爬虫解析利器PyQuery详解及使用实践
↑ 关注 + 星标 ,每天学Python新技能
后台回复【大礼包】送你Python自学大礼包
作者:叶庭云
整理:Lemon
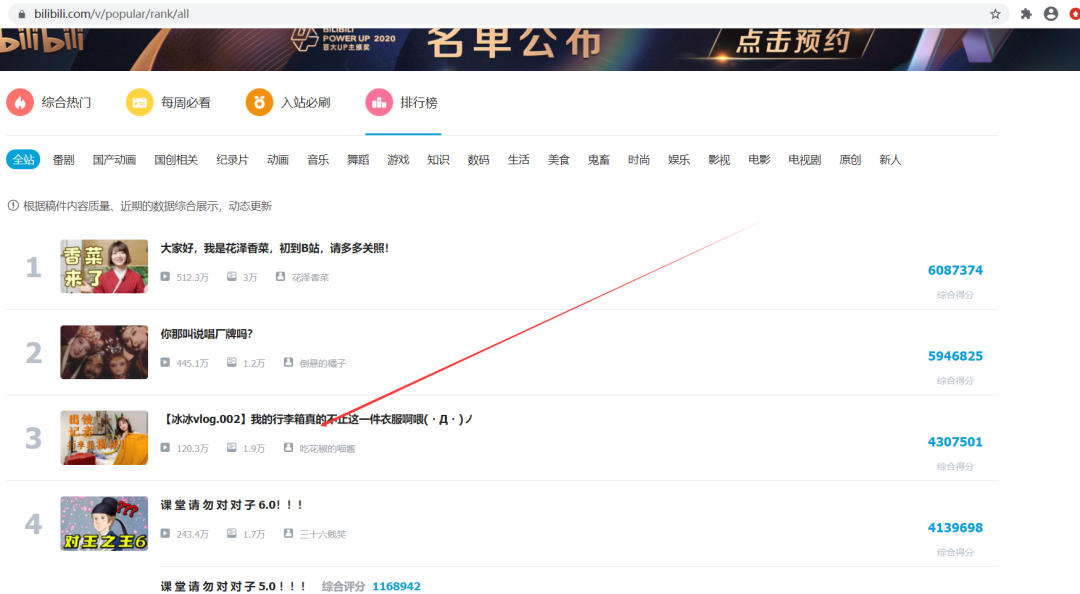
爬虫解析利器
PyQuery详解及使用实践
之前跟大家分享了 selenium、Scrapy、Pyppeteer 等工具的使用。
今天来分享另一个好用的爬虫解析工具 PyQuery。
一、简介
每个网页,都有一定的特殊结构和层级关系,而且很多节点都有 id 或 class 作为区分,我们可以借助它们的结构和属性来提取信息。
PyQuery 是一个强大的 HTML 解析库,利用它,我们可以直接解析 DOM 节点的结构,并通过 DOM 节点的一些属性快速进行内容提取。
pyquery 是 Python 的第三方库,可以用 pip3 来安装,安装命令如下:
pip3 install pyquery -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
在解析 HTML 文本的时候,首先需要将其初始化为一个 pyquery 对象。它的初始化方式有多种,比如直接传入字符串、传入 URL、传入文件名等等。
字符串初始化
可以直接把 HTML 的内容当作参数来初始化 pyquery 对象,下面用一个实例来感受一下:
from pyquery import PyQuery as pq
html = '''
first item
second item
'''
doc = pq(html)
print(doc('li'))
运行结果如下:
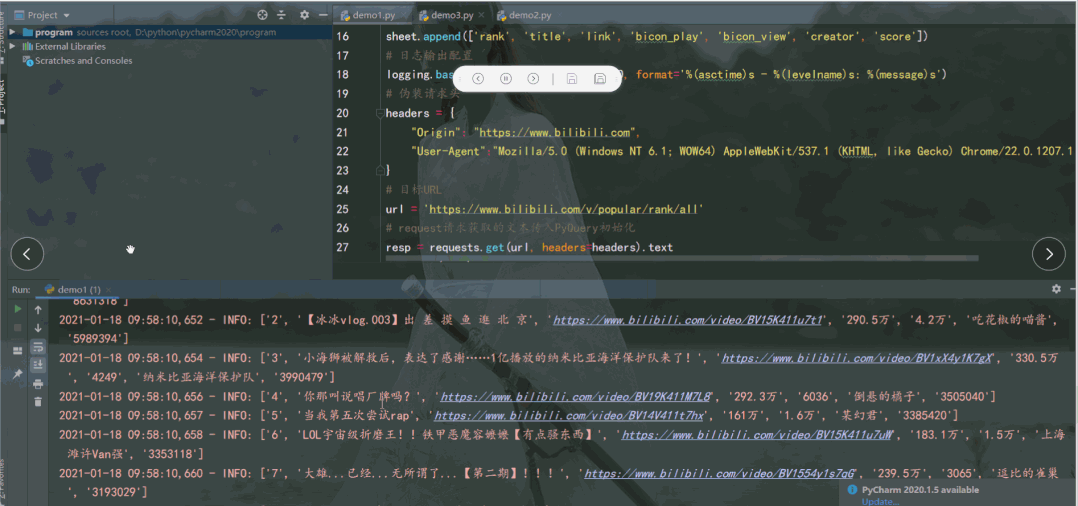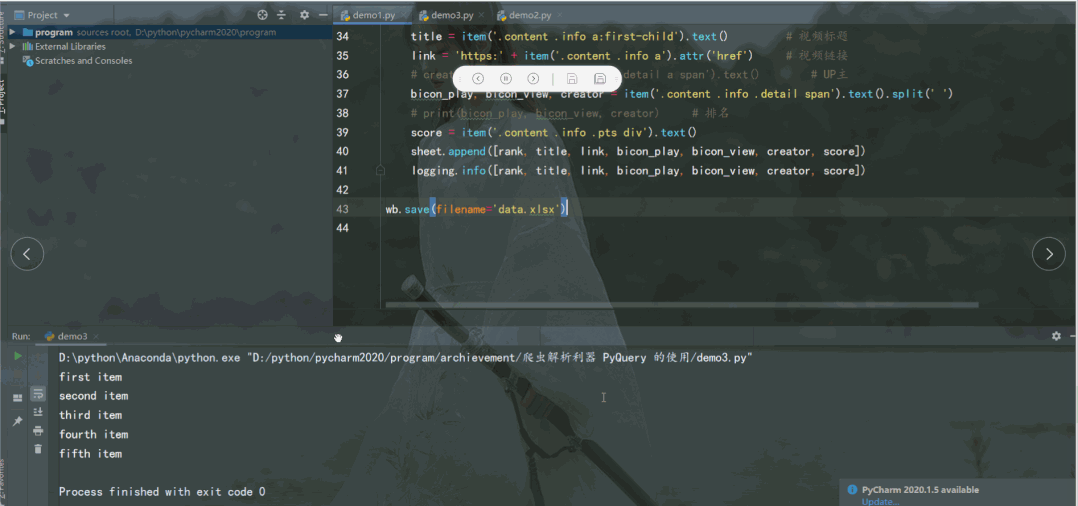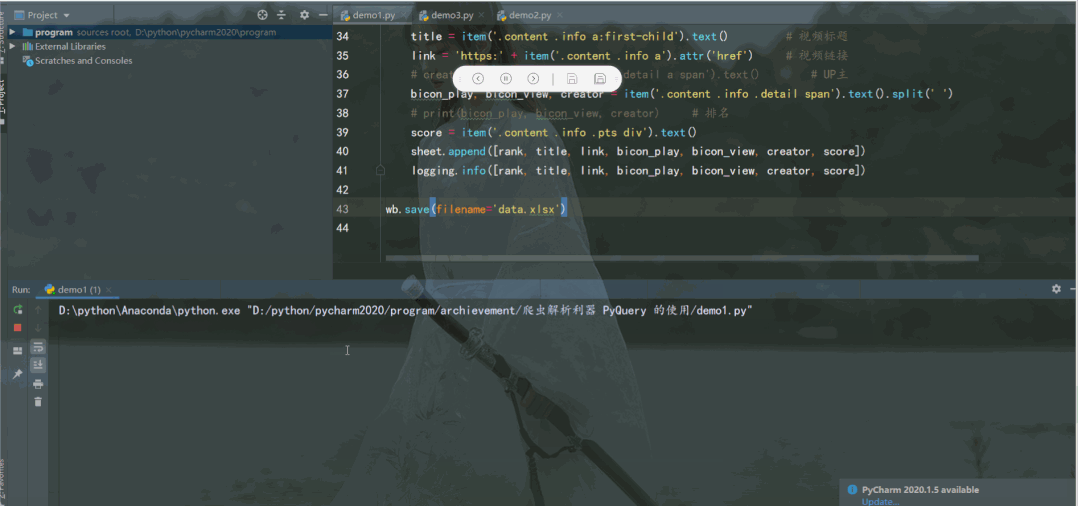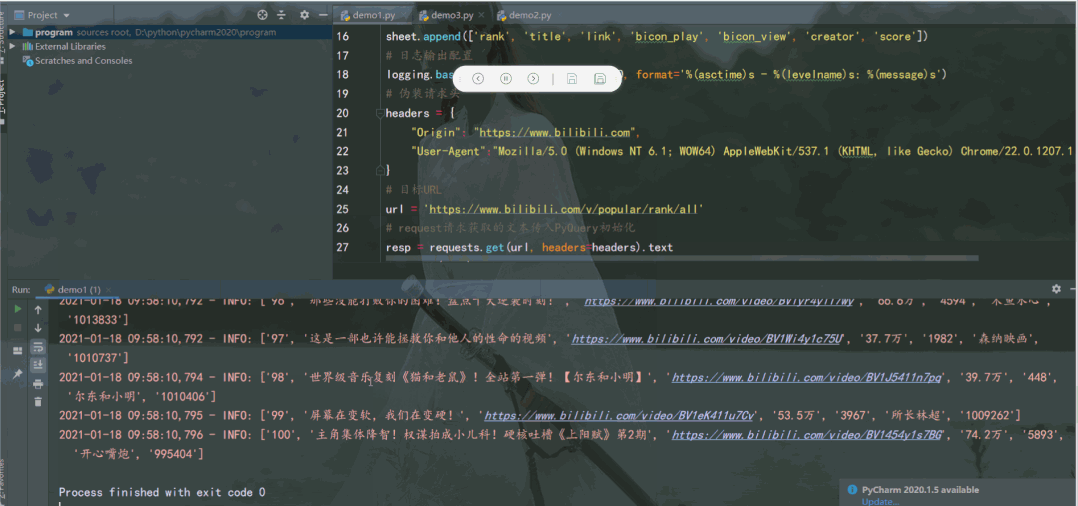
class="item-0">first itemli>
