
爬虫实战,文末有代码链接,Python爬取安居客网站数据
背景
最近跟一个朋友聊天的过程中,朋友提到最近工作上被老板安排了一个任务,要她对某个城市的二手房数据进做一下分析,并做一个数据分析报告。而这些房源的数据基本都在几大房产交易网站上,如果靠她个人一页一页的浏览下载太慢了,在如今工作如此内卷的情况下,等她下载完数据分析完,老板估计得立马让她卷铺盖走人了。
但如果用程序自动访问这些页面,解析页面数据,然后获取需要的数据到本地,再进行分析,就能快很多了。而这个过程用Python来完成正合适不过,于是我告诉她这个简单,我来帮她搞定,朋友听完安心地点了一杯咖啡继续内卷去了,于是,我开始负责搞定这个Python爬虫脚本。
Python爬虫开发步骤
其实,无论是用Python还是用其他编程语言来开发一个爬虫爬取某个网站的数据,一般都会分为如下几个步骤:
待爬取页面的访问url探索和获取; 待爬取页面的页面元素的探查和分析; 访问url获取网页数据; 解析网页数据获取自己想要的结果; 将结果数据保存到本地文件;
所以,接下来,我就分如上5个步骤分别讲解一下这个Pytho爬虫脚本如何开发。
1. 待爬取页面的访问url探索和获取
步骤一是对待爬取页面访问url的探索和获取
有人说,获取要爬取页面的访问url还不简单,网站上点一下链接看一下浏览器地址栏的链接地址不就行了。大家可以去试试,有的网站可能确实如此简单,但有的网站靠这样的方式是获取不到的。
比如,我们先拿一个简单的网站来说,比如有这样一个博客网站《蚂蚁学Phthon》,假如我想爬取这个网站上的博客文章列表,如下图红框所示:

大家可以点一下红框的文章以及点一下翻页,然后看一下浏览器地址栏的链接地址,可以看到,每点一个文章或者翻页,浏览器地址栏的链接地址都会变化,反映的是当前你访问的url地址,具体是长如下这样的:
#每篇文章url的正则
pattern = r'^http://www.crazyant.net/\d+.html$'
#文章列表url的正则
pattern = r'^http://www.crazyant.net/page/\d+$'
所以,这个网站假如我们要爬取所有的文章列表数据,那就很简单了,因为从浏览器地址栏我们就可以很方便地获取到要爬取的每个文章列表页的url地址,然后根据特征用正则进行匹配。
但不是所有网站都是如此简单的,我们再来看一下另外一个博客网站博客园,大家可以自己访问看一下。假如我同样希望爬取这个博客网站所有的文章列表数据,那如何获取到每个文章列表页面的url呢?
如果大家实际点过翻页就会发现,点完后浏览器地址栏的地址是这样的:

也即浏览器地址是长这样子的:
#文章列表页的正则
pattern = r'^https://www.cnblogs.com/#p\d+$
我们会看到地址里面有一个#号,如果我们直接访问这个url,能获取到我们想要的文章列表数据吗?大家可以用下面的代码自己试一下:
import requests
r = requests.get('https://www.cnblogs.com/#p5',timeout=3)
if r.status_code == 200:
resp = r.text
print(resp)
