
如何开发一个自己的TensorFlow?
链接:https://www.zhihu.com/question/326890535
编辑:深度学习与计算机视觉

我的理解,如果只是为了训练一些具体的网络,不考虑扩展性,应该不是很难吧,tensorflow也是用了很多第三方的库。

作者:王潜升
https://www.zhihu.com/question/326890535/answer/719907717
介绍一下自己研一时的一个工作,当时花过几个月时间帮当时的论文指导老师写过深度学习框架N3LDG(主要实现了完整的GPU计算和计算图上的优化),整了篇中文论文http://xbna.pku.edu.cn/EN/abstract/abstract3327.shtml
当时测了几个典型的模型的GPU训练速度,论文中的表格:
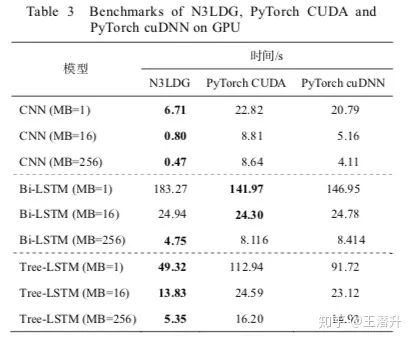
不过后来发现有个地方写错了,数据复制到gpu时没有异步,改掉后就都比pytorch快了。
我fork了一个完全由自己主导的版本:https://github.com/chncwang/N3LDG-plus
等有时间加上transformer和BERT的支持了,再整文档吧(其实到底该叫啥名也没想清楚,姑且称之为N3LDG++),目前主要就自己在用来做文本生成。
GPU计算的实现是相对麻烦的一部分。出于性能极致的追求(N卡很贵,计算速度怎么强调都不过分)和对自己代码负责的态度,当时算把CUDA彻底整明白了(除了图形学用的纹理内存),针对每种操作专门写了对应的CUDA,比如concat操作就能在一次kernel调用下完成一个batch里的多个不同维度输入向量的拼接:

