
C++异步从理论到实践总览篇

作者:fangshen,腾讯 IEG 客户端开发工程师
C++20带来了coroutine特性, 同时新的execution也在提案过程中, 这两者都给我们在C++中解决异步问题带来了新的思路. 但对比其他语言的实现, C++的协程和后续的execution都存在一定的理解和封装成本, 本系列的分享我们将围绕基本的原理, 相应的封装, 以及剥析优秀的第三方实现, 最终结合笔者framework落地的情况来展开.
1. 纠结的开篇
之前设计我们游戏用的c++框架的时候, 刚好c++20的coroutine已经发布, 又因为是专门 给game server用的c++ framework, 对多线程的诉求相对有限, 或者本着少并发少奇怪的错误的原则, 除网络和IO和日志等少量模块外, 大部分模块主要还是工作在主线程上的, 所以当时设计的重点也就放在了c++20 coroutine的包装和使用上, 更多的使用coroutine来完善异步的支持. 但如果考虑到framework作为前后端公用框架的话, 原来主要针对主线程使用的包装的coroutine调度器就显得有些不够用, 以此作为基础, 我们开始了尝试结合比较新的c++异步思路, 来重新思考应该如何实现一个尽量利用c++新特性, 业务层简单易用的异步框架了.
本系列的主要内容也是围绕这条主线来铺开, 过程中我们 主要以:
自有的framework异步实现 - 主要落地尝试利用c++20的coroutine实现一个业务级的调度器. asio - 这个应该不用多说了, 近年来一直高频迭代, 业界广泛使用的开源第三方库, 中间的异步任务调度, 网络部分的代码实现都非常优质. libunifex - 最接近当前sender/receiver版 execution提案的可实操版本, c++17/20兼容, 但不推荐使用c++17的版本进行任何尝试, 原因后续文件会展开.
这几个库作为基础, 逐步展开我们对c++异步的探索, 然后再回到落地实践这条主线上, 探讨一个业务侧使用简单, 内部高效的异步库应该如何来实现并落地. 当然, 我们的侧重点主要还是c++异步的调度和处理上, 网络相关的有部分内容可能会简单提到, 但不会进行深入的展开.
其实整个尝试的过程只能说非常不顺利了, 当然, 随着对相关实现的深入理解和细节的深挖, 收益也是颇多的. 闲话不多说了, 我们直接切入主题, 以对异步的思考来展开这篇总览的内容.
2. 前尘往事 - rstudio framework实现
rstudio framework的异步框架由两块比较独立的部分组成:
一部分是源自asio几年前版本的post和strand部分实现, 另外附加了一些业务侧较常用的像Fence等对象; 另外一部分是主线程的协程调度器实现, 这部分最早是基于c++17实现的一版stackless 协程; 另外一版则是gcc11.1正式发布后, 直接用c++20重构了整个实现, 直接使用c++20的coroutine的一个版本.
2.1 asio 部分
这一部分的内容因为后续有asio scheduler实现具体的分析篇章, 这个地方主要以业务侧使用进行展开了.
2.1.1 executor概述
来源于1.6X boost同期的asio standalone版本 去除了各平台网络处理相关的代码 仅保留了post和相关的功能(新版本有executor实现) 早期c++11兼容, 无coroutine支持 除网络库外, asio非常有使用价值的一部分代码
2.1.2 一个简单的使用示例
GJobSystem->Post([]() {
//some calculate task here
//...
GJobSystem->Post(
[]() {
//task notify code here
//...
