
我如何用两行代码节省了30%的CPU
将滴滴技术设为“
星标⭐️
”
第一时间收到文章更新
ClickHouse 是一个开源的用于实时数据分析高性能列式分布式数据库,
支持向量化计算引擎、多核并行计算、高压缩比等,在分析型数据库中单表查询性能第一。滴滴从2020年开始引进Clickhouse,服务网约车及日志检索等核心业务,节点数300+,每天PB级别的数据写入,每天千万级别的查询量,其中最大的集群有200+节点。本篇文章主要介绍Clickhouse在性能优化上的一个点,从发现问题到最后解决问题的过程,并获取较好的收益。
01
发现问题
线上节点负载比较高,需要定位CPU主要用在什么地方。首先需要确认的是哪个模块占用了CPU,在Clickhouse中比较耗CPU的主要是查询、写入和Merge等模块。使用top命令定位出占用CPU最高的进程,定位到进程后在使用 top -Hp pid 命令, 查看占用 CPU 最高的线程,如下图:
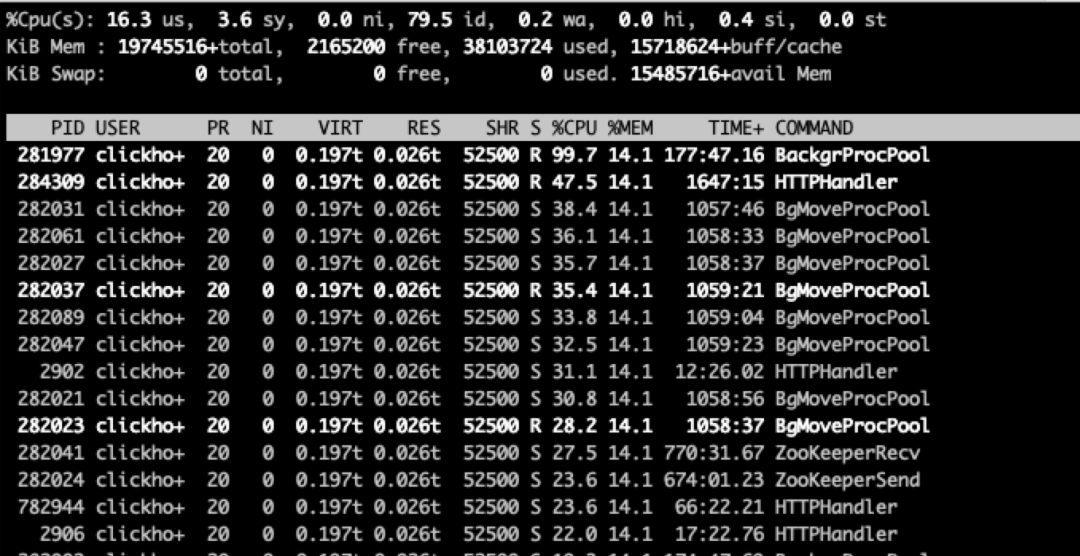
1、排在第一是BackgrProcPool线程是负责执行ReplicatedMergeTree表的merge和mutation任务,需要处理大量的数据。
2、排在第二是HTTPHandler线程是负责处理客户的http请求,包括查询解析、优化及执行计划的生成等,最终生成的物理执行计划会交由QueryPipelineEx线程来执行。
3、接着往下看,会发现连续6个BackgrProcPool线程分别占用30%多的CPU,他们主要是负责磁盘间的数据移动,当磁盘使用率超过了设定的阀值(默认是90%),BgMoveProcPool线程就会将该磁盘上的Part文件移动到其他的磁盘,同时如果对表设置了Move TTL,当Part的数据过期后就会将该Part移动到目标磁盘,主要用来实现数据的冷热分离。BgMoveProc线程池默认最大的线程数是8,负责所有MergeTree表磁盘间数据的移动。
4、图中剩下的ZookeeperSend线程和ZookeeperRecv线程分别是负责发送对ZK的操作请求及接收对应操作的响应,ReplicatedMergeTree 表的副本同步机制就依赖ZK来实现的。Clickhouse中还有很多其他的线程,这里就不再一一的介绍。
top
命令持续监听了一段时间,发现这8个BgMoveProPool线程的CPU占用几乎一直是排在前面的,难道有磁盘的使用率已经达到90%了,所有的Move线程都在磁盘间搬迁
数据?
但是线上磁盘使用到了80%就会报警,难道报警有问题?
