
(附论文&代码)ICML 2021 :二值化网络(BNN)究竟如何训练?
点击左上方蓝字关注我们

转载自 | AI科技评论
二值化网络(BNN)如下所示:
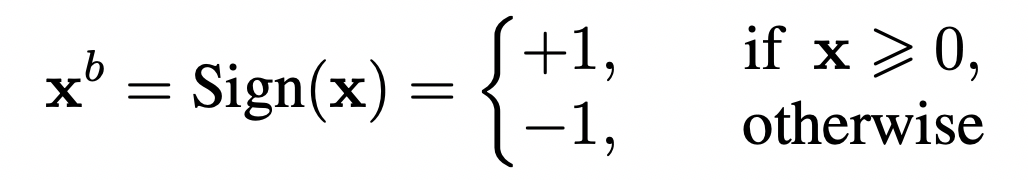
可以预料的是,这种极度的压缩方法在带来优越的压缩性能的同时,会造成网络精度的下降。
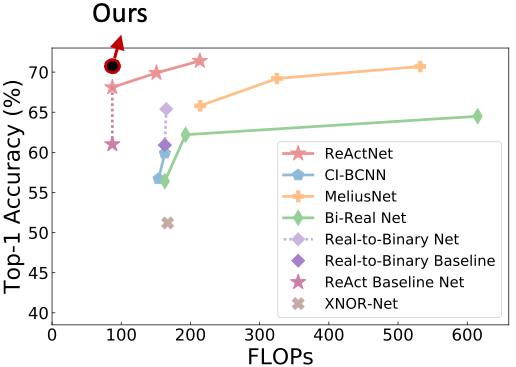
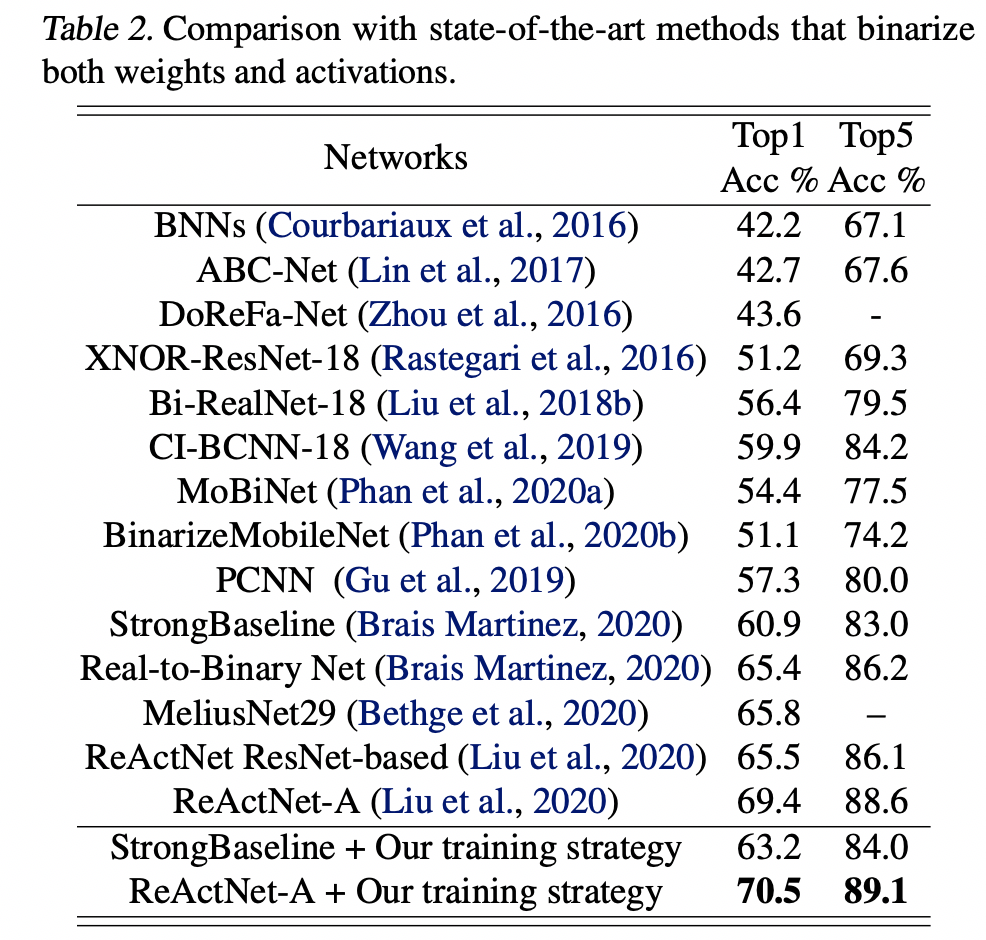
今天介绍的这篇最新来自CMU和HKUST科研团队的ICML 论文,仅通过调整训练算法就在ImageNet数据集上取得了比之前state-of-the-art 的BNN 网络 ReActNet 高1.1% 的分类精度,最终的top-1 accuracy达70.5%,超过了所有同等量级的二值化网络,如下图所示。

论文:https://arxiv.org/abs/2106.11309
代码:https://github.com/liuzechun/AdamBNN
