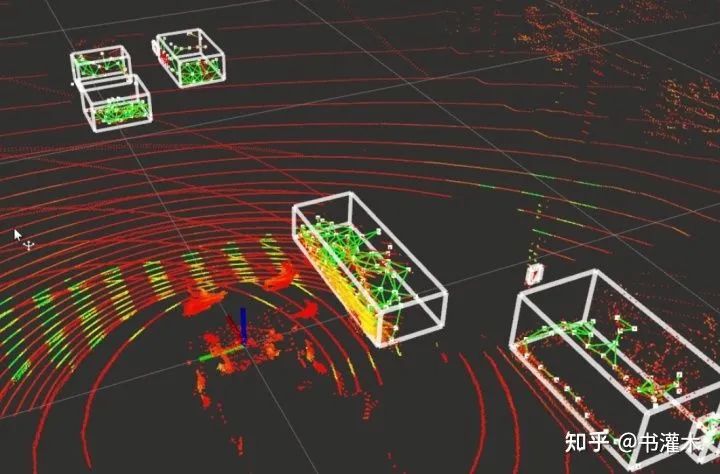
现在是晚上22点46分,大小美女都睡觉了,我突然想写一篇这五年无人驾驶工作的总结。没有打草稿,想到啥说啥。如有不对的地方,请大家指正。我从事无人驾驶是从2016年初开始的,机缘巧合之下被伯乐选中,原因是我的专业是控制理论与控制工程,可是我本人对控制一点兴趣没有,就喜欢编程。当时自学了java,面试很容易就过了,也是因为单位当时的现状是矮子里面找高个,挑无可挑了,算是赶鸭子上架吧。现在非常感谢当时的那位领导,要不是他,我学不到这么多受用终身的知识。其实从2014年开始,国外的无人驾驶已经进入了高速发展,当时国内都在炒房、炒股、炒比特币,所以起步就已经落后了。当时就没听过深度学习、机器学习,只在学校里学习过神经网络、免疫算法等,感觉就是参数优化和大范围随机搜索,没学到精髓。我非常荣幸的见证了我国某代军车的研发和制造过程,从初样车到正样车,再到定型车,最后量产。团队的无人驾驶工作也在这款军车上开展,目的是为了在未来某天,能够接到军方的项目,提升车辆的二次开发价值。2016年国内的无人驾驶开始预热,各大主机厂、科技公司都开始入场,高校在理论方面更是走到了前面,毕竟高校的知识储备太丰富。开始的目标很简单,实现轨迹跟踪就行,尽量提高车辆速度和控制稳定性。在当时只有三个人的情况下,从一脸懵逼到实现预期目标。写过前端控制界面,也干过轨迹规划,都是用c#写的,当时根本不懂去用linux,更别提ros,c++了。当时是真的莽,真敢坐车上测试,现在有些后怕。控制用的PID,轨迹跟踪用的预瞄,简单而且效果好,算是入行了吧。2017年,在前一年的基础上实现了车道保持,车道预警,车道线识别,变道等功能。传感器使用了一个mobileye和惯性导航,最高车速55,坐车上是真的害怕,手就放在急停按钮上,一旦有险情直接急刹。通过实践,发现了用c#的不足,首先编写前端界面很麻烦,不光要实现控制,还需要将车辆轨迹和mobileye检测的障碍物呈现出来。当时也不懂什么多线程、多进程,就是在主线程里整,这会影响到控制的实时性,好在当时没有出问题。其次,扩展性差,当加入其他功能单元或者传感器后,需要改动程序,很麻烦。最后是调试不方便。这也是我学艺不精,其实c#功能很强大,只是用错了地方。2018年,我们终于换了系统,在ubuntu下使用ros,编程语言也切换成了c++。为了学c++,翻了书,也抄了一个github上的开源代码,从头抄到尾,这样就熟悉了c++的语法和编写方式。抄代码是个笨办法,我是比较笨的那种人,如果只看书、看教程,我看了就忘,跟没看一样。原来上课的时候老师就说,编程编程,你得去编啊,动手才是王道。由于人员的扩充,我更换了研究方向,终于不用在编写界面了,跳进了坑了我3年的激光雷达领域,这个坑是真的大,一直到现在我还在坑底,努力的向上爬。当时接激光雷达是在年底了,目标是用激光雷达识别目标,主要是车辆、行人以及在一定范围内的所有静态障碍物,并且跟踪障碍物运动状态。先使用4线激光雷达,雷达本身能直接输出检测的障碍物。后来4线的效果只在平面内,不能实现3d成像,所以改用velodyne16线为主,4线补盲的方式。第一次看到密密麻麻的点云数据,真的是一脸懵逼,这到底是啥啊,我就靠这些点能识别出障碍物吗?搞笑呢吧。为了实现目标,去学习了pcl库。通过阅读pcl库的某些源代码,了解了点云的处理方式和一些基础算法。最后使用了欧式聚类,实现了在城市道路上的目标检测。这种目标检测有很多的局限性。1. 得先识别地面,然后去掉地面。2. 需要去掉空中的点,比如树冠等,因为我只关心车辆前方道路上和道路两侧的低空障碍物。3. 欧式聚类设置一个距离阈值,只有点与点间的距离小于阈值时才算做同一个障碍物。