使用 df -h 命令查看了磁盘的使用情况,执行后发现12块磁盘的使用率都在50%左右,这就很奇怪了,磁盘的空间是充足的且线上的集群也没有配置冷热分离,按道理BgMoveProcPool线程就不应该占用CPU,究竟在做什么呢?
02
确认问题
为了搞清楚BgMoveProcPool线程到底在执行什么,使用pstack pid命令抓取此时的堆栈,多次打印堆栈发现BgMoveProcPool线程都处于MergeTreePartsMover::selectPartsForMove方法中,堆栈如下:
#0 0x00000000100111a4 in DB::MergeTreePartsMover::selectPartsForMove(std::__1::vector<DB::MergeTreeMoveEntry, std::__1::allocator<DB::MergeTreeMoveEntry> >&, std::__1::function<bool (std::__1::shared_ptr<DB::IMergeTreeDataPart const> const&, std::__1::basic_string<char, std::__1::char_traits<char>, std::__1::allocator<char> >*)> const&, std::__1::lock_guard<std::__1::mutex> const&) ()
#1 0x000000000ff6ef5a in DB::MergeTreeData::selectPartsForMove() ()
#2 0x000000000ff86096 in DB::MergeTreeData::selectPartsAndMove() ()
#3 0x000000000fe5d102 in std::__1::__function::__func<DB::StorageReplicatedMergeTree::startBackgroundMovesIfNeeded()::{lambda()#1}, std::__1::allocator<{lambda()#1}>, DB::BackgroundProcessingPoolTaskResult ()>::operator()() ()
#4 0x000000000ff269df in DB::BackgroundProcessingPool::workLoopFunc() ()
#5 0x000000000ff272cf in _ZZN20ThreadFromGlobalPoolC4IZN2DB24BackgroundProcessingPoolC4EiRKNS2_12PoolSettingsEPKcS7_EUlvE_JEEEOT_DpOT0_ENKUlvE_clEv ()
#6 0x000000000930b8bd in ThreadPoolImpl<std::__1::thread>::worker(std::__1::__list_iterator<std::__1::thread, void*>) ()
#7 0x0000000009309f6f in void* std::__1::__thread_proxy<std::__1::tuple<std::__1::unique_ptr<std::__1::__thread_struct, std::__1::default_delete<std::__1::__thread_struct> >, void ThreadPoolImpl<std::__1::thread>::scheduleImpl<void>(std::__1::function<void ()>, int, std::__1::optional<unsigned long>)::{lambda()#3}> >(std::__1::tuple<std::__1::unique_ptr<std::__1::__thread_struct, std::__1::default_delete<std::__1::__thread_struct> >, void ThreadPoolImpl<std::__1::thread>::scheduleImpl<void>(std::__1::function<void ()>, int, std::__1::optional<unsigned long>)::{lambda()#3}>) ()
