
图解|了解分布式—程序员进阶之路
编程是一门艺术,它的魅力在于创造。
65 哥已经工作两年了,一直做着简单重复的编程工作,活活熬成了一个只会 CRUD 的打工 boy。
65 哥:总是听大佬讲分布式分布式,什么才是分布式系统呢?
分布式系统是一个硬件或软件系统分布在不同的网络计算机上,彼此之间仅仅通过消息传递进行通信和协调的系统。在一个分布式系统中,一组独立的计算机展现给用户的是一个统一的整体,就好像是一个系统似的。系统拥有多种通用的物理和逻辑资源,可以动态的分配任务,分散的物理和逻辑资源通过计算机网络实现信息交换。
65 哥:巴拉巴拉,能不能讲点人话。俺听不懂。
那好,下面我们从平常最熟悉的事物开始理解分布式系统如何出现,发展的,并经过实践总结通用的理论,这些理论成为指导我们如何设计更完善的分布式系统的基础。
从此篇文章,你将学习到以下知识:
Web 应用的扩展
为什么会出现分布式应用?
65 哥:这个我也不清楚啊,以前我写的 web 应用都是直接扔进 Tomcat 中,启动 Tomcat 就可以访问了,这肯定不是分布式应用。
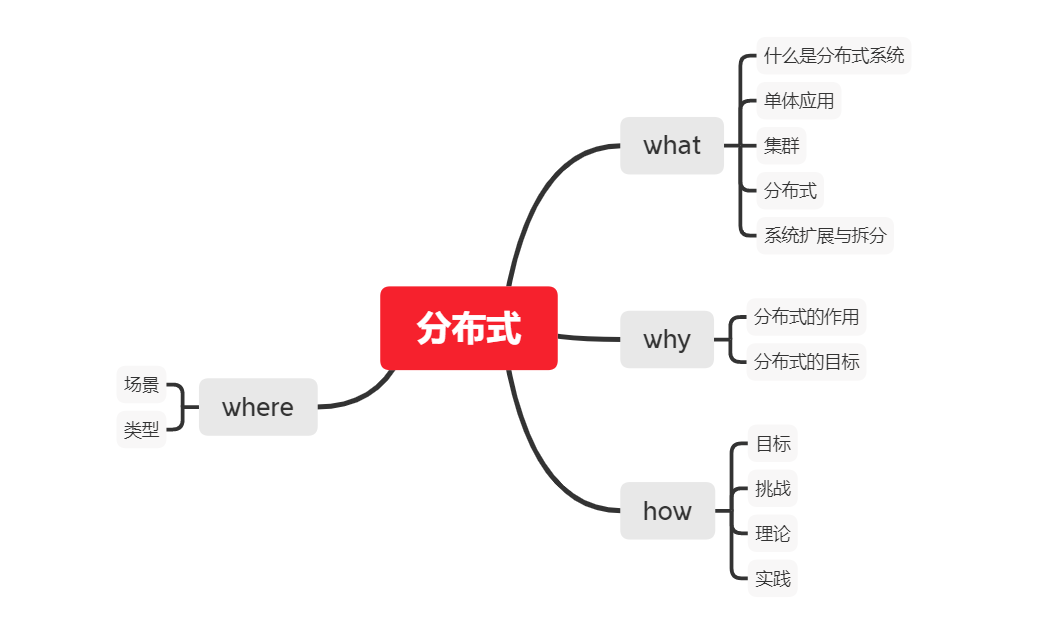
嗯,我们就从大家最熟悉 web 后台应用讲起,以前我们的系统访问量小,业务也不复杂,一台服务器一个应用就可以处理所有的业务请求了,后来我们公司发达了,访问量上去了,业务也拓展了,虽然老板依旧没有给我们加工资,却总是埋怨我们系统不稳定,扛不住大并发,是可忍孰不可也,加钱,我们要升级。
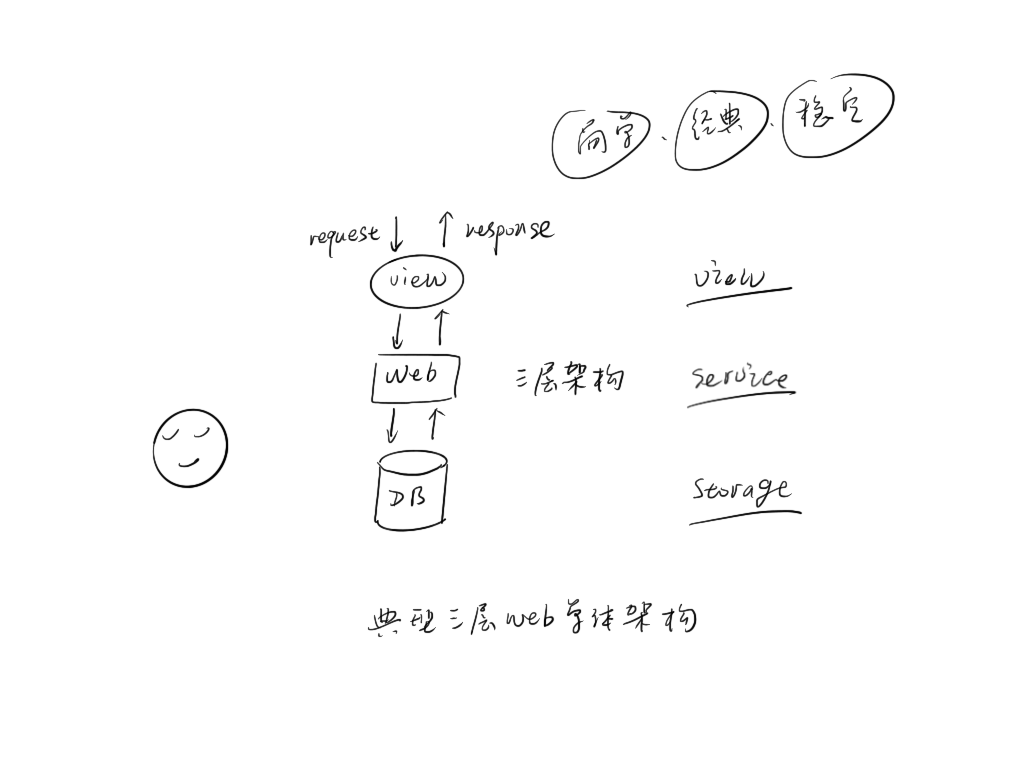
如果我们的服务器可以无限添加配置,那么一切性能问题都不是问题。
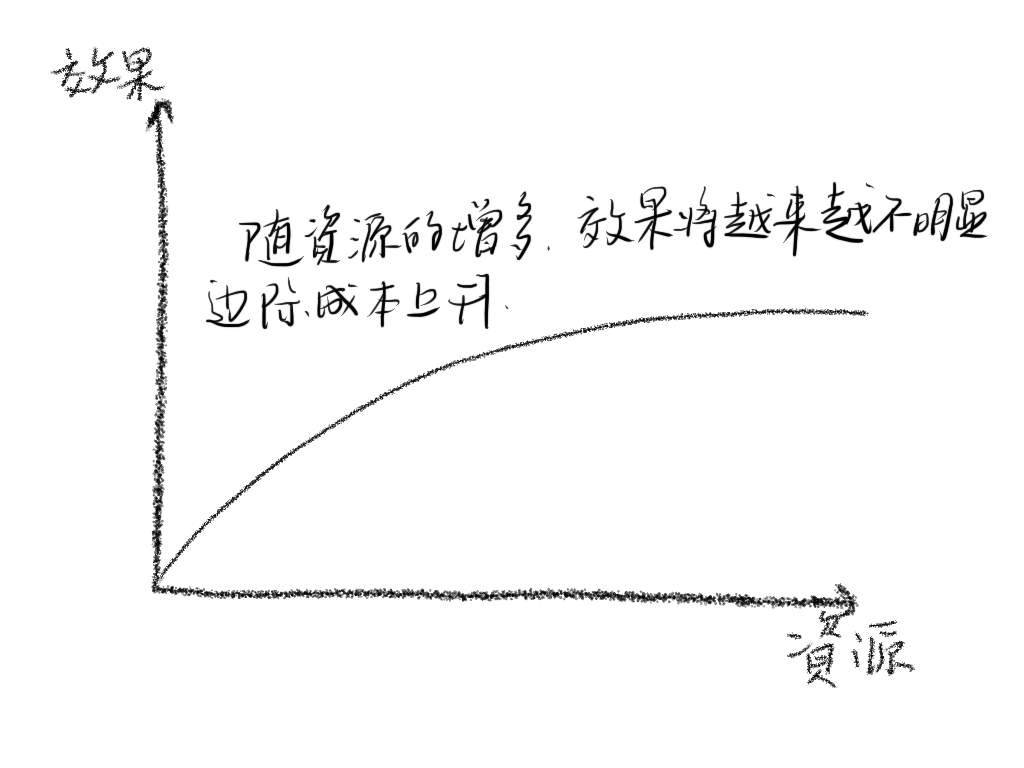
