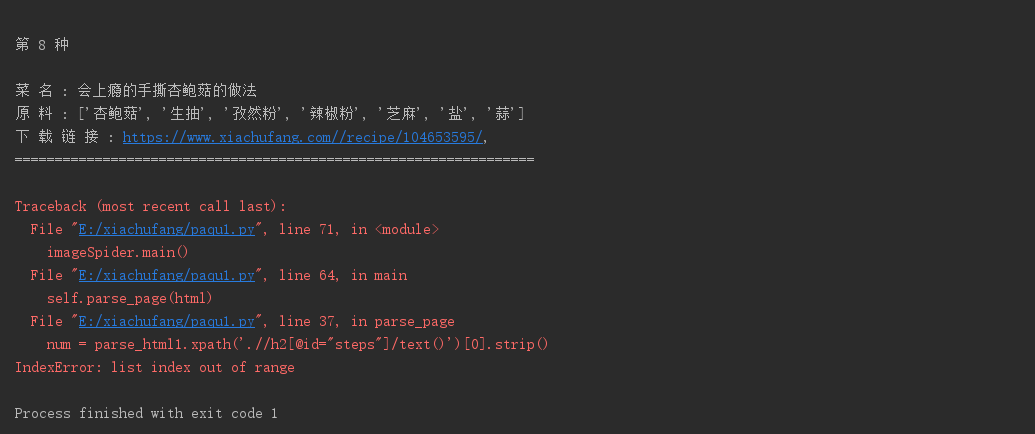
二、解决过程
这里很容易的一个怀疑点是原网页上的网页结构变化了,使用xpath选择器进行提取的话,会出现不匹配的情况,列表索引不在范围内,引起报错。
【Python进阶者】给出了一个思路,确实可以使用try异常处理来避开,不过始终拿不到数据,确实有点让人头大。
后来下午的时候【Python进阶者】跑他代码的时候发现了原因,如下图所示。
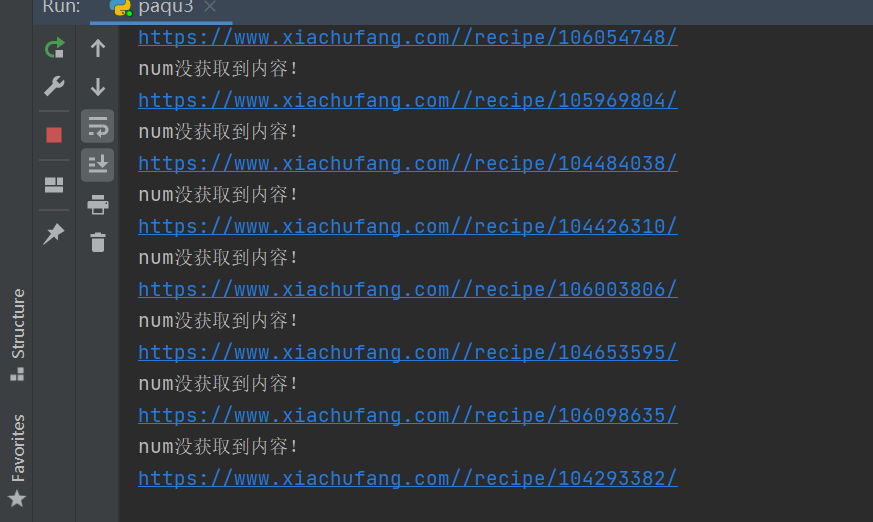 他的
他的url这里,构造有问题,多了一个/,导致网页访问出错。
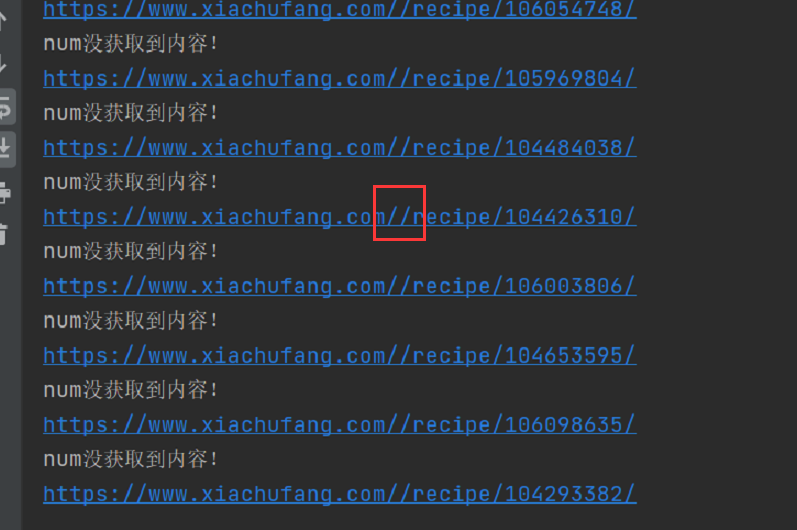
修改下,就可以跑了,另外,网页详情页里边也有多次请求,记得稍微sleep下,就可以了。下面是详细代码,感兴趣的小伙伴们,可以拿去跑下。
import requests
from lxml import etree
from fake_useragent import UserAgent
import time
class kitchen(object):
u = 0
def __init__(self):
self.url = "https://www.xiachufang.com/category/40076/"
ua = UserAgent(verify_ssl=False)
for i in range(1, 50):
self.headers = {
'User-Agent': ua.random,
}
'''发送请求 获取响应'''
def get_page(self, url):
res = requests.get(url=url, headers=self.headers)
html = res.content.decode("utf-8")
time.sleep(2)
return html
def parse_page(self, html):
parse_html = etree.HTML(html)
image_src_list = parse_html.xpath('//li/div/a/@href')
for i in image_src_list:
try:
url = "https://www.xiachufang.com" + i
# print(url)
html1 = self.get_page(url) # 第二个发生请求
parse_html1 = etree.HTML(html1)
# print(parse_html1)
num = parse_html1.xpath('.//h2[@id="steps"]/text()')[0].strip()
name = parse_html1.xpath('.//li[@class="container"]/p/text()')
ingredients = parse_html1.xpath('.//td//a/text()')
self.u += 1
# print(self.u)
# print(str(self.u)+"."+house_dict["名 称 :"]+":")
# da=tuple(house_dict["材 料:"])
food_info = '''
