
JVM进阶之路, 不然又要被面试官吊打了
1. 什么使用JVM?
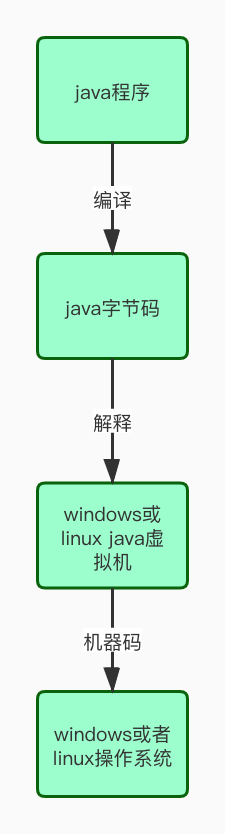
jvm编译流程
2. 字节码和机器码的区别
机器码是电脑CPU直接读取运行的机器指令, 运行速度最快, 但是非常晦涩难懂, 也比较难编写, 一般从业人员接触不到。
字节码是一种中建状态(中间码)的二进制代码(文件)。需要直译器转义后才能成为机器码
3. JDK, JRE, JVM的关系
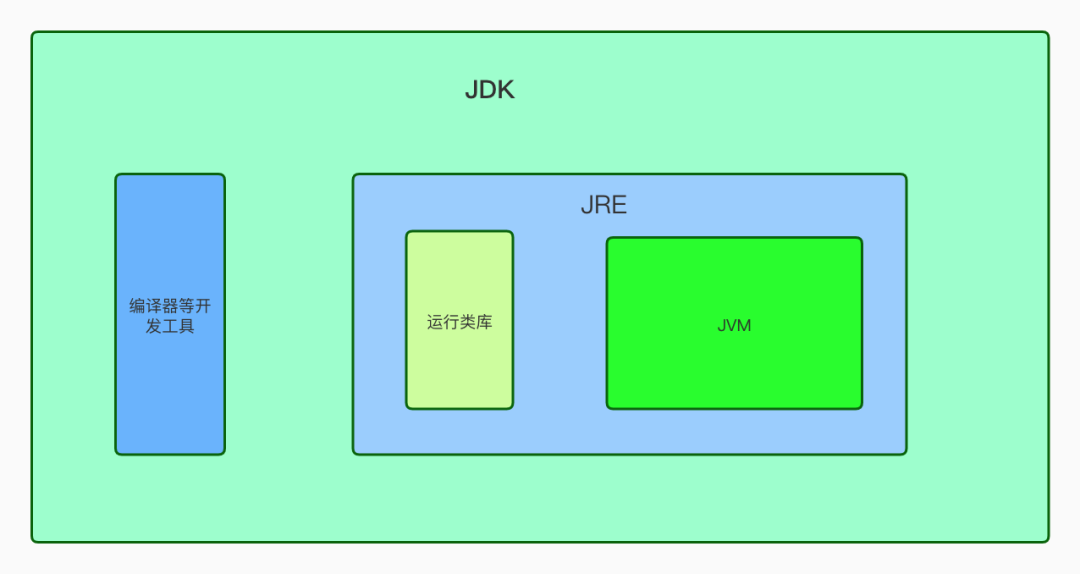
JDK,JRE,JVM的关系
4. OracleJDK和OpenJDK
4.1.查看JDK的版本
java -version
如果是SUN/OracleJDK, 显示信息为:
[root@localhost ~]# java -version
java version "1.8.0_162"
Java(TM) SE Runtime Environment (build 1.8.0_162-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.162-b12, mixed mode)
说明:
Java HotSpot(TM) 64-Bit Server VM 表明, 此JDK的JVM是Oracle的64位HotSpot****虚拟机,
运行在Server模式下(虚拟机有Server和Client两种运行模式)
Java(TM) SE Runtime Environment (build 1.8.0_162-b12) 是Java运行时环境(即JRE)的版本信息.
如果是OpenJDK, 显示信息为:
[root@localhost ~]# java -version
openjdk version "1.8.0_144"
OpenJDK Runtime Environment (build 1.8.0_144-b01) OpenJDK 64-Bit Server VM (build 25.144-b01, mixed mode)
4.2. OpenJDK和OracleJDK的区别
1. OpenJDK的来历
Java由SUN公司(Sun Microsystems, 发起于美国斯坦福大学, SUN是Stanford University Network
的缩写)发明, 2006年SUN公司将Java开源, 此时的JDK即为OpenJDK.
