
前端工程师的一大神器:puppeteer
本文主要讲述一下Google出版并一直在不断维护的神器puppeteer,通过学习本文你将了解其基本使用和常用功能。
一、Puppeteer简介
Puppeteer 是一个 Node 库,它提供了一个高级 API 来通过 DevTools 协议控制 Chromium 或 Chrome,利用Puppeteer可以获取页面DOM节点、网络请求和响应、程序化操作页面行为、进行页面的性能监控和优化、获取页面截图和PDF等,利用该神器就可以操作Chrome浏览器玩出各种花样。
二、Puppeteer核心组成结构
Puppeteer的结构也反映了浏览器的结构,其核心结构如下所示:
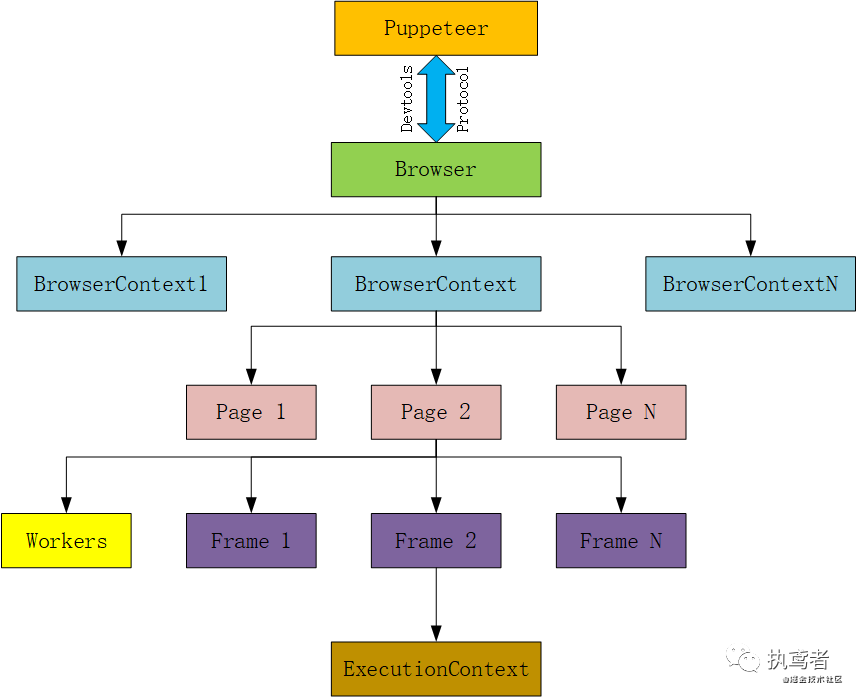 图片
图片- Browser:这是一个浏览器实例,可以拥有浏览器上下文,可通过 puppeteer.launch 或 puppeteer.connect 创建一个 Browser 对象。
- BrowserContext:该实例定义了一个浏览器上下文,可拥有多个页面,创建浏览器实例时默认会创建一个浏览器上下文(不能关闭),此外可以利用 browser.createIncognitoBrowserContext()创建一个匿名的浏览器上下文(不会与其它浏览器上下文共享cookie/cache).
- Page:至少包含一个主框架,除了主框架外还有可能存在其它框架,例如iframe。
- Frame:页面中的框架,在每个时间点,页面通过page.mainFrame()和frame.childFrames()方法暴露当前框架的细节。对于该框架中至少有一个执行上下文
- ExecutionCOntext:表示一个JavaScript的执行上下文。
- Worker:具有单个执行上下文,便于与 WebWorkers 交互。
三、基本使用和常用功能
该神器整体使用起来比较简单,下面就开始我们的使用之路。
3.1 启动Browser
核心函数就是异步调用puppeteer.launch()函数,根据相应的配置参数创建一个Browser实例。
const path = require('path');
const puppeteer = require('puppeteer');
const chromiumPath = path.join(__dirname, '../', 'chromium/chromium/chrome.exe');
async function main() {
// 启动chrome浏览器
const browser = await puppeteer.launch({
// 指定该浏览器的路径
executablePath: chromiumPath,
// 是否为无头浏览器模式,默认为无头浏览器模式
headless: false
});
}
main();
3.2 访问页面
访问页面首先需要创建一个浏览器上下文,然后基于该上下文创建一个新的page,最后指定要访问的网址。
async function main() {
// 启动chrome浏览器
// ……
// 在一个默认的浏览器上下文中被创建一个新页面
const page1 = await browser.newPage();
// 空白页访问该指定网址
await page1.goto('https://51yangsheng.com');
// 创建一个匿名的浏览器上下文
const browserContext = await browser.createIncognitoBrowserContext();
// 在该上下文中创建一个新页面
const page2 = await browserContext.newPage();
page2.goto('https://www.baidu.com');
}
main();
3.3 设备模拟
经常需要不同类型的机型的浏览结果,此时就可以采用设备模拟实现,下面模拟一个iPhone X的设备的浏览器结果
async function main() {
// 启动浏览器
// 设备模拟:模拟一个iPhone X
// user agent
await page1.setUserAgent('Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1')
// 视口(viewport)模拟
await page1.setViewport({
width: 375,
height: 812
});
// 访问某页面
}
main();
3.4 获取DOM节点
获取DOM节点有两种方式,一种方式是直接调用page所带的原生函数,另一种是通过执行js代码获取。
async function main() {
// 启动chrome浏览器
const browser = await puppeteer.launch({
// 指定该浏览器的路径
executablePath: chromiumPath,
// 是否为无头浏览器模式,默认为无头浏览器模式
headless: false
});
// 在一个默认的浏览器上下文中被创建一个新页面
const page1 = await browser.newPage();
// 空白页访问该指定网址
await page1.goto('https://www.baidu.com');
// 等待title节点出现
await page1.waitForSelector('title');
// 用page自带的方法获取节点
const titleDomText1 = await page1.$eval('title', el => el.innerText);
