
深入GPU硬件架构及运行机制(下)


一、导言
二、GPU概述
三、GPU物理架构
四、GPU运行机制
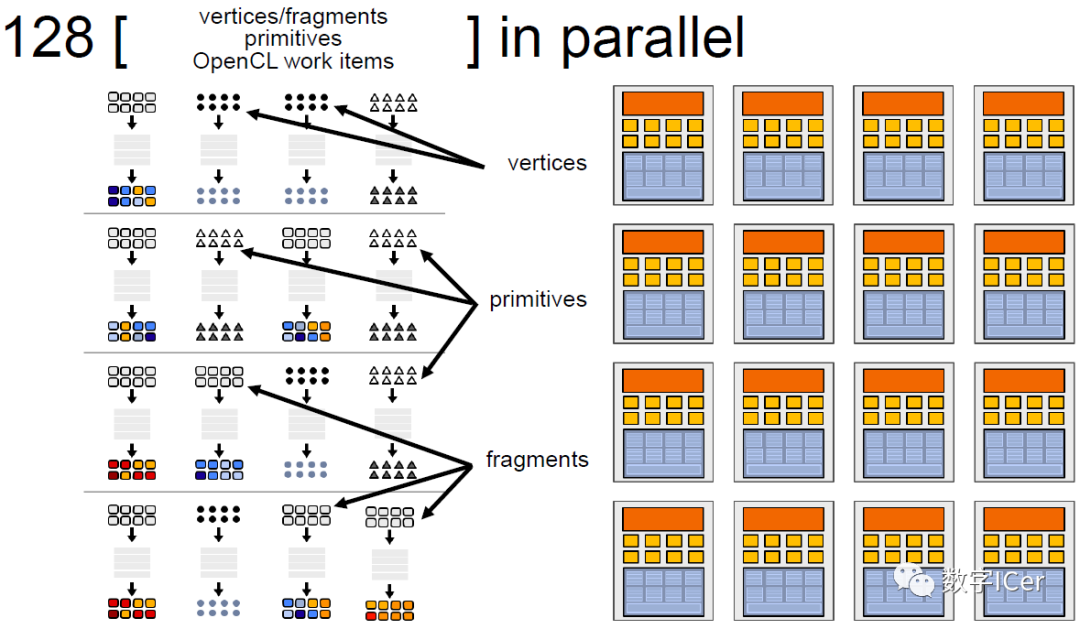
4.1 GPU渲染总览
4.2 GPU逻辑管线
4.3 GPU技术要点
4.4 GPU资源机制
4.4.1 内存架构
4.4.2 GPU Context和延迟
4.4.3 CPU-GPU异构系统
4.4.4 GPU资源管理模型
4.4.5 CPU-GPU数据流
4.4.6 显像机制
4.5 Shader运行机制
4.6 利用扩展例证
五、总结
5.1 CPU vs GPU
5.2 渲染优化建议
5.3 GPU的未来
5.4 结语
参考文献
特别说明
上篇:深入GPU硬件架构及运行机制(上)
4.4 GPU资源机制
4.4.1 内存架构

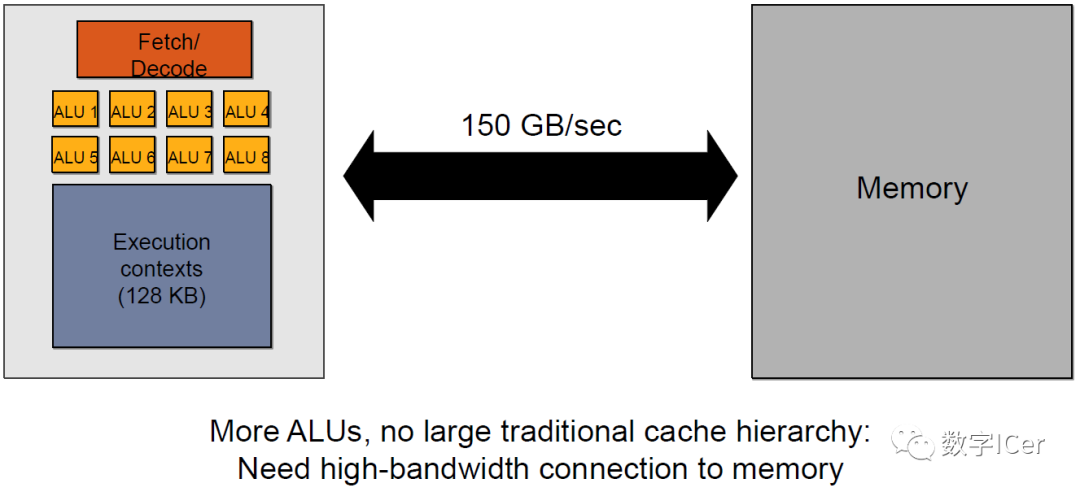
4.4.2 GPU Context和延迟
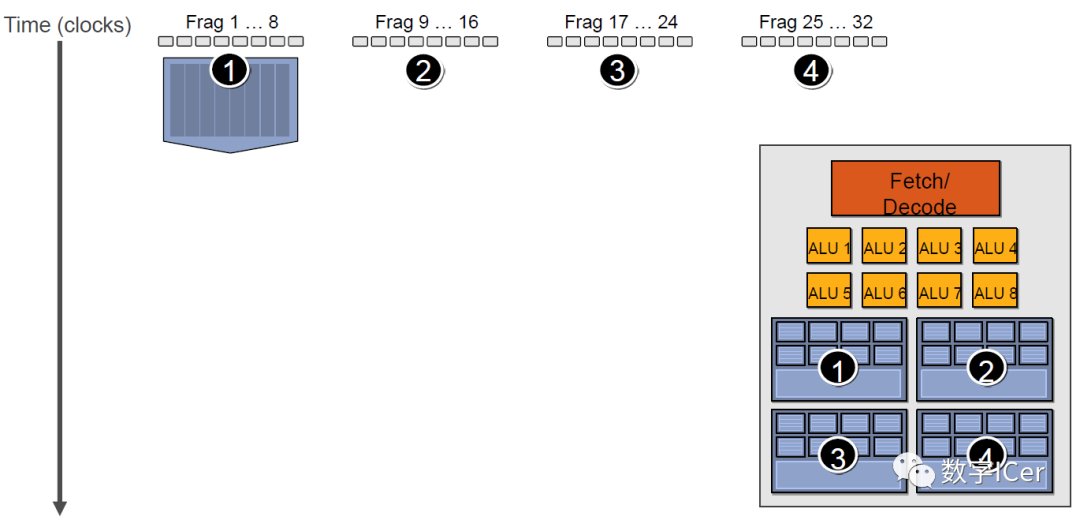

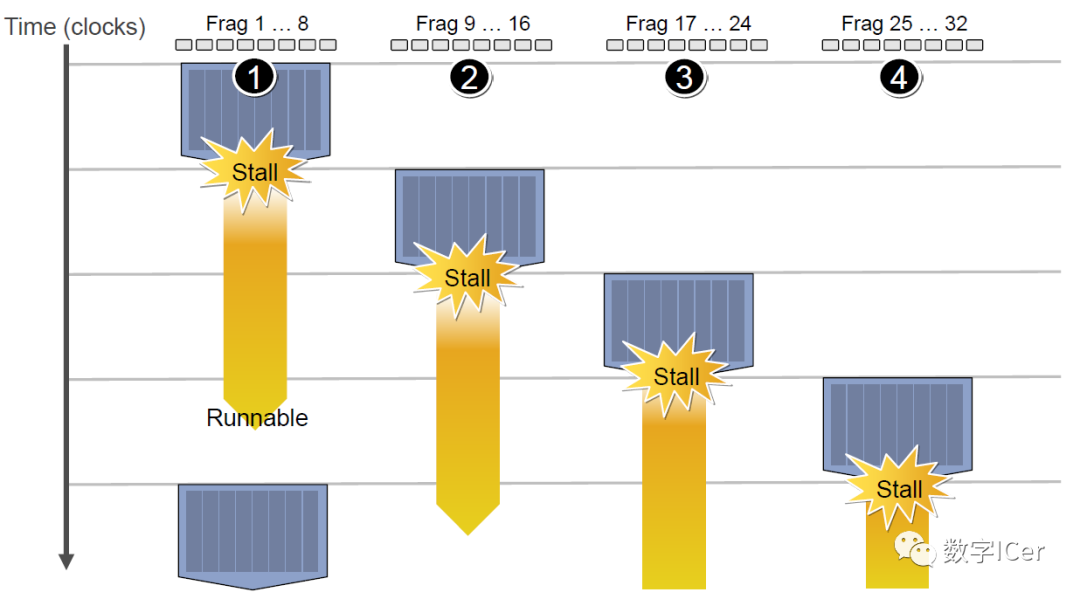
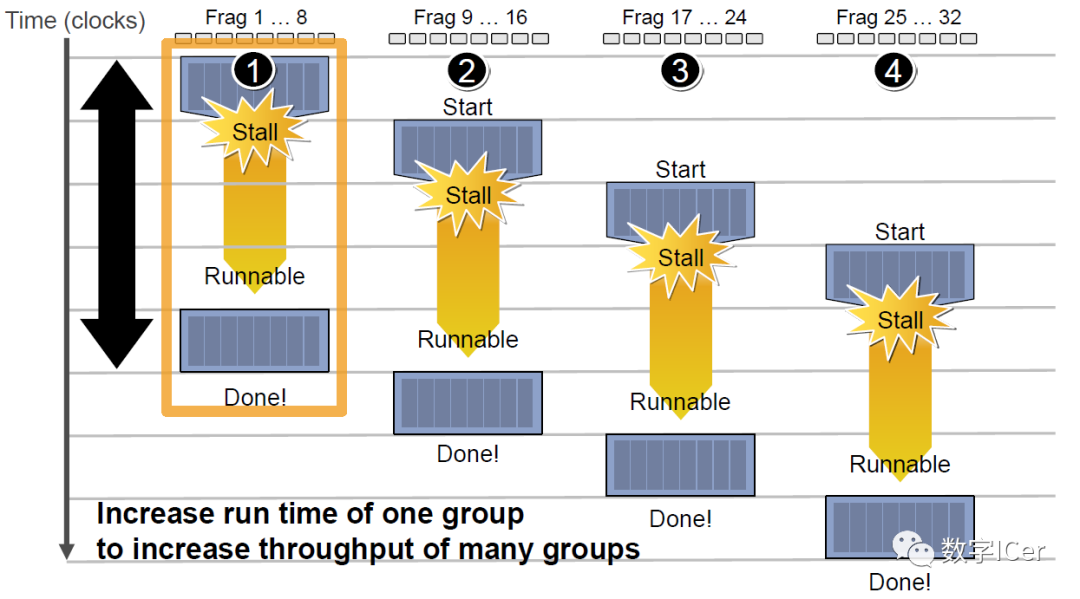
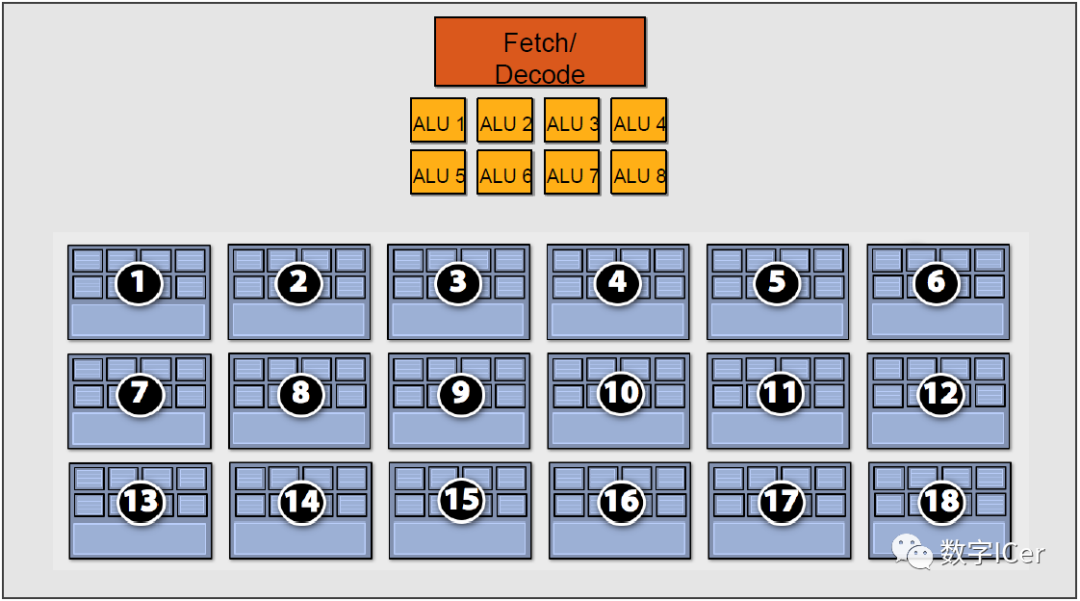
4.4.3 CPU-GPU异构系统
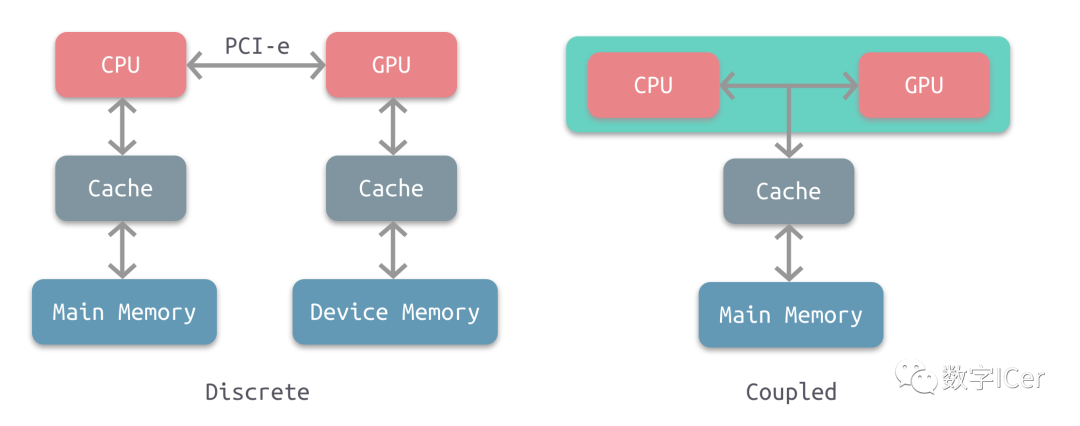
4.4.4 GPU资源管理模型
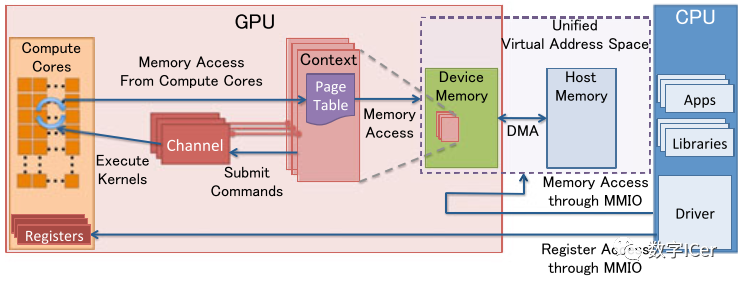
MMIO(Memory Mapped IO) CPU与GPU的交流就是通过MMIO进行的。CPU 通过 MMIO 访问 GPU 的寄存器状态。 DMA传输大量的数据就是通过MMIO进行命令控制的。 I/O端口可用于间接访问MMIO区域,像Nouveau等开源软件从来不访问它。 GPU Context GPU Context代表了GPU计算的状态。 在GPU中拥有自己的虚拟地址。 GPU 中可以并存多个活跃态下的Context。 GPU Channel 任何命令都是由CPU发出。 命令流(command stream)被提交到硬件单元,也就是GPU Channel。 每个GPU Channel关联一个context,而一个GPU Context可以有多个GPU channel。 每个GPU Context 包含相关channel的 GPU Channel Descriptors , 每个 Descriptor 都是 GPU 内存中的一个对象。 每个 GPU Channel Descriptor 存储了 Channel 的设置,其中就包括 Page Table 。 每个 GPU Channel 在GPU内存中分配了唯一的命令缓存,这通过MMIO对CPU可见。 