
OpenCV测量物体的尺寸技能 get~
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


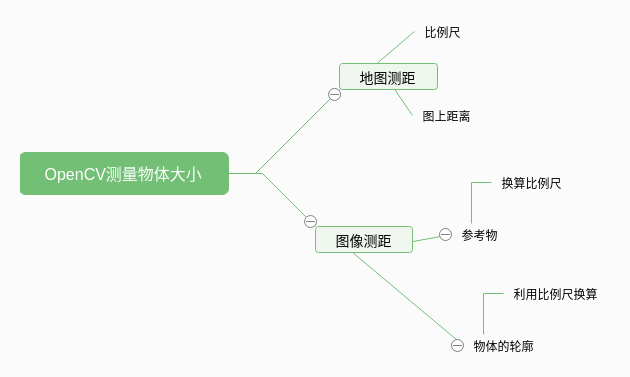
测距原理
性质1:参考物尺寸
性质2:易于识别
我们应该能够很容易地在图片中找到参照物体,无论是基于物体的位置(例如,参考物体总是放在图片的左上角)还是通过外观(例如,独特的颜色或形状,不同与图片中的其他物体)。无论是哪种情况,我们的参照物都应该以某种方式具有唯一的可识别性。
在下面的例子中,我们将使用美国硬币作为我们的参考对象,在所有的示例中,确保它始终是图片中的最左侧的对象。

通过确保硬币是最左边的物体,我们可以从左到右对物体轮廓进行排序,获取硬币(始终是排序列表中的第一个轮廓),并使用它定义每个单位的像素数,我们将其定义为:
已知硬币的宽度为0.955英寸。现在假设,物体的宽为150像素(基于其关联的边界框)。
pixels_per_metric可得:
pixels_per_metric=150px/0.955in = 157px/in
因此,在图片中应用每英寸所占的像素点为157个。使用这个比率,我们可以计算图片中物体的大小。
利用计算机视觉测量物体的大小
现在我们理解了pixels_per_metric比率的含义,我们可以应用python运行代码来测量图片中的物体大小。
打开一个文件,命名为 object_size.py,并插入以下代码:
# 导入必要的包from scipy.spatial import distance as distfrom imutils import perspectivefrom imutils import contoursimport numpy as npimport argparseimport imutilsimport cv2def midpoint(ptA, ptB):return ((ptA[0]+ptB[0])*0.5, (ptA[1]+ptB[1])*0.5)# 构造解析参数ap = argparse.ArugmentParser()ap.add_argument("-i", "--image", required=True,help="path to the input image")ap.add_argument("-w", "--width", required=True,help="width of the left-most object in the image(in inches)")args = vars(ap.parse_args()
pip3 install imutils除此之外,如果你安装了imutils,请确保你安装了最新版本的,本例中imutils的版本为“0.5.2”
pip3 install --upgrade imutils第10-11行定义个midpoint的辅助函数,从它的名字可知,该函数是用于计算两组(x,y)坐标的中点。
在第14-19行构造解析参数。我们需要两个参数,--image,我们需要测量的物体图片的路径,--width,参考物体的宽(单位in),假定它是我们图片中的最左边的对象。
# 导入图片转换为灰度图,并进行轻微的模糊image = cv2.imread(args["image"])gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)gray = cv2.GaussianBlur(gray, (7, 7), 0)# 执行边缘检测# 然后在物体之间的边缘执行膨胀+腐蚀操作使其缝隙闭合edged = cv2.Canny(gray, 50, 100)edged = cv2.dilate(edged, None, iterations=1)edged = cv2.erode(edged, None, iterations=1)# 在边缘图中查找轮廓cnts = cv2.findContours(edged.copy(), cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)cnts = imutils.grab_contours(cnts)# 从左往右对轮廓进行排序# 初始化'pixels per metric' 校准变量(cnts, _) = contours.sort_contours(cnts)pixelsPerMetric = None
2-4行 从磁盘中导入图片,转换为灰度图,然后用高斯滤波进行平滑。
然后,我们执行边缘检测和膨胀+腐蚀操作以闭合边缘图片中所有边缘之间的间隙。
13-15行在我们的边缘图片中找相应物体的轮廓。
19行将这些轮廓从左往右排序。初始化'pixels per metric' 的值
下一步就是去检测每个轮廓:
for c in cnts:if cv2.contourArea(c)<100:continueorig = image.copy()box = cv2.minAreaRect(c)box = cv2.cv.BoxPoints(box) if imutils.is_cv2() else cv2.boxPoints(box)box = np.array(box, dtype="int")box = perspective.order_points(box)cv2.drawContours(orig, [box.astype("int")], -1, (0,255,0), 2)for (x, y) in box:cv2.circle(orig, (int(x), int(y)), 5, (0,0,255), -1)
2行开始遍历每个单独的轮廓。
如果轮廓不够大,则会丢弃该区域,认为该区域是边缘检测过程中留下的噪声(4-5行)。
如果轮廓区域足够大,在第9-11行计算图中的选择边界框,特别注意OpenCV2使用的是cv2.cv.BoxPoints函数,OpenCV3使用的是cv2.boxPoints函数。
然后,我们按照左上、右上、右下和左下的顺序排列旋转的边界框坐标。
最后,第16-20行用绿色的线画出物体的轮廓,然后用红色的小圆圈绘制出边界框矩形的顶点。
现在我们已经对边界框进行了排序,我们可以计算一系列的中点:
# 打开有序的边界框,然后计算左上和右上坐标之间的中点,# 再计算左下和右下坐标之间的中点(tl, tr, br, bl) = box(tltrX, tltrY) = midpoint(tl, tr)(blbrX, blbrY) = midpoint(bl, br)# 计算左上点和右上点之间的中点# 然后是右上角和右下角之间的中点(tlblX, tlblY) = midpoint(tl, bl)(trbrX, trbrY) = midpoint(tr, br)# 在图中画出中点cv2.circle(orig, (int(tltrX), int(tltrY)), 5, (255, 0, 0), -1)cv2.circle(orig, (int(blbrX), int(blbrY)), 5, (255, 0, 0), -1)cv2.circle(orig, (int(tlblX), int(tlblY)), 5, (255, 0, 0), -1)cv2.circle(orig, (int(trbrX), int(trbrY)), 5, (255, 0, 0), -1)# 在中点之间绘制线cv2.line(orig, (int(tltrX), int(tltrY)), (int(blbrX), int(blbrY)),(255, 0, 255), 2)cv2.line(orig, (int(tlblX), int(tlblY)), (int(trbrX), int(trbrY)),(255, 0, 255), 2)
第3-5行取出有序的边界框,然后计算左上和右上点之间的中点,再计算左下和右下点之间的中点。
我们还将分别计算左上+左下和右上+右下之间的中点。
第13-16行在图中画出蓝色的中点,然后用紫色线连接中点。
接下来,我们通过分析参考物体来初始化pixelsPerMetric值
# 计算中点间的欧式距离dA = dist.euclidean((tltrX, tltrY), (blbrX, blbrY))dB = dist.euclidean((tlblX, tlblY), (trbrX, trbrY))# 如果pixels per metric还未初始化,# 则将其计算为像素与提供的度量的比率(本例中为英寸)if pixelsPerMetric is None:pixelsPerMetric = dB / args["width"]
第2-3行计算集合中的中点的欧式距离。
dA保存的是高度距离,dB保存的是宽度距离。
然后,我在第7行进行检测pixelsPerMetric是否被初始化了,如果未被初始化,我们通过用dB出于--width提供的值,得到我们需要每英寸的像素数。
现在pixelsPerMetric的值已经被定义,我们可以测量图片中物体的大小
dimA = dA / pixelsPerMetricdimB = dB / pixelsPerMetriccv2.putText(orig, "{:.1f}in".format(dimA),(int(tltrX - 15), int(tltrY - 10)), cv2.FONT_HERSHEY_SIMPLEX,0.65, (255, 255, 255), 2)cv2.putText(orig, "{:.1f}in".format(dimB),(int(trbrX + 10), int(trbrY)), cv2.FONT_HERSHEY_SIMPLEX,0.65, (255, 255, 255), 2)cv2.imshow("Image", orig)cv2.waitKey(0)
第2-3行通过对应的欧式距离除以pixelsPerMetric计算得到物体的尺寸。
第6-11行在图中画出物体的尺寸,而第14-15行为显示输出结果的图片。
物体尺寸测量结果
在命令行中输入
python3 object_size.py --image images/example_01.png --width 0.955输出结果如下图所示:

