
什么?用了Java 8的并行流还更慢了?
往期热门文章:
3、36 张图梳理 Intellij IDEA 常用设置,写代码贼爽!
前言
Java 8给大家带来了一个非常便捷的多线程工具:并行流,一改往日Java多线程繁琐的编程规范,只需要一行代码,就可以让一个多线程跑起来,似乎让很多人忘记了被多线程支配的恐惧,这篇文章给大家分享一个真实的生产故障,由于在消费消息的处理器中使用了Java 8的并行流,导致集群消费消息的能力急速下降,造成线上消息堆积,引发故障。可能有朋友会好奇,到底是什么场景让并行流起了反作用?
并行流执行速度一定比串行快吗?
void testParallelStream() throws InterruptedException {
ExecutorService threadPool = new ThreadPoolExecutor(50, 200, 20, TimeUnit.MINUTES, new ArrayBlockingQueue<>(1000),
new ThreadFactoryBuilder().setNameFormat("test-parallel-thread").build(), new ThreadPoolExecutor.CallerRunsPolicy());
Long time1 = System.currentTimeMillis();
// 1. 多线程+foreach执行时长
for (int i = 0; i < ARRAY_LENGTH; i++) {
CommonExecutor commonExecutor = new CommonExecutor();
commonExecutor.array = arrays[i];
threadPool.submit(commonExecutor);
}
commonCountDownLatch.await();
Long time2 = System.currentTimeMillis();
System.out.println("for循环耗时: " + (time2 - time1));
threadPool = new ThreadPoolExecutor(50, 200, 20, TimeUnit.MINUTES, new ArrayBlockingQueue<>(1000),
new ThreadFactoryBuilder().setNameFormat("test-parallel-thread").build(), new ThreadPoolExecutor.CallerRunsPolicy());
// 2. 多线程+并行流执行时长
for (int i = 0; i < ARRAY_LENGTH; i++) {
ParallelStreamExecutor parallelStreamExecutor = new ParallelStreamExecutor();
parallelStreamExecutor.array = arrays[i];
threadPool.submit(parallelStreamExecutor);
}
parallelCountDownLatch.await();
Long time3 = System.currentTimeMillis();
System.out.println("并行流耗时: " + (time3 - time2));
}
@Data
private static class CommonExecutor implements Runnable {
private long[] array;
@Override
public void run() {
// 选择排序法进行排序
for (int i = 0; i < array.length; i++) {
array[i] = i * i;
}
commonCountDownLatch.countDown();
}
}
@Data
private static class ParallelStreamExecutor implements Runnable {
private long[] array;
@Override
public void run() {
// 选择排序法进行排序
IntStream.range(0, array.length).parallel().forEach(i -> array[i] = i * i);
parallelCountDownLatch.countDown();
}
}
arrays的每一行,计算其列下标的平方数,并且回填到数组中,只不过这个过程是通过线程池去完成的,提交给线程池的执行器有两种,一种是普通的for循环,通过游标遍历每一个元素的下标,并计算平方数。另一种使用了并行流去完成同样的事情。简单起见,我们把这段代码循环执行10次,并统计了每次两种实现方式的耗时(单位是毫秒),大家可以猜猜看,到底哪种实现方式更快。| 执行次数 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 平均耗时 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| for循环耗时 | 18 | 17 | 13 | 18 | 17 | 13 | 13 | 16 | 20 | 16 | 16.1 |
| 并行流耗时 | 32 | 41 | 38 | 59 | 51 | 34 | 53 | 57 | 49 | 47 | 46.1 |
并行流的实现原理
threadPool的线程数开到多大,最终实际处理Action的线程数都由并行流的公共线程池大小决定,这一点我们可以从并行流的源码上看个大概:@Override
@SuppressWarnings("unchecked")
public final S parallel() {
sourceStage.parallel = true;
return (S) this;
}
java.util.stream.AbstractPipeline中的sourceStage.parallel置为true,到调用foreach的时候,会调用到下面这个方法final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) {
assert getOutputShape() == terminalOp.inputShape();
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}
isParallel()就会判断上面设置的sourceStage.parallel字段,从而使程序的执行流程走到terminalOp.evaluateParallel这个分支,再往后跟的话会发现最终任务会提交到ForEachTask@Override