GPU Context Switching 和命令执行都在GPU硬件内部调度。 GPU Page Table GPU Context在虚拟基地空间由Page Table隔离其它的Context 。 GPU Page Table隔离CPU Page Table,位于GPU内存中。 GPU Page Table的物理地址位于 GPU Channel Descriptor中。 GPU Page Table不仅仅将 GPU虚拟地址转换成GPU内存的物理地址,也可以转换成CPU的物理地址。因此,GPU Page Table可以将GPU虚拟地址和CPU内存地址统一到GPU统一虚拟地址空间来。 PCI-e BAR GPU 设备通过PCI-e总线接入到主机上。Base Address Registers(BARs) 是 MMIO的窗口,在GPU启动时候配置。 GPU的控制寄存器和内存都映射到了BARs中。 GPU设备内存通过映射的MMIO窗口去配置GPU和访问GPU内存。 PFIFO Engine PFIFO是GPU命令提交通过的一个特殊的部件。 PFIFO维护了一些独立命令队列,也就是Channel。 此命令队列是Ring Buffer,有PUT和GET的指针。 所有访问Channel控制区域的执行指令都被PFIFO 拦截下来。 GPU驱动使用Channel Descriptor来存储相关的Channel设定。 PFIFO将读取的命令转交给PGRAPH Engine。 BO Buffer Object (BO),内存的一块(Block),能够用于存储纹理(Texture)、渲染目标(Render Target)、着色代码(shader code)等等。 Nouveau和Gdev经常使用BO。 Nouveau是一个自由及开放源代码显卡驱动程序,是为NVidia的显卡所编写。 Gdev是一套丰富的开源软件,用于NVIDIA的GPGPU技术,包括设备驱动程序。
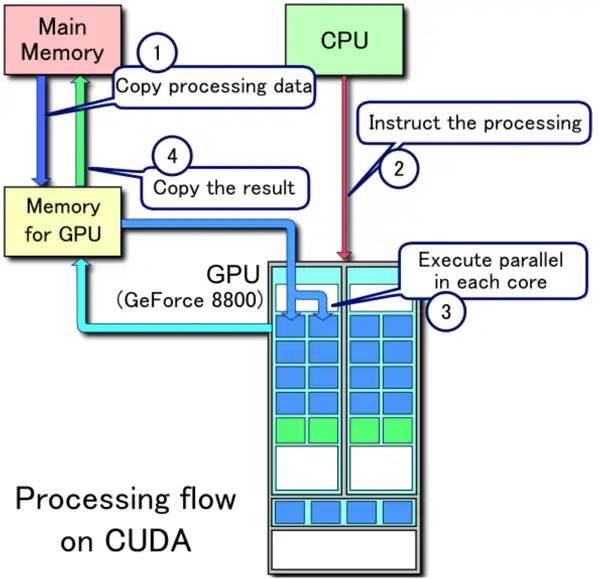
4.4.5 CPU-GPU数据流
4.4.6 显像机制
水平和垂直同步信号 在早期的CRT显示器,电子枪从上到下逐行扫描,扫描完成后显示器就呈现一帧画面。然后电子枪回到初始位置进行下一次扫描。为了同步显示器的显示过程和系统的视频控制器,显示器会用硬件时钟产生一系列的定时信号。 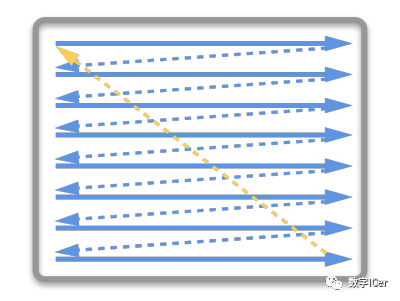