第 %s 种
菜 名 : %s
原 料 : %s
下 载 链 接 : %s,
=================================================================
''' % (str(self.u), num, ingredients, url)
# print(food_info)
f = open('下厨房菜谱.txt', 'a', encoding='utf-8')
f.write(str(food_info))
print(str(food_info))
f.close()
except:
print('xpath没获取到内容!')
def main(self):
startPage = int(input("起始页:"))
endPage = int(input("终止页:"))
for page in range(startPage, endPage + 1):
url = self.url.format(page)
html = self.get_page(url)
self.parse_page(html)
time.sleep(2.4)
print("====================================第 %s 页 爬 取 成 功====================================" % page)
if __name__ == '__main__':
imageSpider = kitchen()
imageSpider.main()
跑出来的结果会保存到一个txt文件里边,如下图所示:
 碰到这种
碰到这种url拼接问题,推荐使用urljoin的方式,示例代码如下:
from urllib.parse import urljoin
source_url = 'https://www.baidu.com/'
child_url1 = '/robots.txt'
child_url2 = 'robots.txt'
final_url1 = urljoin(source_url, child_url1)
final_url2 = urljoin(source_url, child_url2)
print(final_url1)
print(final_url2)
运行结果如下图所示: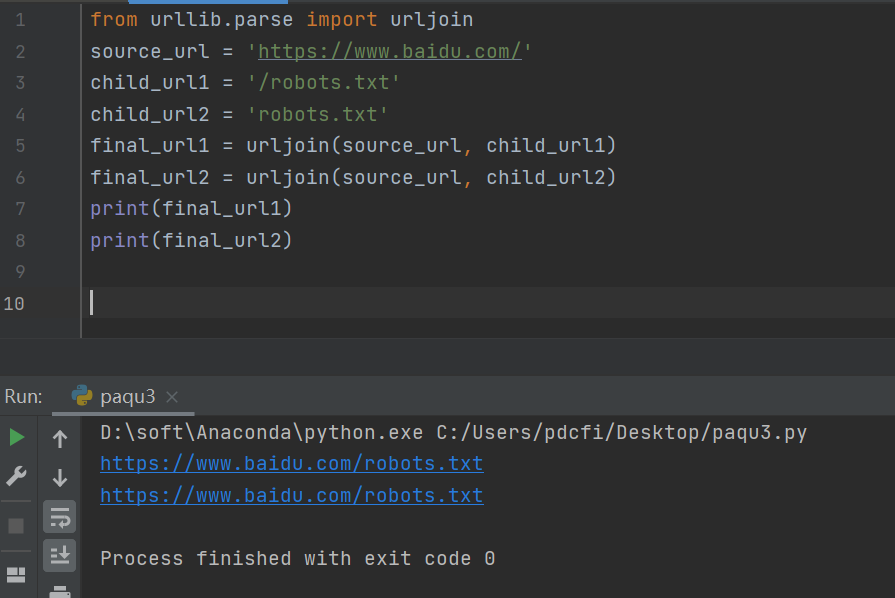
urljoin的作用就是连接两个参数的url,将第二个参数中缺的部分用第一个参数的补齐,如果第二个有完整的路径,则以第二个为主。
三、总结
大家好,我是皮皮。这篇文章主要盘点一个网络爬虫中常见的一个错误问题,文中针对该问题给出了具体的解析和代码演示,帮助粉丝顺利解决了问题。最后给大家安利了一个url拼接的方法,在网络爬虫中还是非常常用的。
最后感谢粉丝【雨就是雨】提问,感谢【Python进阶者】给出的具体解析和代码演示,感谢粉丝【꯭】、【艾希·觉罗】、【月神】、【dcpeng】、【瑜亮老师】等人参与学习交流。
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何Python问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行