},
rstudio::JobSystemType::kLogicJob);
}, rstudio::JobSystemType::kWorkJob);
相关的时序图:
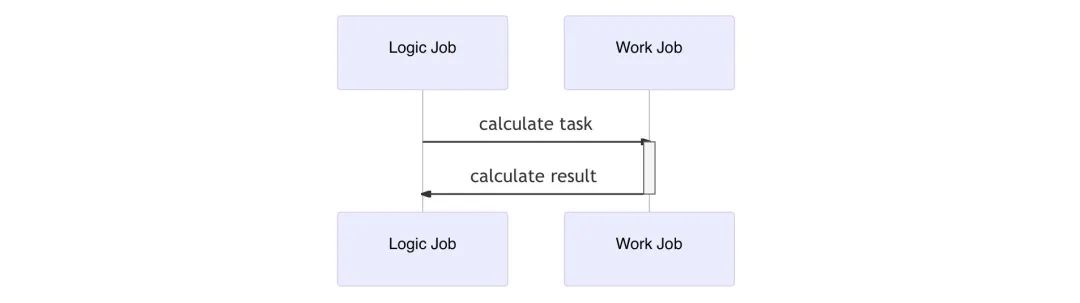
2.1.3 当前框架使用的线程结构
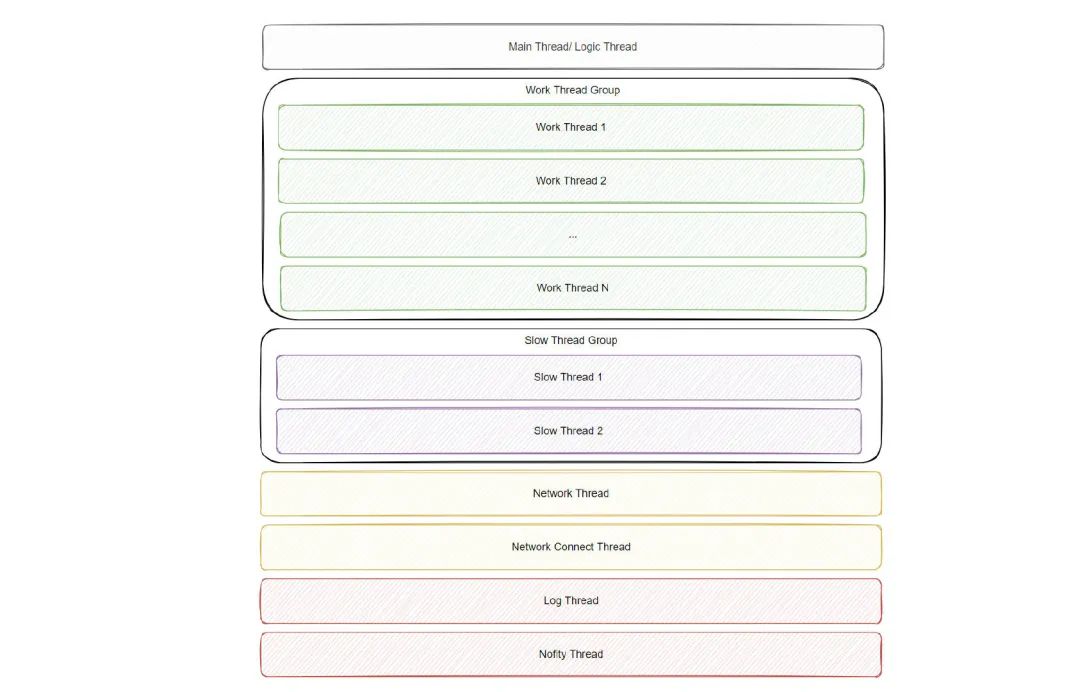
预定义的枚举值:
enum class JobSystemType : int {
kLogicJob = 0, // logic thread(main thread)
kWorkJob, // work thread
kSlowJob, // slow work thread(run io or other slow job)
kNetworkJob, // add a separate thread for network
kNetworkConnectJob, // extra connect thread for network
kLogJob, // log thread
kNotifyExternalJob, // use external process to report something, 1 thread only~~
kTotalJobTypes,
};
不同Job说明:
kLogicJob
主线程(逻辑线程)执行任务 kWorkJob
Work Thread线程池执行任务(多个), 一般是计算量可控的小任务 kSlowJob
IO专用线程池, IO相关的任务投递到本线程池 kNetworkJob
目前tbuspp专用的处理线程 kNetworkConnectJob
专用的网络连接线程, tbuspp模式下不需要 kLogJob
日志专用线程, 目前日志模块是自己起的线程, 可以归并到此处管理 kNotifyExternalJob
专用的通知线程, 如lua error的上报, 使用该类型
2.1.4 Timer任务相关
相关接口:
//NoIgnore version
uint64_t JobSystemModule::AddAlwaysRunJob(JobSystemType jobType,
threads::ThreadJobFunction&& periodJob,
unsigned long periodTimeMs);
uint64_t JobSystemModule::AddTimesRunJob(JobSystemType jobType,
threads::ThreadJobFunction&& periodJob,
unsigned long periodTimeMs,
unsigned int runCount);
uint64_t JobSystemModule::AddDelayRunJob(JobSystemType jobType,
threads::ThreadJobFunction&& periodJob,
unsigned long delayTimeMs);
void JobSystemModule::KillTimerJob(uint64_t tid);
本部分并未直接使用asio原始的basic_waitable_timer实现, 而是自己实现的定时任务.