当电子枪换行进行扫描时,显示器会发出一个水平同步信号(horizonal synchronization),简称 HSync 当一帧画面绘制完成后,电子枪回复到原位,准备画下一帧前,显示器会发出一个垂直同步信号(vertical synchronization),简称 VSync。 显示器通常以固定频率进行刷新,这个刷新率就是 VSync 信号产生的频率。虽然现在的显示器基本都是液晶显示屏了,但其原理基本一致。 CPU将计算好显示内容提交至 GPU,GPU 渲染完成后将渲染结果存入帧缓冲区,视频控制器会按照 VSync 信号逐帧读取帧缓冲区的数据,经过数据转换后最终由显示器进行显示。 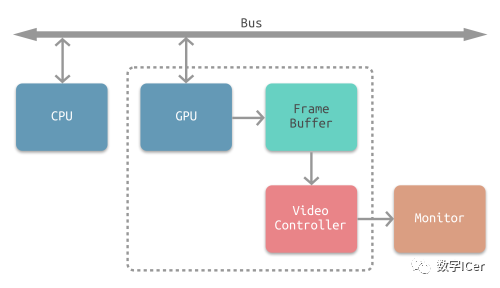
双缓冲 在单缓冲下,帧缓冲区的读取和刷新都都会有比较大的效率问题,经常会出现相互等待的情况,导致帧率下降。 为了解决效率问题,GPU 通常会引入两个缓冲区,即 双缓冲机制。在这种情况下,GPU 会预先渲染一帧放入一个缓冲区中,用于视频控制器的读取。当下一帧渲染完毕后,GPU 会直接把视频控制器的指针指向第二个缓冲器。 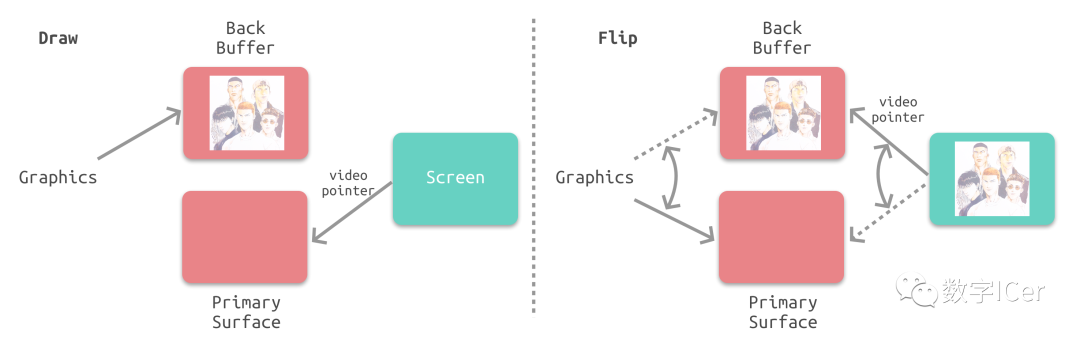
垂直同步 双缓冲虽然能解决效率问题,但会引入一个新的问题。当视频控制器还未读取完成时,即屏幕内容刚显示一半时,GPU 将新的一帧内容提交到帧缓冲区并把两个缓冲区进行交换后,视频控制器就会把新的一帧数据的下半段显示到屏幕上,造成画面撕裂现象: 
为了解决这个问题,GPU 通常有一个机制叫做垂直同步(简写也是V-Sync),当开启垂直同步后,GPU 会等待显示器的 VSync 信号发出后,才进行新的一帧渲染和缓冲区更新。这样能解决画面撕裂现象,也增加了画面流畅度,但需要消费更多的计算资源,也会带来部分延迟。
4.5 Shader运行机制


sampler mySamp;
Texture2D<float3> myTex;
float3 lightDir;
float4 diffuseShader(float3 norm, float2 uv)
{
float3 kd;
kd = myTex.Sample(mySamp, uv);
kd *= clamp( dot(lightDir, norm), 0.0, 1.0);
return float4(kd, 1.0);
}
<diffuseShader>:
sample r0, v4, t0, s0
mul r3, v0, cb0[0]
madd r3, v1, cb0[1], r3
madd r3, v2, cb0[2], r3
clmp r3, r3, l(0.0), l(1.0)
mul o0, r0, r3
mul o1, r1, r3
mul o2, r2, r3
mov o3, l(1.0)


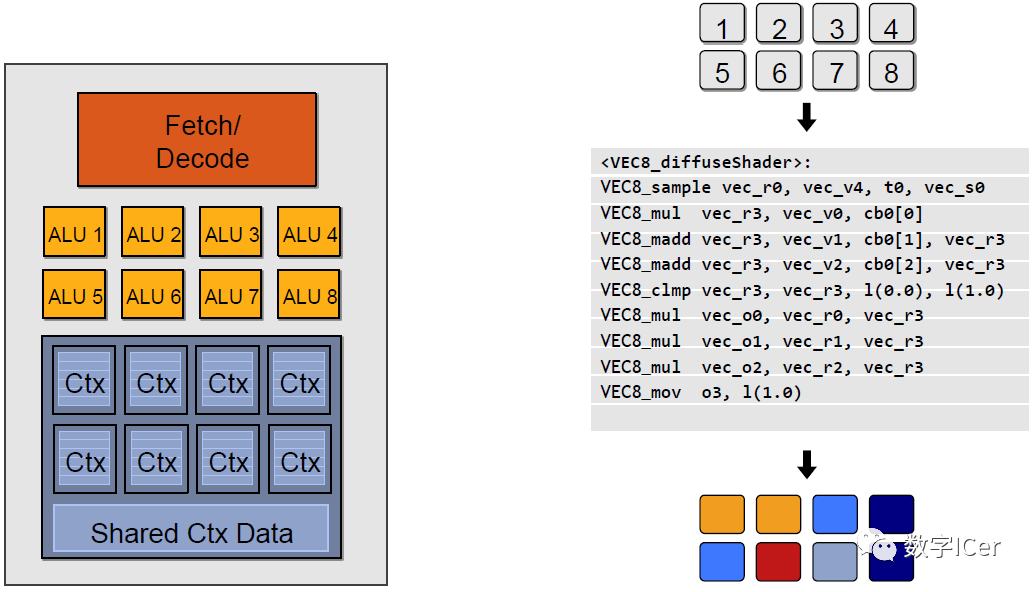
<VEC8_diffuseShader>:
VEC8_sample vec_r0, vec_v4, t0, vec_s0
VEC8_mul vec_r3, vec_v0, cb0[0]