也就是说, OpenJDK是Java SE的开源实现, 它由SUN和Java社区提供支持, 2009年Oracle收购了Sun
公司, 自此Java的维护方之一的SUN也变成了Oracle . 大多数JDK都是在OpenJDK的基础上编写实现的, 比如IBM J9, Azul Zulu, Azul Zing和Oracle JDK.
几乎现有的所有JDK都派生自OpenJDK, 它们之间不同的是许可证:
OpenJDK根据许可证GPL v2发布;
Oracle JDK根据Oracle二进制代码许可协议获得许可。
2. Orcale JDK的来历
Oracle JDK之前被称为SUN JDK, 这是在2009年Oracle收购SUN公司之前, 收购后被命名为OracleJDK。
实际上, Oracle JDK是基于OpenJDK源代码构建的, 因此Oracle JDK和OpenJDK之间没有重大的技术差异。
Oracle的项目发布经理Joe Darcy在OSCON 2011 上对两者关系的介绍也证实了OpenJDK 7和Oracle JDK 7在程序上是非常接近的, 两者共用了大量相同的代码(如下图), 注意: 图中提示了两者共同代码的 占比要远高于图形上看到的比例, 所以我们编译的OpenJDK基本上可以认为性能、功能和执行逻辑上 都和官方的Oracle JDK是一致的。
3. OpenJDK和OracleJDK的区别
OpenJDK使用的是开源免费的FreeType, 可以按照GPL v2许可证使用.GPL V2允许在商业上使用;
Oracle JDK则采用JRL(Java Research License,Java研究授权协议) 放出.JRL只允许个人研究使 用,要获得Oracle JDK的商业许可证, 需要联系Oracle的销售人员进行购买。
