
盘点Python网络爬虫入门常见的一个问题
回复“资源”即可获赠Python学习资料
大家好,我是皮皮。
一、前言
前几天在Python铂金交流群【余丰恺】问了一个Python网络爬虫的问题,如下图所示。
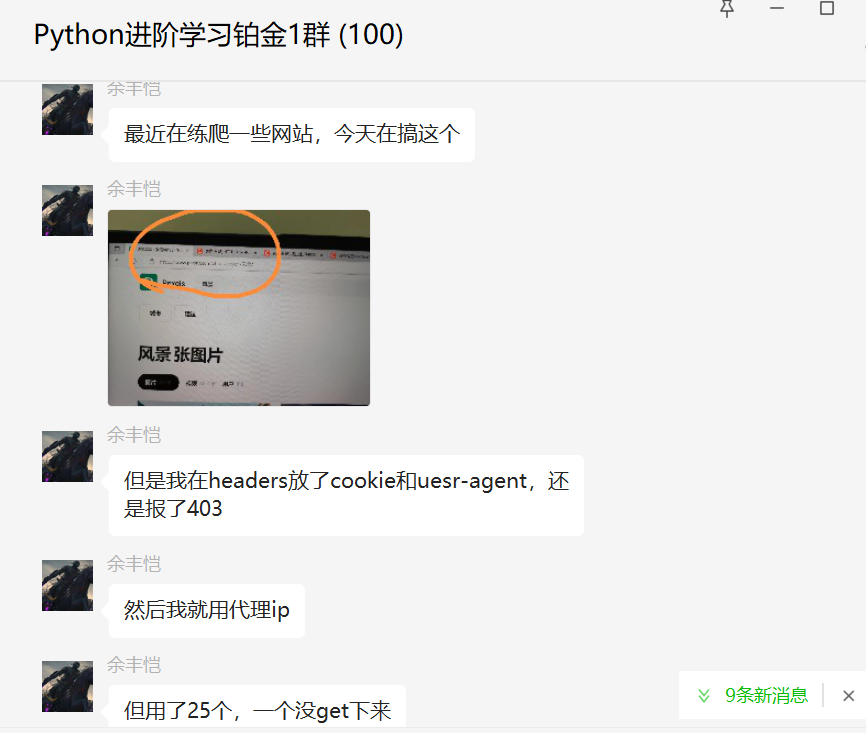
下图是报错的界面。
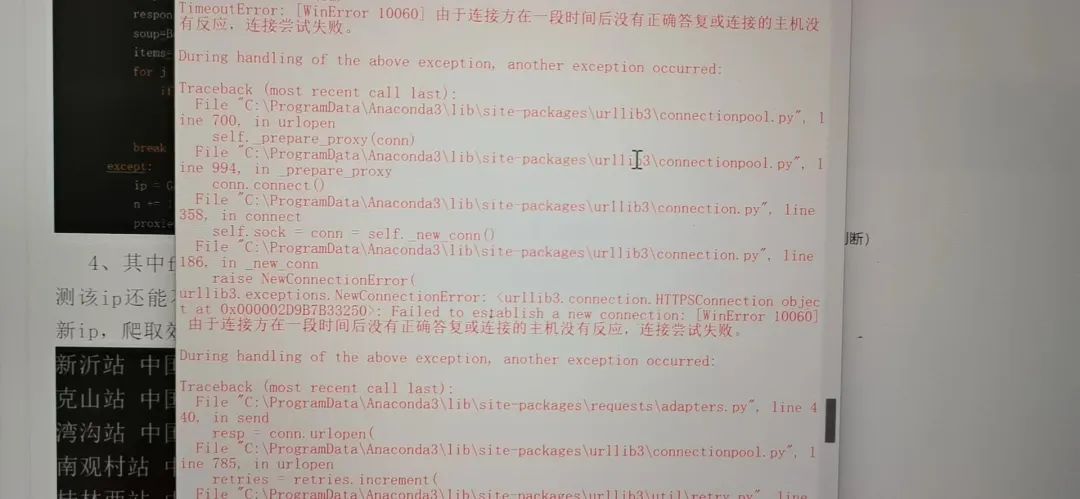
吐槽下,在Python自带的idle下面跑程序代码,看着还是挺难受的。
二、实现过程
这里大家也都比较有经验,纷纷献计,讨论非常激烈。