#8 0x00007ff91f4d5ea5 in start_thread () from /lib64/libpthread.so.0
#9 0x00007ff91edf2b0d in clone () from /lib64/libc.so.6
多次抓取BgMoveProcPool线程都在执行selectPartsForMove方法,说明selectPartsForMove方法耗时很长,通过方法名可以了解这个方法是在查找可以move的Part,接着查询system.part_log表查看MovePart的记录。
SELECT * FROM system.part_log WHERE event_time > now() - toIntervalDay(1) AND event_type = 'MovePart'
执行上述SQL查询最近一天的MovePart的记录,没有匹配到一条。到这里我们几乎可以确定BgMoveProcPool线程一直在查询可以移动的Part,但结果都空,CPU一直在做无效的计算。根据上面的分析已经定位到出现问题的代码,接下来就是研究selectPartsForMove的源码,如下:
bool MergeTreePartsMover::selectPartsForMove(MergeTreeMovingParts & parts_to_move, const AllowedMovingPredicate & can_move, const std::lock_guard<std::mutex> & /* moving_parts_lock */) {
std::unordered_map<DiskPtr, LargestPartsWithRequiredSize> need_to_move;
/// 1. 遍历所有的disk,将使用率超过阀值的disk添加need_to_move中
if (!volumes.empty()) {
for (size_t i = 0; i != volumes.size() - 1; ++i) {
for (const auto & disk : volumes[i]->getDisks()) {
UInt64 required_maximum_available_space = disk->getTotalSpace() * policy->getMoveFactor(); /// move_factor默认0.9
UInt64 unreserved_space = disk->getUnreservedSpace();
if (unreserved_space < required_maximum_available_space)
need_to_move.emplace(disk, required_maximum_available_space - unreserved_space);
}
}
}
/// 2. 遍历所有的part,首先如果Part的MoveTTL已过期则添加到需要移动的集合parts_to_move中,否则为超过阈值的disk添加候选Part
time_t time_of_move = time(nullptr);
for (const auto & part : data_parts) {
/// 检查该part能否被move,
if (!can_move(part, &reason))
continue;
/// 检查part的move_ttl
auto ttl_entry = data->selectTTLEntryForTTLInfos(part->ttl_infos, time_of_move);
auto to_insert = need_to_move.find(part->volume->getDisk());
if (ttl_entry) { /// 已过期,则需要移动到目标磁盘
auto destination = data->getDestinationForTTL(*ttl_entry);