<li class="item-1"><a href="link2.html">second itema>li>
<li><img src="http://pic.netbian.com/uploads/allimg/210107/215736-1610027856f6ef.jpg"/>
190902 /152344-1567409024af8c.jpg"/>
首先引入 pyquery 这个对象,取别名为 pq,然后定义了一个长 HTML 字符串,并将其当作参数传递给 pyquery 类,这样就成功完成了初始化。
接下来,将初始化的对象传入 CSS 选择器。在这个实例中,我们传入 li 节点,这样就可以选择所有的 li 节点。
URL 初始化
# -*- coding: UTF-8 -*-
from pyquery import PyQuery as pq
url = 'https://yetingyun.blog.csdn.net/'
doc = pq(url)
print(doc('title'))
运行结果如下:
叶庭云的博客_CSDN博客-python 爬虫,python数据可视化,计算机视觉图像处理领域博主
pyquery 对象会首先请求这个 URL,然后用得到的 HTML 内容完成初始化。这就相当于将网页的源代码以字符串的形式传递给 pyquery 类来初始化。
文件初始化
除了传递一个 URL,我们还可以传递本地的文件名,参数指定为 filename 即可:
from pyquery import PyQuery as pq
doc = pq(filename='时间轮播图.html')
print(doc('title'))
运行结果如下:
Awesome-pyecharts
当然,这里需要有一个本地 HTML 文件,其内容是待解析的 HTML 字符串。这样它会先读取本地的文件内容,然后将文件内容以字符串的形式传递给 pyquery 类来初始化。
以上 3 种方式均可初始化,当然最常用的初始化方式还是以字符串形式传递。