这篇论文从二值化网络训练过程中的常见问题切入,一步步给出对应的解决方案,最后收敛到了一个实用化的训练策略。接下来就跟着这篇论文一起看看二值化网络(BNN)应该如何优化。
首先BNN的optimizer 应该如何选取?
可以看到,BNN的优化曲面明显不同于实数值网络,如下图所示。实数值网络在局部最小值附近有更加平滑的曲面,因此实数值网络也更容易泛化到测试集。相比而言,BNN的优化曲面更陡,因此泛化性差并且优化难度大。
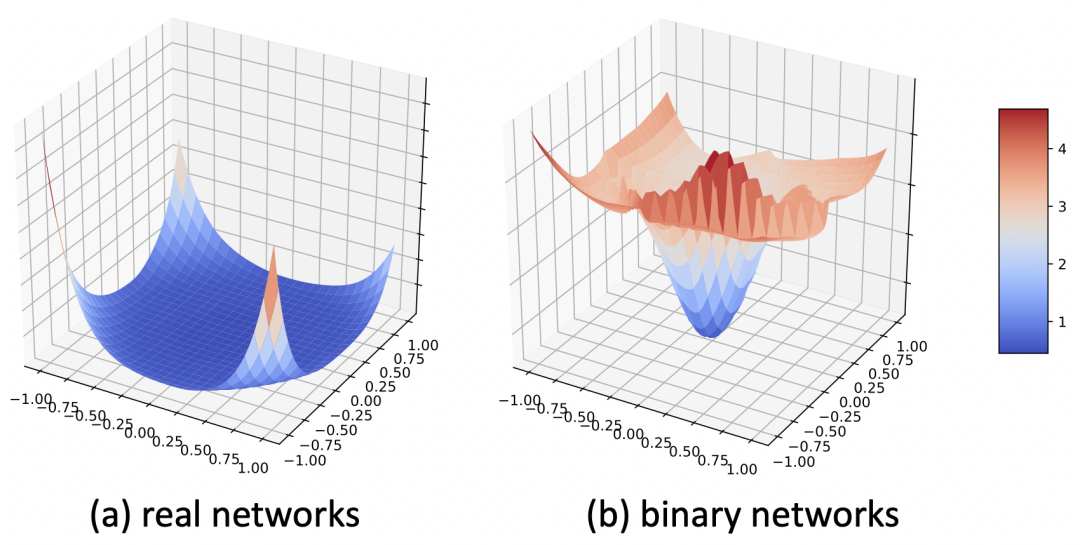
这个明显的优化区别也导致了直接沿用实数值网络的optimizer在BNN上表现效果并不好。目前实数值分类网络的通用optimizer都是SGD,该论文的对比实验也发现,对于实数值网络而言,SGD的性能总是优于自适应优化器Adam。但对于BNN而言,SGD的性能却不如Adam,如下图所示。这就引发了一个问题:为什么SGD在实数值分类网络中是默认的通用optimizer,却在BNN优化中输给了Adam呢?
