
【面试招聘】快手 AI算法岗面试及答案解析
文章共2000字,预计阅读时间10min
参考目录:
1 自我介绍+项目
2 样本不均衡的处理方法
3 随机森林中随机的意义
4 卷积层的缺点
5 最大池化层 vs 平均池化层?
6 随机森林中bagging的比例为什么是63.2%
7 卷积网络感受野怎么扩大
8 什么模型需要数据标准化?
9 数据标准化的目的是什么?
10 如果模型欠拟合怎么办
11 模型中dropout在训练和测试的区别?
12 算法题:数组的回文遍历
1 自我介绍+项目
参考答案:略
2 样本不均衡的处理方法
之前文章讲过8种常见的方法:上采样,下采样,二分类变成多分类等多模型方法。
3 随机森林中随机的意义
随机对数据进行样本采样和特征采样。这个随机森林的内容之前的文章也讲解的非常详细啦。下面文章比较长,内容比较全。
【小白学ML】随机森林 全解 (从bagging到variance)
4 卷积层的缺点
反向传播更新参数对数据的需求量非常大;卷积的没有平移不变性,稍微改变同一物体的朝向或者位置,会对结果有巨大的改变,虽然数据增强会有一定缓解;池化层让大量图像特丢失,只关注整体特征,而忽略到局部。比方说,在识别人脸的时候,只要人的五官同时出现,那么就会认为这是人脸,因此按照泽中卷积池化的判别方式,下面两种情况可能会被判断成同一图片.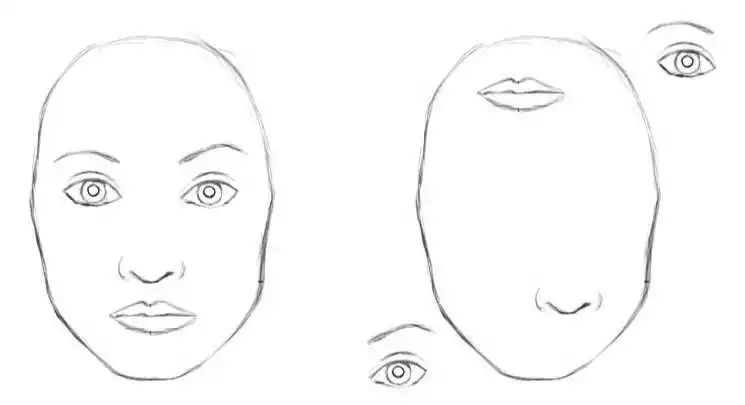
总之,CNN最大的两个问题在于平移不变性和池化层。
5 最大池化层 vs 平均池化层?
这个我不太确定,当时的回答是:平均池化层会让特征图变得更加模糊;最大池化层反向传播中,计算量会小于平均池化层;最大池化层会增加一定的平移不变性和旋转不变性给卷积网络。
根据相关理论,特征提取的误差主要来自两个方面:
邻域大小受限造成的估计值方差增大; 卷积层参数误差造成估计均值的偏移。
一般来说,mean-pooling能减小第一种误差,更多的保留图像的背景信息,max-pooling能减小第二种误差,更多的保留纹理信息。
6 随机森林中bagging的比例为什么是63.2%
关键公式:
这个详细的计算过程也在随即森林全解的文章中。
【小白学ML】随机森林 全解 (从bagging到variance)
7 卷积网络感受野怎么扩大
池化层。maxpool,avepool,感受野大一倍。 空洞卷积。 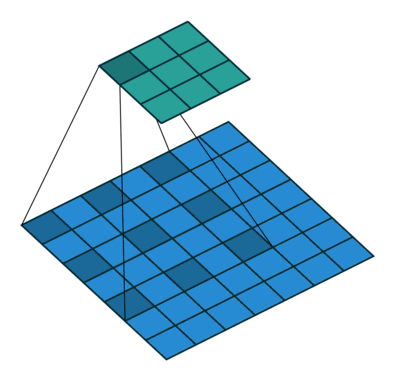
多个3*3的卷积层可以构成5*5和7*7的视野域。 GCN图卷积网络也可以起到这样的效果,但是对GCN了解的不多。
8 什么模型需要数据标准化?
我们可以知道当原始数据不同维度上的特征的尺度(单位)不一致时 ,需要标准化步骤对数据进行预处理。
聚类模型,kmeans,DBSCAN等聚类算法;2,神经网络 分类模型,逻辑回归和SVM等
决策树模型则不需要进行标准化,回归模型不用标准化。
9 数据标准化的目的是什么?
