
爬虫福音:GitHub 超火爆开源 IP 代理池!

经常有粉丝在后台留言,问:大佬,运行你的爬虫程序怎么报错了?
我让他把报错信息发过来,看过之后一声叹息。
大多数粉丝是直接拿着代码就开始运行,然后就是等待结果,完全不去仔细阅读和理解源码,遇到报错就直接过来询问。
多数爬虫源码运行的报错都是由于访问目标网站过于频繁,从而导致目标网站返回错误或者没有数据返回。
目前大多数网站都是有反爬措施的,如果 IP 在一定时间内 请求次数超过了一定的阈值就会触发反爬措施,拒绝访问,也就是我们经常听到的“封IP”。
那么怎么解决这个问题呢?
一种解决办法就是降低访问频率,访问一次就等待一定时长,然后再次访问。这种方法对于反爬措施不严格的网站是有效的。
如果遇到反爬措施严格的网站,访问次数多了还是会被封杀。而且有时候你需要爬取数据,这种解决办法会使获取数据的周期特别长。
第二种解决办法就是使用代理 IP。我不断地切换 IP 访问,让目标网站认为是不同的用户在访问,从而绕过反爬措施。这也是最常见的方式。
接着,我们又面临一个问题:哪来这么多独立 IP 地址呢?
最省事的方式当然是花钱买服务,这种花钱买到的 IP 一般都是比较稳定可靠的。
今天我们来聊一下不花钱免费获取代理 IP 的方式。
ProxyPool 简介
ProxyPool 是一个爬虫的代理 IP 池,主要功能为定时采集网上发布的免费代理验证入库,定时验证入库的代理保证代理的可用性,提供API和CLI两种使用方式。
同时你也可以扩展代理源以增加代理池IP的质量和数量。
获取项目
我们可以通过两种方式获取 ProxyPool 项目。
第一种是通过命令行下载:
git clone git@github.com:jhao104/proxy_pool.git
第二种是下载对应的 zip 压缩包:
安装依赖
我们获取到项目之后,进入到项目的根目录,运行下面的代码来安装项目所需的依赖包:
pip install -r requirements.txt
修改配置文件
要在本地运行项目,我们需要针对本地环境修改一些配置。打开项目中的 setting.py 这个文件,根据自己本地的环境和要求修改配置。
# setting.py 为项目配置文件
# 配置API服务
HOST = "0.0.0.0" # IP
PORT = 5000 # 监听端口
# 配置数据库
DB_CONN = 'redis://:pwd@127.0.0.1:8888/0'
# 配置 ProxyFetcher
PROXY_FETCHER = [
"freeProxy01", # 这里是启用的代理抓取方法名,所有fetch方法位于fetcher/proxyFetcher.py
"freeProxy02",
# ....
]
主要修改的几项配置是监听端口(PORT)、 Redis 数据库的配置(DB_CONN)和启用的代理方法名(PROXY_FETCHER)。
启动项目
修改完配置之后,我们就可以愉快地使用了。
这个项目总体分为两个部分:爬取代理 IP 和 取用代理 IP。
如果你要启用爬取代理 IP 的服务,直接运行下面命令:
python proxyPool.py schedule
启动之后,你就可以看到如下的控制台信息了:
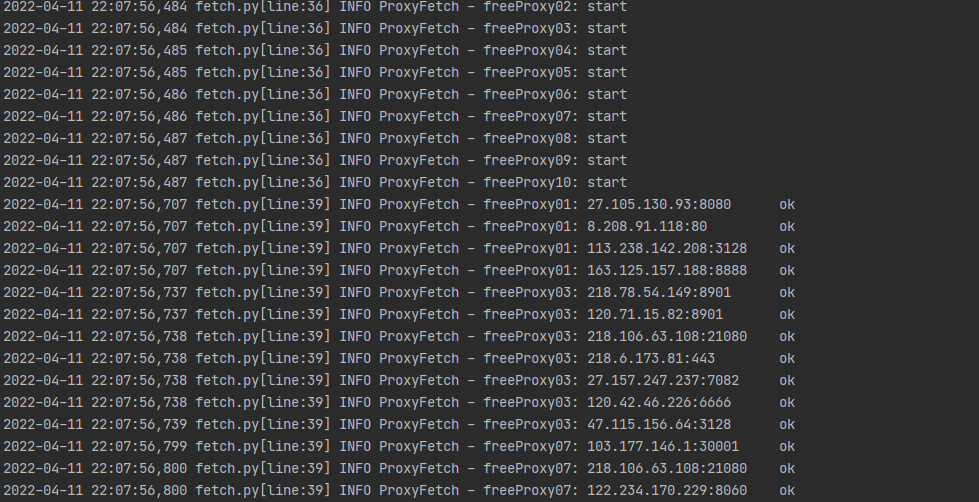
