
426,什么是递归,通过这篇文章,让你彻底搞懂递归

Beauty begins the moment you decide to be yourself.
美丽开始于你决定做自己的那一刻。
啥叫递归
tips:文章有点长,可以慢慢看,如果来不及看,也可以先收藏以后有时间在看。
聊递归之前先看一下什么叫递归。
递归,就是在运行的过程中调用自己。
构成递归需具备的条件:
1. 子问题须与原始问题为同样的事,且更为简单;
2. 不能无限制地调用本身,须有个出口,化简为非递归状况处理。
递归语言例子
我们用2个故事来阐述一下什么叫递归。
1,从前有座山,山里有座庙,庙里有个老和尚,正在给小和尚讲故事呢!故事是什么呢?“从前有座山,山里有座庙,庙里有个老和尚,正在给小和尚讲故事呢!故事是什么呢?‘从前有座山,山里有座庙,庙里有个老和尚,正在给小和尚讲故事呢!故事是什么呢?……’”
2,大雄在房里,用时光电视看着从前的情况。电视画面中的那个时候,他正在房里,用时光电视,看着从前的情况。电视画面中的电视画面的那个时候,他正在房里,用时光电视,看着从前的情况……
递归模板
我们知道递归必须具备两个条件,一个是调用自己,一个是有终止条件。这两个条件必须同时具备,且一个都不能少。并且终止条件必须是在递归最开始的地方,也就是下面这样
public void recursion(参数0) {if (终止条件) {return;}recursion(参数1);}
不能把终止条件写在递归结束的位置,下面这种写法是错误的
public void recursion(参数0) {recursion(参数1);if (终止条件) {return;}}
如果这样的话,递归永远退不出来了,就会出现堆栈溢出异常(StackOverflowError)。
但实际上递归可能调用自己不止一次,并且很多递归在调用之前或调用之后都会有一些逻辑上的处理,比如下面这样。
public void recursion(参数0) {if (终止条件) {return;}可能有一些逻辑运算recursion(参数1)可能有一些逻辑运算recursion(参数2)……recursion(参数n)可能有一些逻辑运算}
实例分析
我对递归的理解是先往下一层层传递,当碰到终止条件的时候会反弹,最终会反弹到调用处。下面我们就以5个最常见的示例来分析下
1,阶乘
我们先来看一个最简单的递归调用-阶乘,代码如下
1public int recursion(int n) {
2 if (n == 1)
3 return 1;
4 return n * recursion(n - 1);
5}
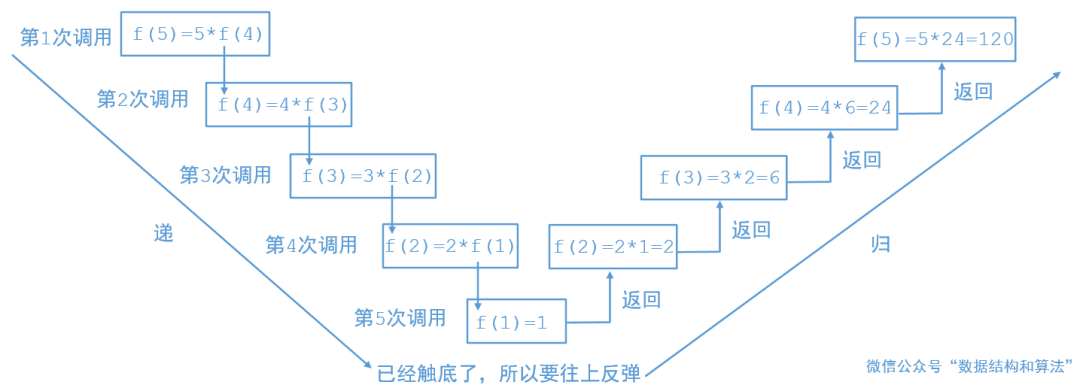
这个递归在熟悉不过了,第2-3行是终止条件,第4行是调用自己。我们就用n等于5的时候来画个图看一下递归究竟是怎么调用的
如果看不清,图片可点击放大。
这种递归还是很简单的,我们求f(5)的时候,只需要求出f(4)即可,如果求f(4)我们要求出f(3)……,一层一层的调用,当n=1的时候,我们直接返回1,然后再一层一层的返回,直到返回f(5)为止。
递归的目的是把一个大的问题细分为更小的子问题,我们只需要知道递归函数的功能即可,不要把递归一层一层的拆开来想,如果同时调用多次的话这样你很可能会陷入循环而出不来。比如上面的题中要求f(5),我们只需要计算f(4)即可,即f(5)=5*f(4);至于f(4)是怎么计算的,我们就不要管了。因为我们知道f(n)中的n可以代表任何正整数,我们只需要传入4就可以计算f(4)。
2,斐波那契数列
我们再来看另一道经典的递归题,就是斐波那契数列,数列的前几项如下所示
[1,1,2,3,5,8,13……]
我们参照递归的模板来写下,首先终止条件是当n等于1或者2的时候返回1,也就是数列的前两个值是1,代码如下
