
盘点一个使用playwright实现网络爬虫的实战案例
回复“资源”即可获赠Python学习资料
大家好,我是皮皮。
一、前言
前几天在Python白银交流群【空翼】问了一个Pyhton网络爬虫的问题,这里拿出来给大家分享下。
二、实现过程
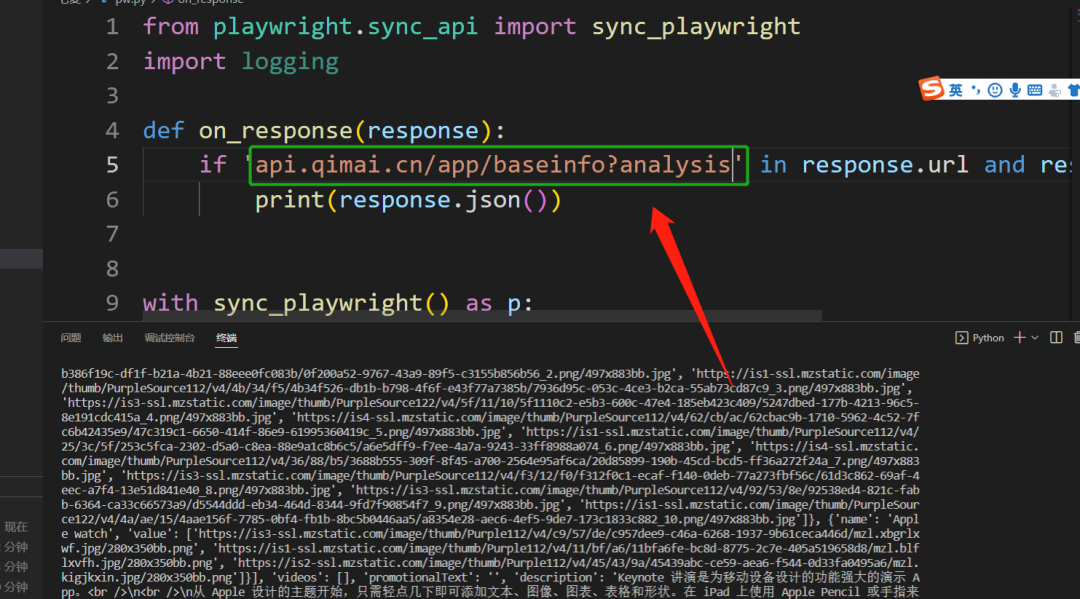
【喜靓仔】提出用playwright实现,后来他自己给出了代码,如下图所示:

代码如下:
from playwright.sync_api import sync_playwright
def on_response(response):
if '/app/baseinfo' in response.url and response.status == 200:
print(response.json())
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.on('response', on_response)
page.goto('https://www.qimai.cn/app/baseinfo/appid/361285480/country/cn')
page.wait_for_load_state('networkidle')
browser.close()
代码运行之后,有个问题,会报错。后来发现是地址片段写的有问题。
顺利地解决了问题。

playwright功能还是很强大的,可以自己生成代码。
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Pyhton网络爬虫的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【空翼】提问,感谢【喜靓仔】给出的思路和代码解析,感谢【Python狗】等人参与学习交流。
大家在学习过程中如果有遇到问题,欢迎随时联系我解决(我的微信:pdcfighting),应粉丝要求,我创建了一些高质量的Python付费学习交流群和付费接单群,欢迎大家加入我的Python学习交流群和接单群!

小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~
评论