如果两个障碍物距离近,将会有很大概率识别成同一个物体,也就会将路边停的一排家用车识别成一个大平板。识别距离是40米,纵向误差小于0.5米,横向误差小于0.3米。算是达到了预期效果。实验过程中发现了一些问题,首先,16线激光雷达更适合补盲,线太少,如果作为主要传感器,探测距离太近,在40米外的障碍物可能只是一条水平直线。其次,在障碍物密集的场景,运算速度下降。最后,由于没有识别道路边界,无法识别障碍物是否在前方道路内。时间来到了2019年,目标是:1. 提高激光雷达目标识别精度、距离、运算速度;2. 识别道路边界,拟合边界曲线。首先是目标识别,之前看了一篇关于凸平面分割障碍物的文章,觉得特别有道理,重要的是可以分割的很精确。沿着这个方向查了相关资料,发现了一篇论文《Object Partitioning using Local Convexity》,阅读沦为,并搞懂了算法原理。文章中给出了在pcl库中的实现,名字叫LCCP,可惜使用在图像上。图像和点云有很强的相似性,都是由点组成,只不过一个是像素,一个是xyz。像素点在经过相机内参和外参变换后,就会映射到三维空间。算法上也有很多相通点,我所知道的特征提取还有金字塔算法都可以通用,只需要将点云在三维空间中结构化,比方说八叉树等。(说实话,我知道的图像处理知识很有限,如果错了,请给我留言说一声,感谢。)经过修改后,将LCCP用在了点云上。激光雷达LCCP算法效果图这就是处理的效果图,能够描述车辆的外形轮廓。但就是计算速度慢,得170ms+,无法实时处理点云数据,不适合无人驾驶,但是如果用在离线处理,比如slam上去除动态目标物,兴许效果更好,我没有尝试。运算速度慢的原因是体素过滤后计算了每个点的法向量,使用周边一定距离内的所有点进行主成分析,体素过小和周边点太多导致计算缓慢,毕竟需要计算每个点的法向量,然后再区域生长聚合目标物。我尝试了扩大体素和使用最近的若干点,虽然提高了计算速度,但是轮廓精度降低很多。在这种两难的场景下,我更倾向于保证精度,所以将代码保留,如果以后做slam可以使用。LCCP的编写和调试花废了太长时间,效果又没有达到预期。所以不得不立刻改变方向,加快进度,如果年底目标达不到,扣钱是肯定的。在金钱的诱惑下,我给屁股上扎了两针鸡血~~~。更改的方向锁定在速度快,越快越好,精度不能太低,识别距离50米以上。最后发现了这篇神文--Fast Multi-Pass 3D Point Segmentation Based on a Structured Mesh Graph for Ground Vehicles。算法实现后是真的快,单32线雷达只需要17ms,一个32线加两个16线融合后只需要22ms,我惊了。看到结果图的瞬间,我感觉已经达到了人生的巅峰,并且已经保证不用扣钱了,获取还能奖励点(做梦)。算法的核心思想就是利用激光雷达的数据分层结构,论文中有一步拟合多项式,我去掉了,原因是会拖慢运算速度,而且效果也没有多大提升。年底时,用这套目标识别算法,再加上去年的目标跟踪,成功的在环境较为复杂的路面实现了无人驾驶。环境是一半越野路,一半公路,甚至了S形弯道等,实验结果达到了既定目标。不足之处:1. 3个雷达数据融合存在问题,我选择目标级别融合,也就是先识别目标物,然后目标物融合跟踪。只有障碍物被跟踪若干周期后,等它稳定并且长期存在后,再输出给控制层,这就导致滞后。滞后的这几个周期会对控制有很大影响,车速慢就罢了,一旦车速快就会发生碰撞或剐蹭。2. 识别距离短,刚好达到50米的最低要求,分析原因是32线雷达斜向下安装,前向线不足导致,但是32线如果水平装,就会产生很大盲区,雷达安装离地大概有2.5米到3米。道路边界识别没啥好说的,就是先识别马路牙子或者隔离带或者护栏,然后线性拟合。我们有同事加入了kalman滤波,道路边界曲线稳定性有了极大提高。