1public int fibonacci(int n) {
2 if (n == 1 || n == 2)
3 return 1;
4 这里是递归调用;
5}
递归的两个条件,一个是终止条件,我们找到了。还一个是调用自己,我们知道斐波那契数列当前的值是前两个值的和,也就是
fibonacci(n) =fibonacci(n - 1) + fibonacci(n - 2)
所以代码很容易就写出来了
1//1,1,2,3,5,8,13……
2public int fibonacci(int n) {
3 if (n == 1 || n == 2)
4 return 1;
5 return fibonacci(n - 1) + fibonacci(n - 2);
6}
3,汉诺塔
通过前面两个示例的分析,我们对递归有一个大概的了解,下面我们再来看另一个示例-汉诺塔,这个其实前面讲过,有兴趣的可以看下362,汉诺塔

汉诺塔的原理这里再简单提一下,就是有3根柱子A,B,C。A柱子上由上至下依次由小至大排列的圆盘。把A柱子上的圆盘借B柱子全部移动到C柱子上,并且移动的过程始终是小的圆盘在上,大的在下。我们还是用递归的方式来解这道题,先来定义一个函数
public void hanoi(int n, char A, char B, char C)
他表示的是把n个圆盘从A借助B成功的移动到C。
我们先来回顾一下递归的条件,一个是终止条件,一个是调用自己。我们先来看下递归的终止条件就是当n等于1的时候,也就是A柱子上只有一个圆盘的时候,我们直接把A柱子上的圆盘移动到C柱子上即可。
1//表示的是把n个圆盘借助柱子B成功的从A移动到C
2public static void hanoi(int n, char A, char B, char C) {
3 if (n == 1) {
4 //如果只有一个,直接从A移动到C即可
5 System.out.println("从" + A + "移动到" + C);
6 return;
7 }
8 这里是递归调用
9}
再来看一下递归调用,如果n不等于1,我们要分3步,
1,先把n-1个圆盘从A借助C成功的移动到B
2,然后再把第n个圆盘从A移动到C
3,最后再把n-1个圆盘从B借助A成功的移动到C。
那代码该怎么写呢,我们知道函数
hanoi(n, 'A', 'B', 'C')表示的是把n个圆盘从A借助B成功的移动到C
所以hanoi(n-1, 'A', 'C', 'B')就表示的是把n-1个圆盘从A借助C成功的移动到B
hanoi(n-1, 'B', 'A', 'C')就表示的是把n-1个圆盘从B借助A成功的移动到C
所以上面3步如果用代码就可以这样来表示
1,hanoi(n-1, 'A', 'C', 'B')
2,System.out.println("从" + A + "移动到" + C);
3,hanoi(n-1, 'B', 'A', 'C')
所以最终完整代码如下
1//表示的是把n个圆盘借助柱子B成功的从A移动到C
2public static void hanoi(int n, char A, char B, char C) {
3 if (n == 1) {
4 //如果只有一个,直接从A移动到C即可
5 System.out.println("从" + A + "移动到" + C);
6 return;
7 }
8 //表示先把n-1个圆盘成功从A移动到B
9 hanoi(n - 1, A, C, B);
10 //把第n个圆盘从A移动到C
11 System.out.println("从" + A + "移动到" + C);
12 //表示把n-1个圆盘再成功从B移动到C
13 hanoi(n - 1, B, A, C);