4.3. JVM和Hotspot的关系
JVM是《JVM虚拟机规范》中提出来的规范
Hotspot是使用JVM规范的商用产品, 除此之外还有Orcacle JRockit, IBMde J9也是JVM产品
4.4. JVM和Java的关系
 jvm和java的关系.jpg
jvm和java的关系.jpg
4.5. JVM的运行模式
JVM有两种运行模式:Server模式与Client模式。
两种模式的区别在于:
Client模式启动速度较快,Server模式启动较慢;
但是启动进入稳定期长期运行之后Server模式的程序运行速度比Client要快很多。
因为Server模式启动的JVM采用的是重量级的虚拟机,对程序采用了更多的优化;
而Client模式启 动的JVM采用的是轻量级的虚拟机。所以Server启动慢,但稳定后速度比Client远远要快。
4.6. 程序执行方式有哪些?
主要有三种:静态编译执行、动态编译执行和动态解释执行。
JVM架构理解
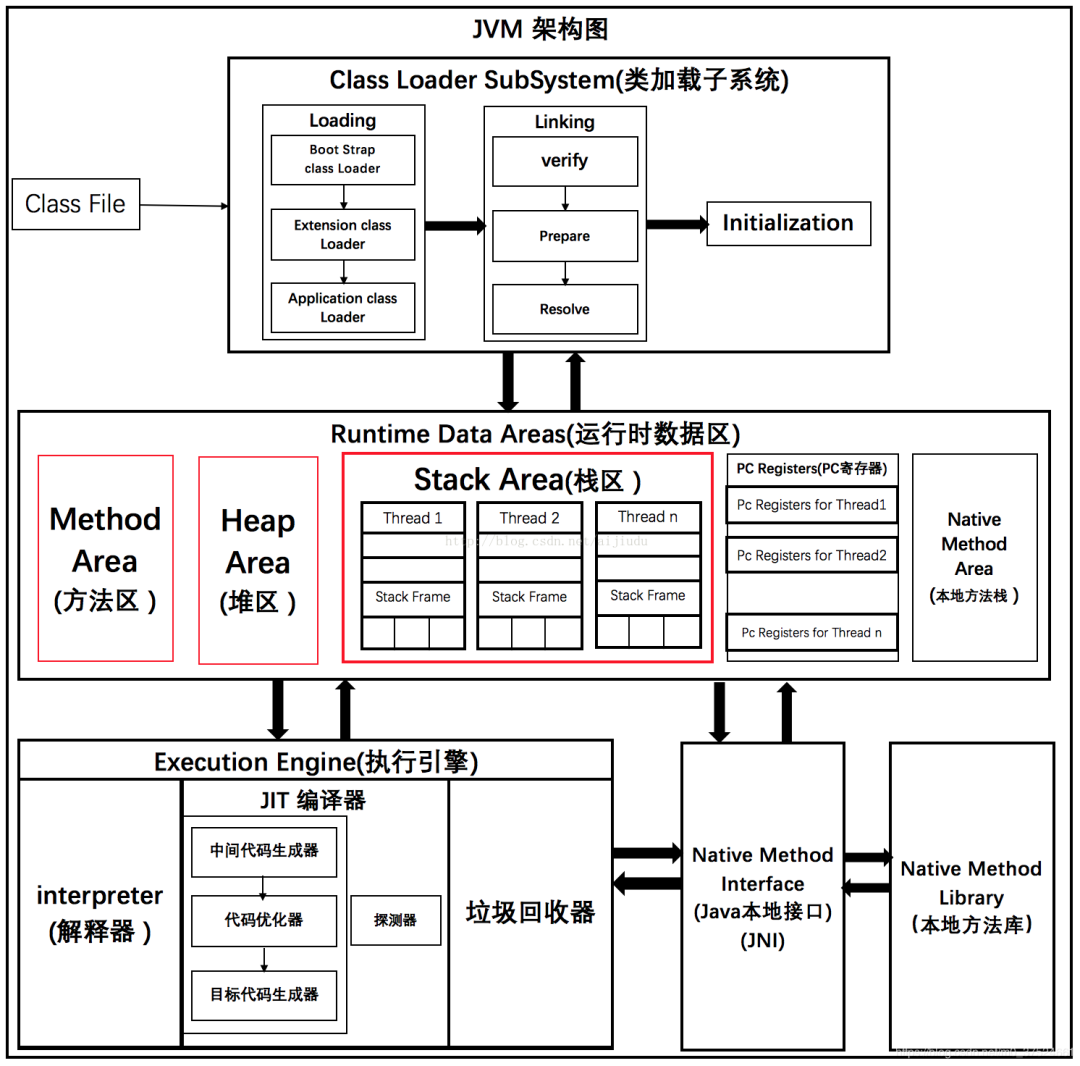
JVM架构图.png
JVM程序执行流程
Java编译成字节码、动态编译和解释为机器码的过程分析:
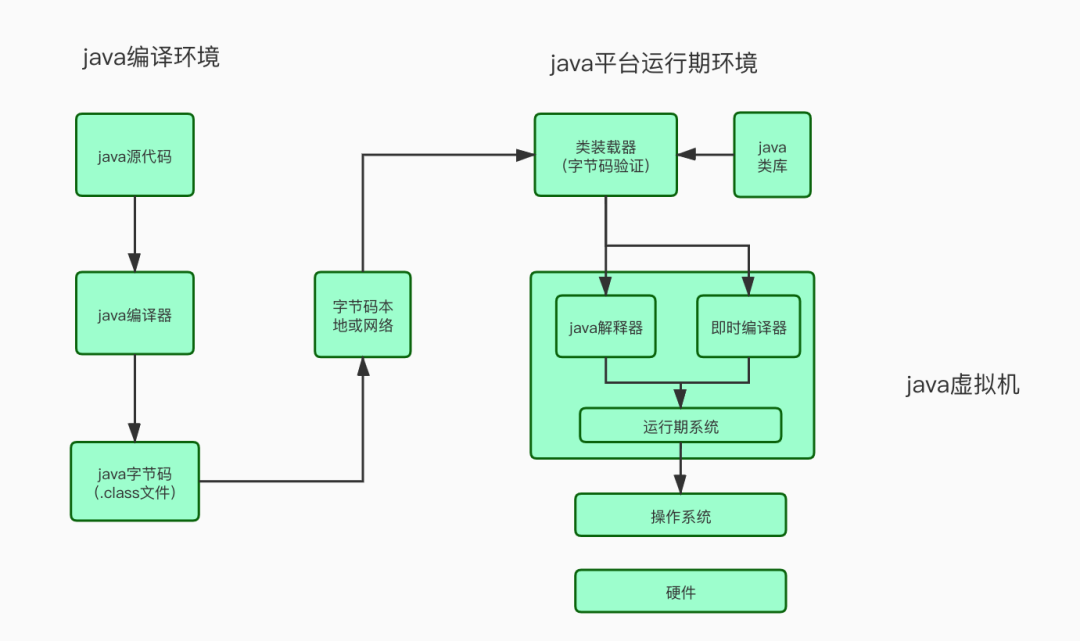
java编译执行过程.jpg
编译器和解释器的协调工作流程
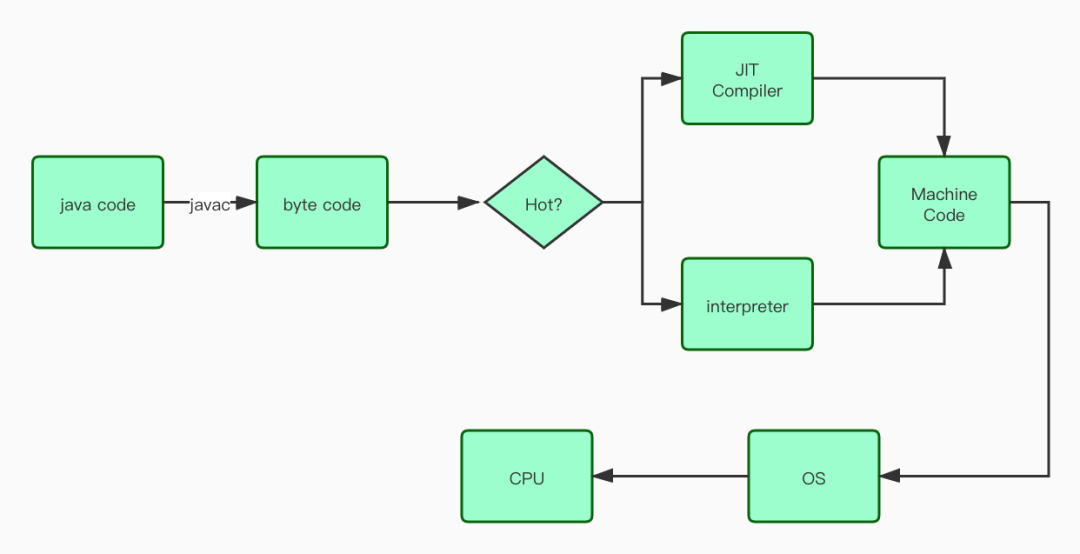
编译器和解释器的协调工作流程.jpg