二、pyquery基本使用
基本 CSS 选择器
用一个实例来感受一下 pyquery 的 css 选择器的用法:
from pyquery import PyQuery as pq
html = '''
first item
second item
third item
fourth item
fifth item
'''
doc = pq(html)
print(doc('#container .list li'))
print(type(doc('#container .list li')))
运行结果如下:
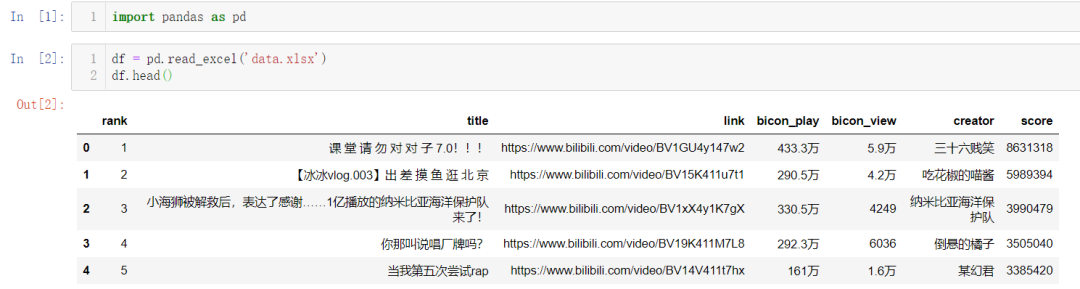
class="item-0">first itemli>
<li class="item-1"><a href="link2.html">second itema>li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third itemspan>a>li>
<li class="item-1 active"><a href="link4.html">fourth itema>li>
<li class="item-0"><a href="link5.html">fifth itema>li>
<class 'pyquery.pyquery.PyQuery'>
初始化 pyquery 对象之后,传入 css 选择器 #container .list li,它的意思是先选取 id 为 container 的节点,然后再选取其内部 class 为 list 的所有 li 节点,最后打印输出。
可以看到,我们成功获取到了符合条件的节点。我们将它的类型打印输出后发现,它的类型依然是 pyquery 类型。
下面,我们直接遍历这些节点,然后调用 text 方法,就可以获取节点的文本内容
from pyquery import PyQuery as pq
html = '''
first item
second item
third item