程序每隔一段时间就会定时爬取一下,直到我们的 IP 池里面有一定数量的可用 IP 。
其实,作者在这个项目中运用的原来就是到一些免费的代理网站采集 IP,然后测试 IP 的可用性,可用的就存入 Redis 中,不可用就丢弃。
所以你完全可以自己写一套程序实现这个逻辑。
使用代理 IP
要使用代理 IP,你需要启动 webApi 服务:
python proxyPool.py server
启动web服务后, 默认配置下会开启 http://127.0.0.1:5010 的api接口服务:
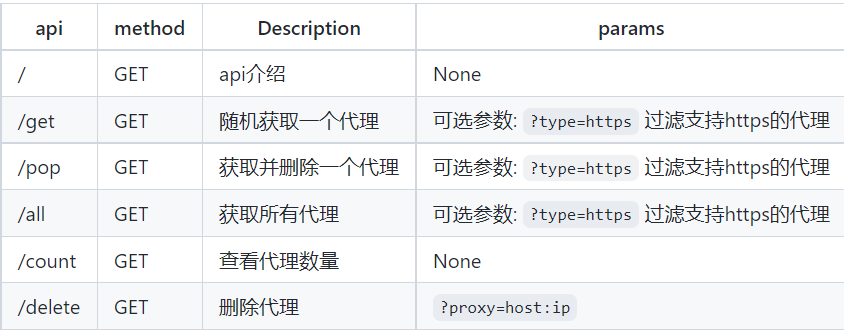
如果要在爬虫代码中使用的话, 可以将此api封装成函数直接使用,例如:
import requests
def get_proxy():
return requests.get("http://127.0.0.1:5010/get/").json()
def delete_proxy(proxy):
requests.get("http://127.0.0.1:5010/delete/?proxy={}".format(proxy))
# your spider code
def getHtml():
# ....
retry_count = 5
proxy = get_proxy().get("proxy")
while retry_count > 0:
try:
html = requests.get('http://www.example.com', proxies={"http": "http://{}".format(proxy)})
# 使用代理访问
return html
except Exception:
retry_count -= 1
# 删除代理池中代理
delete_proxy(proxy)
return None
总结
作为学习使用的 IP 代理池,这项目获取的足够使用了,但是对于一些复杂的爬虫项目或者商业项目的话,可能比较够呛,毕竟这种爬取的免费代理质量肯定没有那么好,不稳定是正常的。
这是我开发的机器人公众号小号,目前增加了天气查询,955公司名单,关注时间查询;后面还会增加图片功能和每日送书抽奖送书活动,以及调戏功能,欢迎来体验,捧场。
一个机器人公众号已经上线,欢迎调戏
推荐阅读:
入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径
干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |碟中谍这么火,我用机器学习做个迷你推荐系统电影
趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!
AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影
小工具: Pdf转Word,轻松搞定表格和水印! | 一键把html网页保存为pdf!| 再见PDF提取收费! | 用90行代码打造最强PDF转换器,word、PPT、excel、markdown、html一键转换 | 制作一款钉钉低价机票提示器! |60行代码做了一个语音壁纸切换器天天看小姐姐!|
年度爆款文案
点阅读原文,看B站我的视频
