
二值化网络如何训练?这篇ICML 2021论文给你答案
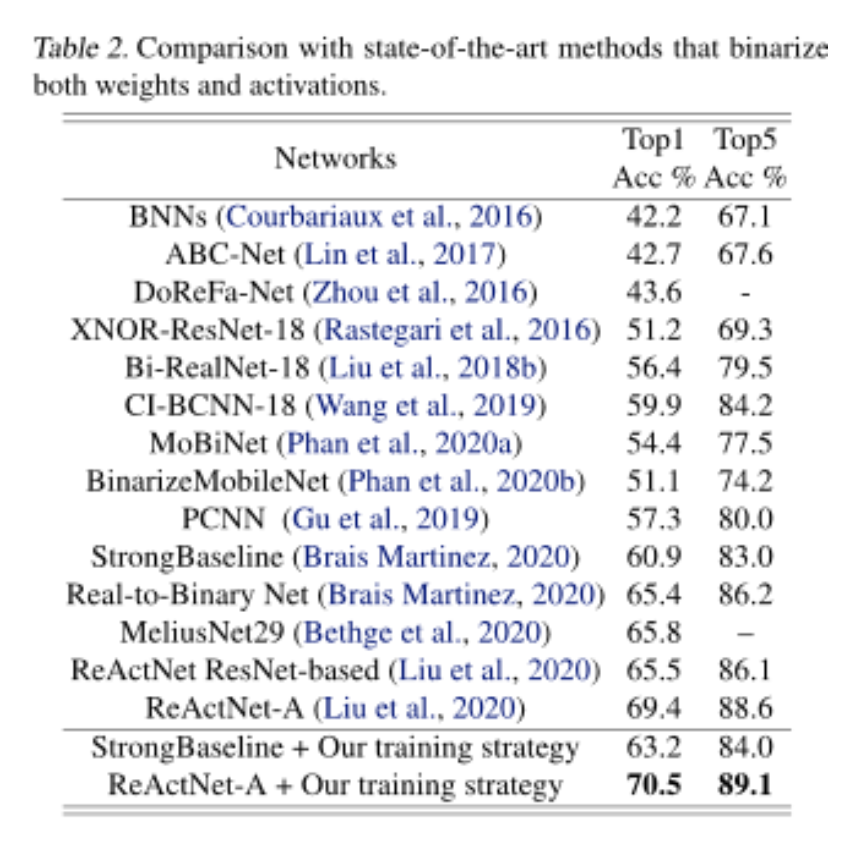
这篇来自 CMU 和 HKUST 科研团队的 ICML 论文,仅通过调整训练算法,在 ImageNet 数据集上取得了比之前的 SOTA BNN 网络 ReActNet 高1.1% 的分类精度。
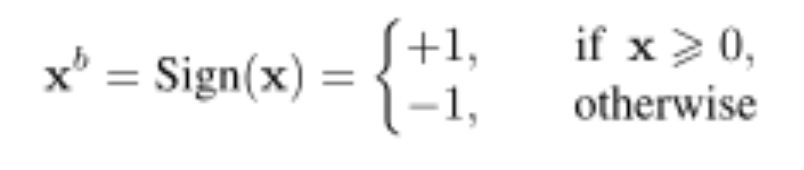
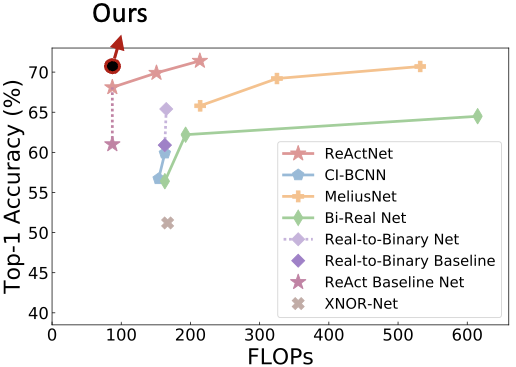

论文地址:https://arxiv.org/abs/2106.11309
代码地址:https://github.com/liuzechun/AdamBNN
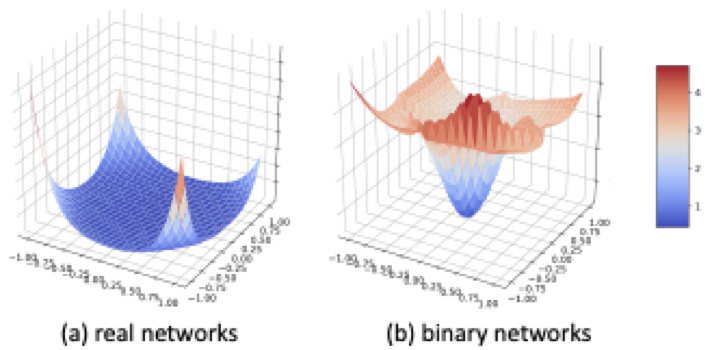
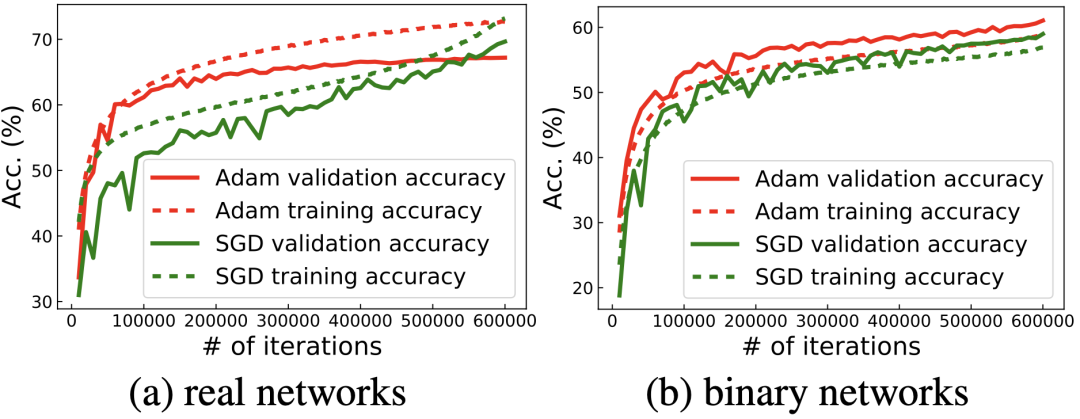
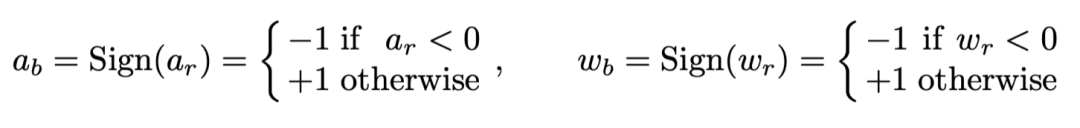
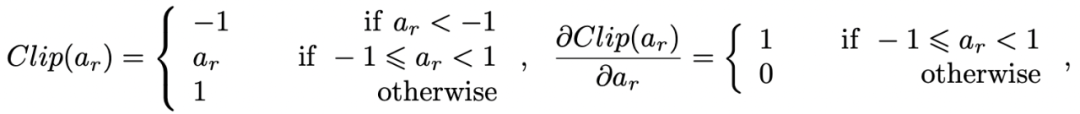
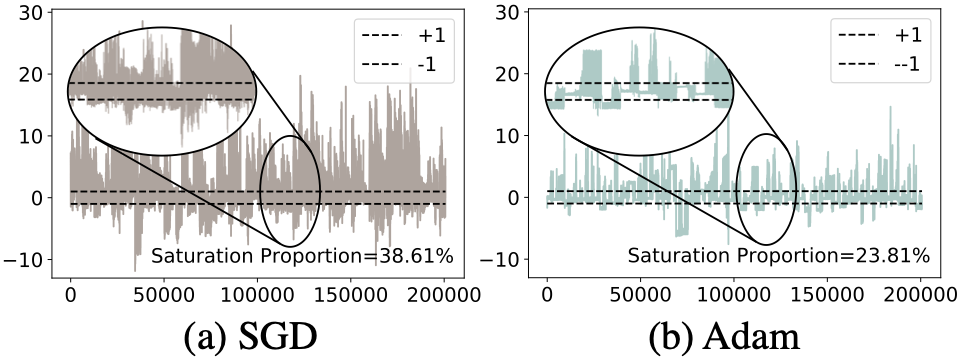