在部分商用虚拟机中(如HotSpot),Java程序最初是通过解释器(Interpreter)进行解释执行的,当虚拟机发现某个方法或代码块的运行特别频繁时,就会把这些代码认定为“热点代码”。为了提高热点代 码的执行效率,在运行时,虚拟机将会把这些代码编译成与本地平台相关的机器码,并进行各种层次的 优化,完成这个任务的编译器称为 (Just In Time Compiler,下文统称JIT编译器)
由于Java虚拟机规范并没有具体的约束规则去限制即使编译器应该如何实现,所以这部分功能完全是与 虚拟机具体实现相关的内容,如无特殊说明,我们提到的编译器、即时编译器都是指Hotspot虚拟机内 的即时编译器,虚拟机也是特指HotSpot虚拟机。
我们的JIT是属于动态编译方式的, (dynamic compilation)指的是“在运行时进行编译”;与 之相对的是事前编译(ahead-of-time compilation,简称AOT),也叫 (static compilation)。
JIT编译(just-in-time compilation)狭义来说是当某段代码即将第一次被执行时进行编译,因而叫“即 时编译”。JIT 。JIT编译一词后来被泛化, 时常与动态编译等价;但要注意广 义与狭义的JIT编译所指的区别。
1. 哪些程序代码会被即时编译
程序中的代码只有是热点代码时,才会编译为本地代码,那么什么是 呢? 运行过程中会被即时编译器编译的“热点代码”有两类:
被多次调用的方法。
被多次执行的循环体。
两种情况,编译器都是以整个方法作为编译对象。这种编译方法因为编译发生在方法执行过程之中,因 此形象的称之为栈上替换(On Stack Replacement,OSR),即方法栈帧还在栈上,方法就被替换 了。
2. 如何判断热点代码呢?