2.1.5 在线程池上关联执行任务 - Strand
特定的情况下, 被派发到Work线程池的任务存在依赖关系
需要串联执行的时候, 这个时候我们需要额外的设施 JobStrand
来保证任务是按先后依赖关系来串行执行的
如下图中part1, part2, part3, part4串行执行的情况所示
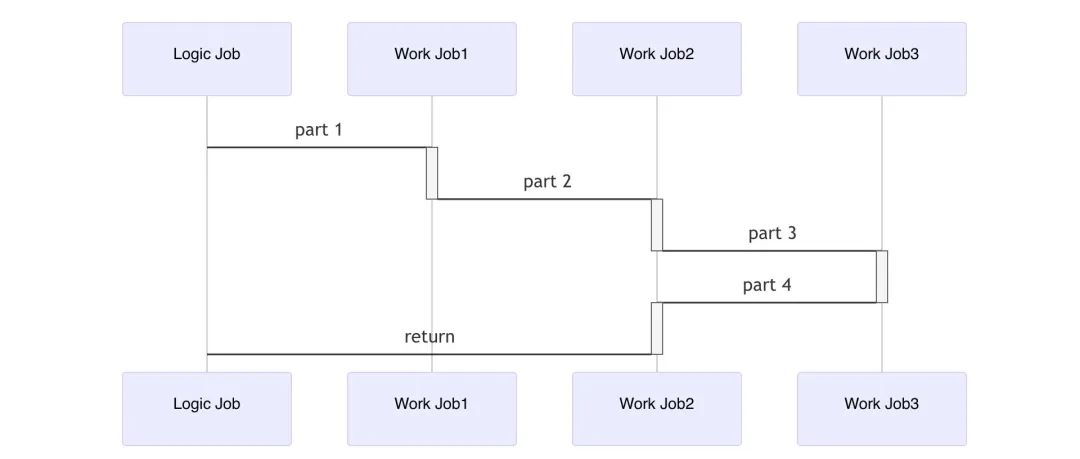
示例代码:
auto strand = GJobSystem->RequestStrand(rstudio::JobSystemType::kWorkJob);
starnd.Post([](){
//part1~
// ...
});
starnd.Post([](){
//part2~
// ...
});
starnd.Post([](){
//part3~
// ...
});
starnd.Post([](){
//part4~
// ...
});
starnd.Post([](){
GJobSystem->Post([](){
//return code here
// ...
}, rstudio::JobSystemType::kLogicJob);
});
2.1.6 其他辅助设施
JobFence
jobs::JobFencePtr JobSystemModule::RequestFence();
字面义, 栅栏, 起到拦截执行的作用. 一般多用于模块的初始化和结束 如tbuspp在kNetworkJob上的初始化和结束.
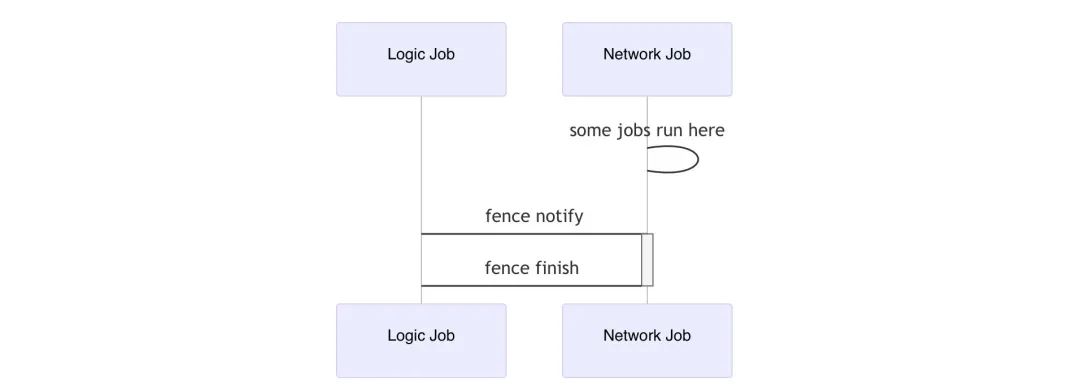
示例代码(TcpService的初始化):
job_system_module_->Post(
[this, workTicket]() {
if (!workTicket || workTicket->IsExpired()) return;
InitInNetworkThread();
},
JobSystemType::kNetworkJob);
period_task_ptr = job_system_module_->AddAlwaysRunJob(
JobSystemType::kNetworkJob,
[this, workTicket]() {
if (!workTicket || workTicket->IsExpired()) return;
LoopInNetworkThread();
},
10);
fence_->FenceTo((int)JobSystemType::kNetworkJob);
fence_->Wait();
JobNotify && JobWaiter
jobs::JobWaiterPtr JobSystemModule::RequestWaiter();
jobs::JobNotifyPtr JobSystemModule::RequestNotify();
批量任务管理使用 等待的方式的区别 JobNotify: 执行完成调用额外指定的回调. JobWaiter: 以Wait的方式在特定线程等待所有Job执行完成.