14}
通过上面的分析,是不是感觉递归很简单。所以我们写递归的时候完全可以套用上面的模板,先写出终止条件,然后在写递归的逻辑调用。还有一点非常重要,就是一定要明白递归函数中每个参数的含义,这样在逻辑处理和函数调用的时候才能得心应手,函数的调用我们一定不要去一步步拆开去想,这样很有可能你会奔溃的。
4,二叉树的遍历
再来看最后一个常见的示例就是二叉树的遍历,在前面也讲过,如果有兴趣的话可以看下373,数据结构-6,树,我们主要来看一下二叉树的前中后3种遍历方式,
1,先看一下前序遍历(根节点最开始),他的顺序是
根节点→左子树→右子树
我们来套用模板看一下
1public void preOrder(TreeNode node) {
2 if (终止条件)// (必须要有)
3 return;
4 逻辑处理//(不是必须的)
5 递归调用//(必须要有)
6}
终止条件是node等于空,逻辑处理这块直接打印当前节点的值即可,递归调用是先打印左子树在打印右子树,我们来看下
1public static void preOrder(TreeNode node) {
2 if (node == null)
3 return;
4 System.out.printf(node.val + "");
5 preOrder(node.left);
6 preOrder(node.right);
7}
中序遍历和后续遍历直接看下
2,中序遍历(根节点在中间)
左子树→根节点→右子树
1public static void inOrder(TreeNode node) {
2 if (node == null)
3 return;
4 inOrder(node.left);
5 System.out.println(node.val);
6 inOrder(node.right);
7}
3,后序遍历(根节点在最后)
左子树→右子树→根节点
1public static void postOrder(TreeNode tree) {
2 if (tree == null)
3 return;
4 postOrder(tree.left);
5 postOrder(tree.right);
6 System.out.println(tree.val);
7}
5,链表的逆序打印
这个就不在说了,直接看下
1public void printRevers(ListNode root) {
2 //(终止条件)
3 if (root == null)
4 return;
5 //(递归调用)先打印下一个
6 printRevers(root.next);
7 //(逻辑处理)把后面的都打印完了在打印当前节点
8 System.out.println(root.val);
9}
分支污染问题
通过上面的分析,我们对递归有了更深一层的认识。但总觉得还少了点什么,其实递归我们还可以通过另一种方式来认识他,就是n叉树。在递归中如果只调用自己一次,我们可以把它想象为是一棵一叉树(这是我自己想的,我们可以认为只有一个子节点的树),如果调用自己2次,我们可以把它想象为一棵二叉树,如果调用自己n次,我们可以把它想象为一棵n叉树……。就像下面这样,当到达叶子节点的时候开始往回反弹。

递归的时候如果处理不当可能会出现分支污染导致结果错误。为什么会出现这种情况,我先来解释一下,因为除了基本类型是值传递以外,其他类型基本上很多都是引用传递。看一下上面的图,比如我开始调用的时候传入一个list对象,在调用第一个分支之后list中的数据修改了,那么后面的所有分支都能感知到,实际上也就是对后面的分支造成了污染。
我们先来看一个例子吧
给定一个数组nums=[2,3,5]和一个固定的值target=8。找出数组sums中所有可以使数字和为target的组合。先来画个图看一下