要知道方法或一段代码是不是热点代码,是不是需要触发即时编译,需要进行Hot Spot Detection(热点探测)。
目前主要的热点探测方式有以下两种:
基于采样的热点探测
采用这种方法的虚拟机会周期性地检查各个线程的栈顶,如果发现某些方法经常出现在栈顶,那这 个方法就是“热点方法”。这种探测方法的好处是实现简单高效,还可以很容易地获取方法调用关系 (将调用堆栈展开即可),缺点是很难精确地确认一个方法的热度,容易因为受到线程阻塞或别的 外界因素的影响而扰乱热点探测。
基于计数器的热点探测
采用这种方法的虚拟机会为每个方法(甚至是代码块)建立计数器,统计方法的执行次数,如果执 行次数超过一定的阀值,就认为它是“热点方法”。这种统计方法实现复杂一些,需要为每个方法建 立并维护计数器,而且不能直接获取到方法的调用关系,但是它的统计结果相对更加精确严谨。
3. 热点检测方式
在HotSpot虚拟机中使用的是第二种——基于计数器的热点探测方法,因此它为每个方法准备了两个计 数器: 方法调用计数器和回变计数器 。在确定虚拟机运行参数的前提下,这两个计数器都有一个确定的 阈值,当计数器超过阈值溢出了,就会触发JIT编译。
方法调用计数器
顾名思义,这个计数器用于统计方法被调用的次数。
回边计数器
它的作用就是统计一个方法中循环体代码执行的次数,在字节码中遇到控制流向后跳转的指令称为“回边”。
4. JIT使用
4.1. 为什么要使用解释器与编译器并存的架构
尽管并不是所有的Java虚拟机都采用解释器与编译器并存的架构,但许多主流的商用虚拟机(如
HotSpot**),都同时包含解释器和编译器**。
解释器与编译器特点
当程序需要迅速启动和执行的时候,解释器可以首先发挥作用,省去编译的时间,立即执行。
在程 序运行后,随着时间的推移,编译器逐渐发挥作用,把越来越多的代码编译成本地代码之后,可以 获取更高的执行效率。
当程序运行环境中内存资源限制较大(如部分嵌入式系统中), 可以使用解释器执行节约内存, 反之可以使用编译执行来提升效率
编译的时间开销
解释器的执行, 抽象的看成是这样的
输入代码-> 解释器, 解释执行 -> 执行结果
而要JIT编译然后在执行的话, 抽象的看则是:
输入代码-> 编译器编译-> 编译后的代码 -> 执行-> 执行结果
说JIT比解释快,其实说的是“执行编译后的代码”比“解释器解释执行”要快,并不是说“编译”这个动作 比“解释”这个动作快。JIT编译再怎么快,至少也比解释执行一次略慢一些,而要得到最后的执行结果还 得再经过一个“执行编译后的代码”的过程。所以,对“只执行一次”的代码而言,解释执行其实总是比JIT 编译执行要快
怎么算是“只执行一次的代码”呢?粗略说,下面两个条件同时满足时就是严格的“只执行一次”
只被调用一次,例如类的构造器(class initializer,())
没有循环
对只执行一次的代码做JIT编译再执行,可以说是得不偿失。对只执行少量次数的代码,JIT编译带来的执行速度的提升也未必能抵消掉最初编译带来的开销。
只有对频繁执行的代码, JIT编译才能保证有正面的收益
编译的空间开销
对一般的Java方法而言,编译后代码的大小相对于字节码的大小,膨胀比达到10x是很正常的。同上面 说的时间开销一样,这里的空间开销也是,只有对执行频繁的代码才值得编译,如果把所有代码都编译 则会显著增加代码所占空间,导致“代码爆炸”。
这个就解释了为什么有些JVM在选择不总是做JIT编译, 而是选择用解释器+JIT编译器的混合执行引擎
4.2. 为何要实现两个不同的即时编译器
HotSpot虚拟机中内置了两个即时编译器:Client Complier和Server Complier,简称为C1、C2编译 器,分别用在客户端和服务端。
目前主流的HotSpot虚拟机中默认是采用解释器与其中一个编译器直接配合的方式工作。程序使用哪个 编译器,取决于虚拟机运行的模式。HotSpot虚拟机会根据自身版本与宿主机器的硬件性能自动选择运行模式,用户也可以使用“-client”或“-server”参数去强制指定虚拟机运行在Client模式或Server模式。
用Client Complier获取更高的编译速度,用Server Complier 来获取更好的编译质量。为什么提供多个 即时编译器与为什么提供多个垃圾收集器类似,都是为了适应不同的应用场景
4.3. 如何编译本地代码
Server Compiler和Client Compiler两个编译器的编译过程是不一样的。
对Client Compiler来说,它是一个简单快速的编译器,主要关注点在于局部优化,而放弃许多耗时较长 的全局优化手段。
而Server Compiler则是专门面向服务器端的,并为服务端的性能配置特别调整过的编译器,是一个充 分优化过的高级编译器。
4.4. JIT优化
HotSpot 虚拟机使用了很多种优化技术,这里只简单介绍其中的几种,完整的优化技术介绍可以参考官网内容。
公共子表达式的消除