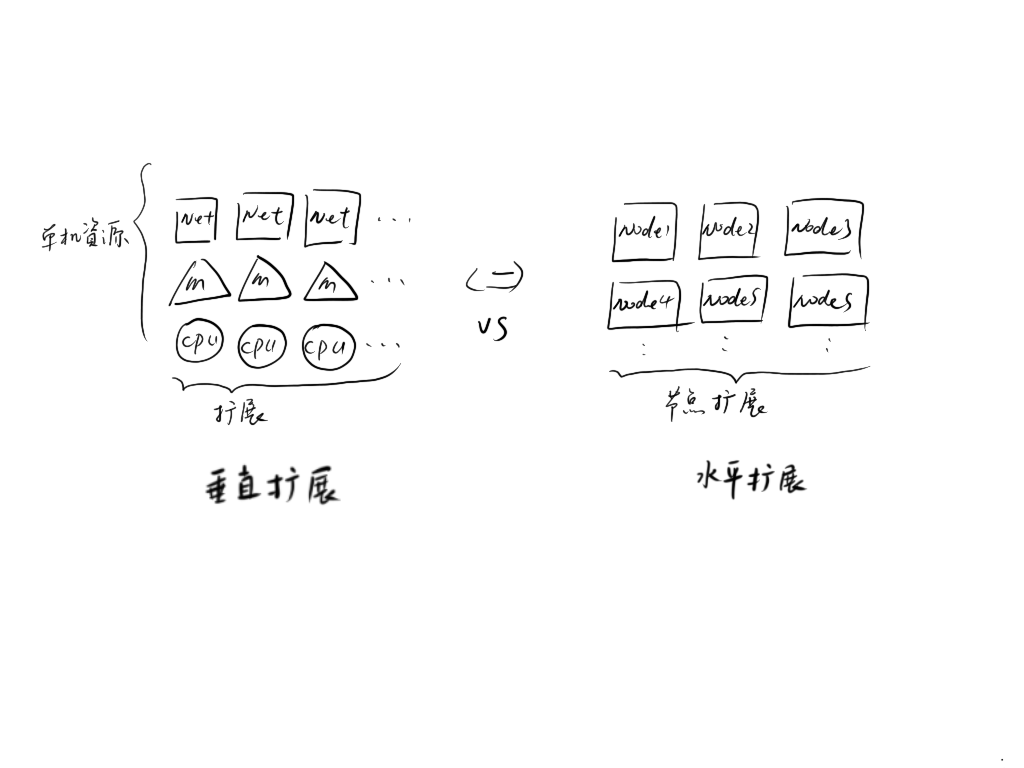
为提高系统处理能力,我们首先想到的扩展方式就是升级系统配置,8 核 cpu 升级为 32 核,64 核,内存 64G 升级为 128G,256G,带宽上万兆,十万兆,这就叫做垂直扩展。但这样的扩展终将无法持续下去,原因如下。
单机系统的处理能力最终会达到瓶颈 单机升级的边际成本将越来越大
没有什么可以拦住我们编程打工人的步伐。
俗话说,系统撑不住了,就加服务器,一台不行就加两台。
当垂直扩展到达技术瓶颈或投入产出比超过预期,我们可以考虑通过增加服务器数量来提高并发能力,这种方式就是水平扩展。
系统拆分
65 哥:哦,这就是分布式系统了?这么简单的么。
我勒个呵呵,哪有那么简单,在水平扩展中,我们增加了服务器数量,但是如何让这些服务器像一个整体一样对外提供稳定有效的服务才是关键。既然已经有了多台服务器,我们就要考虑如何将系统部署到到不同的节点上去。
65 哥:这还不简单,我将我的 SpringBoot 项目部署到多台服务器上,前面加个 nginx 就可以了,现在我们的系统都是这样的,稳定高效 perfect。给你画个架构图(小声,这个我在学校时就会了。)
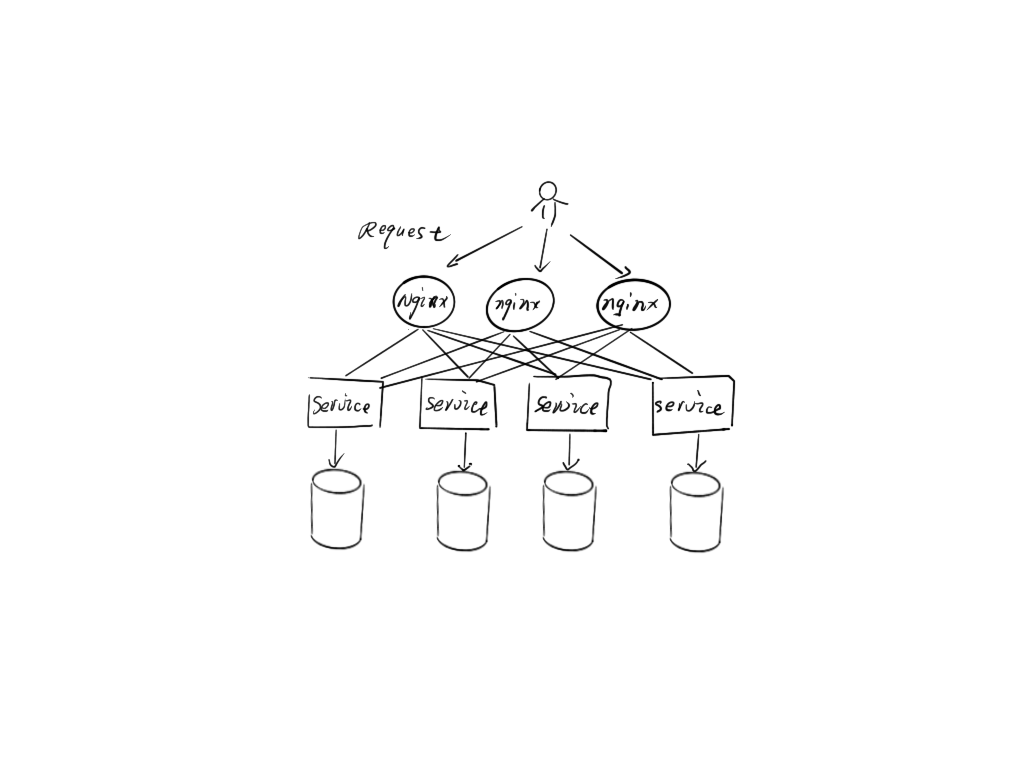
哪有什么岁月静好,只不过是有人在为你负重前行。上面你所认为的简单,其实有两个原因:
系统分离不彻底,很重要的一点,就是依然在共享一个数据库 在这个成熟的体系中,有太多成熟的中间件在为我们服务,比如上面提到的 nginx
系统拆分也有两种方式,垂直拆分和水平拆分,注意,这里和上面提到的垂直扩展和水平扩展不是处理同一个问题的。(65 哥:哈哈,我知道,世间万物不外乎纵横二字)。