JobTicket
jobs::JobTicketPtr JobSystemModule::RequestTicket();
令牌对象 一般用来处理跨线程的生命周期控制 回调之前先通过IsExpired()来判断对应对象是否已经释放
示例代码:
GJobSystem->Post(
[this, workTicket]() {
if (!workTicket || workTicket->IsExpired()) return;
InitInNetworkThread();
},
JobSystemType::kNetworkJob);
2.2 asio 与其他实现的对比
正好今年的GDC上有一个<<One Frame In Halo Infinite>>的分享, 里面主要讲述的是对Halo Infinite的引擎升级, 提供新的JobSystem和新的动态帧的机制来支撑项目的, 我们直接以它为例子来对比一下framework和Halo的实现, 并且也借用Halo Infinite的例子, 来更好的了解这种lambda post模式的缺陷, 以及可以改进的点.
Halo引入新的JobSystem主要是为了将老的Tetris结构的并发模式:
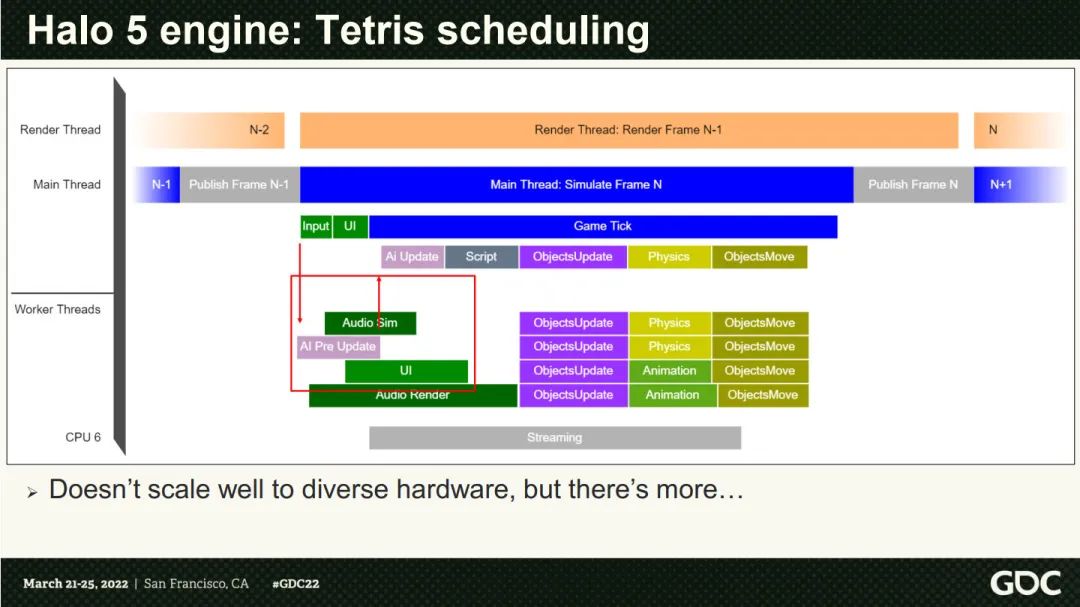
向新的基于Dependency的图状结构迁移: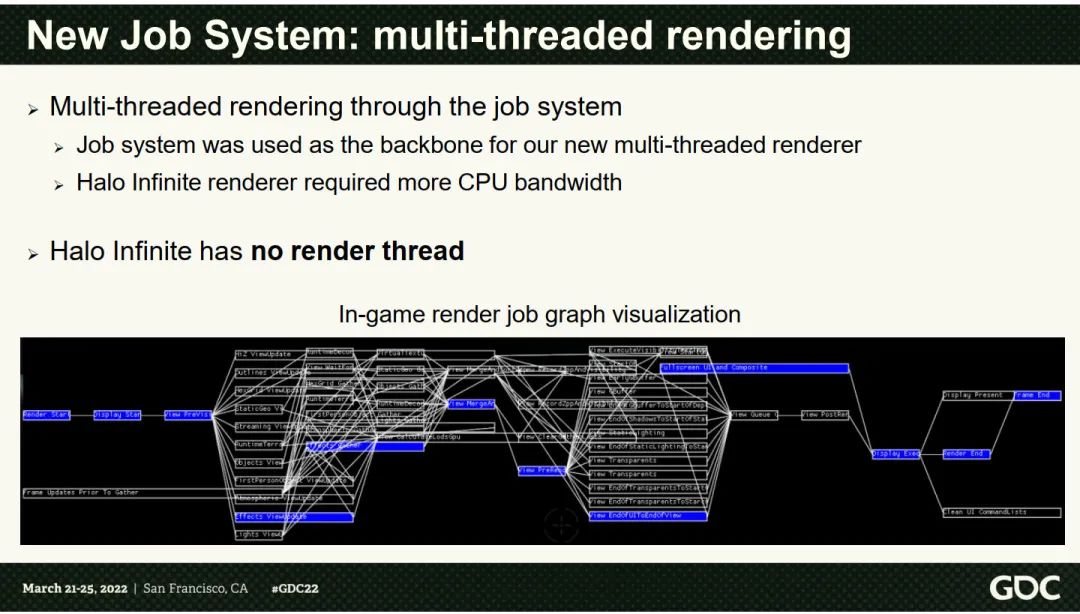
他使用的JobSystem的业务Api其实很简单, 我们直接来看一下相关的代码:
JobSystem& jobSsytem = JobSystem::Get();
JobGraphHandle graphHandle = jobSystem.CreateJobGraph();
JobHandle jobA = jobSystem.AddJob(
graphHandle,
"JobA",
[](){...} );
JobHandle jobB = jobSystem.AddJob(
graphHandle,
"JobB",
[](){...} );
jobSystem.AddJobToJobDependency(jobA, jobB);
jobSystem.SubmitJobGraph(graphHandle);
通过这样的机制, 就很容易形成如: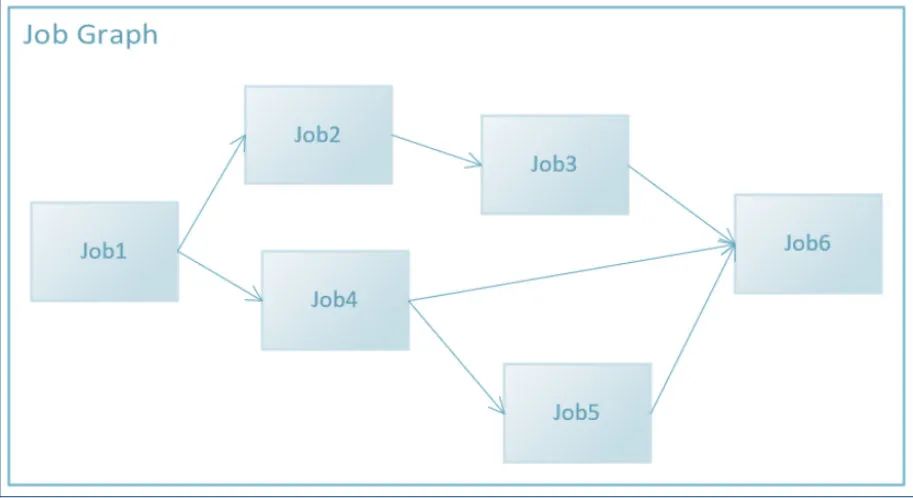
另外还有一个用于同步的SyncPoint:
JobSystem& jobSystem = JobSystem::Get();
JobGraphHandle graphHandle = jobSystem.CreateJobGraph();
SyncPointHandle syncPointX = jobSystem.CreateSyncPoint(graphHandle, "SyncPointX");
JobHandle jobA = jobSystem.AddJob(graphHandle, "JobA", [](){...});
