
爬虫神器之 PyQuery 实用教程(一)
咪哥杂谈

本篇阅读时间约为 4 分钟。接下来的教程,短小而精悍。
1
前言
最近在研究 PySpider 框架,一个国人写的好用框架,其中在提取网页节点元素的时候,可以利用 PyQuery 来高效使用。
今天就来的介绍下关于 PyQuery 的一些实用方法。
2
安装及详情介绍
开始之前,先要安装下第三方库。
pip install pyquery来看下官方定义:
pyquery allows you to make jquery queries on xml documents. The API is as much as possible the similar to jquery. pyquery uses lxml for fast xml and html manipulation.
PyQuery官方文档
大致意思:PyQuery 允许你在 xml 文档结构去进行 jQuery 的语法查询。它的 api 使用方法与 jQuery 相似度很高。
看完官网后,再结合名字,但凡是接触过前端的同学,一定可以联想到jQuery,这里在普及下 jQuery。
jQuery是一个快速、简洁的JavaScript框架。它的本身语法可以非常简洁的提取到 HTML 元素的节点。
而 PyQuery 则是 Python 仿照 jQuery 来实现的。熟悉 jQuery 的同学,再去学习 PyQuery 简直 so easy。
3
实战环境准备
废话不多说,直接开始搞实战。
刚经历七天小长假,就以"穷游网"为例,来用它讲解下 PyQuery 如何获取页面的元素节点。
打开穷游网,随便选了个地点,以"日本"为例。
https://place.qyer.com/japan/citylist-0-0-1/
穷游网
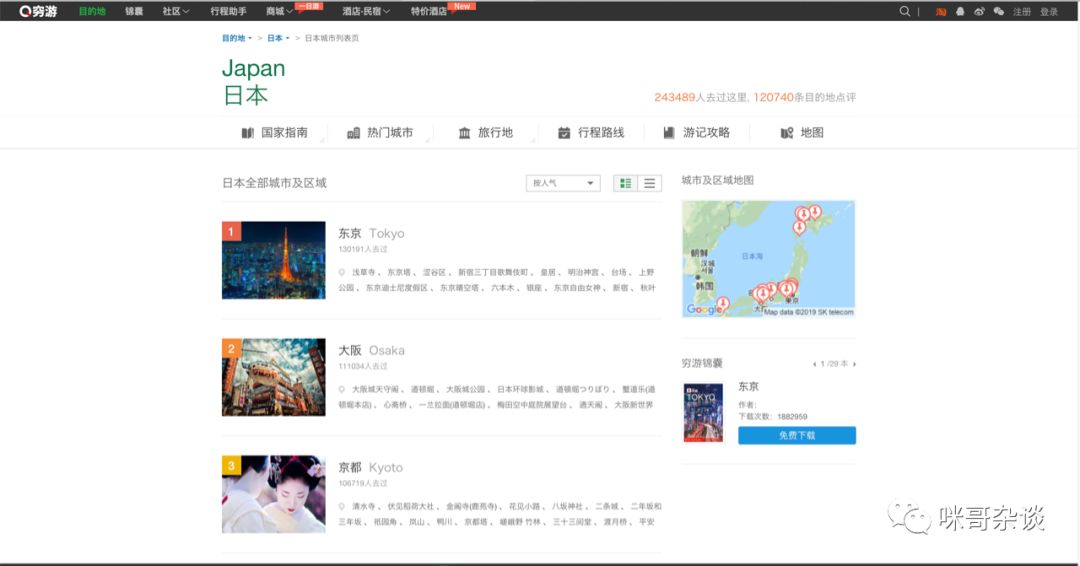
可以看到上图中,列出了日本全部城市以及区域。爬它!