if (destination && !data->isPartInTTLDestination(*ttl_entry, *part))
reservation = data->tryReserveSpace(part->getBytesOnDisk(), data->getDestinationForTTL(*ttl_entry));
}
if(reservation) /// 需要移动
parts_to_move.emplace_back(part, std::move(reservation));
else { /// 候选Part
if (to_insert != need_to_move.end())
to_insert->second.add(part);
}
}
/// 3. 为候选的Part申请空间并添加到需要移动的集合parts_to_move中
for (auto && move : need_to_move) {
for (auto && part : move.second.getAccumulatedParts()) {
auto reservation = policy->reserve(part->getBytesOnDisk(), min_volume_index);
if (!reservation)
break;
parts_to_move.emplace_back(part, std::move(reservation));
++parts_to_move_by_policy_rules;
parts_to_move_total_size_bytes += part->getBytesOnDisk();
}
}
SelectPartsForMove方法主要做3件事:
首先遍历所有的disk,将使用率超过阀值的disk添加到need_to_move中。
然后遍历所有的part,首先如果Part的MoveTTL已过期则添加到需要移动的集合parts_to_move中,否则为超过阈值的disk添加候选Part。
最后为候选的Part申请空间并添加到需要移动的集合parts_to_move中。
其中耗时最长的是第二步,会随着表Part数的增加而增加,接着查询了system.parts,发现总共有30多万的part,最大的表有6万多个part,为什么那么耗时就不奇怪了。
到这里问题就很明显了,BgMoveProcPool线程不断的在检查这30多万个part是否符合移动的条件,但每次都没有一个part符合条件,一直在做无效的计算。
03
解决问题
线上节点磁盘空间很充足且未设置数据的冷热分层,就不需要浪费CPU去检查每个part。
当没有磁盘使用率达到90%得到的need_to_move为空,没有设置冷热分层,即move_ttl为空,当两个条件都成立的时候是不是就可以不用去检查所有的part,就能节省大量的重复计算了,于是在遍历检查part之前添加下面两行代码,当need_to_move为空且move_ttl为空,就直接返回false。
if (need_to_move.empty() && !metadata_snapshot->hasAnyMoveTTL())
return false;
04
实际效果
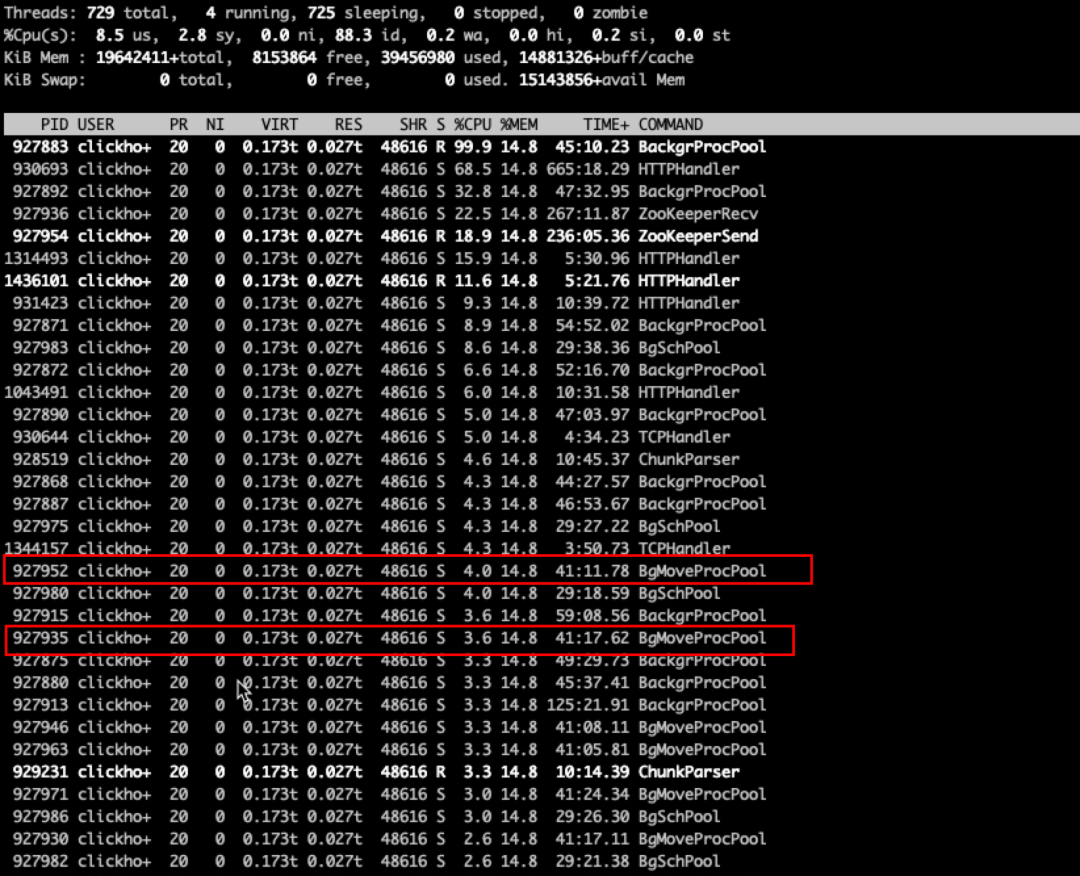
发布到国内公共集群,接着使用top命令观察各个线程消耗的CPU,可以发现在前面已经找不到BgMoveProcPool线程了,8个BgMoveProcPool线程占用的CPU也从之前的30%左右都降到了4%以下。
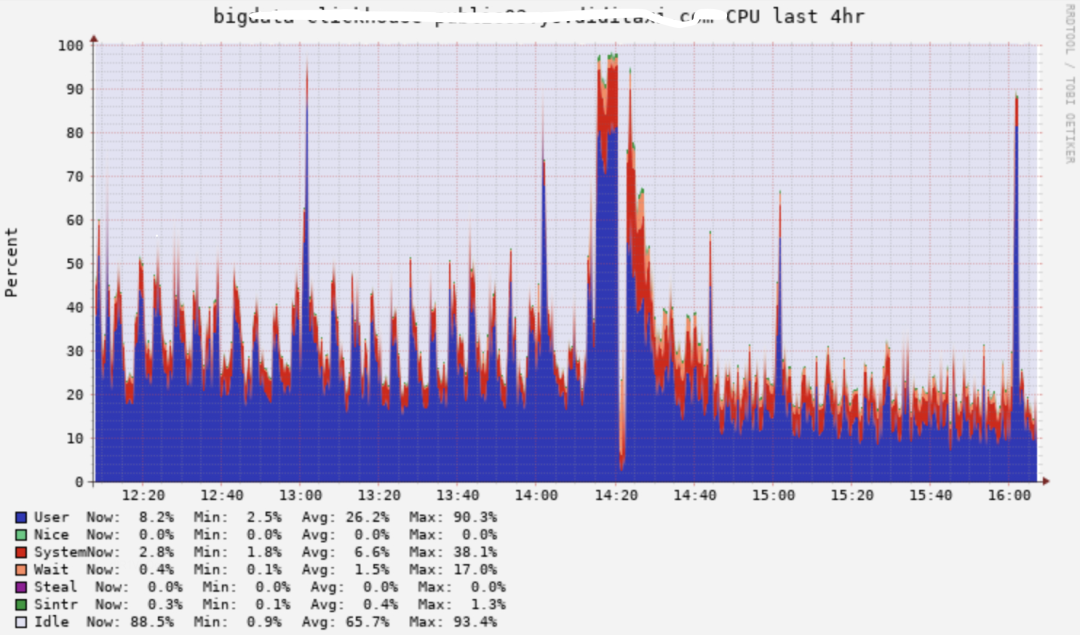
再来观察一下机器整体的CPU,可以清晰的发现CPU由升级前的20%左右降到了10%左右,并且尖刺没那么高了。
并将这个优化贡献给了社区,已经被merge到master。
05
后续思考
很多时候代码在数据量小、并发低的时候不会有问题,一旦数据量、并发上来了就会出现很多问题,在写代码的过程中敬畏每一行代码,让程序更加健壮。后续Clickhouse将持续在日志检索场景发力,打造稳定、低成本、高吞吐、高性能的PB级日志检索系统。