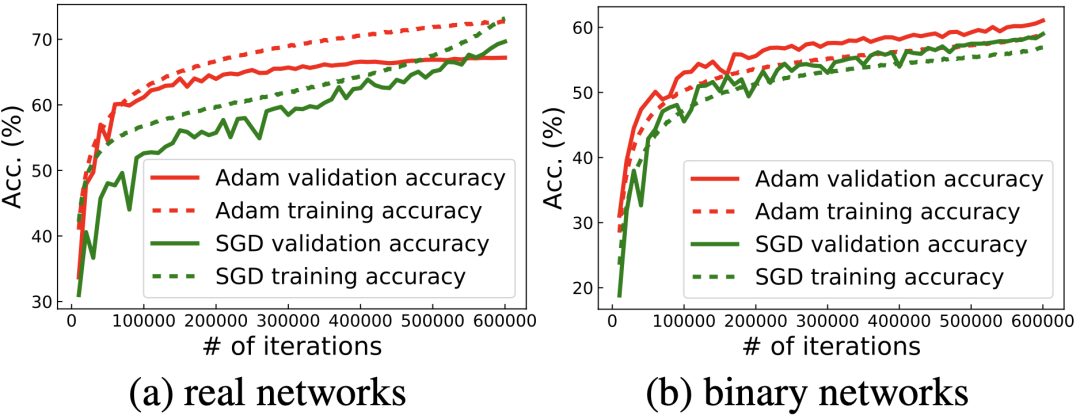
这就要从BNN的特性说起。因为BNN中的参数值(weight)和激活值(activation)都是二值化的,这就需要用sign 函数来把实数值的参数和激活值变成二值化。
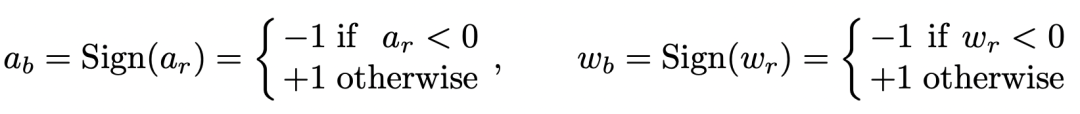
而这个Sign函数是不可导的,所以常规做法就是对于二值化的激活值用Clip函数的导数拟合Sign函数的导数。
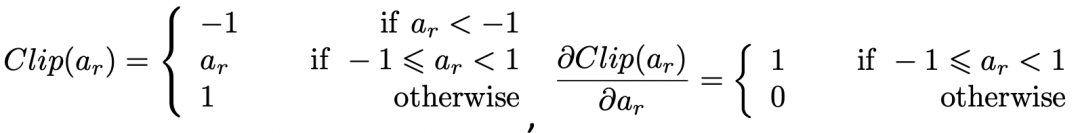
这样做有一个问题就是,当实数值的激活值超出了[-1,1]的范围,称为激活值过饱和(activation saturation),对应的导数值就会变为0。从而导致了臭名昭著的梯度消失(gradient vanishing)问题。从下图的可视化结果中可以看出,网络内部的激活值超出[-1, 1] 范围十分常见,所以二值化优化里的一个重要问题就是由于激活值过饱和导致的梯度消失,使得参数得不到充分的梯度估计来学习,从而容易困局部次优解里。
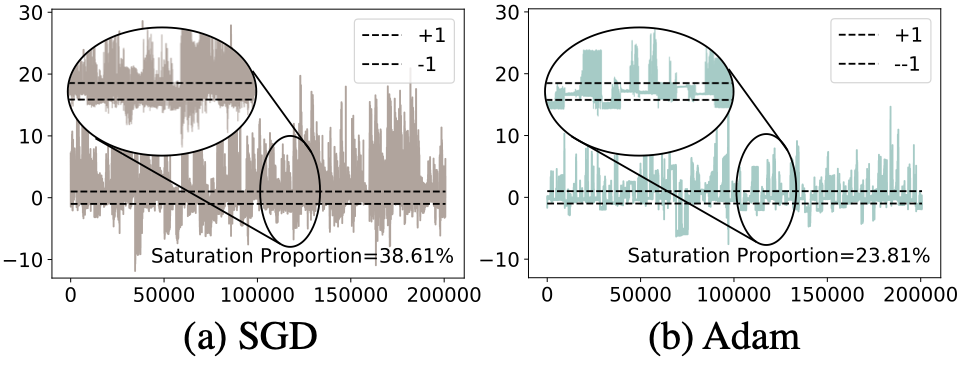
而比较SGD而言,Adam优化的二值化网络中激活值过饱和问题和梯度消失问题都有所缓解。这也是Adam在BNN上效果优于SGD的原因。
那么为什么Adam就能缓解梯度消失的问题呢?