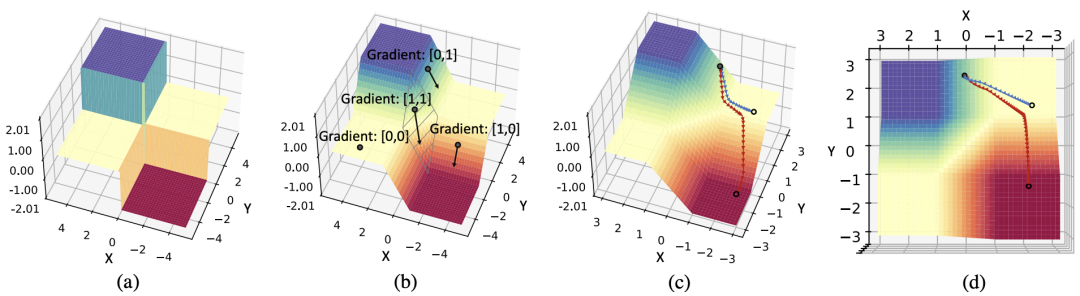
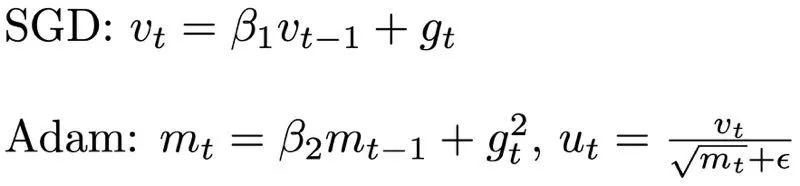
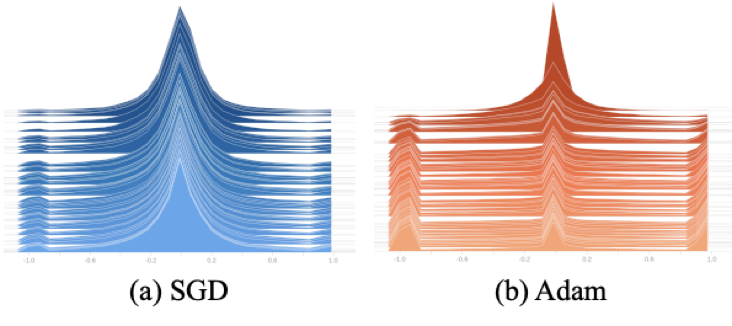
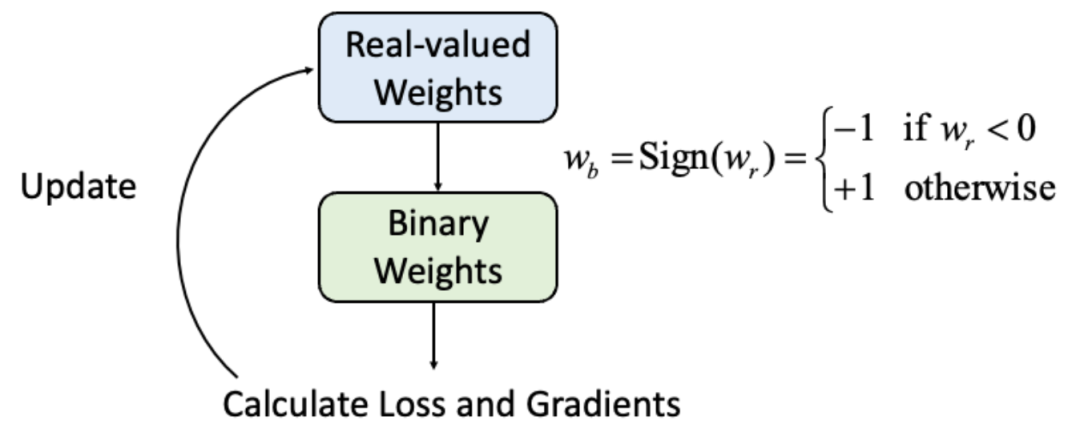
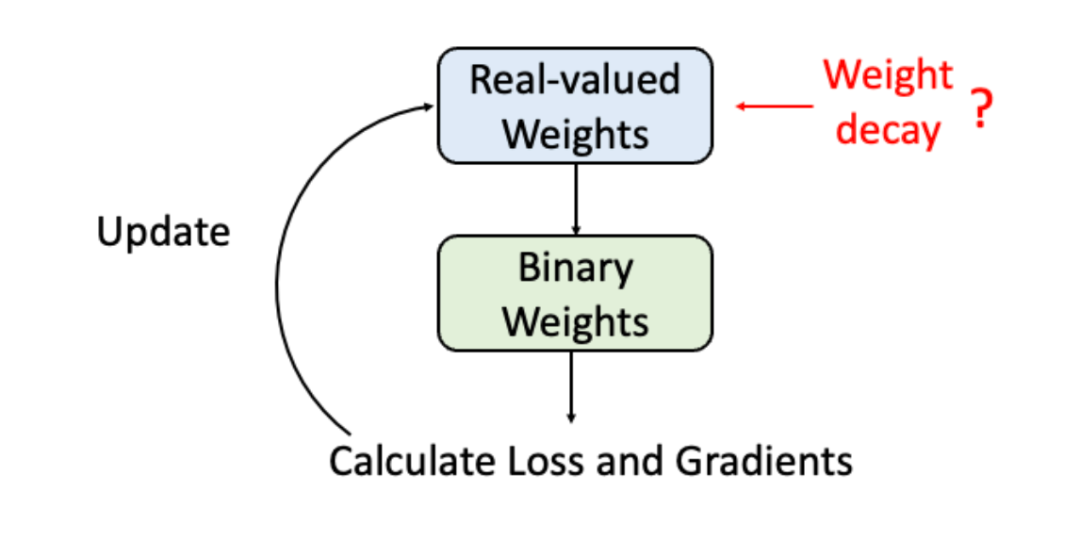

Helwegen, K., Widdicombe, J., Geiger, L., Liu, Z., Cheng, K.-T., and Nusselder, R. Latent weights do not exist: Rethinking binarized neural network optimization. In Advances in neural information processing systems, pp. 7531–7542, 2019.
Liu, Z., Wu, B., Luo, W., Yang, X., Liu, W., and Cheng, K.- T. Bi-real net: Enhancing the performance of 1-bit CNNs with improved representational capability and advanced training algorithm. In Proceedings of the European conference on computer vision (ECCV), pp. 722–737, 2018b.
Liu, Z., Shen, Z., Savvides, M., and Cheng, K.-T. Reactnet: Towards precise binary neural network with generalized activation functions. ECCV, 2020.
Brais Martinez, Jing Yang, A. B. G. T. Training binary neural networks with real-to-binary convolutions. Inter- national Conference on Learning Representations, 2020.
© THE END
转载请联系机器之心公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

点个在看 paper不断!