可以看到,直接访问浏览器地址的url是拿不到我们希望的文章列表页的返回数据的。因为这个网站是一个所谓的SPA应用(Single Page Application),地址栏的#号是一个Hash,改变Hash 不会重新加载页面。SPA应用的典型特征是,首次访问会加载整个页面框架,然后通过Ajax/Fetch异步获取数据更新页面内容。
所以,在这种情况下,我们只能借助于抓包工具比如chrome的开发者工具,来探索和获取真实的Ajax/Fetch的url,如下图所示:
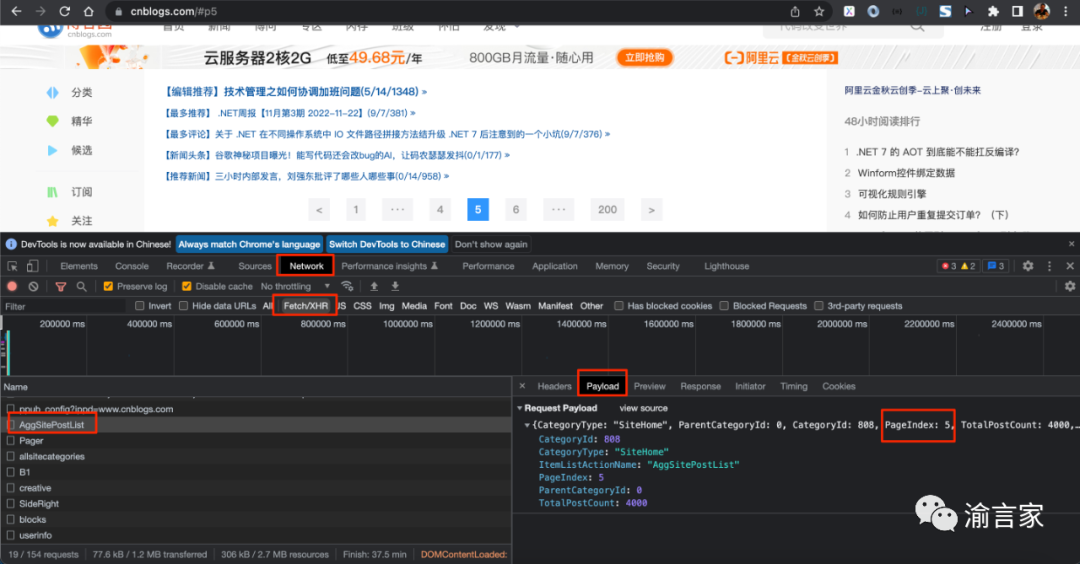
Chrome的开发者工具中的Network面板,可以很方便的获取到当前访问页面的各类请求资源,比如静态的Html/js/css/图片、动态的Fetch/XHR异步请求等,我们打开Network面板下的子面板Fetch/XHR,就可以看到所有的异步请求。点击某一个异步请求,我们就可以查看这个请求的request header、response header、cookies、请求提交的数据等信息。
我们通过探查,可以发现,有一个POST的异步请求:
https://www.cnblogs.com/AggSite/AggSitePostList
在他的Playload也即post提交的数据里,有一个"PageIndex:5"的字段,正好对应当前的页码,通过进一步探查response面板的内容,我们就可以进一步确认,这个异步请求才是我们真正要爬取的url。
所以,大家看到了,对于爬虫开发的第一步,并不都是如大家想象的那么简单,对于有的网站,还是需要利用类似Chrome开发者工具这样的抓包工具做一些探查工作的。
好了,利用上述的思路,我也对我们这次真正要爬取的某房产网站页面进行了一次探查,获取到了我要爬取的url,这次要爬取的网站的url获取还是比较简单的,属于第一种情况,在这里就不详述过程了。
2. 待爬取页面的页面元素的探查和分析
步骤二是对待爬取页面的页面元素进行探查和分析
对页面元素进行探查分析的工作,还是会用到我们之前提到的Chrome开发者工具,而要探查什么内容,则取决于我们要爬取的数据是什么。比如这次我们的需求是要爬取某房产网站的二手房房源新消息,那我们的探查就会类似下图所示:
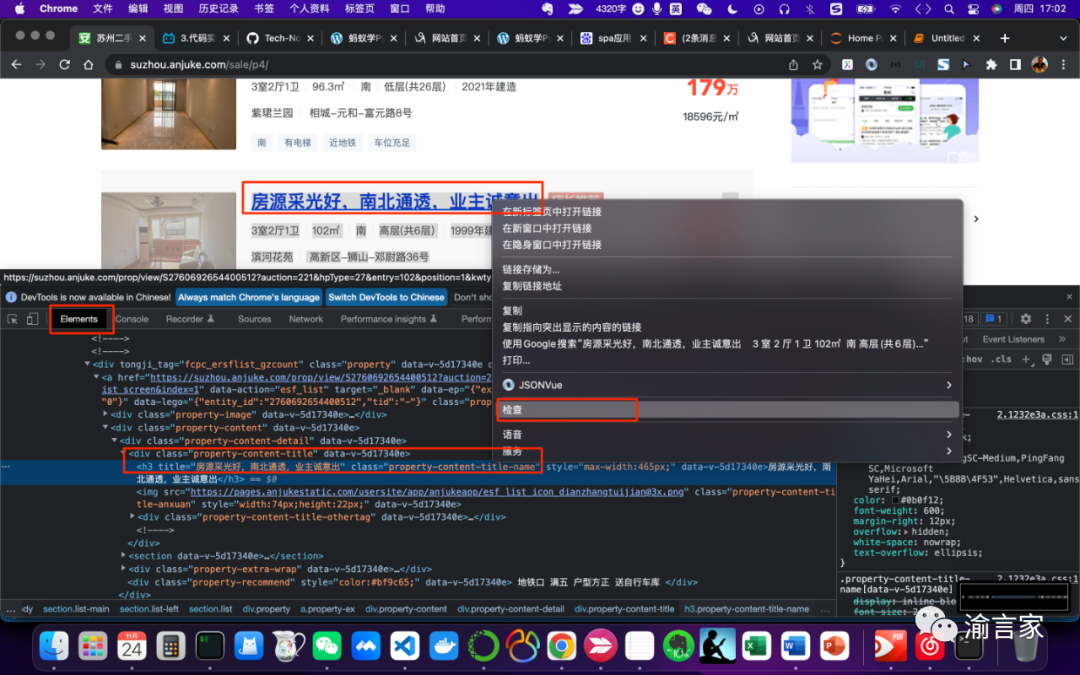
从图中可以看到,假如我们想获取房源的信息,那我们可以在房源标题上右键,然后选择检查,这时就会打开Chrome开发者工具的Elements面板,直接定位到对应的元素节点,从图中我们可以看到对应的节点是一个h3标签节点,同时我们也相应能够很清晰地看到节点的属性有哪些,哪些属性能够准确唯一地定位这个节点。比如这个h3节点有一个class属性值为“property-content-title-name”,这个属性可能不能唯一定位一个节点,但如果我们通过定位他的父节点,然后通过父节点寻找其下所有"class='property-content-title-name'"的子节点,则能够帮我们准确的定位。
好了,用如上同样的方法,我们可以逐步对我们要获取的数据对应的网页元素进行一一探查,这些探查的结果,将帮助我们后续开发页面解析的脚本代码。
3. 访问url获取网页数据