2020年,人员再次扩充,我交出了目标识别的工作,转向SLAM。这个领域是我接触激光雷达开始就强烈希望去做的,但是得根据团队的规划走,所以一直拖到了现在。当知道我能做SLAM后,你们想象不到我的快乐!!!激光slam没有摄像头slam那样热门,但是也有很多非常出名的算法。我首先求助的是google的开源项目cartogrpher。这个算法是真的牛逼,就靠概率累加和有限范围搜索,实现了实时slam。阅读源码后不得不感叹google的神仙是真的牛逼。cartographer的2D和3D的实现差别是点云的空间结构上,2D是平面栅格,3D是八叉树结构,其他算法都一样。只是cartographer中使用按一定区间旋转和平移点云,进行轮寻式的匹配,以此作为回环检测,实际使用时,会出现匹配错误的情况,再加入IMU数据后会好转,但是如果缩小每步的旋转和平移,会增加计算时间。后来,团队觉得cartographer是扫地机器人的核心算法,用在无人车上不靠谱,无人车要3D,再解释无果的情况下,也是为了保住我能做SLAM,更换算法,转到了Lego-SLAM。Lego-SLAM是使用了提取点云特征,匹配相邻两帧间特征点计算相对姿态变换,回环检测使用和当前帧最近的若干帧进行匹配,检测是否存在循环,在使用图优化进行全局优化。可以使用IMU数据,也可以不使用,当然使用了精度更高。还有一个种叫SC-lego-loam,在回环检测中使用了scanContext,这种算法太巧妙了,适合在雷达高度固定的场景。团队又说了,loam很好,但是IMU却没有起到关键作用,应该使用IMU数据和GPS数据对slam进行矫正,我觉得也对,毕竟传感器越多越精确,诚挚的接受团队建议,再次修改方向。最后使用了hdl_graph_slam,传感器包含雷达、IMU、GPS,匹配算法使用了变种NDT集合图优化,回环检测依然是在距离最近的若干关键帧中寻找。该变种NDT修改了临近点的数量,从26变到了7,并且在求每个点的梯度和hessian时使用了openmp的多线程方法,极大的加速了运算速度。最近,在刷知乎的时候看了一篇slam发展趋势的文章,里面提到了语义建图,而且国外的学术会议有关语义建图的论文越来越多。我个人认为无人驾驶已经从算法驱动向着数据驱动发展了,引入深度学习才是王道。所以最近在研究Suma,opengl看不懂,glow看不懂,要搞懂Suma和Suma++还得研究下。以上提出得几种SLAM算法,我写了详细的源码解析,但是没有整理,待我整理完,在逐一发出。最后,说一些我的感悟:1. 无人驾驶。无人驾驶现在冷却了下来,从科技公司到政府都希望尽快落地。今年百度的无人驾驶出租车已经在海淀和长沙等地试运行了。这其中最明显的认知变化就是无人驾驶目前只能在限定场景下实现,特斯拉的几次事故就已经说明了这一点。在类似沙盒的场景下,要处理的环境信息太多,随时都可能发生意想不到的情况,深度学习对这种可能出现的意外缺乏数据支撑,没有办法作出正确决定。连特斯拉都不敢再吹牛逼,但当我看到国内主机厂吹自己实现了L4、L5级别的无人驾驶,我真的很无语,国内的无人驾驶一直很浮躁,沉下心,少吹牛逼,默默追赶才是出路,花拳绣腿终归比不过冬练三九夏练三伏。2. 关于代码造轮子。网上很多人说编程的大忌就是造轮子。但是算法你不造轮子不行啊,只会用库,不懂原理,你连修改都没法改,没有办法根据目标的变化修改代码,很被动。所以,算法造轮子不能偷懒,该造还得造,还得好好造,多编多练才能取得进步。3. 我觉得V2X是未来无人驾驶的强大甚至是核心助力,物联网,啧啧,想着就牛逼。4. 跟着国外走吧,国内的主机厂都在搞笑,他们很少真正关心技术,关心的只是项目完成,年底拿钱。请保持一颗追赶超越的心。本文仅做学术分享,如有侵权,请联系删文。

 下载APP
下载APP