如上图所示,我们已经成功的计算出图片中每个物体的尺寸。
然而,并非所有的结果都是完美的。
可能的原因
1、拍摄的角度并非是一个完美的90°俯视。如果不是90°拍摄,物体的尺寸可能会出现扭曲。
2、没有使用相机内在和外在参数来校准。当无法确定这些参数时,照片很容易发生径向和切向的透镜变形。执行额外的校准步骤来找到这些参数可以消除图片中的失真并得到更好的物体大小的近似值。
总结
在本文中,我们学习了如何通过使用python和OpenCV来测量图片中的物体的大小。
我们需要确定pixels per metric比率(单位尺寸像素数),即在给定的度量(如英寸、毫米、米等)下,像素的数量。
为了计算这个比率,我们需要一个参考物体,它需要两点重要的性质:
1、参考物体需要有含测量单位(英寸、毫米等等)的尺寸
2、无论从物体的位置还是形状,参考物体都需要容易被找到。
加入上面的性质都能满足,你可以使用参考物体计算pixels per metric比率,并根据这个计算图片中物体的大小。
英文原文:
https://www.pyimagesearch.com/2016/03/28/measuring-size-of-objects-in-an-image-with-opencv/
其他参考项目:https://github.com/snsharma1311/object-size

详细代码链接:https://github.com/DWCTOD/AI_study/tree/master/%E5%90%88%E6%A0%BC%E7%9A%84CV%E5%B7%A5%E7%A8%8B%E5%B8%88/%E5%AE%9E%E6%88%98%E7%AF%87/opencv/%EF%BC%88%E5%85%AD%EF%BC%89%E5%88%A9%E7%94%A8python%E5%92%8COpenCV%E6%B5%8B%E9%87%8F%E7%89%A9%E4%BD%93%E7%9A%84%E5%A4%A7%E5%B0%8F
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~