步骤三是访问待爬取的url获取网页数据
使用Python提供的requests库,我们可以方便的访问url获取数据
如果我们只是简单的手工获取一页的数据,那是很简单的,但如果我们用脚本自动地高频地访问url获取数据,则需要考虑如何绕过网站的反爬的机制了。简单的说,如果某个ip地址在某段时间内高频地访问网站,则可能触发网站的反爬机制,ip可能会被封禁。
另外,还要考虑一个问题是,网站一般会对来访者进行一些安全的校验,来识别来访者是真实的用户还是类似我们爬虫这样的robot,所以,我们需要把我们的爬虫脚本伪装成一个真实的用户来访问。
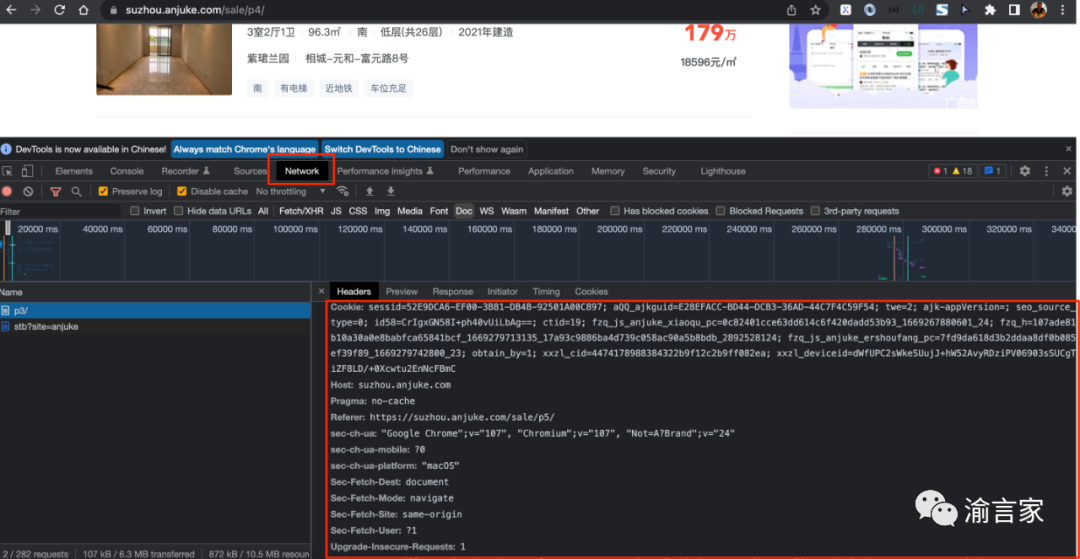
用户伪装的方法,就是获取到我们要爬取的url请求的request headers数据,然后在发送我们的request的时候,把该请求头带上,最重要的是cookies、User-Agent等字段,如下图所示:
具体在python脚本中的代码则是如下所示:
import requests
#构造url的request headers,伪装成正常用户
headers = {
'accept':'',
'accept-encoding': '',
'accept-language': '',
'cookie': '',
......
'user-agent': ''
}
r = requests.get(url=craw_url,headers=headers,timeout=3)
上面的代码我略去了部分header字段以及具体的header字段值,大家从Chrome开发者工具拷贝出来然后填进去就行。
而关于如何避免同一个IP高频的访问同一个网站,我采取的是使用代理IP服务的方式。原理简单的说,就是我通过一个代理IP的API服务,批量获取一个IP Pool,然后同一时间多个不同的线程拿不同的代理IP去访问不同的页面,这样就避免了同一个时间同一IP高频访问的问题。
这样的代理IP服务商市面上应该有很多,大家自己找一下就好,为避免打广告嫌疑,我就不直接说我用的是哪家了,直接上使用代理IP API服务的代码大家自行观摩吧:
def get_proxies():
proxy_list = []
#这里是我使用的代理IP服务商的API接口,敏感的参数值信息我用xxx代替了
proxy_url = 'http://api.tianqiip.com/getip?secret=xxx&num=1&type=json&port=1&time=3&mr=1&sign=xxx'
try:
datas = requests.get(proxy_url).json()
#如果代理ip获取成功
if datas['code'] == 1000:
data_array = datas['data']
for i in range(len(data_array)):
proxy_ip = data_array[i]['ip']
proxy_port = str(data_array[i]['port'])
proxy = proxy_ip + ":" + proxy_port
proxy_list.append({'http':'http://'+proxy,'https':'http://'+proxy})