console.log(titleDomText1);// 百度一下
// 用js获取节点
const titleDomText2 = await page1.evaluate(() => {
const titleDom = document.querySelector('title');
return titleDom.innerText;
});
console.log(titleDomText2);
}
main();
3.5 监听请求和响应
下面就来监听一下百度中某一js脚本的请求和响应,request事件是监听请求,response事件是监听响应。
async function main() {
// 启动chrome浏览器
const browser = await puppeteer.launch({
// 指定该浏览器的路径
executablePath: chromiumPath,
// 是否为无头浏览器模式,默认为无头浏览器模式
headless: false
});
// 在一个默认的浏览器上下文中被创建一个新页面
const page1 = await browser.newPage();
page1.on('request', request => {
if (request.url() === 'https://s.bdstatic.com/common/openjs/amd/eslx.js') {
console.log(request.resourceType());
console.log(request.method());
console.log(request.headers());
}
});
page1.on('response', response => {
if (response.url() === 'https://s.bdstatic.com/common/openjs/amd/eslx.js') {
console.log(response.status());
console.log(response.headers());
}
})
// 空白页刚问该指定网址
await page1.goto('https://www.baidu.com');
}
main();
3.6 拦截某一请求
默认情况下request事件只有只读属性,不能够拦截请求,若想拦截该请求则需要通过page.setRequestInterception(value)启动请求拦截器,然后利用request.abort, request.continue 和 request.respond 方法决定该请求的下一步操作。
async function main() {
// 启动chrome浏览器
const browser = await puppeteer.launch({
// 指定该浏览器的路径
executablePath: chromiumPath,
// 是否为无头浏览器模式,默认为无头浏览器模式
headless: false
});
// 在一个默认的浏览器上下文中被创建一个新页面
const page1 = await browser.newPage();
// 拦截请求开启
await page1.setRequestInterception(true);// true开启,false关闭
page1.on('request', request => {
if (request.url() === 'https://s.bdstatic.com/common/openjs/amd/eslx.js') {
// 终止该请求
request.abort();
console.log('该请求被终止!!!');
}
else {
// 继续该请求
request.continue();
}
});
// 空白页访问该指定网址
await page1.goto('https://www.baidu.com');
}
main();
3.7 截图
截图是一个很有用的功能,通过截取就可以保存一份快照,方便后期问题的排查。(注:在无头模式下进行截图,否则截的图可能有问题)
async function main() {
// 启动浏览器,访问页面的操作
// 截屏操作,使用Page.screenshot函数
// 截取整个页面:Page.screenshot函数默认截取整个页面,加上fullPage参数就是全屏截取
await page1.screenshot({
path: '../imgs/fullScreen.png',
fullPage: true
});
// 截取屏幕中一个区域的内容
await page1.screenshot({
path: '../imgs/partScreen.jpg',
type: 'jpeg',
quality: 80,
clip: {
x: 0,
y: 0,
width: 375,
height: 300
}
});
browser.close();
}
main();
3.8 生成pdf
除了利用截图保留快照外,还可以使用pdf保留快照。
async function main() {
// 启动浏览器,访问页面的操作
// 根据网页内容生成pdf文件,使用Page.pdf——注意:必须在无头模式下才可以调用
await page1.pdf({
path: '../pdf/baidu.pdf'
});
browser.close();
}
main();
- EOF -
推荐阅读 点击标题可跳转觉得本文对你有帮助?请分享给更多人
推荐关注「前端大全」,提升前端技能
点赞和在看就是最大的支持❤️