
CVPR2022| BodyMap可用于换装,Vision Transformers 又立功!
Updated on : 19 May 2022
total number : 1
BodyMap: Learning Full-Body Dense Correspondence Map
论文/Paper: http://arxiv.org/pdf/2205.09111
代码/Code: None
摘要
人类之间的密集对应承载了强大的语义信息,可用于解决全身理解的基本问题,例如自然场景下表面匹配、跟踪和重建。
在本文中,我们提出了 BodyMap,这是一个新的框架,用于在穿着衣服的人的自然图像和 3D 模板模型的表面之间获得高清全身和连续密集对应关系。对应关系涵盖手和头发等精细细节,同时捕捉远离身体表面的区域,例如宽松的衣服。用于估计这种密集表面对应关系的现有方法 i) 将 3D 身体切割成展开到 2D UV 空间的部分,沿部分接缝产生不连续性,或 ii) 使用单个表面来表示整个身体,但没有处理身体细节。
在这里,我们介绍了一种带有Vision Transformers的新型网络架构,它可以在连续的身体表面上学习精细级别的特征。BodyMap 在各种指标和数据集(包括 DensePose-COCO)上的表现大大优于先前的工作。此外,我们展示了各种应用,包括多层密集布对应、具有新视图合成的神经渲染和外观交换。
BodyMap 模型架构
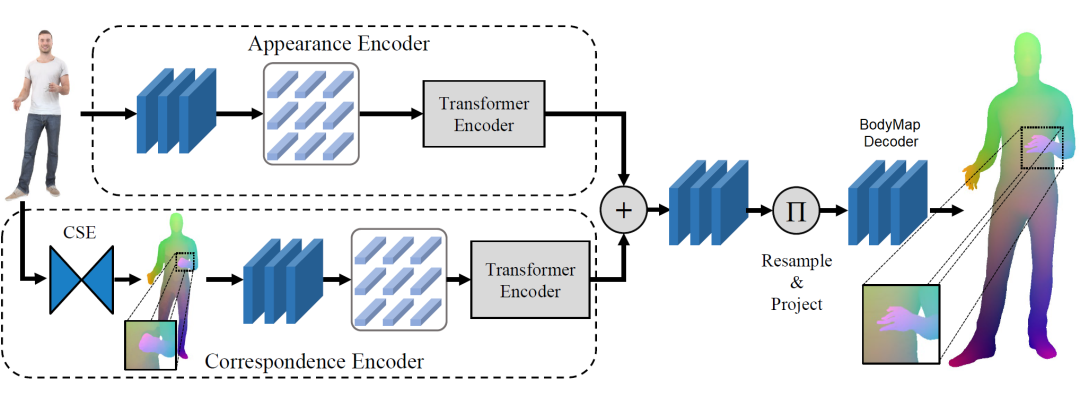
给定一个 RGB 图像作为输入,我们首先提取连续的表面嵌入 [1],然后将其馈送到视觉转换器。我们将这些特征与从各自的外观编码器中提取的特征相结合,并将它们馈送到解码器,该解码器以高精度为穿衣人体的每个像素建立密集的表面对应关系。
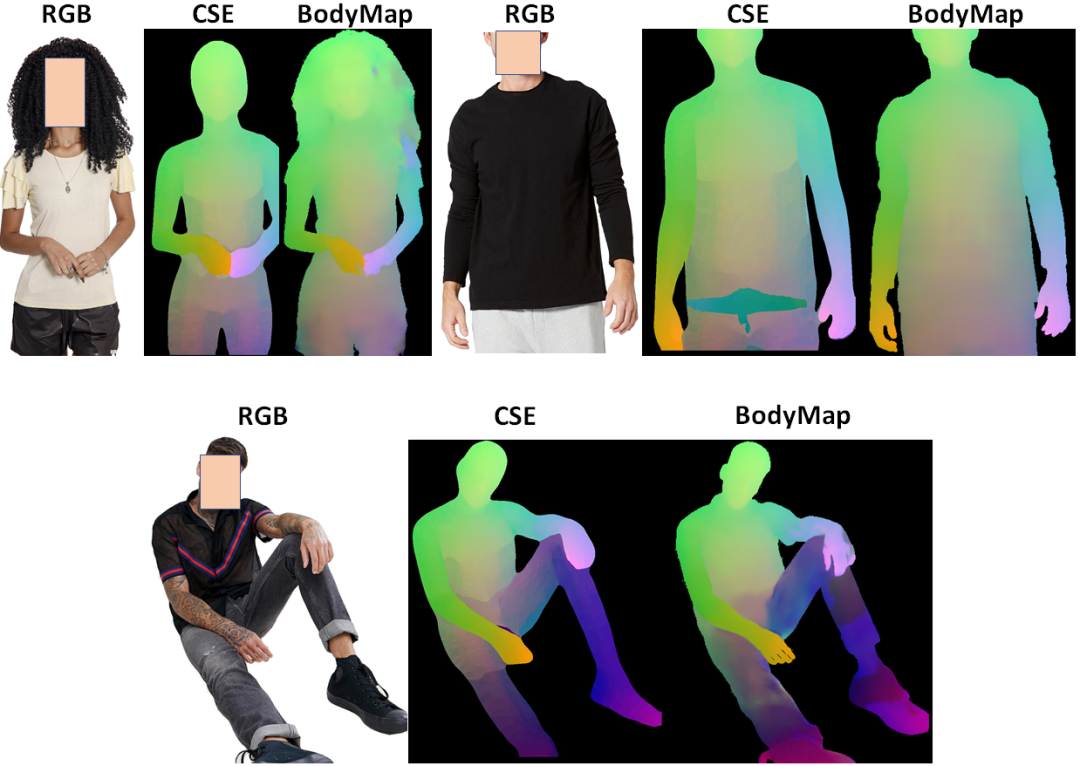
定性结果
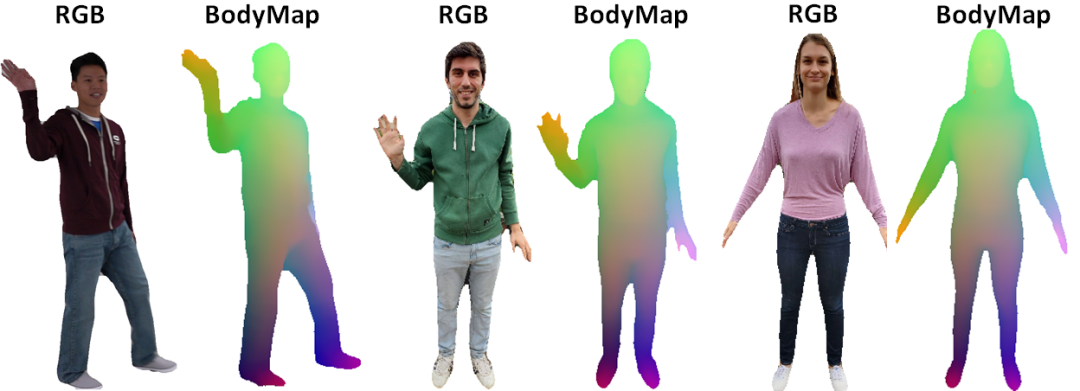
换装应用

评论