公共子表达式消除是一个普遍应用于各种编译器的经典优化技术,他的含义是:如果一个表达式E已经 计算过了,并且从先前的计算到现在E中所有变量的值都没有发生变化,那么E的这次出现就成为了公共子表达式。对于这种表达式,没有必要花时间再对他进行计算,只需要直接用前面计算过的表达式结果 代替E就可以了。
如果这种优化仅限于程序的基本块内,便称为**局部公共子表达式消除(**Local Common Subexpression Elimination)
如果这种优化范围涵盖了多个基本块,那就称为**全局公共子表达式消除(**Global Common Subexpression Elimination)。
举个简单的例子来说明他的优化过程,假设存在如下代码:
int d = (c*b)*12+a+(a+b*c);
如果这段代码交给Javac编译器则不会进行任何优化,那生成的代码如下所示,是完全遵照Java源码的写 法直译而成的。
iload_2 // b
imul // 计算b*c
bipush 12 // 推入12
imul // 计算(c*b)*12
iload_1 // a
iadd // 计算(c*b)*12+a iload_1 // a
iload_2 // b
iload_3 // c
imul // 计算b*c
iadd // 计算a+b*c
iadd // 计算(c*b)*12+a+(a+b*c) istore 4
当这段代码进入到虚拟机即时编译器后,他将进行如下优化:编译器检测到”cb“ ”bc“是一样的表达 式,而且在计算期间b与c的值是不变的。因此,这条表达式就可能被视为:
int d = E*12+a+(a+E);
这时,编译器还可能(取决于哪种虚拟机的编译器以及具体的上下文而定)进行另外一种优化:代数化 简(Algebraic Simplification),把表达式变为:
int d = E*13+a*2;
表达式进行变换之后,再计算起来就可以节省一些时间了。
方法内联
在使用JIT进行即时编译时,将方法调用直接使用方法体中的代码进行替换,这就是方法内联,减少了方 法调用过程中压栈与入栈的开销。同时为之后的一些优化手段提供条件。如果JVM监测到一些小方法被 频繁的执行,它会把方法的调用替换成方法体本身。
比如说下面这个
private int add4(int x1, int x2, int x3, int x4) { return add2(x1, x2) + add2(x3, x4);
}
private int add2(int x1, int x2) {
return x1 + x2;
}
可以肯定的是运行一段时间后JVM会把add2方法去掉,并把你的代码翻译成:
private int add4(int x1, int x2, int x3, int x4) { return x1 + x2 + x3 + x4;
}
逃逸分析
逃逸分析(Escape Analysis)是目前Java虚拟机中比较前沿的优化技术。这是一种可以有效减少Java 程序 中同步负载和内存堆分配压力的跨函数全局数据流分析算法。通过逃逸分析,Java Hotspot编译器能够 分析出一个新的对象的引用的使用范围从而决定是否要将这个对象分配到堆上。
逃逸分析的基本行为就是分析对象动态作用域:当一个对象在方法中被定义后,它可能被外部方法所引用,例如作为调用参数传递到其他地方中,称为方法逃逸。
逃逸分析包括:
全局变量赋值逃逸
方法返回值逃逸
实例引用发生逃逸 线程逃逸:赋值给类变量或可以在其他线程中访问的实例变量
例如:
public class EscapeAnalysis { //全局变量
public static Object object;
public void globalVariableEscape(){//全局变量赋值逃逸
object = new Object();
}
public Object methodEscape(){ //方法返回值逃逸
return new Object();
}
public void instancePassEscape(){ //实例引用发生逃逸
this.speak(this);
}
public void speak(EscapeAnalysis escapeAnalysis){
System.out.println("Escape Hello");
}
}
使用方法逃逸的案例进行分析:
public static StringBuffer craeteStringBuffer(String s1, String s2) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
return sb;
}
StringBuffer sb是一个方法内部变量,上述代码中直接将sb返回,这样这个StringBuffer有可 能被其他方法所改变,这样它的作用域就不只是在方法内部,虽然它是一个局部变量,称其逃逸 到了方法外部。甚至还有可能被外部线程访问到,譬如赋值给类变量或可以在其他线程中访问的 实例变量,称为线程逃逸。