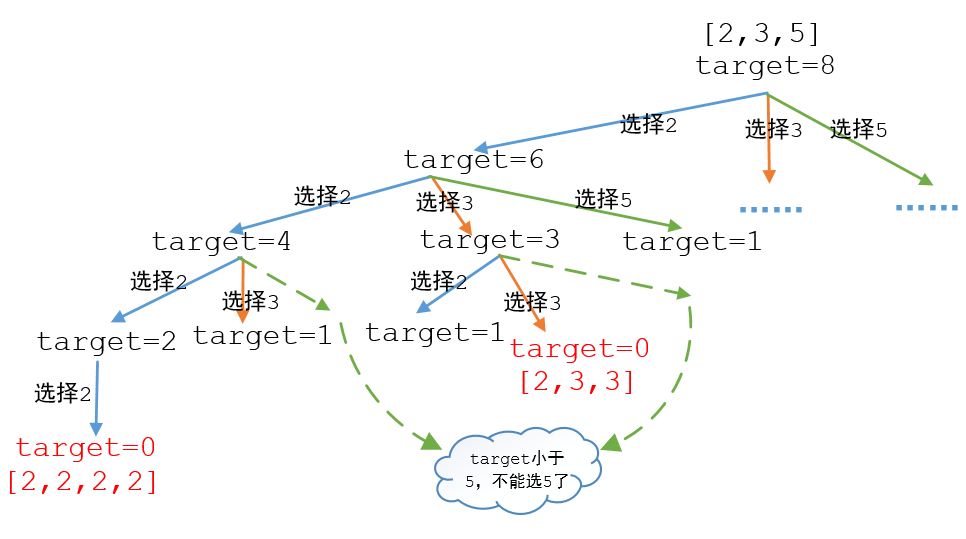
图中红色的表示的是选择成功的组合,这里只画了选择2的分支,由于图太大,所以选择3和选择5的分支没画。在仔细一看这不就是一棵3叉树吗,OK,我们来使用递归的方式,先来看一下函数的定义
1private void combinationSum(List cur, int sums[], int target) {
2
3}
在把递归的模板拿出来
1private void combinationSum(List cur, int sums[], int target) {
2 if (终止条件) {
3 return;
4 }
5 //逻辑处理
6
7 //因为是3叉树,所以这里要调用3次
8 //递归调用
9 //递归调用
10 //递归调用
11
12 //逻辑处理
13}
这种解法灵活性不是很高,如果nums的长度是3,我们3次递归调用,如果nums的长度是n,那么我们就要n次调用……。所以我们可以直接写成for循环的形式,也就是下面这样
1private void combinationSum(List cur, int sums[], int target) {
2 //终止条件必须要有
3 if (终止条件) {
4 return;
5 }
6 //逻辑处理(可有可无,是情况而定)
7 for (int i = 0; i < sums.length; i++) {
8 //逻辑处理(可有可无,是情况而定)
9 //递归调用(递归调用必须要有)
10 //逻辑处理(可有可无,是情况而定)
11 }
12 //逻辑处理(可有可无,是情况而定)
13}
下面我们再来一步一步看
1,终止条件是什么?
当target等于0的时候,说明我们找到了一组组合,我们就把他打印出来,所以终止条件很容易写,代码如下
1 if (target == 0) {
2 System.out.println(Arrays.toString(cur.toArray()));
3 return;
4 }
2,逻辑处理和递归调用
我们一个个往下选的时候如果要选的值比target大,我们就不要选了,如果不比target大,就把他加入到list中,表示我们选了他,如果选了他之后在递归调用的时候target值就要减去选择的值,代码如下
1 //逻辑处理
2 //如果当前值大于target我们就不要选了
3 if (target < sums[i])
4 continue;
5 //否则我们就把他加入到集合中
6 cur.add(sums[i]);
7 //递归调用
8 combinationSum(cur, sums, target - sums[i]);
终止条件和递归调用都已经写出来了,感觉代码是不是很简单,我们再来把它组合起来看下完整代码
1private void combinationSum(List cur, int sums[], int target ) {
2 //终止条件必须要有
3 if (target == 0) {
4 System.out.println(Arrays.toString(cur.toArray()));
5 return;
6 }
7 for (int i = 0; i < sums.length; i++) {
8 //逻辑处理
9 //如果当前值大于target我们就不要选了
10 if (target < sums[i])
11 continue;
12 //否则我们就把他加入到集合中
13 cur.add(sums[i]);
14 //递归调用
15 combinationSum(cur, sums, target - sums[i]);
16 }