JobHandle jobB = jobSystem.AddJob(graphHandle, "JobB", [](){...});
jobSystem.AddJobToSyncPointDependency(jobA, syncPointX);
jobSystem.AddSyncPointToJobDependency(syncPointX, jobB);
jobSystem.SubmitJobGraph(graphHandle);
大致的作用如下:
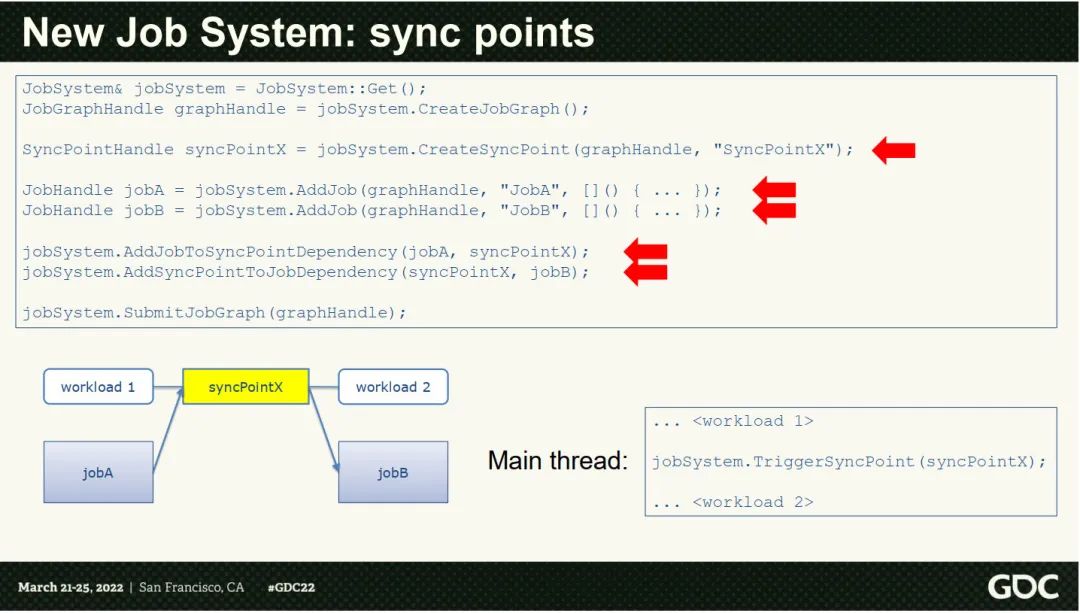
这样在workload主动触发SyncPoint后, 整体执行才会继续往下推进, 这样就能方便的加入一些主动的同步点对整个Graph的执行做相关的控制了。
回到asio, 我们前面也介绍了, 使用strand和post(), 我们也能很方便的构造出Graph形的执行情况 , 而SyncPoint其实类型framework中提供的Event, 表达上会略有差异, 但很容易看出两套实现其实是相当类同的. 这样的话, Halo 的JobSystem有的所有优缺点, framework基本也同样存在了, 这里简单搬运一下:

对于复杂并发业务的表达以lambda内嵌为主, 虽然这种方式尽可能保证所有代码上下文是比较集中的, 对比纯粹使用callback的模式有所进步, 但这种自由度过高的方式本身也会存在一些问题, 纯粹靠编码者来维系并发上下文的正确性, 这种情况下状态值在lambda之间的传递也需要特别的小心, 容易出错, 并且难以调试。
2.3 coroutine实现部分
coroutine部分之前的帖子里已经写得比较详细了, 这里仅给出链接以及简单的代码示例:
如何在C++17中实现stackless coroutine以及相关的任务调度器 C++20 Coroutine实例教学 另外还有一个purecpp大会的演讲视频, 主要内容与上述的两篇文章相关度比较高, 这里也给出相关的链接, 感兴趣的同学可以自行观看:C++20 coroutine原理与应用
代码示例:
//C++ 20 coroutine
auto clientProxy = mRpcClient->CreateServiceProxy("mmo.HeartBeat");
mScheduler.CreateTask20([clientProxy]()
-> rstudio::logic::CoResumingTaskCpp20 {
auto* task = rco_self_task();
printf("step1: task is %llu\n", task->GetId());
co_await rstudio::logic::cotasks::NextFrame{};
printf("step2 after yield!\n");
int c = 0;
while (c < 5) {
printf("in while loop c=%d\n", c);