上述代码如果想要StringBuffer sb不逃出方法,可以这样写:
public static String createStringBuffer(String s1, String s2) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
return sb.toString();
}
不直接返回 StringBuffer,那么StringBuffer将不会逃逸出方法。
使用逃逸分析,编译器可以对代码做如下优化:
一、同步省略。如果一个对象被发现只能从一个线程被访问到,那么对于这个对象的操作可以不考虑同
步。二、将堆分配转化为栈分配。如果一个对象在子程序中被分配,要使指向该对象的指针永远不会逃逸,对
象可能是栈分配的候选,而不是堆分配。三、分离对象或标量替换。有的对象可能不需要作为一个连续的内存结构存在也可以被访问到,那么对象 的部分(或全部)可以不存储在内存,而是存储在CPU寄存器中。
在Java代码运行时,通过JVM参数可指定是否开启逃逸分析,
-XX:+DoEscapeAnalysis : 表示开启逃逸分析
-XX:-DoEscapeAnalysis : 表示关闭逃逸分析
从jdk 1.7开始已经默认开始逃逸分析,如需关闭,需要指定 -XX:-DoEscapeAnalysis
对象的栈上内存分配
我们知道,在一般情况下,对象和数组元素的内存分配是在堆内存上进行的。但是随着JIT编译器的日渐 成熟,很多优化使这种分配策略并不绝对。JIT编译器就可以在编译期间根据逃逸分析的结果,来决定是 否可以将对象的内存分配从堆转化为栈。
我们来看以下代码:
public class EscapeAnalysisTest {
public static void main(String[] args) {
long a1 = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
alloc();
}
// 查看执行时间
long a2 = System.currentTimeMillis();
System.out.println("cost " + (a2 - a1) + " ms");
// 为了方便查看堆内存中对象个数,线程sleep
try {
Thread.sleep(100000);
} catch (InterruptedException e1) {
e1.printStackTrace();
}
}
//此方法内的User对象,未发生逃逸
private static void alloc() {
User user = new User();
}
static class User {
}
}
其实代码内容很简单,就是使用for循环,在代码中创建100万个User对象。我们在alloc方法中定义了User对象,但是并没有在方法外部引用他。也就是说,这个对象并不会
逃逸到alloc外部。经过JIT**的逃逸分析之后,就可以对其内存分配进行优化
我们指定以下JVM参数并运行:
-Xmx4G -Xms4G -XX:-DoEscapeAnalysis -XX:+PrintGCDetails -XX:+HeapDumpOnOutOfMemoryError
在程序打印出 cost XX ms 后,代码运行结束之前,我们使用jmap命令,来查看下当前堆内存中有多 少个User对象:
~ jps
2809 StackAllocTest
2810 Jps
~ jmap -histo 2809
num #instances #bytes class name
----------------------------------------------
1: 524 87282184 [I
2: 1000000 16000000 StackAllocTest$User
3: 6806 2093136 [B
4: 8006 1320872 [C
5: 4188 100512 java.lang.String
6: 581 66304 java.lang.Class
从上面的jmap执行结果中我们可以看到,堆中共创建了100万个 StackAllocTest$User 实例。
在关闭逃避分析的情况下(-XX:-DoEscapeAnalysis),虽然在alloc方法中创建的User对象并没 有逃逸到方法外部,但是还是被分配在堆内存中。也就说,如果没有JIT编译器优化,没有逃逸分 析技术,正常情况下就应该是这样的。即所有对象都分配到堆内存中
接下来,我们开启逃逸分析,再来执行下以上代码。
-Xmx4G -Xms4G -XX:+DoEscapeAnalysis -XX:+PrintGCDetails -XX:+HeapDumpOnOutOfMemoryError