我们还用上面的数据打印测试一下
1public static void main(String[] args) {
2 new Recursion().combinationSum(new ArrayList<>(), new int[]{2, 3, 5}, 8);
3}
运行结果如下

是不是很意外,我们思路并没有出错,结果为什么不对呢,其实这就是典型的分支污染,我们再来看一下图
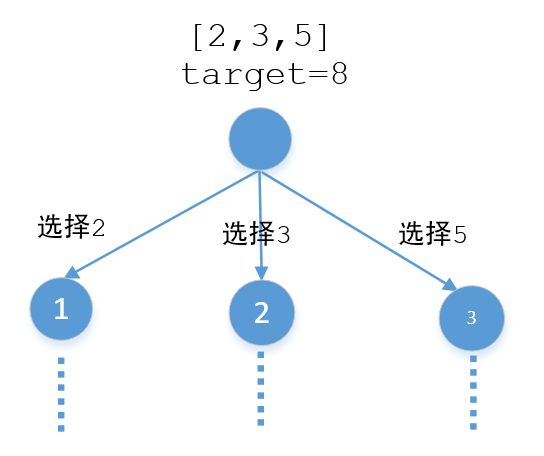
当我们选择2的时候是一个分支,当我们选择3的时候又是另外一个分支,这两个分支的数据应该是互不干涉的,但实际上当我们沿着选择2的分支走下去的时候list中会携带选择2的那个分支的数据,当我们再选择3的那个分支的时候这些数据还依然存在list中,所以对选择3的那个分支造成了污染。有一种解决方式就是每个分支都创建一个新的list,也就是下面这样,这样任何一个分支的修改都不会影响到其他分支。
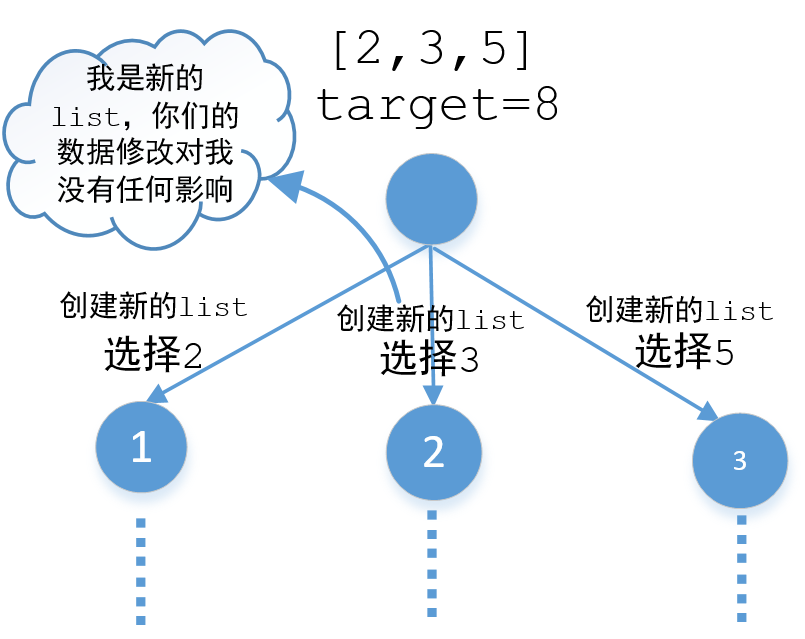
再来看下代码
1private void combinationSum(List cur, int sums[], int target) {
2 //终止条件必须要有
3 if (target == 0) {
4 System.out.println(Arrays.toString(cur.toArray()));
5 return;
6 }
7 for (int i = 0; i < sums.length; i++) {
8 //逻辑处理
9 //如果当前值大于target我们就不要选了
10 if (target < sums[i])
11 continue;
12 //由于List是引用传递,所以这里要重新创建一个
13 List list = new ArrayList<>(cur);
14 //把数据加入到集合中
15 list.add(sums[i]);
16 //递归调用
17 combinationSum(list, sums, target - sums[i]);
18 }
19}
我们看到第13行是重新创建了一个list。再来打印一下看下结果,结果完全正确,每一组数据的和都是8
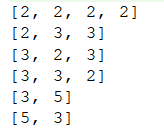
上面我们每一个分支都创建了一个新的list,所以任何分支修改都只会对当前分支有影响,不会影响到其他分支,也算是一种解决方式。但每次都重新创建数据,运行效率很差。我们知道当执行完分支1的时候,list中会携带分支1的数据,当执行分支2的时候,实际上我们是不需要分支1的数据的,所以有一种方式就是从分支1执行到分支2的时候要把分支1的数据给删除,这就是大家经常提到的回溯算法,我们来看下
1private void combinationSum(List cur, int sums[], int target ) {
2 //终止条件必须要有
3 if (target == 0) {
4 System.out.println(Arrays.toString(cur.toArray()));
5 return;
6 }
7 for (int i = 0; i < sums.length; i++) {
8 //逻辑处理
9 //如果当前值大于target我们就不要选了
10 if (target < sums[i])
11 continue;
12 //把数据sums[i]加入到集合中,然后参与下一轮的递归
13 cur.add(sums[i]);
14 //递归调用
15 combinationSum(cur, sums, target - sums[i]);
16 //sums[i]这个数据你用完了吧,我要把它删了