这篇论文通过一个构造的超简二维二值网络分析来分析Adam和SGD 优化过程中的轨迹:
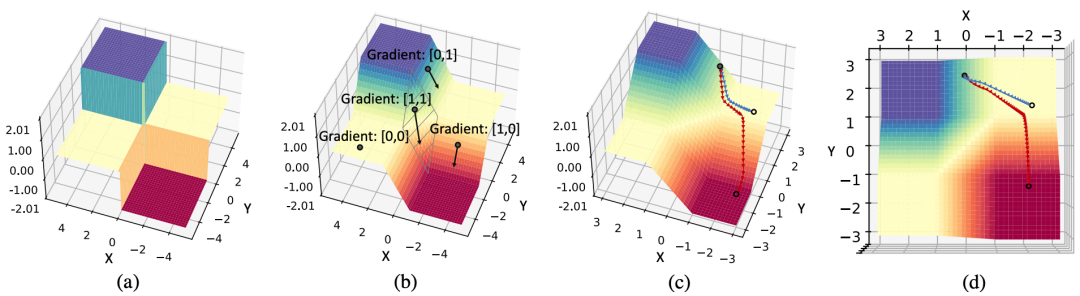
图中展示了用两个二元节点构建的网络的优化曲面。(a) 前向传递中,由于二值化函数 Sign的存在,优化曲面是离散的,(b) 而反向传播中,由于用了Clip(−1, x, 1)的导数近似Sign(x)的导数,所以实际优化的空间是由Clip(−1, x, 1)函数组成的, (c) 从实际的优化的轨迹可以看出,相比SGD,Adam 优化器更能克服零梯度的局部最优解,(d) 实际优化轨迹的顶视图。
在图(b)所示中,反向梯度计算的时候,只有当X 和 Y方向都落在[-1, 1] 的范围内的时候,才在两个方向都有梯度,而在这个区域之外的区域,至少有一个方向梯度消失。
而从下式的SGD与Adam 的优化方式比较中可以看出,SGD 的优化方式只计算first moment,即梯度的平均值,遇到梯度消失问题,对相应的参数的更新值下降极快。而在Adam中,Adam会累加second moment,即梯度的二次方的平均值,从而在梯度消失的方向,对应放大学习率,增大梯度消失方向的参数更新值。这样能帮助网络越过局部的零梯度区域达到更好的解空间。
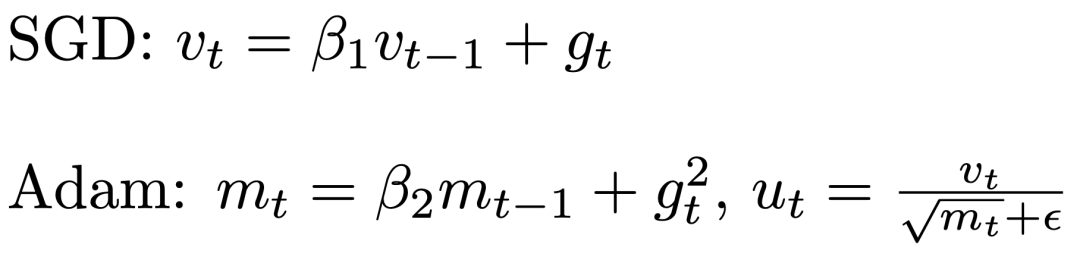
进一步,这篇论文展示了一个很有趣的现象,在优化好的BNN中,网络内部存储的用于帮助优化的实数值参数呈现一个有规律的分布:
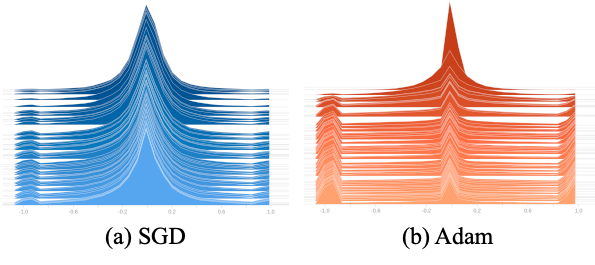
分布分为三个峰,分别在0附近,-1附近和1附近。而且Adam优化的BNN中实数值参数接近-1和1的比较多。这个特殊的分布现象就要从BNN中实数值参数的作用和物理意义讲起。BNN中,由于二值化参数无法直接被数量级为10^ -4左右大小的导数更新,所以需要存储实数值参数,来积累这些很小的导数值,然后在每次正向计算loss的时候取实数值参数的Sign作为二值化参数,这样计算出来的loss和导数再更新实数值参数,如下图所示。
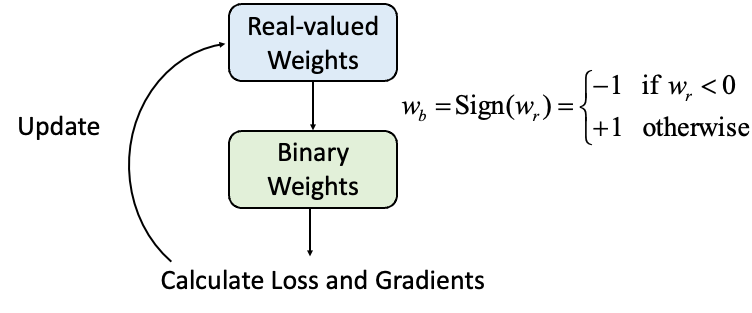
所以,当这些实数值参数靠近零值时,它们很容易通过梯度更新就改变符号,导致对应的二值化参数容易跳变。而当实值参数的绝对值较高时,就需要累加更多往相反方向的梯度,才能使得对应的二值参数改变符号。所以正如 (Helwegen et al., 2019) 中提到的,实值参数的绝对值的物理意义可以视作其对应二值参数的置信度。实值参数的绝对值越大,对应二值参数置信度更高,更不容易改变符号。从这个角度来看,Adam 学习的网络比 SGD实值网络更有置信度,也侧面印证了Adam 对于BNN而言是更优的optimizer。