在程序打印出 cost XX ms 后,代码运行结束之前,我们使用 jmap 命令,来查看下当前堆内存中有多 少个User对象:
~ jps
709
2858 Launcher
2859 StackAllocTest
2860 Jps
~ jmap -histo 2859
num #instances #bytes class name
---------------------------------------------
1: 524 101944280 [I
2: 6806 2093136 [B
3: 83619 1337904 StackAllocTest$User
4: 8006 1320872 [C
5: 4188 100512 java.lang.String
6: 581 66304 java.lang.Class
从以上打印结果中可以发现,开启了逃逸分析之后(-XX:+DoEscapeAnalysis),在堆内存中只有 8万多个 StackAllocTest$User 对象。也就是说在经过JIT优化之后,堆内存中分配的对象数量, 从100万降到了8万。
除了以上通过jmap验证对象个数的方法以外,还可以尝试将堆内存调小,然后执行以上代码,根 据GC的次数来分析,也能发现,开启了逃逸分析之后,在运行期间,GC次数会明显减少。正是 因为很多堆上分配被优化成了栈上分配,所以GC次数有了明显的减少。
所以,如果以后再有人问你:是不是所有的对象和数组都会在堆内存分配空间?
那么你可以告诉他:不一定,随着JIT编译器的发展,在编译期间,如果JIT经过逃逸分析,发现有些对象 没有逃逸出方法,那么有可能堆内存分配会被优化成栈内存分配。但是这也并不是绝对的。就像我们前 面看到的一样,在开启逃逸分析之后,也并不是所有User对象都没有在堆上分配。
4.5. 标量替换
标量(Scalar**)**是指一个无法再分解成更小的数据的数据 。
在JIT阶段,如果经过逃逸分析,发现一个对象不会被外界访问的话,那么经过JIT优化,就会把这个对象拆解成若干个其中包含的若干个成员变量来代替。
//有一个类A
public class A{
public int a=1;
public int b=2
}
//方法getAB使用类A里面的a,b
private void getAB(){
A x = new A();
x.a;
x.b;
}
//JVM在编译的时候会直接编译成
private void getAB(){
a = 1;
b = 2;
}
//这就是标量替换
4.6. 同步锁消除
同样基于逃逸分析,当加锁的变量不会发生逃逸,是线程私有的完全没有必要加锁。在JIT编译时期就 可以将同步锁去掉,以减少加锁与解锁造成的资源开销。
public class TestLockEliminate {
public static String getString(String s1, String s2) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
return sb.toString();
}
public static void main(String[] args) {
long tsStart = System.currentTimeMillis();
for (int i = 0; i < 10000000; i++) {
getString("TestLockEliminate ", "Suffix");
}
System.out.println("一共耗费:" + (System.currentTimeMillis() - tsStart) + " ms");
}
}
getString()方法中的StringBuffer数以函数内部的局部变量,进作用于方法内部,不可能逃逸出该 方法,因此他就不可能被多个线程同时访问,也就没有资源的竞争,但是StringBuffer的append 操作却需要执行同步操作,
StringBuffer中append方法的代码如下:
@Override
public synchronized StringBuffer append(String str) {
toStringCache = null;
super.append(str);
return this;
}
逃逸分析和锁消除分别可以使用参数 -XX:+DoEscapeAnalysis 和 -XX:+EliminateLocks (锁消除必须 在-server模式下)开启。使用如下参数运行上面的程序:
-XX:+DoEscapeAnalysis -XX:-EliminateLocks
得到如下结果:
一共耗费:244ms
使用如下命令运行程序:
-XX:+DoEscapeAnalysis -XX:+EliminateLocks
一共耗费:220ms
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️