else:
code = datas['code']
print(f'获取代理失败,状态码={code}')
return proxy_list
except Exception as e:
print('调用天启API获取代理IP异常:'+ e)
return proxy_list
#在使用代理的情况下,需要在请求url数据的时候传入proxies参数值为我们获取的proxy
r = requests.get(url=craw_url,headers=headers,proxies=proxy,timeout=10)
好了,通过真实用户伪装和使用代理IP服务,我们就可以用我们的脚本来自动批量的访问url获取我们要爬取的url数据了。
通过代理IP服务商的API拿到IP Pool之后,我们可以启动多个线程进行数据的爬取,代码如下:
while crawlerUrlManager.has_new_url():
crawler_threads = []
for i in range(len(proxy_list)):
proxy = proxy_list[i]
crawler_thread = threading.Thread(target=craw_anjuke_suzhou,args=(crawlerUrlManager.get_url(),proxy))
crawler_threads.append(crawler_thread)
#启动线程开始爬取
for crawler_thread in crawler_threads:
crawler_thread.start()
for crawler_thread in crawler_threads:
crawler_thread.join()
#谨慎起见,一批线程爬取结束后,间隔一段时间,再启动下一批爬取,这里默认设置为3秒,可调整
time.sleep(3)
大家看这段代码的时候,会看到一个叫crawlerUrlManager的类,这个类主要用来对要爬取的url进行管理的,记录哪些url已经被爬取,哪些url还没有被爬取,因为在爬取的过程中可能会碰到各种问题,尤其是网络访问相关的问题,所以有这么一个manager,可以在出现问题的时候告诉我们哪些url爬取成功了,还剩余哪些url待爬取,方便后续跟进处理,这部分的核心代码如下:
#新增一个待爬取Url
def add_new_url(self,url):
if url is None or len(url) == 0:
return
if url in self.new_urls or url in self.old_urls:
return
self.new_urls.add(url)
return True
#获取一个要爬取的url
def get_url(self):
if self.has_new_url():
url = self.new_urls.pop()
self.old_urls.add(url)
return url
else:
return None
#判断是否有待爬取的url
def has_new_url(self):
return len(self.new_urls) > 0
......