VEC8_madd vec_r3, vec_v1, cb0[1], vec_r3
VEC8_madd vec_r3, vec_v2, cb0[2], vec_r3
VEC8_clmp vec_r3, vec_r3, l(0.0), l(1.0)
VEC8_mul vec_o0, vec_r0, vec_r3
VEC8_mul vec_o1, vec_r1, vec_r3
VEC8_mul vec_o2, vec_r2, vec_r3
VEC8_mov o3, l(1.0)
4.6 利用扩展例证
OpenGL 4.3+; GLSL 4.3+; 支持OpenGL 4.3+的NV显卡;
This extension interacts with NV_gpu_program5
This extension interacts with NV_compute_program5
This extension interacts with NV_tessellation_program5
// 开启扩展
#extension GL_NV_shader_thread_group : require (or enable)
WARP_SIZE_NV // 单个线程束的线程数量
WARPS_PER_SM_NV // 单个SM的线程束数量
SM_COUNT_NV // SM数量
uniform uint gl_WarpSizeNV; // 单个线程束的线程数量
uniform uint gl_WarpsPerSMNV; // 单个SM的线程束数量
uniform uint gl_SMCountNV; // SM数量
in uint gl_WarpIDNV; // 当前线程束id
in uint gl_SMIDNV; // 当前线程束所在的SM id,取值[0, gl_SMCountNV-1]
in uint gl_ThreadInWarpNV; // 当前线程id,取值[0, gl_WarpSizeNV-1]
in uint gl_ThreadEqMaskNV; // 是否等于当前线程id的位域掩码。
in uint gl_ThreadGeMaskNV; // 是否大于等于当前线程id的位域掩码。
in uint gl_ThreadGtMaskNV; // 是否大于当前线程id的位域掩码。
in uint gl_ThreadLeMaskNV; // 是否小于等于当前线程id的位域掩码。
in uint gl_ThreadLtMaskNV; // 是否小于当前线程id的位域掩码。
in bool gl_HelperThreadNV; // 当前线程是否协助型线程。