co_await rstudio::logic::cotasks::Sleep(1000);
c++;
}
for (c = 0; c < 5; c++) {
printf("in for loop c=%d\n", c);
co_await rstudio::logic::cotasks::NextFrame{};
}
printf("step3 %d\n", c);
auto newTaskId = co_await rstudio::logic::cotasks::CreateTask(false,
[]()-> logic::CoResumingTaskCpp20 {
printf("from child coroutine!\n");
co_await rstudio::logic::cotasks::Sleep(2000);
printf("after child coroutine sleep\n");
});
printf("new task create in coroutine: %llu\n", newTaskId);
printf("Begin wait for task!\n");
co_await rstudio::logic::cotasks::WaitTaskFinish{ newTaskId, 10000 };
printf("After wait for task!\n");
rstudio::logic::cotasks::RpcRequest
rpcReq{clientProxy, "DoHeartBeat", rstudio::reflection::Args{ 3 }, 5000};
auto* rpcret = co_await rpcReq;
if (rpcret->rpcResultType == rstudio::network::RpcResponseResultType::RequestSuc) {
assert(rpcret->totalRet == 1);
auto retval = rpcret->retValue.to<int>();
assert(retval == 4);
printf("rpc coroutine run suc, val = %d!\n", retval);
}
else {
printf("rpc coroutine run failed! result = %d \n", (int)rpcret->rpcResultType);
}
co_await rstudio::logic::cotasks::Sleep(5000);
printf("step4, after 5s sleep\n");
co_return rstudio::logic::CoNil;
} );
执行结果:
step1: task is 1
step2 after yield!
in while loop c=0
in while loop c=1
in while loop c=2