系统的垂直拆分,就是将相同的系统部署多套,所有的节点并没有任何不同,角色和功能都一样,它们各自分担一部分功能请求,这样整个系统的处理能力的上升了。
从处理 web 请求上来看,垂直拆分的每个节点都处理一个完整的请求,每个节点都承担一部分请求量;
从数据存储的角度看,每个数据节点都存储相同的业务数据,每个节点存储一部分数据。
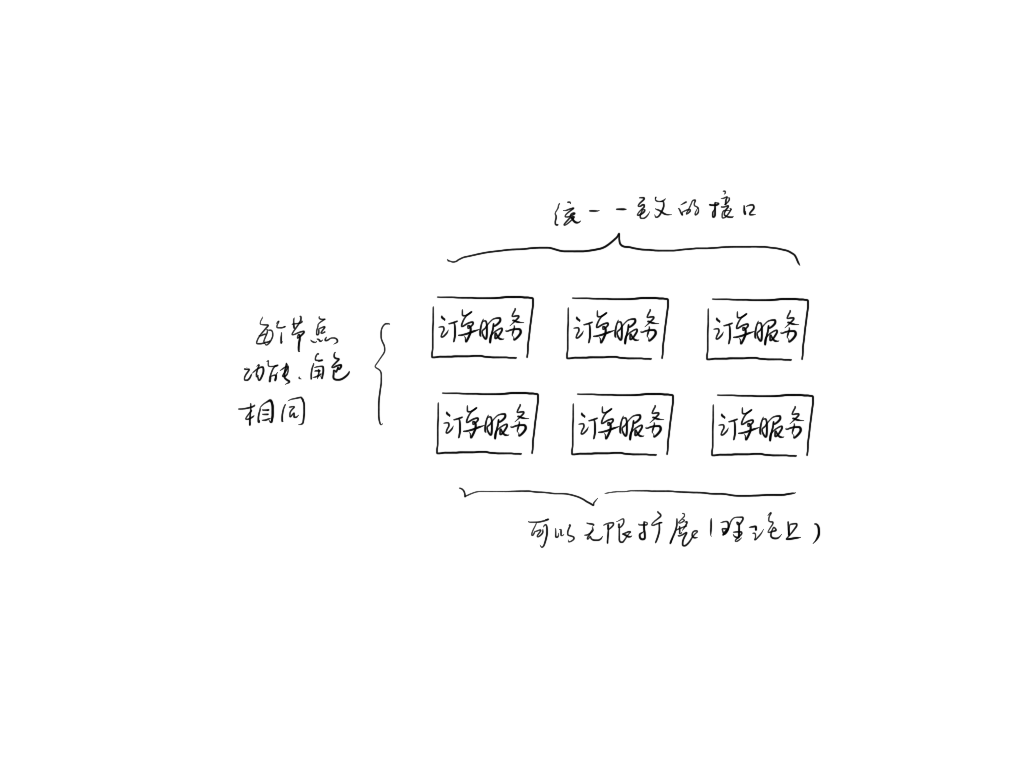
系统的水平拆分,就是将系统按不同模块或角色拆分,不同的模块处理不同的事情。
从 web 请求上来看,需要多个相互依赖的系统配合完成一个请求,每个节点处理的需求不一致;
从数据存储角度上来看,每个数据节点都存储着各自业务模块相关的数据,它们的数据都不一样。
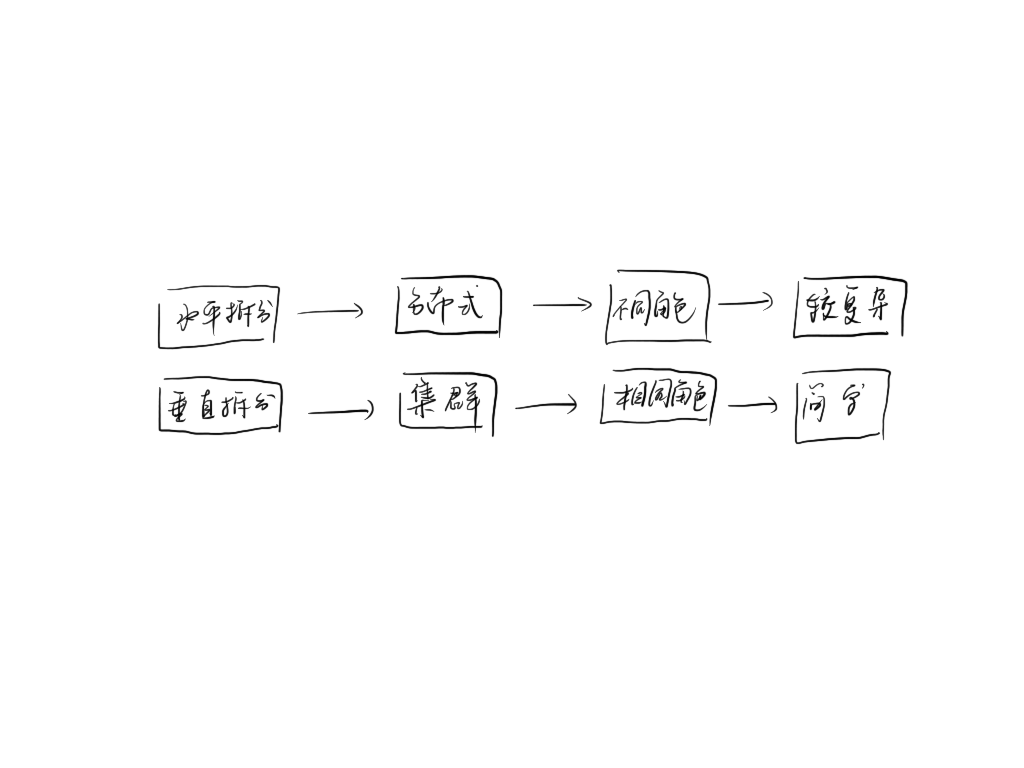
上面垂直拆分之后各个节点组成的就是一个集群,而水平拆分各个节点就是分布式。这就是集群和分布式的区别。集群除了上面提到的可以提高并发处理能力外,还可以保证系统的高可用,当一部分节点失效后,整个系统依旧可以提供完整的服务。分布式也一样,除了提高并发能力,解耦系统,使系统边界更清晰,系统功能更内聚也是其一大好处,所以在实际的系统中我们往往这两种方式同时都在使用,而且我们常常提及的分布式系统其实是包含着集群的概念在里面的。
分布式目标
归纳和演绎是人类理性的基石,学习和思考就是不断的归纳过去的经验,从而得到普遍的规律,然后将得之的规律演绎于其他事物,用于指导更好的实践过程。
上面我们讲解了分布式系统的由来,现在我们回顾和总结一下这个过程。我们引入分布式系统必然是基于现实的需求和目标而来的。
65 哥:那分布式的目标什么呢?