4
PyQuery获取原网页代码
PyQuery 内置提供了一个方法,可以直接对网页进行模拟请求。
from pyquery import PyQuery as pqdoc = pq(url='https://place.qyer.com/japan/citylist-0-0-1/')
导入 PyQuery 并且命名为 pq。为了命名简短,所以调用使用 pq 来操作。当参数指定为 url 时,pq 底层封装了请求网址的动作。
doc = pq(url='https://place.qyer.com/japan/citylist-0-0-1/')上述代码的底层执行机制,类似于这样:
url = 'https://place.qyer.com/japan/citylist-0-0-1/'doc = pq(requests.get(url).text)
让我们来改写代码打印下,看看 doc 得到的内容,以及它的类型是什么:
from pyquery import PyQuery as pqdef spider_travel():doc = pq(url='https://place.qyer.com/japan/citylist-0-0-1/')print(doc)print(type(doc))spider_travel()
结果:
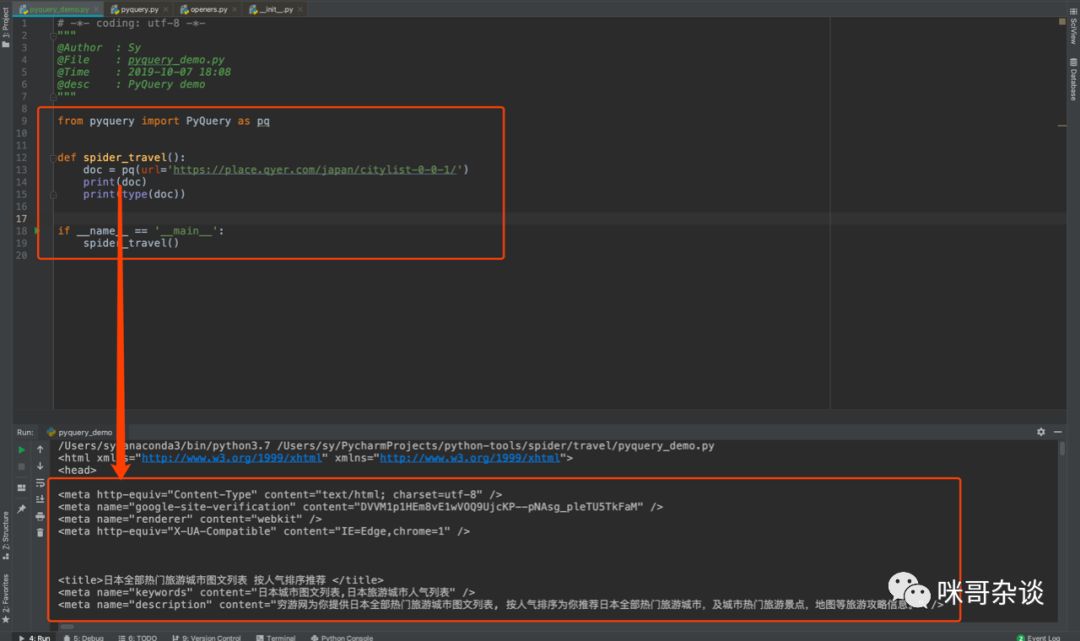
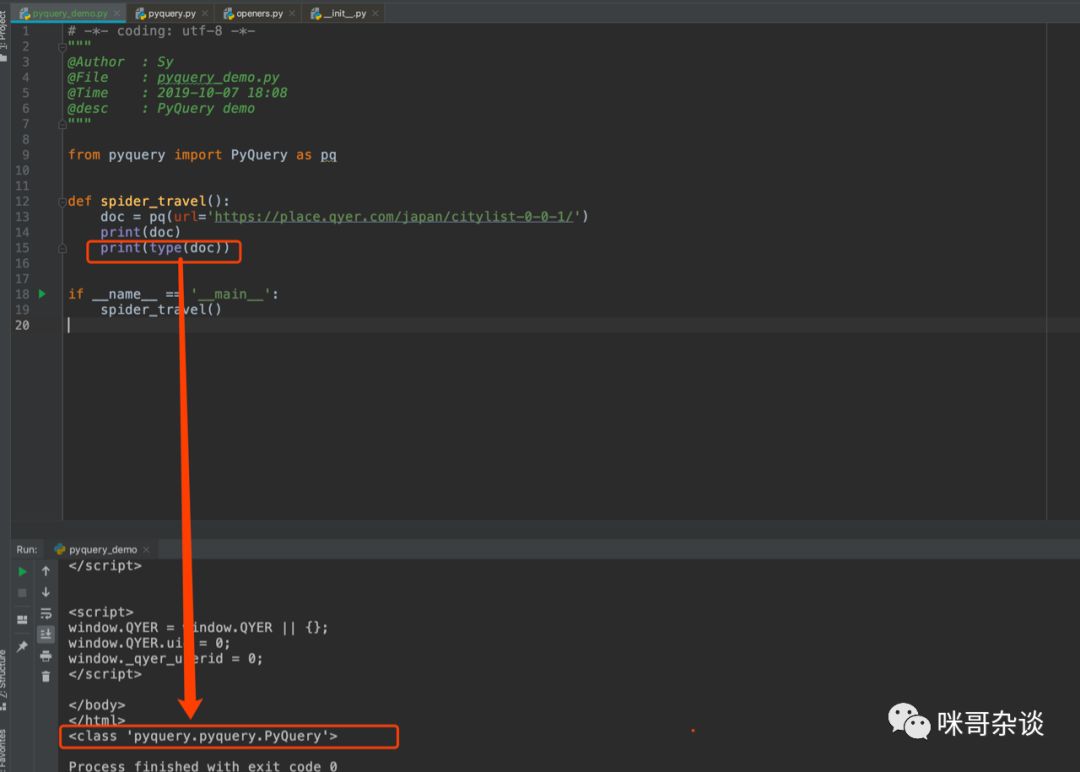
doc打印的结果,大家可以看到,是将 HTML 源代码以文本的形式返回了。而 doc 的类型,则是 PyQuery 。
后续想从 HTML 源码中提取我们想要的内容,都需要此类来进行操作。也就是通过 doc 变量来进行操作,提取。
5
总结
好了,简单的回顾下。
上面介绍了 PyQuery 库的用途以及如何对一个网站发起请求,以及它最重要的类。下一篇重点介绍如何提取元素节点。
本篇文章就到这里!是不是很简短。毕竟现在大家阅读的时间越来越少了,而真正能看进去文章的也越来越少。所以将长篇大论的文章,分隔缩短,分成好几篇来介绍!你觉得这样是否合适呢?
Python玩转高德地图API(一)
 你点的每个在看,我都认真当成了喜欢
你点的每个在看,我都认真当成了喜欢