17 cur.remove(cur.size() - 1);
18 }
19}
我们再来看一下打印结果,完全正确

递归分支污染对结果的影响
分支污染一般会对结果造成致命错误,但也不是绝对的,我们再来看个例子。生成一个2^n长的数组,数组的值从0到(2^n)-1,比如n是3,那么要生成
[0, 0, 0][0, 0, 1][0, 1, 0][0, 1, 1][1, 0, 0][1, 0, 1][1, 1, 0][1, 1, 1]
我们先来画个图看一下
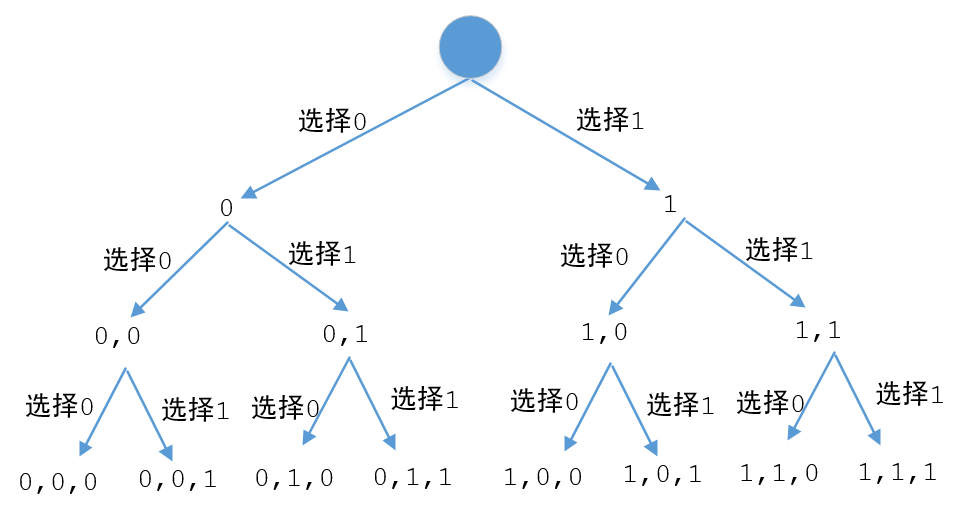
这不就是个二叉树吗,对于递归前面已经讲的很多了,我们来直接看代码
1private void binary(int[] array, int index) {
2 if (index == array.length) {
3 System.out.println(Arrays.toString(array));
4 } else {
5 int temp = array[index];
6 array[index] = 0;
7 binary(array, index + 1);
8 array[index] = 1;
9 binary(array, index + 1);
10 array[index] = temp;
11 }
12}
上面代码很好理解,首先是终止条件,然后是递归调用,在调用之前会把array[index]的值保存下来,最后再还原。我们来测试一下
new Recursion().binary(new int[]{0, 0, 0}, 0);看下打印结果

结果完全正确,我们再来改一下代码
1private void binary(int[] array, int index) {
2 if (index == array.length) {
3 System.out.println(Arrays.toString(array));
4 } else {
5 array[index] = 0;
6 binary(array, index + 1);
7 array[index] = 1;
8 binary(array, index + 1);
9 }
10}
再来看一下打印结果

和上面结果一模一样,开始的时候我们没有把array[index]的值保存下来,最后也没有对他进行复原,但结果丝毫不差。原因就在上面代码第5行array[index]=0,这是因为,上一分支执行的时候即使对array[index]造成了污染,在下一分支又会对他进行重新修改。即使你把它改为任何数字也都不会影响到最终结果,比如我们在上一分支执行完了时候我们把它改为100,你在试试
1private void binary(int[] array, int index) {
2 if (index == array.length) {
3 System.out.println(Arrays.toString(array));
4 } else {
5 array[index] = 0;
6 binary(array, index + 1);
7 array[index] = 1;
8 binary(array, index + 1);
9 //注意,这里改成100了
10 array[index] = 100;
11 }
12}
我们看到第10行,把array[index]改为100了,最终打印结果也是不会变的,所以这种分支污染并不会造成最终的结果错误。
总结
对递归的理解,看完这篇文章应该没有什么疑问了,记住上面模板,其实代码很好写的,后面也会再写一些关于递归的算法题的,让你彻底搞懂递归。

长按上图,识别图中二维码之后即可关注。
如果觉得有用就点个"赞"和“在看”吧