
图像增强领域大突破!以1.66ms的速度处理4K图像,港理工提出图像自适应的3DLUT

极市导读
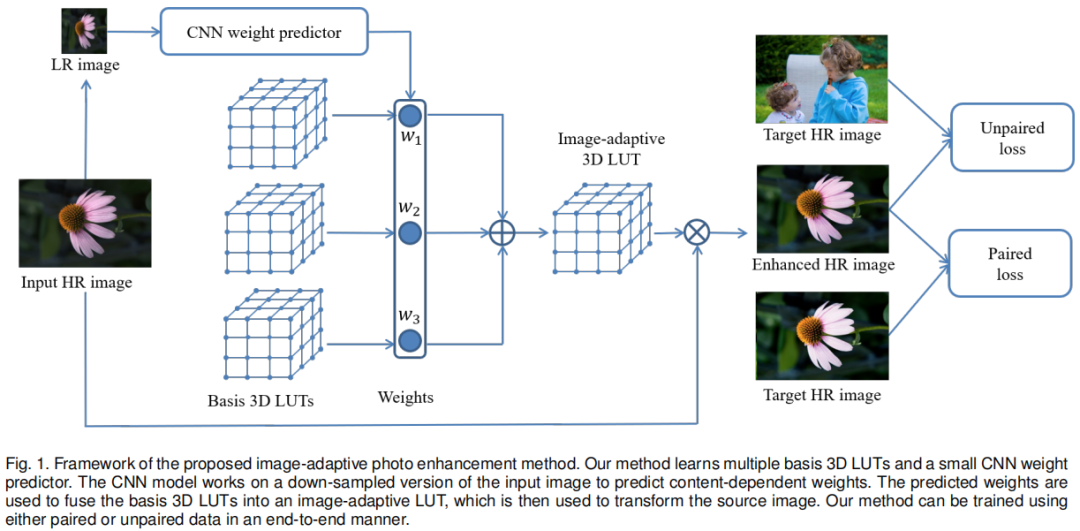
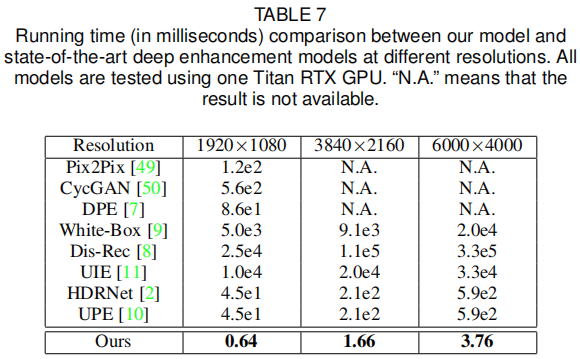
该文是香港理工大学张磊老师及其学生在图像增强领域的又一颠覆性成果。它将深度学习技术与传统3DLUT图像增强技术结合,得到了一种更灵活、更高效的图像增强技术。所提方法能够以1.66ms的速度对4K分辨率图像进行增强(硬件平台:Titan RTX GPU)。

