
Java8中的并行流处理-顺序与并行流处理的性能

并行处理现在随处可见。由于 CPU 核数量的增加以及较低的硬件成本使得集群系统更加便宜,并行处理似乎成为下一个大趋势。
Java8通过新的 stream API 和在集合和数组上创建并行处理的简化来关注这个问题。让我们看看这是怎么运作的。
假设 myList 是一个整数列表,包含500,000个整数值。在 java 8 时代之前,对这个整数值求和的方法是使用 for 每个循环。
for (int i :myList) result+=i;
自从 java 8 之后我们可以使用 stream 来做同样的事情
myList.stream().sum();
并行化这个过程非常简单,如果我们仍然有一个流,我们只需要使用关键字 parallelStream() 来代替 stream 或者 parallel()。
那么myList.parallelStream().sum()
会有用的。因此,很容易将计算扩展到线程和可用的 CPU 核心。但是我们知道多线程和并行处理的开销是昂贵的。问题是什么时候使用并行流,以及什么时候串行流更好地与性能相关。
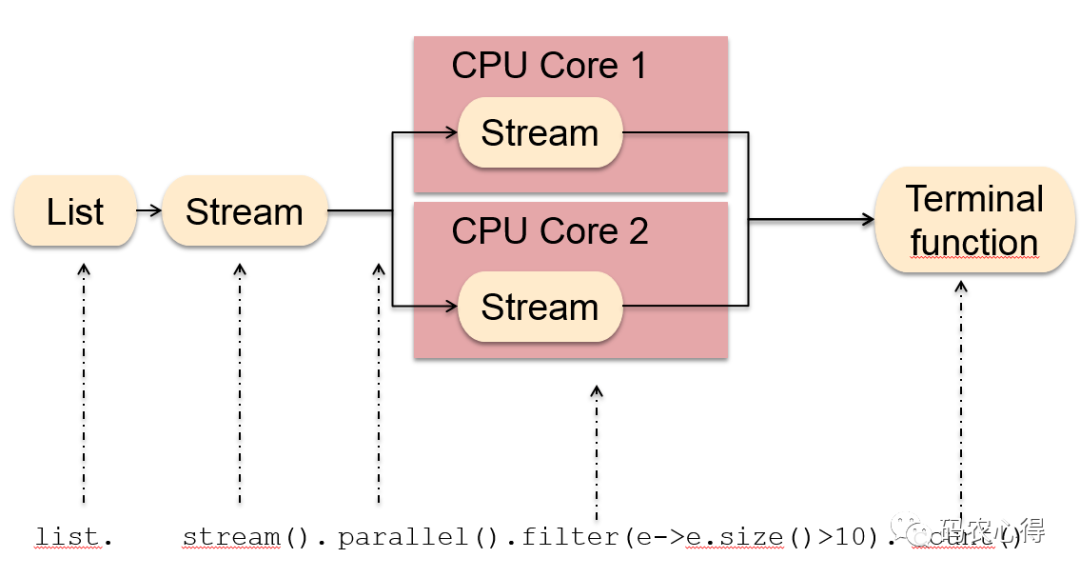
首先让我们来看看幕后发生了什么。并行流使用 Fork/Join Framework 进行处理。这意味着 stream-source 将被拆分并交给 fork/join-pool workers 执行。
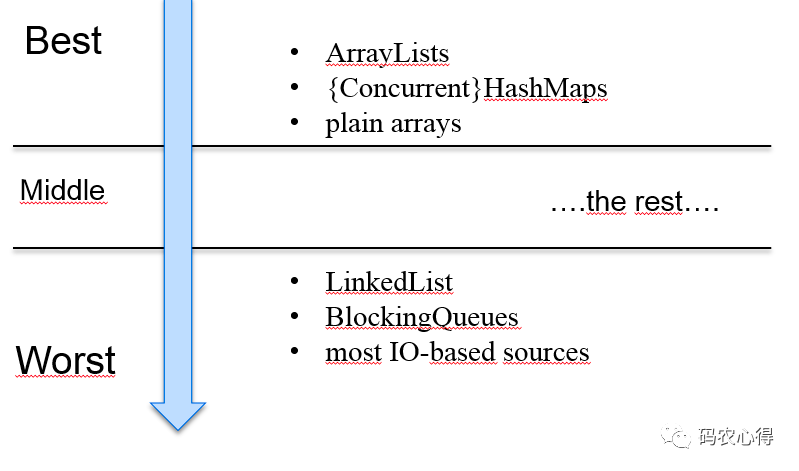
但是在这里我们首先要考虑的是,并非所有的流源都像其他流源一样可以分割。考虑一个 ArrayList,它的内部数据表示基于一个数组。拆分这样的源非常容易,因为可以计算中间元素的索引并拆分数组。
如果我们有一个 LinkedList,那么分割数据元素就会更加复杂。实现必须遍历第一个条目中的所有元素,以找到可以进行拆分的元素。例如,LinkedLists 对于并行流的性能就很差。
这是我们可以保留的关于并行流性能的第一个事实。
S – 源集合必须可以有效拆分
拆分集合、管理 fork 和 join 任务、对象创建和垃圾收集也是一个算法开销。当且仅当在CPU核心上可简单完成或者集合足够大时,才值得这样做。
一个不好的例子是计算5个整数值的最大值。
IntStream.rangeClosed(1, 5).reduce( Math::max).getAsInt();
系统为 fork/join 准备和处理数据的开销非常大,以至于串行流在此场景中要快得多。Math.Max 函数在这里的 CPU 开销并不是很高,而且数据元素很少。