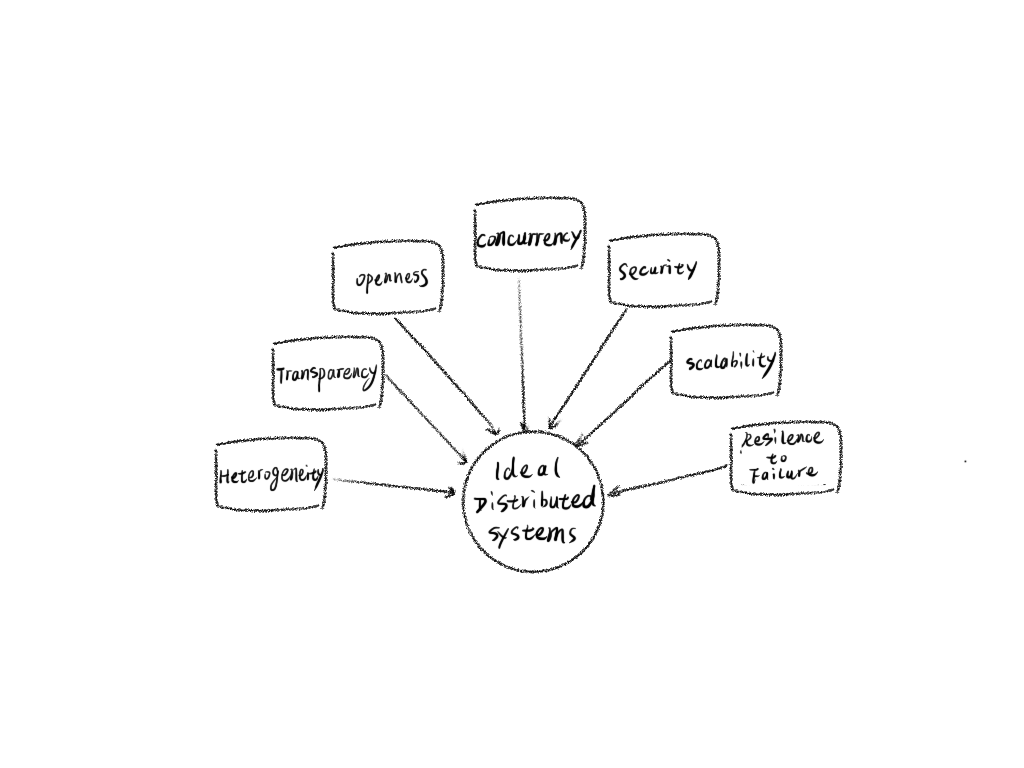
分布式就是为了满足以下目标而设计的:
Transparency: 透明性,即用户是不关心系统背后的分布式的,无论系统是分布式的还是单机的,对用户来说都应该是透明的,用户只需要关心系统可用的能力。这里的透明性就包括以下方面: 访问透明性:固定统一的访问接口和方式,不因为分布式系统内部的变动而改变系统的访问方式。 位置透明性:外部访问者不需要知道分布式系统具体的地址,系统节点的变动也不会影响其功能。 并发透明性:几个进程能并发的使用共享资源而不互相干扰。 复制透明性:使用资源的多个实例提升可靠性和性能,而用户和程序员无需知道副本的相关信息。 故障透明性:分布式系统内部部分节点的故障不影响系统的整体功能。 移动透明性:资源和客户能够在系统内移动而不受影响。 性能透明性:负载变化时,系统能够被重新配置以提高性能。 伸缩透明性:系统和应用能够进行扩展而不改变系统结构和应用算法。 Openness: 开放性,通用的协议和使用方式。 Scalability: 可伸缩性,随着资源数量的增加和用户访问的增加,系统仍然能保持其有效性,该系统就被称为可伸缩的。分布式系统应该在系统大小,系统管理方面都可扩展。 Performance: 性能,相对于单体应用,分布式系统应该用更加突出的性能。 Reliability: 可靠性,与单体系统相比,分布式系统应具有更好安全性,一致性和掩盖错误的能力。
分布式挑战
分布式的挑战来源于不确定性。想一想,分布式系统相对于单体应用,多了哪些东西?