public <S> Void evaluateParallel(PipelineHelper<T> helper,
Spliterator<S> spliterator) {
if (ordered)
new ForEachOrderedTask<>(helper, spliterator, this).invoke();
else
new ForEachTask<>(helper, spliterator, helper.wrapSink(this)).invoke();
return null;
}
ForEachTask这里稍微提一嘴,是java 1.7引入的一个轻量级多线程任务,逻辑还是比较多的,后面有机会我们再看下它的实现原理,通过断点跟进去,发现最后提交的任务都会调用到ForEachTask的compute方法public void compute() {
// 以我们初始提交的任务为例spliterator的类型是一个RangeIntSpliterator,其中from = 0, upTo = 10000, last = 0
Spliterator<S> rightSplit = spliterator, leftSplit;
// estimateSize = upTo - from + last
long sizeEstimate = rightSplit.estimateSize(), sizeThreshold;
if ((sizeThreshold = targetSize) == 0L)
// 目标大小会根据上文提到的公共线程池计算,值等于 sizeEstimate/线程池大小 * 4
targetSize = sizeThreshold = AbstractTask.suggestTargetSize(sizeEstimate);
boolean isShortCircuit = StreamOpFlag.SHORT_CIRCUIT.isKnown(helper.getStreamAndOpFlags());
boolean forkRight = false;
Sink<S> taskSink = sink;
ForEachTask<S, T> task = this;
// 【核心逻辑】进入任务切分逻辑,
while (!isShortCircuit || !taskSink.cancellationRequested()) {
// 切分直至子任务的大小小于阈值
if (sizeEstimate <= sizeThreshold ||
// trySplit()会将rightSplit等比例切分,并返回切分的第一个子任务,切分比例跟待切分的任务总数相关
// 如果待切分的子任务大小小于等于1,则返回null,停止切分
(leftSplit = rightSplit.trySplit()) == null) {
task.helper.copyInto(taskSink, rightSplit);
break;
}
ForEachTask<S, T> leftTask = new ForEachTask<>(task, leftSplit);
task.addToPendingCount(1);
ForEachTask<S, T> taskToFork;
// 这里通过forkRight控制本线程切割任务的顺序是
// 左->右->左->右->左->右直至子任务大小满足阈值,这样可以让整个任务执行更离散
// 关于这样做的好处也欢迎大家在评论区讨论
if (forkRight) {
forkRight = false;
rightSplit = leftSplit;
taskToFork = task;
task = leftTask;
}
else {
forkRight = true;
taskToFork = leftTask;
}
// 通过fork将将切分好的子任务提交到线程池
taskToFork.fork();
sizeEstimate = rightSplit.estimateSize();
}
task.spliterator = null;
task.propagateCompletion();
}
public final ForkJoinTask<V> fork() {
Thread t;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)
((ForkJoinWorkerThread)t).workQueue.push(this);
else
ForkJoinPool.common.externalPush(this);
return this;
}
其中提交给共享队列的线程会被内部工作线程偷取 私有工作队列中的任务通过fork切分成小任务后会将子任务push回私有队列 如果工作线程有空闲,他还可以去偷取其他工作队列的任务
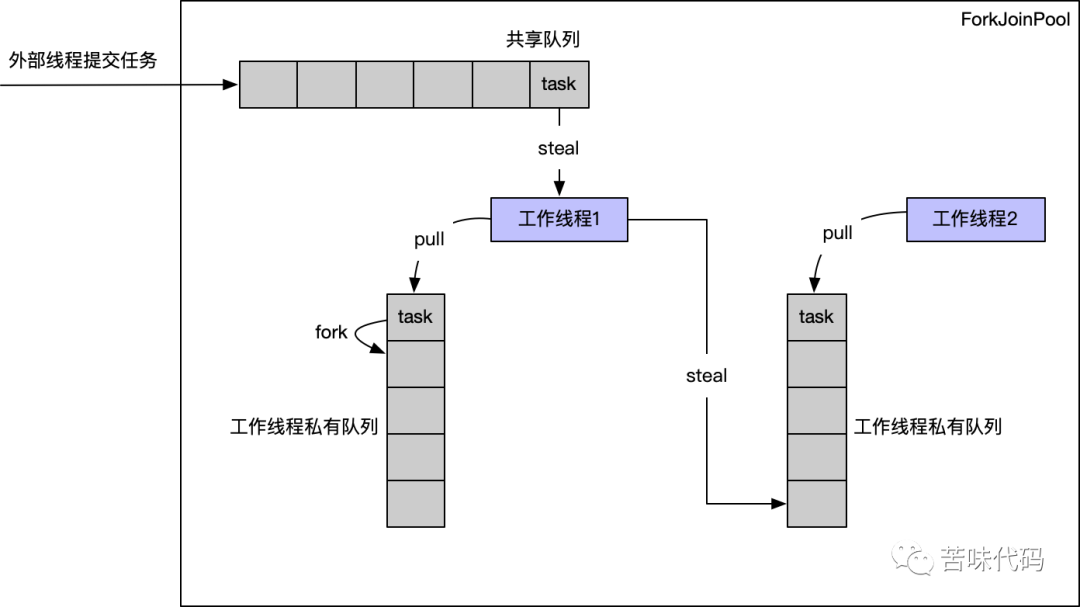
private static ForkJoinPool makeCommonPool() {
final ForkJoinWorkerThreadFactory commonPoolForkJoinWorkerThreadFactory =
new CommonPoolForkJoinWorkerThreadFactory();
int parallelism = -1;
ForkJoinWorkerThreadFactory factory = null;
UncaughtExceptionHandler handler = null;
try { // ignore exceptions in accessing/parsing properties
String pp = System.getProperty
// 可以通过设置这个值来改变公共线程池的大小
("java.util.concurrent.ForkJoinPool.common.parallelism");
String fp = System.getProperty
("java.util.concurrent.ForkJoinPool.common.threadFactory");
String hp = System.getProperty
("java.util.concurrent.ForkJoinPool.common.exceptionHandler");
if (pp != null)
parallelism = Integer.parseInt(pp);
if (fp != null)
factory = ((ForkJoinWorkerThreadFactory)ClassLoader.