gl_HelperThreadNV是指在处理2x2的像素块时,那些未被图元覆盖的像素着色器线程将被标记为gl_HelperThreadNV = true,它们的结果将被忽略,也不会被存储,但可辅助一些计算,如导数dFdx和dFdy。为了防止理解有误,贴出原文:The variable gl_HelperThreadNV specifies if the current thread is a helper thread. In implementations supporting this extension, fragment shader invocations may be arranged in SIMD thread groups of 2x2 fragments called "quad". When a fragment shader instruction is executed on a quad, it\\\'s possible that some fragments within the quad will execute the instruction even if they are not covered by the primitive. Those threads are called helper threads. Their outputs will be discarded and they will not execute global store functions, but the intermediate values they compute can still be used by thread group sharing functions or by fragment derivative functions like dFdx and dFdy.
操作系统:Windows 10 Pro, 64-bit DirectX 版本:12.0
GPU 处理器:GeForce RTX 2060
驱动程序版本:417.71
Driver Type: Standard
Direct3D API 版本:12
Direct3D 功能级别:12_1CUDA 核心:1920
核心时钟:1710 MHz
内存数据速率:14.00 Gbps
内存接口:192-位
内存带宽:336.05 GB/秒
全部可用的图形内存:22494MB
专用视频内存:6144 MB GDDR6
系统视频内存:0MB
共享系统内存:16350MB
视频 BIOS 版本:90.06.3F.00.73
IRQ:Not used
总线:PCI Express x16 Gen3
// set up vertex data (and buffer(s)) and configure vertex attributes
const float HalfSize = 1.0f;
float vertices[] = {
-HalfSize, -HalfSize, 0.0f, // left bottom