65 哥:有了更多的服务节点,还有就是服务之间的网络通信。
是的,看来 65 哥同学已经懂得思考和分析系统了。分布式系统的所有挑战就来源于这两者的不确定性。
节点故障:
节点数量越多,出故障的概率就变高了。分布式系统需要保证故障发生的时候,系统仍然是可用的,这就需要系统能够感知所有节点的服务状态,在节点发生故障的情况下将该节点负责的计算、存储任务转移到其他节点。
不可靠的网络:
节点间通过网络通信,我们都知道网络是不可靠的。可能的网络问题包括:网络分割、延时、丢包、乱序。相比单机过程调用,网络通信最让人头疼的是超时已经双向通行的不确定性。出现超时状态时,网络通信发起方是无法确定当前请求是否被成功处理的。
在不可靠的网络和节点中,分布式系统依然要保证其可用,稳定,高效,这是一个系统最基本的要求。因此分布式系统的设计和架构充满了挑战。
分而治之
分布式系统就是充分利用更多的资源进行并行运算和存储来提升系统的性能,这就是分而治之的原理。
65 哥:哦,懂了懂了,那 MapReduce 的 map,Elasticsearch 的 sharding,Kafka 的 partition 是不是都是分布式的分而治之原理。
可以啊,65 哥同学不仅能够归纳,还能够举一反三了。不错,无论是 map,sharding 还是 partition,甚至 请求路由负载均衡 都是在将计算或数据拆分,再分布到不同的节点计算和存储,从而提高系统的并发性。
不同集群类型的分
sharding
同样是分,在不同领域的,甚至不同实现的系统中通常会有不同的说法。sharding 通常是在数据存储系统中将不同数据分布到不同节点的方式,中文通常翻译为数据分片。
比如在 MongoDB 中,当 MongoDB 存储海量的数据时,一台机器可能不足以存储数据,也可能不足以提供可接受的读写吞吐量。这时,我们就可以通过在多台机器上分割数据,使得数据库系统能存储和处理更多的数据。
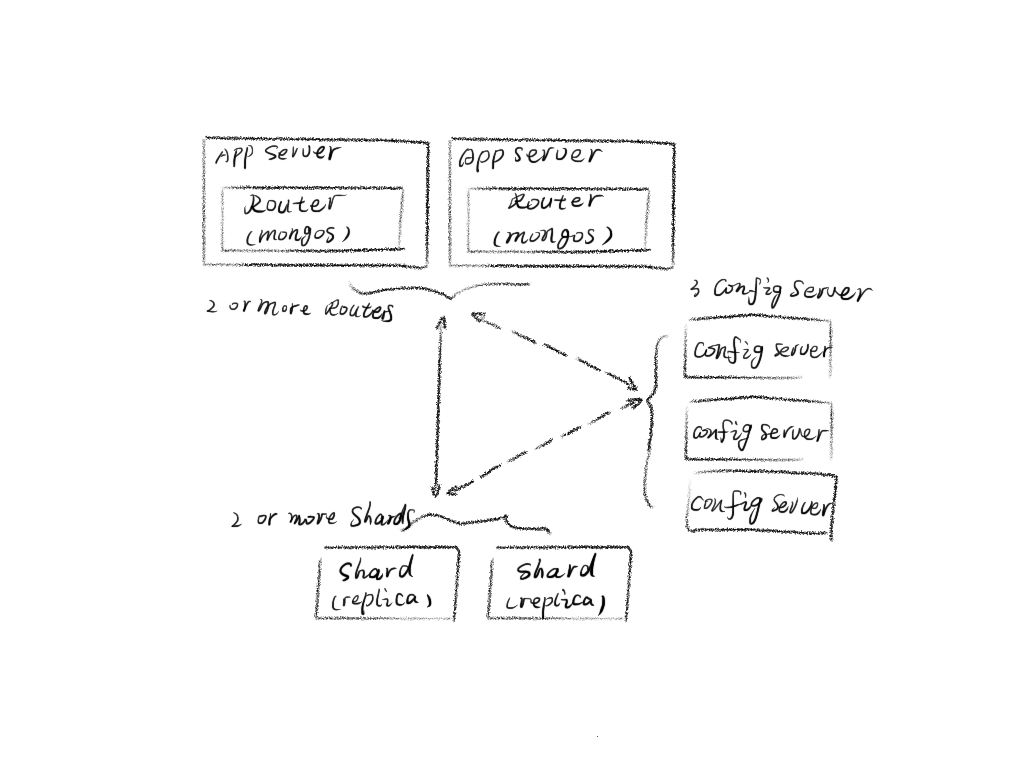
比如在 Elasticsearch 中,每个索引有一个或多个分片,索引的数据被分配到各个分片上,相当于一桶水用了 N 个杯子装。分片有助于横向扩展,N 个分片会被尽可能平均地(rebalance)分配在不同的节点上。
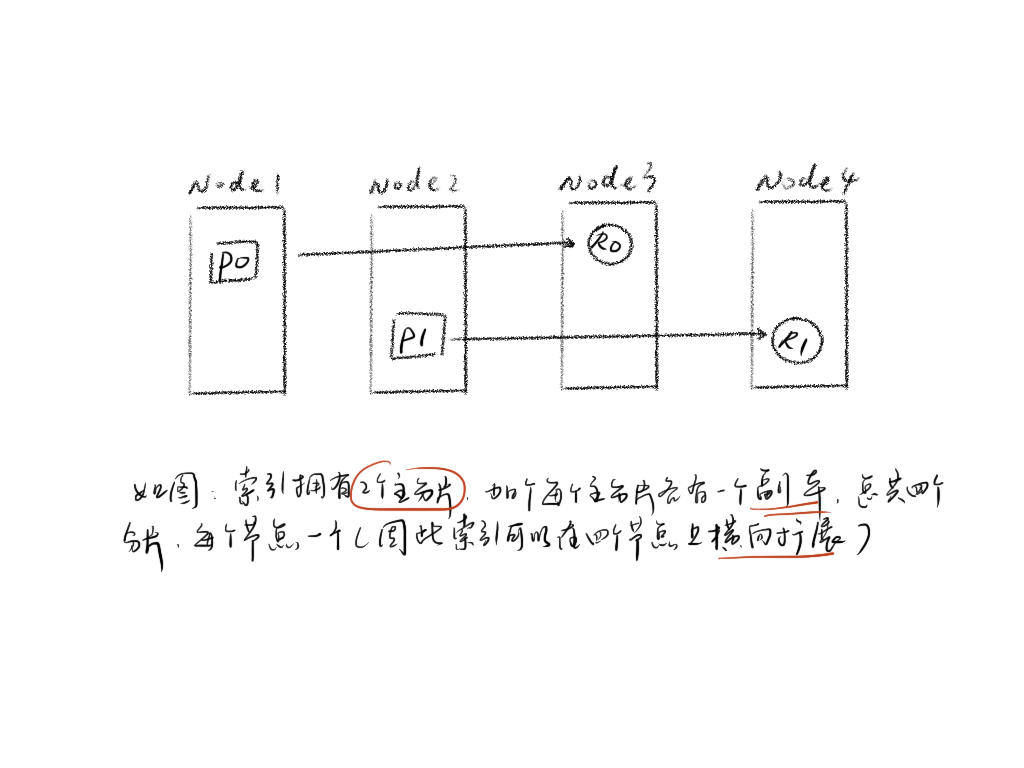
partition
partition的概念经常在 Kafka 中可以看到,在 kafka 中 topic 是一个逻辑概念,从分布式队列的角度看,topic 对使用者来说就是一个队列,topic 在 kafka 的具体实现中,由分布在不同节点上的 partition 组成,每个 partition 就是根据分区算法拆分的多个分区,在 kafka 中,同一个分区不能被同一个 group 下的多个 consumer 消费,所以一个 topic 有多少 partition 在一定意义上就表示这个 topic 具有多少并发处理能力。
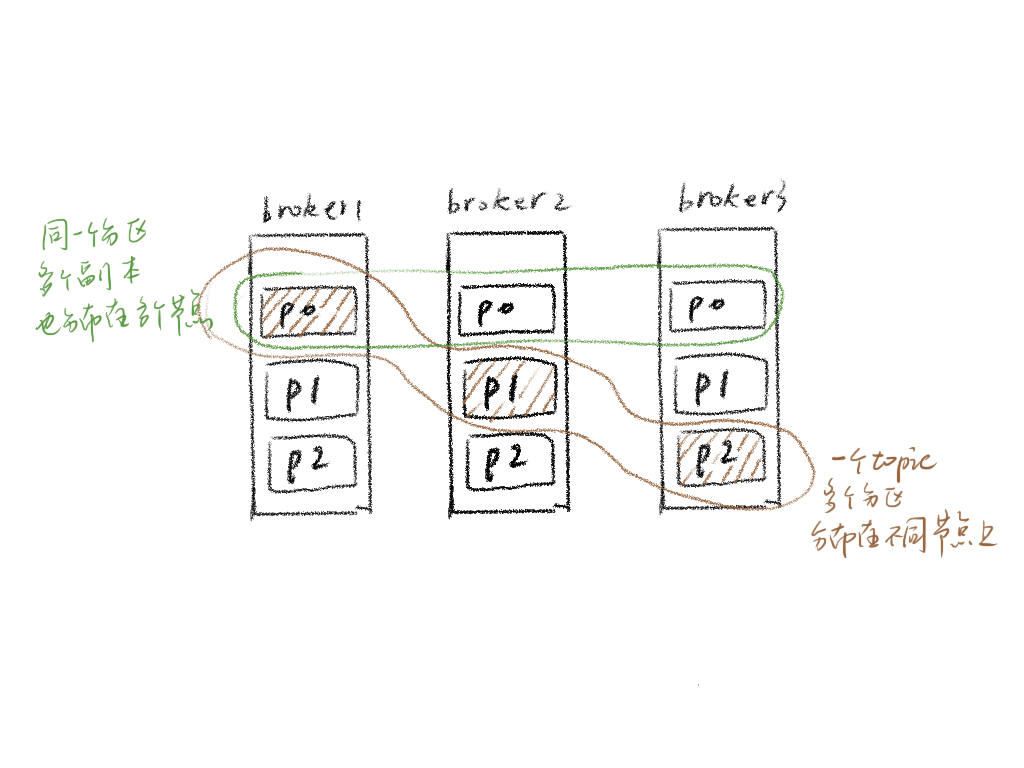
在 Amazing 的分布式数据库DynamoDB中,一张表在底层实现中也被分区为不同的 partition。
load balance