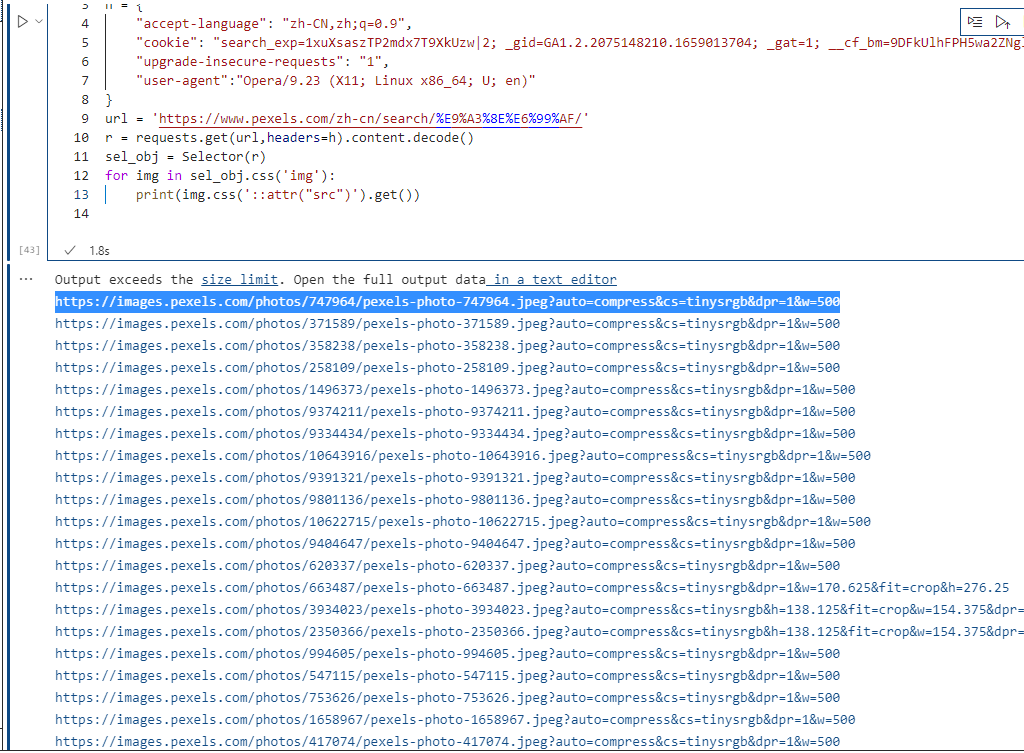
后来【const GF = null】给出了一个思路,怀疑是请求头的问题,增加cookie之后就可以请求到,如下所示:
{
"accept-language": "zh-CN,zh;q=0.9",
"cookie": "",
"upgrade-insecure-requests": "1",
"user-agent":"Opera/9.23 (X11; Linux x86_64; U; en)"
}
运行结果也都可以满足粉丝要求。
 那问题来了,一般怎么选择
那问题来了,一般怎么选择headers里面的参数呢?答案如下图所示,如果拿不准就全部带上,屡试不爽。
如果不确定是哪些必要参数,删的时候是从哪个开始删呀?
 这个地方的话,首推
这个地方的话,首推Postman,讲请求头全部复制然后一个一个取消试试,访问不了了,再勾上。
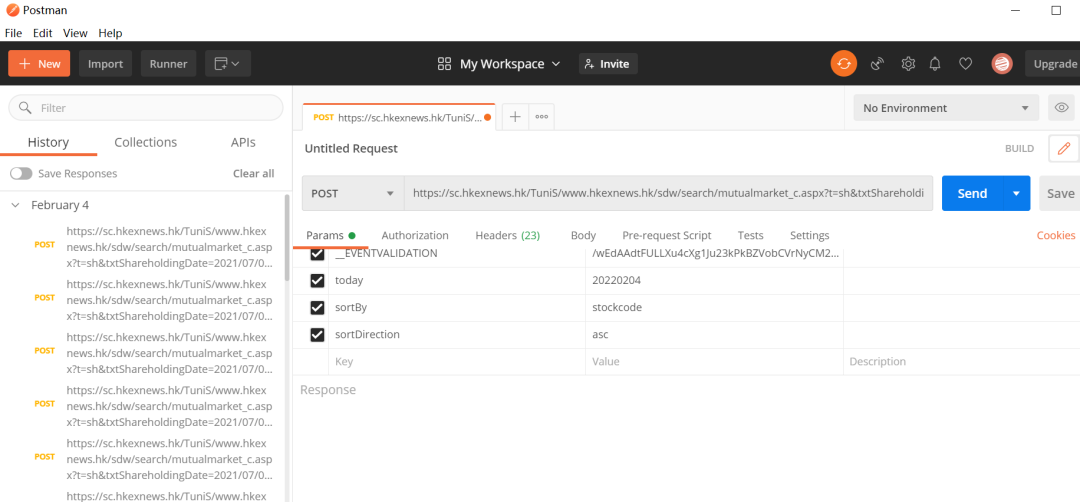
完美地解决粉丝的问题!
如果加上cookie之后,报错403状态码的话,试试看换个ua,如下图所示。

三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Python网络爬虫的基础问题,文中针对该问题给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【余丰恺】提问,感谢【Kenju】、【我怎么又饿了】、【const GF = null】给出的思路和代码解析,感谢【dcpeng】、【冯诚】、【此类生物】等人参与学习交流。
大家在学习过程中如果有遇到问题,欢迎随时联系我解决(我的微信:pdcfighting),应粉丝要求,我创建了一些高质量的Python付费学习交流群,欢迎大家加入我的Python学习交流群!

有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行