Abstract
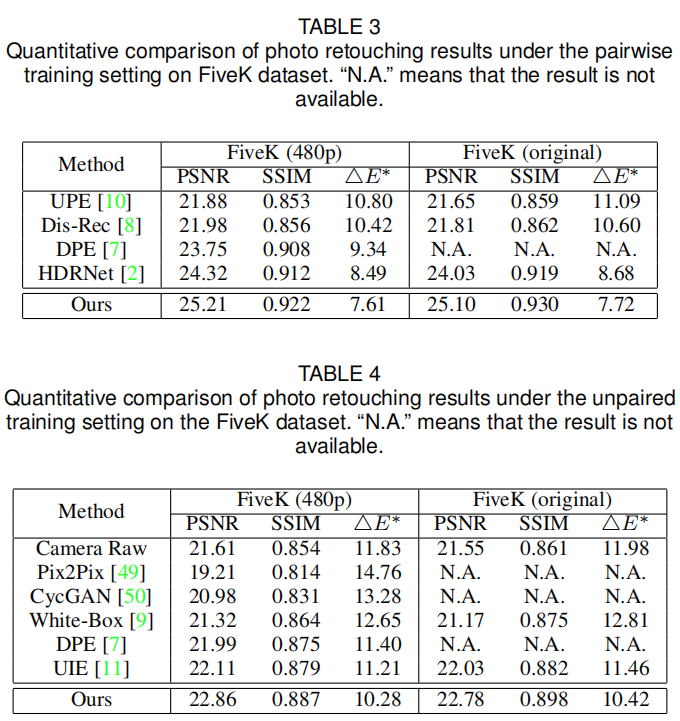
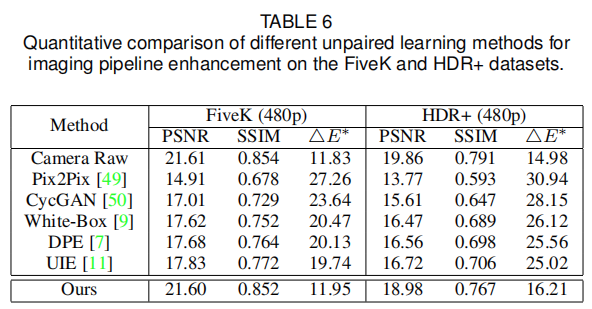
首个采用深度学习方法学习3DLUT并用于自动图像增强的方案,更重要的是,所提方法学习到的3DLUT具有图像自适应性,可以更灵活的进行图像增强; 所提方法仅有不超过600K参数量,且能够以不超过2ms的速度处理4K分辨率图像(GPU); 在两个公开数据集上以极大优势超越其他SOTA图像增强方案。
Method
3DLUT and trilinear interpolation
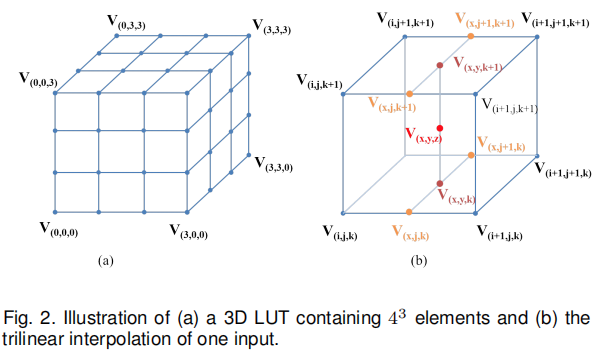
lookup与trilinear interpolation。给定输入RGB颜色,lookup操作可以通过如下公式进行:trilinear interpolation并得到输出RGB。trilinear interpolation可以描述如下:假设,,那么三次插值公式如下:Learning image-adaptive 3D LUTs
Learning Criteria
Regularization

Smooth Regularization。为了稳定的将输入RGB变换到期望的颜色空间,而不引入伪影,3DLUT的输出RGB应当具有局部平滑性。全变差 Total Variation, TV是图像复原领域经典的平滑正则化技术,作者将其引入到3DLUT,此时TV正则定义如下:
Monotonicity regularization。除了平滑性外,单调性也适合3DLUT应当具有的一个属性。为此作者设计了如下的单调正则项:
Final training losses and implementation
trilinear interpolation通过CUDA并行实现。训练的优化器为Adam,Batch=1,学习率固定0.0001(pair)和0.0002(unpair),随机裁剪、随机镜像等数据增强。而这N个3DLUT的初始化方式为:第一个为恒等映射,其他则初始化为0。CNN的全连接层的bias初始化为1,确保起始阶段的权值预测为1。Experiments



推荐阅读
图像超分最新记录!南洋理工提出图神经网络嵌入新思路,复原效果惊艳
计算高效,时序一致,超清还原!清华&NYU 提出 RRN:视频超分新型递归网络
NTIRE2020冠军方案RFB-ESRGAN:带感受野模块的超分网络

评论