in while loop c=3
in while loop c=4
in for loop c=0
in for loop c=1
in for loop c=2
in for loop c=3
in for loop c=4
step3 5
new task create in coroutine: 2
Begin wait for task!
from child coroutine!
after child coroutine sleep
After wait for task!
service yield call finish!
rpc coroutine run suc, val = 4!
step4, after 5s sleep
整体来看, 协程的使用还是给异步编程带来了很多便利, 但框架本身的实现其实还是有比较多迭代优化的空间的:
asio的调度部分与coroutine部分的实现是分离的 coroutine暂时只支持主线程
2.4 小结
上面也结合halo的实例说到了一些限制, 那么这些问题有没有好的解决办法了, 答案是肯定的, 虽然execution并未完全通过提案, 但整体而言, execution新的sender/reciever模型, 对于解决上面提到的一些缺陷, 应该是提供了非常好的思路, 我们下一章节中继续展开.
3. so easy - execution就是解?
最开始的想法其实比较简单, 结合原来的framework, 适当引入提案中的execution一些比较可取的思路, 让framework的异步编程能更多的吸取c++新特性和execution比较高级的框架抽象能力, 提升整个异步库的实现质量. 所以最开始定的主线思路其实是更多的向execution倾斜, 怎么了解掌握execution, 怎么与现在的framework结合成了主线思路.
我们选择的基础参考库是来自冲元宇宙这波改名的Meta公司的libunifex, 客观来说, Meta公司的folly库, 以及libunifex库的实现质量, 肯定都是业界前沿的, 对c++新特性的使用和探索, 也是相当给力的. 这些我们后续在分析libunifex具体实现的篇章中也能实际感受到.
但深入了解libunifex后, 我们会发现, 它的优点有不少:
尝试为c++提供表达异步的框架性结构. 泛型用得出神入化, ponder在它前面基本是小弟级别的, 一系列泛用性特别强的template 编程示例, 比如隐含在sender/receiver思路内的lazy evaluate表达, 如何在大量使用泛型的情况下提供业务定制点等等. 结构化的表达并发和异步, 相关代码的编写从自由发挥自主把控走向框架化, 约束化, 能够更有序更可靠的表达复杂异步逻辑 整个执行pipeline的组织, 所有信息是compile time和runtime完备的, dependencies不会丢失. 节点之间的值类型是强制检查的, 有问题的情况 , 大多时候compiler time就会报错.