HalfSize, -HalfSize, 0.0f, // right bottom
-HalfSize, HalfSize, 0.0f, // top left
-HalfSize, HalfSize, 0.0f, // top left
HalfSize, -HalfSize, 0.0f, // right bottom
HalfSize, HalfSize, 0.0f, // top right
};
#version 430 core
layout (location = 0) in vec3 aPos;
void main()
{
gl_Position = vec4(aPos, 1.0f);
}
#version 430 core
out vec4 FragColor;
void main()
{
FragColor = vec4(1.0f, 0.5f, 0.2f, 1.0f);
}
#version 430 core
#extension GL_NV_shader_thread_group : require
uniform uint gl_WarpSizeNV; // 单个线程束的线程数量
uniform uint gl_WarpsPerSMNV; // 单个SM的线程束数量
uniform uint gl_SMCountNV; // SM数量
in uint gl_WarpIDNV; // 当前线程束id
in uint gl_SMIDNV; // 当前线程所在的SM id,取值[0, gl_SMCountNV-1]
in uint gl_ThreadInWarpNV; // 当前线程id,取值[0, gl_WarpSizeNV-1]
out vec4 FragColor;
void main()
{
// SM id
float lightness = gl_SMIDNV / gl_SMCountNV;
FragColor = vec4(lightness);
}
画面共有32个亮度色阶,也就是Geforce RTX 2060有32个SM。 单个SM每次渲染16x16为单位的像素块,也就是每个SM有256个Core。 SM之间不是顺序分配像素块,而是无序分配。 不同三角形的接缝处出现断层,说明同一个像素块如果分属不同的三角形,就会分配到不同的SM进行处理。由此推断,相同面积的区域,如果所属的三角形越多,就会导致分配给SM的次数越多,消耗的渲染性能也越多。
// warp id
float lightness = gl_WarpIDNV / gl_WarpsPerSMNV;
FragColor = vec4(lightness);
画面共有32个亮度色阶,也就是每个SM有32个Warp,每个Warp有8个Core。 每个色块像素是4x8,由于每个Warp有8个Core,由此推断每个Core单次要处理2x2的最小单元像素块。 也是无序分配像素块。 三角形接缝处出现断层,同SM的推断一致。