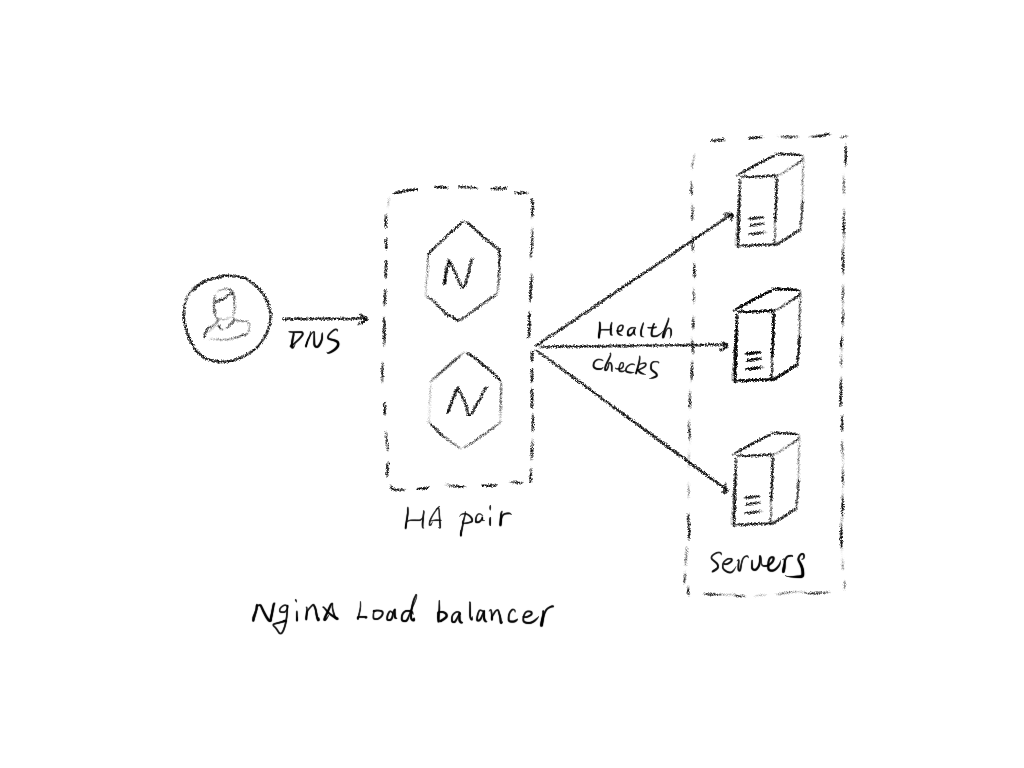
负载均衡是高可用网络基础架构的关键组件,通常用于将工作负载分布到多个服务器来提高网站、应用、数据库或其他服务的性能和可靠性。
比如 nginx 的负载均衡,通过不同的负载均衡分配策略,将 http 请求分发到 web 应用的不同节点之上,从而提高应用的并发处理能力。
比如 dubbo 的客户端负载能力,可以将 dubbo 请求路由到具体的 producer 提供节点上,负载均衡是一个完善的 RPC 所应该具有的能力。
在 Spring Cloud 的体系中 Robbin 组件可以通过 Spring Cloud 的各微服务之间通信的负载均衡分配问题,依旧是将请求分发到集群中的不同节点上去。
分的策略
无论是分区还是分片,还是分区路由,其实都有一些通用的分区算法,以下的概念可能很多同学都在不同的领域看到过,如上面看到的反向代理服务器 nginx 中,如分布式消息队列 kafka 中,如 RPC 框架 Dubbo 中,这有时候会让很多同学感到懵。
其实无论在什么领域中,你只要抓住它在完成的核心功能上就可以理解,它们就是在考虑如何分的问题,把处理请求(即计算)如何均匀地分到不同的机器上,把数据如何分配到不同的节点上。
从大的方向看分有两种策略,一种可复刻,一种不可复刻。
可复刻,这种策略根据一定算法分配计算和数据,在相同的条件下,无论什么时间点得出的结果相同,因此对于相同条件的请求和数据来说是可复刻的,在不同时间点相同的请求和数据始终都在统一节点上。这种策略一般用于有数据状态在情况。
不可复刻,这种策略使用全随机方式,即使在相同的条件下,不同时间点得出的结果也不一致,因此也是不可还原的,如果只是为了可还原,如果通过元数据记录已经分配好的数据,之后需要还原时通过元数据就可以准确的得知数据所在位置了。
65 哥:这么神奇么?我想看看不同系统都有什么策略。
Dubbo 的负载均衡
Dubbo 是阿里开源的分布式服务框架。其实现了多种负载均衡策略。
Random LoadBalance
随机,可以按权重设置随机概率。在一个截面上碰撞的概率高,但调用量越大分布越均匀,而且按概率使用权重后也比较均匀,有利于动态调整提供者权重。
RoundRobin LoadBalance
轮询,按公约后的权重设置轮询比率。存在慢的提供者累积请求的问题,比如:第二台机器很慢,但没挂,当请求调到第二台时就卡在那,久而久之,所有请求都卡在调到第二台上。
LeastActive LoadBalance
最少活跃调用数,相同活跃数的随机,活跃数指调用前后计数差。使慢的提供者收到更少请求,因为越慢的提供者的调用前后计数差会越大。
ConsistentHash LoadBalance
一致性 Hash,相同参数的请求总是发到同一提供者。当某一台提供者挂时,原本发往该提供者的请求,基于虚拟节点,平摊到其它提供者,不会引起剧烈变动。
Kafka 的分区分配策略
Kafka 中提供了多重分区分配算法(PartitionAssignor)的实现:
RangeAssignor
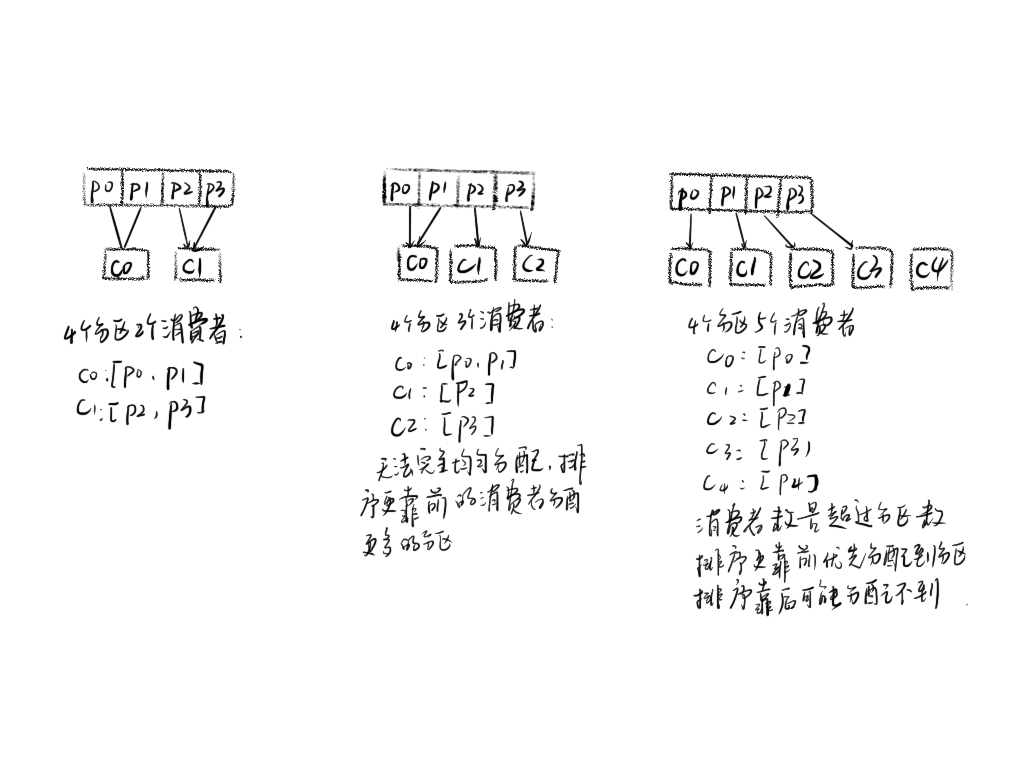