fourth item
fifth item
'''
doc = pq(html)
for item in doc('#container .list li').items():
print(item.text())
运行结果如下:
first item
second item
third item
fourth item
fifth item
而是直接通过选择器和 text 方法,就得到了我们想要提取的文本信息,是不是挺方便的?
获取信息
提取到节点之后,我们的最终目的当然是提取节点所包含的信息了。比较重要的信息有两类,一是获取属性,二是获取文本,下面分别进行说明。
获取属性:提取到某个 pyquery 类型的节点后,可以调用 attr 方法来获取属性:
from pyquery import PyQuery as pq
html = '''
first item
second item
third item
fourth item
fifth item
'''
doc = pq(html)
a = doc('.item-0.active a')
print(a, type(a))
print(a.attr('href'))
print(a.attr.href)
运行结果如下:
"link3.html">class="bold">third itemspan>a> <class 'pyquery.pyquery.PyQuery'>
link3.html
link3.html
在这个例子中我们首先选中 class 为 item-0 和 active 的 li 节点内的 a 节点,它的类型是 pyquery 类型。然后调用 attr 方法。在这个方法中传入属性的名称,就可以得到属性值了。此外,也可以通过调用 attr 属性来获取属性值。
遍历获取所有的 a 节点的属性:
from pyquery import PyQuery as pq
html = '''
first item
second item
third item
fourth item
fifth item