有不少优点的同时, 也有很多缺点:整个库的实现严重依赖了c++20 ranges采用的一种定制手段 cpo, 并且也使用了类似ranges的pipe表达方法, 理解相关代码存在一定的门坎.(后续会有具体的篇章展开相关的内容) 库同时向下兼容了c++17, 但由于c++17本身特性的限制, 引入了大量的宏, 以及X Macros展开的方式, 导致相关的代码阅读难度进一步提升. 但实际上c++17版本并不具备可维护的价值, 依赖SIFINAE的实现, 如果中间任何一环报错, 必然需要在N屏的报错中寻找有效信息. libunifex对coroutine的支持存疑, 虽然让coroutine可以作为一种reciever存在, 但本质上来说, coroutine其实更适合拿来做流程控制的胶水, 而不是作为异步中的某个节点存在. 默认的scheduler实现质量离工业级还存在一定的距离, 这一点后续的代码分析中也会具体提到.
诸多问题的存在, 可能也是execution提案没有短时间内获得通过的原因吧, 但整体来说, execution本身的理念还是很有参考价值的, 但以它的现状来说, 离最终的解肯定还是有比较大的距离的.
4. 尝试重新思考 - 要什么, 用什么
事情到这个点就有点尴尬了, 原有的asio, 架构层面来说, 跟新的execution是存在落差的. 而项目实践上来说, asio相当稳扎稳打, 而以libunifex当前的状态来说, 离工业化使用其实是有一定距离的. 但asio作者在21年时候的两篇演讲(更像coding show):
Talking Async Ep1: Why C++20 is the Awesomest Language for Network Programming Talking Async Ep2: Cancellation in depth第一篇基本整个演示了asio从最开始的callback, 到融入c++20 coroutine后的优雅异步表达, 我们可以通过下面的代码片断感受一下:
asio相关示例代码1
awaitable<void> listen(tcp::acceptor& acceptor, tcp::endpoint target)
{
for (;;)
{
auto [e, client] = co_await acceptor.async_accept(use_nothrow_awaitable);
if (e)
break;
auto ex = client.get_executor();
co_spawn(ex, proxy(std::move(client), target), detached);
}
}
asio相关示例代码2
auto [e] = co_await server.async_connect(target, use_nothrow_awaitable);
if (!e)
{
co_await (
(
transfer(client, server, client_to_server_deadline) ||
watchdog(client_to_server_deadline)
)
&&
(
transfer(server, client, server_to_client_deadline) ||
watchdog(server_to_client_deadline)
)
);
}
对比原来每个async_xxx()函数后接callback的模式, 整个实现可以说是相当的优雅了, 代码的可读性也得到了极大的提高, 这两段代码都来自于上面的演讲中, 想深入了解的可以直接打开相关的链接观看视频, 很推荐大家去看一下.
能够把复杂的事情用更简洁易懂的方法表达, 这肯定是让人振奋的, 当然, 深入了解相关实现后, 也会发现存在一些问题, 但我们的本意是参考学习, 得出最终想要的可以比较好的支撑并发和异步业务的基础框架, 有这些, 其实已经可以理出一条比较清晰的思路了:
execution部分主要使用它的sender/receiver概念, 和它提供的一些通用的算法. 移除掉所有因为fallback c++17引入的大量代码噪声. 抛弃它并不完备的各种scheduler实现 协程借鉴部分asio的思路, 首先让协程可以基于context上下文, 在跨线程的情况下使用, 另外更多还是使用原有框架有明确的scheduler的方式对所有协程进行管理和定制的模式. 使用asio的scheduler部分作为execution的底层scheduler实现, 同时也使用asio的timer表达, 去除原始libunifex依赖不同scheduler提供schedule_at()方法来执行定时器相关逻辑的实现. 根据业务需要, 定制一些必要的sender adapter等简化业务的使用. 尝试用execution框架对接ISPC等特殊的并发库, 能够以一个清晰的方式来表达这种混合环境上执行的逻辑.
本系列涉及的基础知识和相关内容比较多, 先给出一个临时的大纲, 后续可能会有调整. 目前的思路是先介绍大家相对熟悉度不那么高的execution基础知识和libunifex, 后面再介绍asio相关的scheduler以及coroutine实现, 最后再回归笔者正在迭代的framework, 这样一个顺序来展开.
参考
One Frame in Halo Infinite asio官网 libunifex源码库