// thread id
float lightness = gl_ThreadInWarpNV / gl_WarpSizeNV;
FragColor = vec4(lightness);
相较SM、线程束,线程分布图比较规律。说明同一个Warp的线程分布是规律的。 三角形接缝处出现紊乱,说明是不同的Warp造成了不同的线程。 画面有32个色阶,说明单个Warp有32个线程。 每个像素独占一个亮度色阶,与周边相邻像素都不同,说明每个线程只处理一个像素。
五、总结
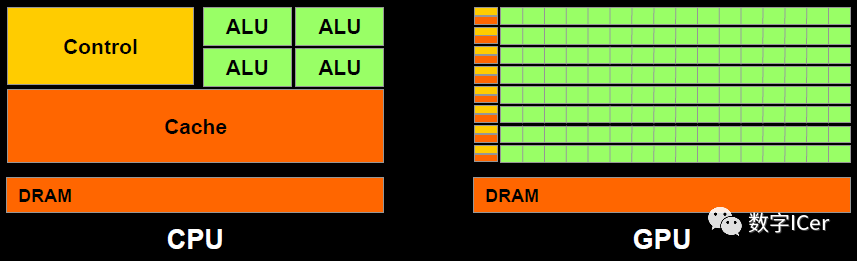
5.1 CPU vs GPU
5.2 渲染优化建议
减少CPU和GPU的数据交换: 例如: glGetUniformLocation会从GPU内存查询状态,耗费很多时间周期。避免每帧设置、查询渲染状态,可在初始化时缓存状态。 CPU版的粒子、动画会每帧修改、提交数据,可移至GPU端。 BVH Portal BSP OSP 合批(Batch) 减少顶点数、三角形数 视锥裁剪 避免每帧提交Buffer数据 减少渲染状态设置和查询 启用GPU Instance 开启LOD 避免从显存读数据 减少过绘制: 粒子数量多且面积小,由于像素块机制,会加剧过绘制情况 植物、沙石、毛发等也如此 背面裁剪 遮挡裁剪 视口裁剪 剪切矩形(scissor rectangle) Early-Z 层次Z缓冲(Hierarchical Z-Buffering,HZB) 避免Tex Kill操作 避免Alpha Test 避免Alpha Blend 开启深度测试 开启裁剪: 控制物体数量 Shader优化: 避免if、switch分支语句 避免 for循环语句,特别是循环次数可变的减少纹理采样次数 禁用 clip或discard操作减少复杂数学函数调用
移动游戏性能优化通用技法。 GPU Programming Guide。 Real-Time Rendering Resources。
5.3 GPU的未来
硬件升级。更多运算单元,更多存储空间,更高并发,更高带宽,更低延时。。。 Tile-Based Rendering的集成。基于瓦片的渲染可以一定程度降低带宽和提升光照计算效率,目前部分移动端及桌面的GPU已经引入这个技术,未来将有望成为常态。 3D内存技术。目前大多数传统的内存是2D的,3D内存则不同,在物理结构上是3D的,类似立方体结构,集成于芯片内。可获得几倍的访问速度和效能比。 
GPU愈加可编程化。GPU天生是并行且相对固定的,未来将会开放越来越多的shader可供编程,而CPU刚好相反,将往并行化发展。也就是说,未来的GPU越来越像CPU,而CPU越来越像GPU。难道它们应验了古语:合久必分,分久必合么? 