完整代码大家可以从这里获取:https://github.com/xiaoyuge/kingfish-python/tree/master/crawler/anjuke,或者关注我公众号:渝言家
4. 解析网页数据获取自己想要的结果
步骤四是对请求到的url数据,进行解析
Python提供了一些对html/xml格式内容进行解析的库,我使用的是bs4这个库。这个步骤就依赖于我们之前提到的第2步对网页元素的分析和探索了,我们需要根据我们对网页元素分析的结果,来决定这部分的代码我们怎么写。另外需要说明的是,因为网站可能会不定期进行升级,升级的过程中可能会改变网页的元素结构,因此,如果网站发生了升级,那我们原先写好的网页解析的代码很可能会不work了,可能需要根据升级后的网站元素结构重新开发。
比如获取刚才我们提到的房源标题信息的代码如下:
from bs4 import BeautifulSoup
#如果正常返回结果,开始解析
if r.status_code == 200:
content = r.text
soup = BeautifulSoup(content,'html.parser')
content_div_nodes = soup.find_all('div',class_='property-content')
for content_div_node in content_div_nodes:
#获取房产标题内容
content_title_name = content_div_node.find('h3',class_='property-content-title-name')
title_name = content_title_name.get_text()
......
获取其他数据的代码就不一一列举了,大同小异,关键就是根据第2步对网页元素分析的结果来帮助代码的编写。
5. 将结果数据保存到本地文件
通过对页面元素的解析,我们拿到了我们想要的数据,为了便于后续的数据分析,我们需要把数据保存到本地,在这里我将结果保存到了一个csv文件,用”;“做分割符:
with open('crawler/anjuke/data/suzhouSecondHouse.csv','a') as fout:
fout.write("%s;%s;%s;%s;%s;%s;%s;%s;%s;%s;%s;%s;%s;%s;%s;%s;%s;%s\n"%(title_name,datas_shi,datas_ting,datas_wei,square_num,square_unit,orientations,floor_level,build_year,housing_estate,district,town,road,tagstr,total_price,total_price_unit,avarage_price_num,avarage_price_unit))
总结
如上我们就完整的介绍了爬取一个网站所需要的步骤,以及每个步骤下具体需要干什么事情以及如何写Python代码。完整的代码可以从这个地址获取:https://github.com/xiaoyuge/kingfish-python/tree/master/crawler/anjuke
但是,爬取网站拿到数据并不是目的,我们真正的目的是对数据进行处理和分析,并进行可视化的展现生成数据报告,才能应付我朋友老板的差事。
看来,我们的任务还没有完成,我朋友还不能安心的喝咖啡,下一篇我们来讲一下如何对数据进行分析并生成好看又好用的数据报告,感兴趣的朋友可以关注我的公众号:渝言家。我是一个有着十多年经验的资深技术开发和技术管理者,历经互联网大厂和创业公司,在我的公众号里,我会和大家一起聊聊对技术、管理、产品和行业的洞见。