先说个人理解的答案:
消除图片过曝,质量不佳等对模型权重的影响; 让梯度下降更稳定
对于卷积网路来说,如果两个相同的图片之间的对比度等不同,就会导致像素值不同,模型对于不同像素值的同一图片会认定为是两个不同的图片。如下图:
大家看上面两只猪,对于人来说,它就是两只一样的猪,只是图片的灰度或者曝光度不一样罢了,于是我们都给它们都标注为“社会人”。虽然我们人眼看起来没有什么毛病,但是对于CNN网络来说,他们的特征很可能不同。这时候一般会对图片事先进行一个Z-Score的标准化(减去均值处以标准差,是不是很多朋友都不知道这个方法的学名。) 把不同的图片映射到同一尺度下,因此上述问题就从像素值不同的问题转化成相似的特征分布的问题,一定程度上消除了因为过度曝光,质量不佳,或者噪音等各种原因对模型权值更新的影响。
另外一个原因是,一个图片RGB三个通道,往往三个通道的数据分布不同。比方说可能一个图片的R的数值偏大,这样就会导致反向传播的时候,图片R通道的梯度大,更新快。R通道就会占据模型判断的主导地位。而下一张图片可能是绿色G比较大,更新较快,从而产生一个类似学习率不稳定的问题。
通过Z-Score,把每个通道都变成0均值1方差,让梯度下降更稳定。
10 如果模型欠拟合怎么办
这道题一开始问懵了。因为之前的几次面试基本上问的都是如何解决过拟合问题。过拟合问题之前也整理的很好了,突然问欠拟合宕机了。不过这个问题也不难,这里简单说一下个人回答的思路:
首先欠拟合就是模型没有很好地捕捉到数据特征,不能够很好地拟合数据,例如下面的例子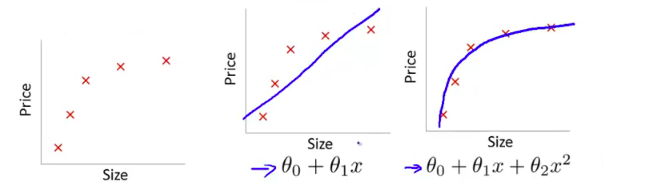 左图表示size与prize关系的数据,中间的图就是出现欠拟合的模型,不能够很好地拟合数据,如果在中间的图的模型后面再加一个二次项,就可以很好地拟合图中的数据了,如右面的图所示。(其实就是增加特征嘛)
左图表示size与prize关系的数据,中间的图就是出现欠拟合的模型,不能够很好地拟合数据,如果在中间的图的模型后面再加一个二次项,就可以很好地拟合图中的数据了,如右面的图所示。(其实就是增加特征嘛)
解决方法:
添加其他特征项,有时候我们模型出现欠拟合的时候是因为特征项不够导致的, 可以添加其他特征项来很好地解决。
添加多项式特征,这个在机器学习算法里面用的很普遍,例如将线性模型通过添加二次项或者三次项使模型泛化能力更强。例如上面的图片的例子。
减少正则化参数,正则化的目的是用来防止过拟合的,但是现在模型出现了欠拟合,则需要减少正则化参数。减小其他的正则化参数,比如树模型中的参数:叶子结点中中最小样本限制,树深度限制,等等
增加模型的复杂度,卷积网路哦加深加宽,boost模型增加训练的迭代次数。
不过关键还是在于更多特征的构建把。
11 模型中dropout在训练和测试的区别?
Dropout 是在训练过程中以一定的概率的使神经元失活,即输出为0,以提高模型的泛化能力,减少过拟合。
Dropout 在训练时采用,是为了减少神经元对部分上层神经元的依赖,类似将多个不同网络结构的模型集成起来,减少过拟合的风险。而在测试时,应该用整个训练好的模型,因此不需要dropout。
如何平衡训练和测试时的差异呢?在训练时以一定的概率使神经元失活,实际上就是让对应神经元的输出为0。假设失活概率为 p ,就是这一层中的每个神经元都有p的概率失活,如下图的三层网络结构中,如果失活概率为0.5,则平均每一次训练有3个神经元失活,所以输出层每个神经元只有3个输入,而实际测试时是不会有dropout的,输出层每个神经元都有6个输入,这样在训练和测试时,输出层每个神经元的输入和的期望会有量级上的差异。因此在训练时还要对第二层的输出数据除以(1-p)之后再传给输出层神经元,作为神经元失活的补偿,以使得在训练时和测试时每一层输入有大致相同的期望。
这里我回答错误了,因为我回答成了是在测试的时候,对输出数据乘上p保证训练和输出有大致的期望。其实是在训练的时候除以(1-p)作为补偿,而测试阶段不做处理,相当于去掉dropout层
12 算法题:数组的回文遍历
参考答案:略
- END -往期精彩回顾
获取一折本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/662nyZF
本站qq群1003271085。
加入微信群请扫码进群(如果是博士或者准备读博士请说明):