RangeAssignor 策略的原理是按照消费者总数和分区总数进行整除运算来获得一个跨度,然后将分区按照跨度进行平均分配,以保证分区尽可能均匀地分配给所有的消费者。对于每一个 Topic,RangeAssignor 策略会将消费组内所有订阅这个 Topic 的消费者按照名称的字典序排序,然后为每个消费者划分固定的分区范围,如果不够平均分配,那么字典序靠前的消费者会被多分配一个分区。
RoundRobinAssignor
RoundRobinAssignor 的分配策略是将消费组内订阅的所有 Topic 的分区及所有消费者进行排序后尽量均衡的分配(RangeAssignor 是针对单个 Topic 的分区进行排序分配的)。
StickyAssignor
从字面意义上看,Sticky 是“粘性的”,可以理解为分配结果是带“粘性的”——每一次分配变更相对上一次分配做最少的变动(上一次的结果是有粘性的),其主要是为了实现以下两个目标:
分区的分配尽量的均衡 每一次重分配的结果尽量与上一次分配结果保持一致
65 哥:哇,看来优秀的系统都是相通的。
副本
副本是解决分布式集群高可用问题的。在集群系统中,每个服务器节点都是不可靠的,每个系统都有宕机的风险,如何在系统中少量节点失效的情况下保证整个系统的可用性是分布式系统的挑战之一。副本就是解决这类问题的方案。副本同样也可以提高并发处理能力,比如数据在不同的节点上可以读写分离,可以并行读等。
在这里其实也有很多说法,如 Master-Salve、Leader-Follower、Primary-Shard、Leader-Replica 等等。
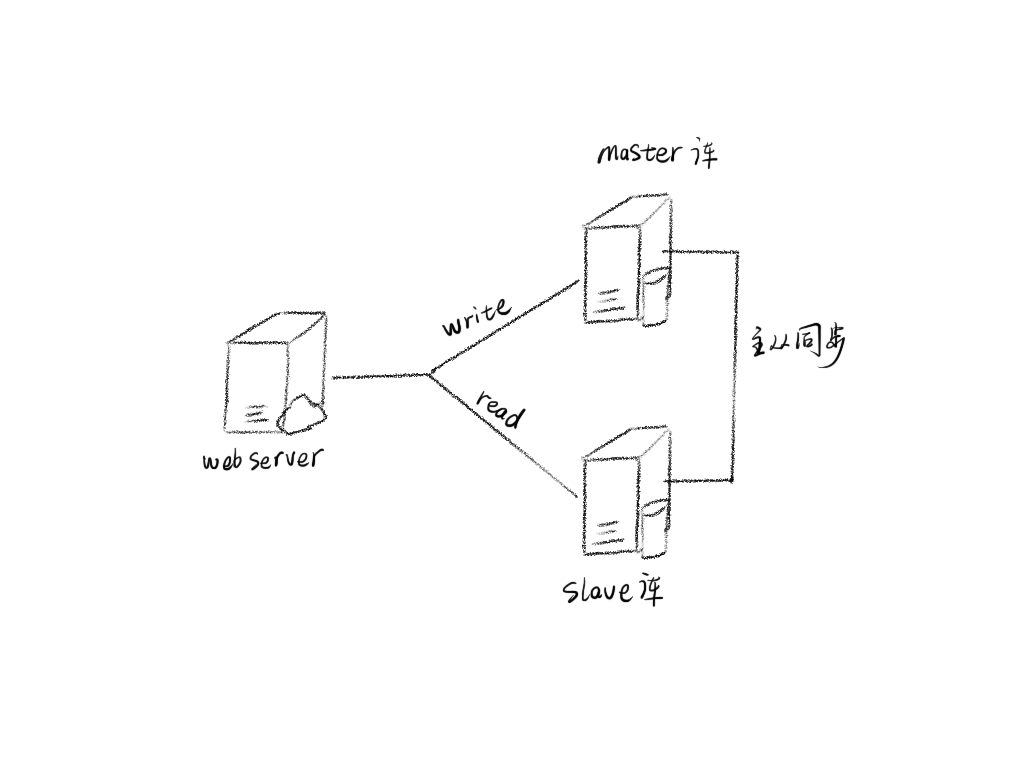
Mysql 的主从架构
目前,大部分的主流关系型数据库都提供了主从热备功能,通过配置两台(或多台)数据库的主从关系,可以将一台数据库服务器的数据更新同步到另一台服务器上。这既可以实现数据库的读写分离,从而改善数据库的负载压力,也可以提高数据高可用,多份数据备份降低了数据丢失的风险。
Elasticsearch 的副本机制
在 ES 中有主分片和副本分片的概念。副本分片的主要目的就是为了故障转移,如果持有主分片的节点挂掉了,一个副本分片就会晋升为主分片的角色从而对外提供查询服务。
CAP 理论
在理论计算机科学中,CAP 定理(CAP theorem),又被称作布鲁尔定理(Brewer's theorem),它指出对于一个分布式计算系统来说,不可能同时满足分布式系统一致性、可用性和分区容错(即 CAP 中的"C","A"和"P"):
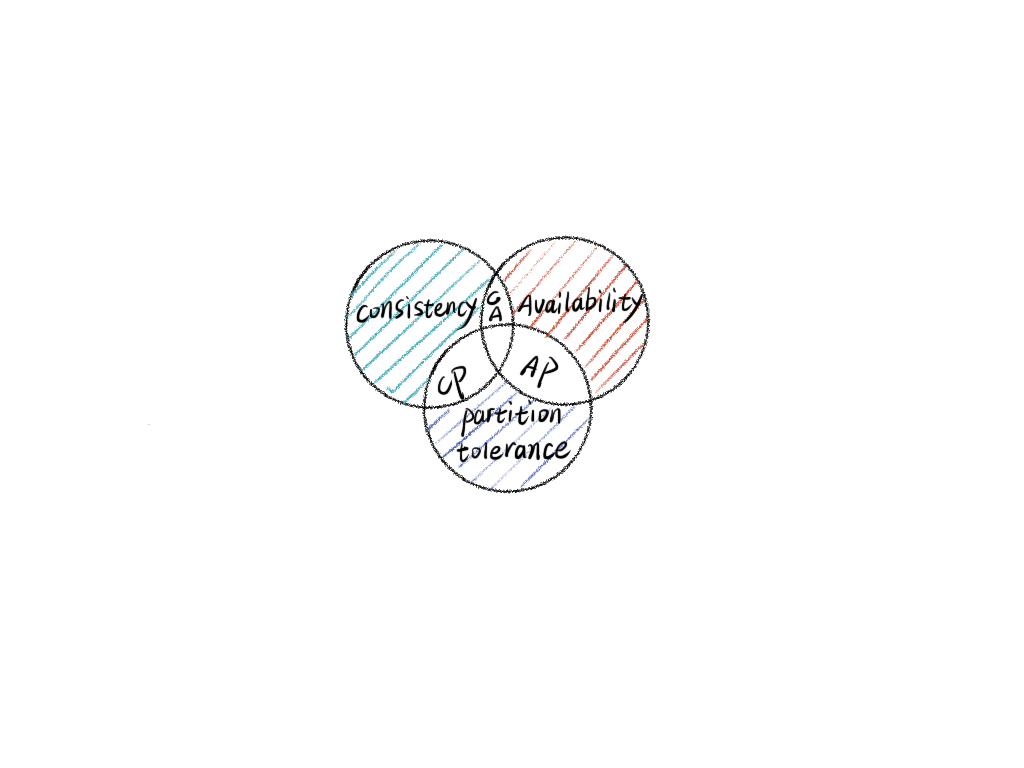
65 哥:什么是一致性、可用性和分区容错性能?
一致性 (Consistency)
一致性意味着所有客户端同时看到相同的数据,无论它们连接到哪个节点。要发生这种情况,每当将数据写入一个节点时,必须立即将数据转发或复制到系统中的所有其他节点,然后才能将写入视为"成功"。
可用性 (Availability)
任何客户端的请求都能得到响应数据,不会出现响应错误。换句话说,可用性是站在分布式系统的角度,对访问本系统的客户的另一种承诺:我一定会给您返回数据,不会给你返回错误,但不保证数据最新,强调的是不出错。
分区容错
分区即分布式系统中的通信中断,两个节点之间的丢失或暂时延迟的连接。分区容错意味着群集必须继续工作,尽管系统中的节点之间存在的通信故障。