当然,实值参数的绝对值代表了其对应二值参数的置信度这个推论就引发了另一个思考:应不应该在BNN中对实值参数施加weight decay?
在实数值网络中,对参数施加weight decay是为了控制参数的大小,防止过拟合。而在二值化网络中,参与网络计算的是实数值参数的符号,所以加在实数值参数上的weight decay并不会影响二值化参数的大小,这也就意味着,weight decay在二值化网络中的作用也需要重新思考。
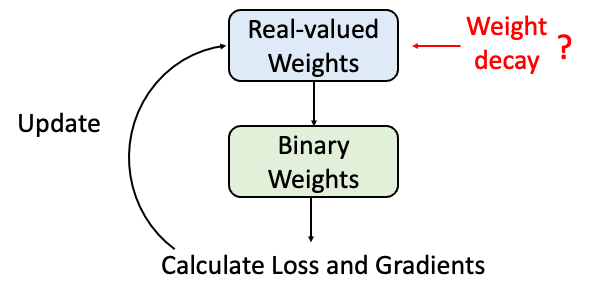
这篇论文发现,二值化网络中使用weight decay会带来一个困境:高weight decay会降低实值参数的大小,进而导致二值参数易变符号且不稳定。而低weight decay或者不加weight decay会使得二值参数将趋向于保持当前状态,而导致网络容易依赖初始值。
为了量化稳定性和初始值依赖性,该论文引入了两个指标:用于衡量优化稳定性的参数翻转比率(FF-ratio),以及用于衡量对初始化的依赖性的初始值相关度 (C2I-ratio)。
两者的公式如下:
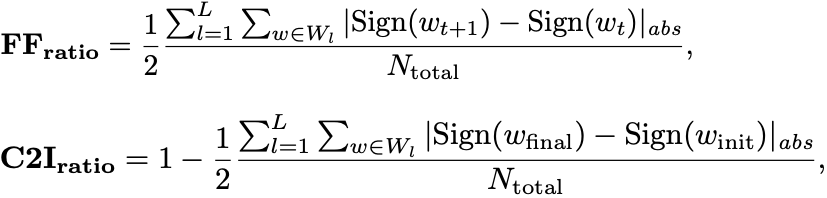
FF-ratio计算了在第 t 次迭代更新后多少参数改变了它们的符号,而 C2I -ratio计算了多少参数与其初始值符号不同。
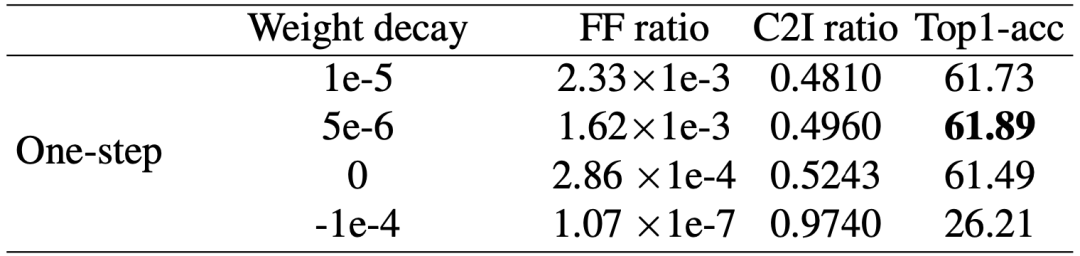
从下表的量化分析不同的weight decay对网络稳定性和初始值依赖性的结果中可以看出,随着weight decay的增加,FF-ratio与C2I-ratio的变化趋势呈负相关,并且FF-ratio呈指数增加,而C2I-ratio呈线性下降。这表明一些参数值的来回跳变对最终参数没有贡献,而只会影响训练稳定性。
那么weight decay带来的稳定性和初始值依赖性的两难困境有没有方法解离呢?该论文发现最近在ReActNet (Liu et al., 2020) 和Real-to-Binary Network (Brais Martinez, 2020) 中提出的两阶段训练法配合合适的weight-decay策略能很好地化解这个困境。
这个策略是,第一阶段训练中,只对激活值进行二值化,不二值化参数。由于实值网络不必担心二值化网络中的参数跳变带来的不稳定,可以添加weight decay来减小初始值依赖。随后在第二阶段训练中,二值化激活值和参数,同时用来自第一步训练好的参数初始化二值网络中的实值参数,不施加weight decay。