但当每个元素执行的函数更加复杂一些——变得「更加 CPU 密集型」时,那它就越来越值得这么做了。比如计算每个元素的正弦值而不是最大值。
在编写一个国际象棋游戏时,计算每一步棋的走法也是一个这种类型的例子。 大量的计算可以并行完成。并且下一步棋的走法有很多种可能性。
这种情况就非常适合使用并行处理。
这就是我们可以保留的关于并行流性能的第二个事实:
N*Q —— 「元素个数 * 每个元素的操作成本」因子 应该要很大
但这也意味着反过来,当每个元素的操作成本较高时,集合应该更小。
或者,当每个元素的操作不是CPU密集型操作时,我们需要一个包含许多元素的非常大的集合,以便并行流的使用变得有价值。
这就直接取决于我们可以保留的第三个事实:
C —— CPU核心数 —— 越多越好 必须大于1
在单核机器上,由于一些管理上的开销导致并行流的性能总是比串行流的差。这就和有多个项目负责人和一个做事的人的公司是一样的。
越多越好 ——不幸的是,这对于现实生活中大多数情况都不适用,比如对于一个特别小的集合,多个 CPU 核心启动,然后发现无事可做——也许他们之前处于节能模式。
另外,决定是否使用并行流对于每一个元素执行的函数也有一些要求。这与其说是性能问题,不如说是并行流能否按预期工作的问题。
函数必须满足以下要求:
独立。这就意味着对于每个元素的计算一定不能依赖或者影响任何其他元素。
不干预。 这就意味着函数在处理过程中不会修改底层数据源。
无状态。
下面是一个在并行流中使用有状态 lambda 函数的例子。这个例子是从 Java 的 JDK API 里抽取出来的对 distinct() 的简易实现。Set seen = Collections.synchronizedSet(new HashSet()); stream.parallel().map(e -> { if (seen.add(e)) return 0; else return e; })...
这就引出了我们可以保留的第四个事实:
F —— 每个元素的操作函数必须是独立的
综上所述,即:

那还有别的不应该使用并行流的情况吗?有,当然有。
始终考虑每个元素的函数正在做什么,以及这是否适合用在并行流里。当你的函数在调用一些同步功能时,你可能不会因为并行化流而获益,因为并行流通常会在这个同步上阻塞。
当你调用阻塞的 I/O 操作,也会发生同样的问题。

就这一点来说,使用基于 I/O 的源作为流也是众所周知的性能不好,因为数据是按照顺序读取的,所以这样的源很难拆分。