这三种性质进行俩俩组合,可以得到下面三种情况:
CA:完全严格的仲裁协议,例如 2PC(两阶段提交协议,第一阶段投票,第二阶段事物提交) CP:不完全(多数)仲裁协议,例如 Paxos、Raft AP:使用冲突解决的协议,例如 Dynamo、Gossip
CA 和 CP 系统设计遵循的都是强一致性理论。不同的是 CA 系统不能容忍节点发生故障。CP 系统能够容忍 2f+1 个节点中有 f 个节点发生失败。
Base 理论
CAP 理论表明,对于一个分布式系统而言,它是无法同时满足 Consistency(强一致性)、Availability(可用性) 和 Partition tolerance(分区容忍性) 这三个条件的,最多只能满足其中两个。
在分布式环境中,我们会发现必须选择 P(分区容忍)要素,因为网络本身无法做到 100% 可靠,有可能出故障,所以分区是一个必然的现象。也就是说分区容错性是分布式系统的一个最基本要求。
CAP 定理限制了我们三者无法同时满足,但我们可以尽量让 C、A、P 都满足,这就是 BASE 定理。
BASE 理论是 Basically Available(基本可用),Soft State(软状态)和 Eventually Consistent(最终一致性)三个短语的缩写。即使无法做到强一致性(Strong consistency),但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventual consistency)。
基本可用 (Basically Available)
基本可用是指分布式系统在出现故障的时候,允许损失部分可用性,即保证核心可用。
电商大促时,为了应对访问量激增,部分用户可能会被引导到降级页面,服务层也可能只提供降级服务,这就是损失部分可用性的体现。
软状态 ( Soft State)
什么是软状态呢?相对于原子性而言,要求多个节点的数据副本都是一致的,这是一种“硬状态”。
软状态指的是:允许系统中的数据存在中间状态,并认为该状态不影响系统的整体可用性,即允许系统在多个不同节点的数据副本存在数据延时。
最终一致性 ( Eventual Consistency)
最终一致性是指系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。
弱一致性和强一致性相反,最终一致性是弱一致性的一种特殊情况。
BASE 理论面向的是大型高可用、可扩展的分布式系统。与传统 ACID 特性相反,不同于 ACID 的强一致性模型,BASE 提出通过牺牲强一致性来获得可用性,并允许数据段时间内的不一致,但是最终达到一致状态。
分布式是系统扩展的必然方向,分布式系统所遇到的问题是普遍,随着大量优秀的项目在分布式的道路上披荆斩棘,前人已经总结了大量丰富的理论。并且不同领域的分布式系统也层出不穷,我们既应该学习好这些好的理论知识,也应该去多看看不同分布式系统的实现,总结它们的共性,发现它们在不同领域独特的亮点权衡,更重要的,我们应该将所学用于日常项目的实践当中,也应该在实践中总结出更多的规律理论。
感谢读者看完本文,码哥将为读者持续输出高质量的文章,下期我们继续深入讲讲分布式一致性的问题和解决方案,敬请关注。
往期推荐: