
实现分布式锁
分布式锁的实现通常有三种方式,利用MySQL、zookeeper、Redis3种组件实现。
MySQL实现
通过MySQL实现分布式锁相对来说比较好理解,主要思路就是通过主键自增长属性来实现,通常也叫AUTO-INC Locking自增长锁。在InnnoDB存储引擎的内存结构中,对每个含有自增长值的表都有一个自增长计数器(auto increment counter)。当含有自增长计数器的表进行插入操作时,这个计数器会被初始化,执行如下的语句来得到计数器的值:
select MAX(auto_inc_col) from t for update;插入操作会依据这个自增长的计数器值+1赋予自增长序列,这个实现方式称作AUTO-INC Locking。这种锁其实是采用一种特殊的表锁机制,为了提高插入性能,锁不是在一个事物完成后才释放的,而是在完成对自增长序列插入的SQL语句后立即释放。
通过伪代码模拟实现过程:
参考链接:https://juejin.cn/post/6844903688088059912
对于分布式锁我们可以创建一个锁表:

实现逻辑
为了达到可重入锁的效果那么我们应该先进行查询,如果有值,那么需要比较node_info是否一致,这里的node_info可以用机器IP和线程名字来表示,如果一致那么就加可重入锁count的值,如果不一致那么就返回false。如果没有值那么直接插入一条数据。需要注意的是这一段代码需要加事务,必须要保证这一系列操作的原子性。

阻塞式获取锁
如果获取不到就睡眠3ms,继续获取直到拿到锁。

非阻塞式获取锁
如果获取不到那么就会马上返回

释放锁
unlock的话如果这里的count为1那么可以删除,如果大于1那么需要减去1。

总结
适用场景: Mysql分布式锁一般适用于资源不存在数据库,如果数据库存在比如订单,那么可以直接对这条数据加行锁,不需要我们上面多的繁琐的步骤,比如一个订单,那么我们可以用select * from order_table where id = 'xxx' for update进行加行锁,那么其他的事务就不能对其进行修改。
优点:理解起来简单,不需要维护额外的第三方中间件(比如Redis,Zk)。
缺点:虽然容易理解但是实现起来较为繁琐,需要自己考虑锁超时,加事务等等。性能局限于数据库,一般对比缓存来说性能较低。对于高并发的场景并不是很适合。
Zookeeper实现
利用zookeeper的相同路径下的节点不能重名的特性和自带的监听机制。zookeeper有三类节点:
持久性节点:只要创建了节点,无论客户端是否断开链接,节点都会存在。
临时性节点:一旦客户端断开链接,服务端不再保存该节点。
顺序性节点:在创建节点的时候,zookeeper会自动给节点分配自增长编号,比如/lock/node_000001、/lock/node_000002等。
/lock是我们用于加锁的目录,/resource是我们锁定的资源,其下面的节点按照我们加锁的顺序排列。
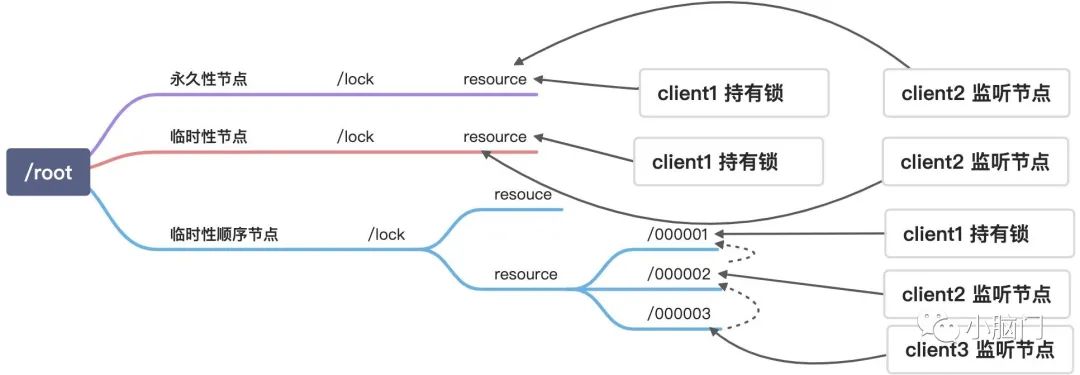
通过持久性节点实现分布式锁
实现步骤
step1:client1创建了resource节点,创建成功即代表持有了锁,client2再去创建resource节点时就会失败,这个时候只能监听这个节点的变化。
step2:client1处理完业务后,删除resource节点;client2得到通知后再去创建resource节点,获取锁。(多个client会并发的去竞争创建resource节点)
缺点
当client1挂掉后没能删除resource,那么就出现了死锁。
存在惊群效应,当client很多时,只有一个client持有锁,其他所有client都要监听这一个resource节点。
通过临时性节点实现分布式锁
临时节点和永久节点的实现方式一样,只不过在client1挂掉后,zookeeper会自动删除resource节点,相当于强制释放了锁。这样就不会出现死锁的风险了。虽然临时性节点解决了死锁的问题,但是没能解决鲸群效应问题。
通过临时性顺序节点实现分布式锁
在resource锁资源下按照获取锁的顺序为每个client维护一个临时性的顺序节点,每个节点只需要监听前一个节点状态,这样只有前一个节点被删除后,后面的监听节点就可以创建resource/xxxxx资源了。这样就解决了惊群效应锁带来的问题了。
Curator
Curator封装了Zookeeper底层的Api,使我们更加容易方便的对Zookeeper进行操作,并且它封装了分布式锁的功能,这样我们就不需要再自己实现了。
Curator实现了可重入锁(InterProcessMutex),也实现了不可重入锁(InterProcessSemaphoreMutex)。在可重入锁中还实现了读写锁。
Redis实现
redis是单线程受理请求的。通过Redis Setnx(SET if Not eXists) 命令在指定的 key 不存在时,为 key 设置指定的值。设置成功,返回 1 。设置失败,返回 0 。当返回结果为1时我们可以认为该client持有锁,当client处理完业务后执行del key删除该键相当于释放锁。
死锁
这种方式虽然可以实现分布式锁,但是也存在死锁问题。如果持锁的client挂掉了,此时该key会一直存在其他client就获取不到锁了。所以对key要加入过期时间限制,加入过期时间需要和setNx同一个原子操作,在Redis2.8之前我们需要使用Lua脚本达到我们的目的,但是redis2.8之后redis支持nx和ex操作是同一原子操作。
set resourceName value ex 5 nx锁失效
虽然通过给key设置有效期能解决死锁问题,但是又引发了一个新问题锁失效,就是如果client1不是挂掉了,而是业务处理耗时长,在5ms之后Redis主动把这个key删除了,那么另外的client2就可以获取到锁了,此时就存在了两个client持有锁的情况。这个时候其实可以把超时设置这一环节交给各个client来完成,具体思路就是客户端client1创建一个key的时候,设置对应的value为超时时间,可以用当前时间戳+(过期窗口),这样当client2获取到这个值之后发现当前系统时间已经超过value了,那么代表client1没有释放锁,这个时候client2需要通过Redis提供的 GETSET KEY VALUE来获取锁并重置过期时间,之所以要用到GETSET就是为了在client2获取锁之后处理业务的时候,client3、client4也能够发现key过期了并获取到了锁的问题。
Redission
Javaer都知道Jedis,Jedis是Redis的Java实现的客户端,其API提供了比较全面的Redis命令的支持。Redission也是Redis的客户端,相比于Jedis功能简单。Jedis简单使用阻塞的I/O和redis交互,Redission通过Netty支持非阻塞I/O。Jedis最新版本2.9.0是2016年的快3年了没有更新,而Redission最新版本是2018.10月更新。Redission封装了锁的实现,其继承了java.util.concurrent.locks.Lock的接口,让我们像操作我们的本地Lock一样去操作Redission的Lock。