这样可以提高稳定性并利用预训练的良好初始化减小初始值依赖带来的弊端。通过观察FF-ratio和C2I-ratio,该论文得出结论,第一阶段使用5e-6的weight-decay,第二阶段不施加weight-decay效果最优。
该论文综合所有分析得出的训练策略,在用相同的网络结构的情况下,取得了比state-of-the-art ReActNet 超出1.1%的结果。
实验结果如下表所示。
更多的分析和结果可以参考原论文。
Reference:
Helwegen, K., Widdicombe, J., Geiger, L., Liu, Z., Cheng, K.-T., and Nusselder, R. Latent weights do not exist: Rethinking binarized neural network optimization. In Advances in neural information processing systems, pp. 7531–7542, 2019.
Liu, Z., Wu, B., Luo, W., Yang, X., Liu, W., and Cheng, K.- T. Bi-real net: Enhancing the performance of 1-bit CNNs with improved representational capability and advanced training algorithm. In Proceedings of the European conference on computer vision (ECCV), pp. 722–737, 2018b.
Liu, Z., Shen, Z., Savvides, M., and Cheng, K.-T. Reactnet: Towards precise binary neural network with generalized activation functions. ECCV, 2020.
Brais Martinez, Jing Yang, A. B. G. T. Training binary neural networks with real-to-binary convolutions. Inter- national Conference on Learning Representations, 2020.
END
整理不易,点赞三连↓