这样最后出来的CNN就能比pytorch快不少。
其实模型训练时的时间包含两块:1) GPU计算时间和 2) 计算图的调度时间。现在多数深度学习框架采用eager evaluation,这么做就使框架没法对计算流程做优化(主要是自动批量化)。在多数模型中,手动批量化也许可行,但是面对树结构或者图结构时就会很麻烦。这时lazy evaluation就是更好的选择。然而计算图的规划是个NP难问题,只能通过一些启发式规则来找到近似解。论文里这一块follow的是dynet的工作,展开来讲有点麻烦,感兴趣的话可以看dynet的论文。
显存也需要操心。由于GPU离CPU远,不能像用malloc一样频繁地调cudaMalloc。当时不满cnmem的性能,就自己撸了个buddy system。显然这个做法不够精细,dynet的解决方案应该更合理,详见他们的论文。
提到显存,忍不住想多说几句。NLP任务和CV不一样,同个mini-batch中句子长短不一,pytorch会要求补零的操作以求维度对齐,往往还会有一个全局的max_sentence_length(哪怕是N3LDG也是如此),这其实很浪费显存。在N3LDG++中,如果一个mini-batch里的句子总长度是100,那么分配100长度的空间也就够用,减少了浪费。所以我计划有时间了支持下BERT,至少让base模型在1080ti里也能伸展开来,不怕OOM。只是不清楚大家都用啥显卡,这块的需求有多强。
然后说一下编程语言。主流的框架使用C++、CUDA实现底层的计算,然后用python实现上层的封装,似乎是兼顾了计算效率和使用方便。然而使用PyTorch时还是会发现CPU模式下的龟速。我自己没用过PyTorch,也不清楚CPU龟速的原因(也许是Python调用C++的额外开销?),只是每当看到实验室同学跑个几千的数据集就要用GPU,就觉得Python在深度学习界的流行抬高了英伟达的市值。
N3LDG++中的C++代码继承自N3LDG,不过做了很大的改动,难以细述,最大的一点是改进了Node类型的资源管理方式,所有的Node对象由Graph持有(比如在N3LDG中每多创建一个节点,都需要有相应的对象来持有,不能当作临时变量用,这很不方便)。不过历史遗留的代码还是有点乱,不少该抽象的地方没有抽象,以后慢慢改吧(唉纯算法背景写出的代码真是。。。)
最后,我觉得从0写一个可用的深度学习框架不难,但是工作量很大, 对人的要求也不高(但是多,不能光懂算法),主要以下几点:
编码能力过关,精通C++、CUDA、OO思想,以及能搞定一切的debug能力
编码习惯良好,比如重视变量命名
算法方面,会手算梯度就行
更新 一下,项目已经更名为InsNet,感兴趣的话求个star~
作者:刘冬煜
https://www.zhihu.com/question/326890535/answer/700281308首先需要熟练使用C++编程,其次学会cuda的GPU显卡计算框架,了解一下并行计算,写出比TensorFlow快的框架非常简单。毕竟TensorFlow为了可移植性等等牺牲了很多。
下图是我正在开发的一个闭源框架TenDPluS,名字中的Ten正是致敬TensorFlow:
部分代码
用下图网络结构:
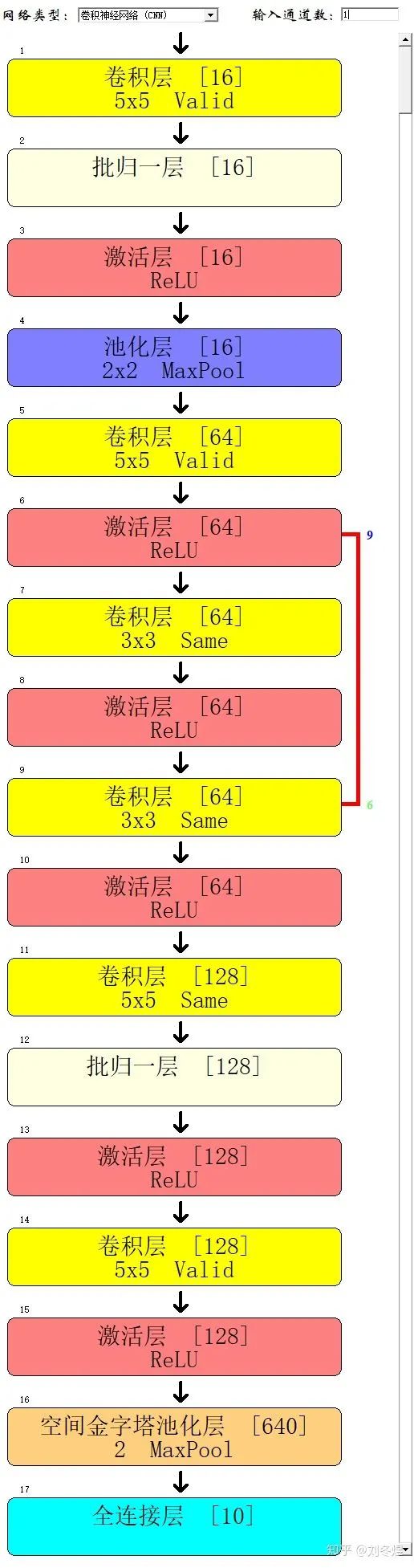
神经网络的结构
跑mnist,测试集正确率:
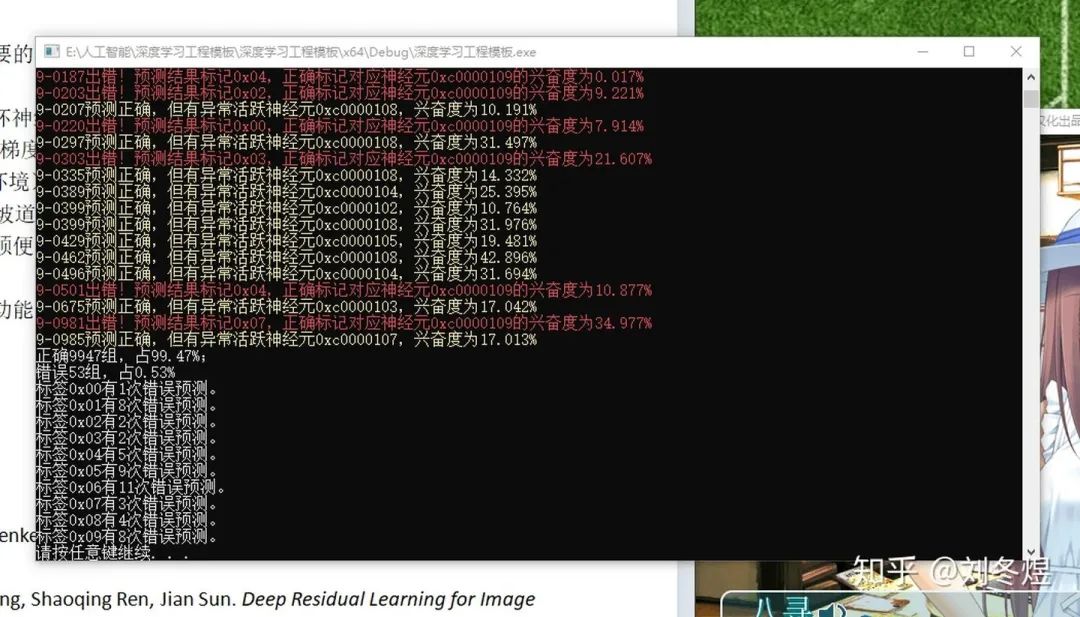
mnist的正确率
可以说,收敛速度、空间利用率和准确率都高于TensorFlow了。
同时还提供了特征可视化的接口:

一次演讲的ppt,下两图来自TenDPluS的特征可视化
我已经用自己的框架做了三四个项目了,由于干最底层的算法岗,自己这不成熟的框架已经能胜任几乎所有需求了。目前我正在对框架进行可视化的相应改进,力求能进一步突破TensorBoard。
作者:phantomrider https://www.zhihu.com/question/326890535/answer/718793714
TensorFlow没写过
写过一个小小的miniflow,用Python面相对象思维写的,将每一层写成一个类,然后每一个类里面有forward,backward两个函数
然后再用拓扑排序对整个神经网络进行forward和backpro操作
作者:匿名用户
https://www.zhihu.com/question/326890535/answer/827912517
我去,一个个都牛X成这个样子了?
1、现在网上tensorflow能源码级的,较清晰解读尚且没看到,不知道说不难的人自己有没有过过源码;
2、不要把手写一两种CNN网络的难度和一个大规模商用深度学习平台来比,不考虑各类具体算法实现,单单是工程层面的抽象、设计也不简单;
3、还有说tf里算法容易的,就想先请教一个小问题,Tensorflow里那种通用求导是如何实现的?别上网搜,想想能搞定不?
—版权声明—
仅用于学术分享,版权属于原作者。
若有侵权,请联系微信号:yiyang-sy 删除或修改!
—THE END—