实时光照追踪的普及。基于Turing架构的GPU已经加入大量RT Core、HVB、AI降噪等技术,Hybrid Rendering Pipeline就是此架构的光线追踪渲染管线,能够同时结合光栅化器、RT Core、Compute Core执行混合渲染: 
Hybrid Rendering Pipeline相当于光线追踪渲染管线和光栅化渲染管线的合体: 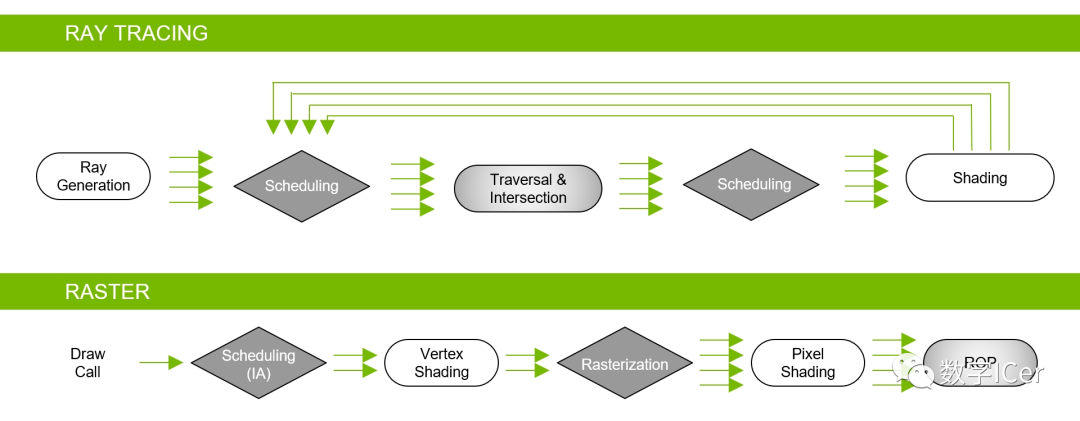
数据并发提升、深度神经网络、GPU计算单元等普及及提升。 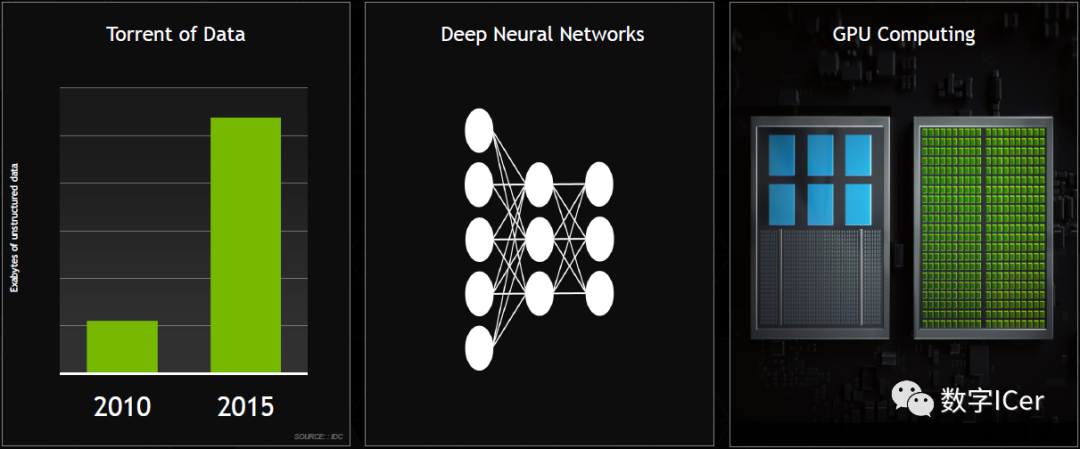
AI降噪和AI抗锯齿。AI降噪已经在部分RTX系列的光线追踪版本得到应用,而AI抗锯齿(Super Res)可用于超高分辨率的视频图像抗锯齿: 
基于任务和网格着色器的渲染管线。基于任务和网格着色器的渲染管线(Graphics Pipeline with Task and Mesh Shaders)与传统的光栅化渲染光线有着很大的差异,它以线程组(Thread Group)、任务着色器(Task shader)和网格着色器(Mesh shader)为基础,形成一种全新的渲染管线: 
关于此技术的更多详情可阅读:NVIDIA Turing Architecture Whitepaper。 可变速率着色(Variable Rate Shading)。可变利率着色技术可判断画面区域的重要性(或由应用程序指定),然后根据画面区域的重要性程度采用不同的着色分辨率精度,可以显著降低功耗,提高着色效率。

5.4 结语
如果想更深入地了解GPU的设计细节、实现细节,可阅读GPU厂商定期发布的白皮书和各大高校、机构发布的论文。推荐一个GPU解说视频:A trip through the Graphics Pipeline 2011: Index,虽然是多年前的视频,但比较系统、全面地讲解了GPU的机制和技术。
作者:0向往0
博客地址:
https://www.cnblogs.com/timlly/p/11471507.html
Real-Time Rendering Resources Life of a triangle - NVIDIA\\'s logical pipeline NVIDIA Pascal Architecture Whitepaper NVIDIA Turing Architecture Whitepaper Pomegranate: A Fully Scalable Graphics Architecture Performance Optimization Guidelines and the GPU Architecture behind them A trip through the Graphics Pipeline 2011 Graphic Architecture introduction and analysis Exploring the GPU Architecture Introduction to GPU Architecture An Introduction to Modern GPU Architecture GPU TECHNOLOGY: PAST, PRESENT, FUTURE GPU Computing & Architectures NVIDIA VOLTA NVIDIA TURING Graphics processing unit GPU并行架构及渲染优化 渲染优化-从GPU的结构谈起 GPU Architecture and Models Introduction to and History of GPU Algorithms GPU Architecture Overview 计算机那些事(8)——图形图像渲染原理 GPU Programming Guide GeForce 8 and 9 Series GPU的工作原理 NVIDIA显示核心列表 DirectX 高级着色器语言 探究光线追踪技术及UE4的实现 移动游戏性能优化通用技法 NV shader thread group 实时渲染深入探究 NVIDIA GPU 硬件介绍 Data Transfer Matters for GPU Computing Slang – A Shader Compilation System Graphics Shaders - Theory and Practice 2nd Edition
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。
免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
电子书<服务器基础知识全解(终极版)>更新完毕,知识点深度讲解,提供182页完整版下载。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。

评论