getSystemClassLoader().loadClass(fp).newInstance());
if (hp != null)
handler = ((UncaughtExceptionHandler)ClassLoader.
getSystemClassLoader().loadClass(hp).newInstance());
} catch (Exception ignore) {
}
if (factory == null) {
if (System.getSecurityManager() == null)
factory = commonPoolForkJoinWorkerThreadFactory;
else // use security-managed default
factory = new InnocuousForkJoinWorkerThreadFactory();
}
if (parallelism < 0 && // default 1 less than #cores
// 获取线程池线程数量,其值等于当前可用处理器减一
(parallelism = Runtime.getRuntime().availableProcessors() - 1) <= 0)
parallelism = 1;
if (parallelism > MAX_CAP)
parallelism = MAX_CAP;
return new ForkJoinPool(parallelism, factory, handler, LIFO_QUEUE,
"ForkJoinPool.commonPool-worker-");
}
并行流比串行更慢的原因
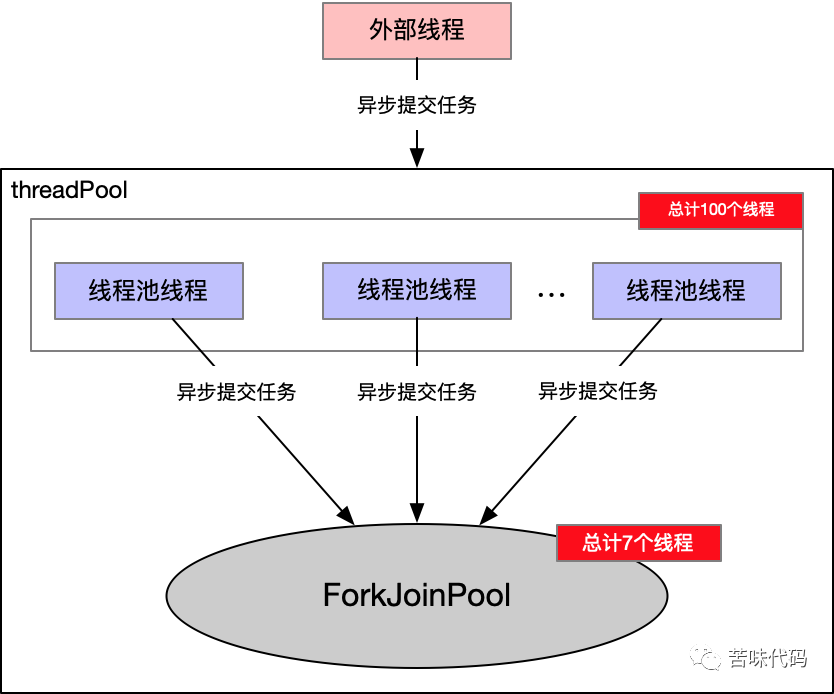
总结
同一个进程提交给并行流的任务都会被同一个公共线程池处理,因此,如果在多线程的环境中使用了并行流,反而会降低并发,使得处理变慢 并行流的公共线程池大小为可用处理器减一,并且并行流会使用外部线程去处理内部子任务,搭配 ThreadLocal使用的时候务必要慎重,在一些与ThreadLocal强耦合的场景,可能会导致ThreadLocal误清理,其他线程相关的全局变量同理并行流的设计是为了应对计算密集型的场景的,如果有较多的IO场景,比如常见的RPC调用,在高并发的场景下会导致外部线程阻塞,引起外部线程数增多,且这类问题在测试的时候不容易发现,极易引起生产故障。

扫描二维码关注
我领取面试资料
评论