
五分钟了解 LogQL 用法
受PromQL的启发,Loki也有自己的LogQL查询语句。根据官方的说法,它就像一个分布式的grep日志聚合查看器。和PromeQL一样,LogQL也是使用标签和运算符进行过滤,它主要分为两个部分:
log stream selector (日志流选择器)
filter expression (过滤器表达式)
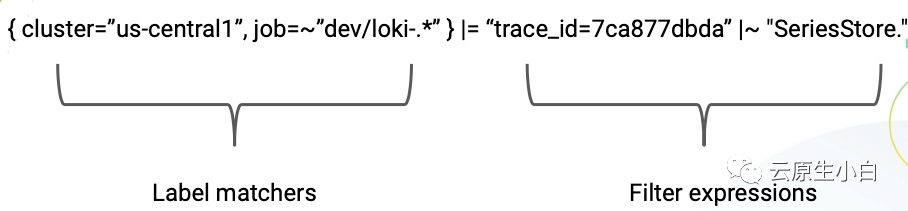 我们用这两部分就可以在Loki中组合出我们想要的功能,通常情况下我们可以拿来做如下功能
我们用这两部分就可以在Loki中组合出我们想要的功能,通常情况下我们可以拿来做如下功能
根据日志流选择器查看日志内容
通过过滤规则在日志流中计算相关的度量指标
log stream selector
日志流选择器这部分和PromQL的语法一样,主要也是通过采集上来的日志label来确定你要查询的日志流。通常label的匹配运算支持以下几种:
=: 完全匹配
!=: 不匹配
=~: 正则表达式匹配
!~: 正则表达式不匹配
举个例子
{name=~"mysql.+", env="prod"}
{name!~"mysql.+", env="prod"}
{name!~`mysql-\d+`,env="prod"}
以上语句都可以查出所有与之匹配的日志内容
filter expression
在查看全文的日志时,通常会用grep等一些工具来查找我们关心的日志内容。LogQL的表达式就是干这个的。当前,过滤的表达式主要支持如下4种:
|=:日志行包含的字符串
!=:日志行不包含的字符串
|~:日志行匹配正则表达式
!~:日志行与正则表达式不匹配
举个例子
{job="mysql"} |= "error"
{name="kafka"} |~ "tsdb-ops.*io:2003"
{name="cassandra"} |~ `error=\w+`
{instance=~"kafka-[23]",name="kafka"} != "kafka.server:type=ReplicaManager"
如果要进行多次匹配的话,我们可以也可以像在linux用管道的方式追加规则:
{job="mysql"} |= "error" != "timeout"
日志度量
LogQL同样支持通过函数方式将日志流进行度量,通常我们可以用它来计算消息的错误率或者排序一段时间内的应用日志输出Top N。
区间向量
LogQL同样也支持有限的区间向量度量语句,使用方式也和PromQL类似,常用函数主要是如下4个:
rate: 计算每秒的日志条目
count_over_time: 对指定范围内的每个日志流的条目进行计数
bytes_rate: 计算日志流每秒的字节数
bytes_over_time: 对指定范围内的每个日志流的使用的字节数
举个例子:
#计算nginx的qps
rate({filename="/var/log/nginx/access.log"}[5m]))
#计算kernel过去5分钟发生oom的次数
count_over_time({filename="/var/log/message"} |~ "oom_kill_process" [5m]))
聚合函数
LogQL也支持聚合运算,我们可用它来聚合单个向量内的元素,从而产生一个具有较少元素的新向量,当前支持的聚合函数如下:
sum:求和
min:最小值
max:最大值
avg:平均值
stddev:标准差
stdvar:标准方差
count:计数
bottomk:最小的k个元素
topk:最大的k个元素
聚合函数通常我们用如下表达式描述:
([parameter,] ) [without|by ( 对于需要对标签进行分组时,我们可以用without或者by来区分,比如
#计算nginx的qps,并按照pod_name来分组
sum(rate({filename="/var/log/nginx/access.log"}[5m])) by (pod_name)
只有在使用bottomk和topk函数时,我们可以对函数输入相关的参数,比如
#计算nginx的qps最大的前5个,并按照pod_name来分组
topk(5,sum(rate({filename="/var/log/nginx/access.log"}[5m])) by (pod_name))
数学计算
有同学要问了,Loki存的不是日志吗?都是文本,怎么计算啊?显然LogQL中的数学运算还是面向区间向量操作的。LogQL中的支持的二进制运算符如下:
+:加法
-:减法
*:乘法
/:除法
%:求模
: 求幂
比如我们要找到某个业务日志里面的错误率,就可以按照如下方式计算:
#计算日志内的错误率
sum(rate({app="foo", level="error"}[1m])) / sum(rate({app="foo"}[1m]))
集合运算
集合运算仅在区间向量范围内有效,当前支持
and:并且
or:或者
unless:排除
小白当前还没找到LogQL里面集合运算的案例,暂且跳过
比较运算
LogQL支持的比较运算符合PromQL一样,均为以下内容:
==:等于
!=:不等于
>:大于
>=: 大于或等于
<:小于
<=: 小于或等于
通常我们使用区间向量计算后会做一个阈值的比较,这对应告警是非常有用的,比如:
# 统计5分钟内error级别日志条目大于10的情况
count_over_time({app="foo", level="error"}[5m]) > 10
当然我们也可以通过布尔计算来表达,比如:
# 统计5分钟内error级别日志条目大于10为真,反正则为假
count_over_time({app="foo", level="error"}[5m]) > bool 10
这部分后面结合Loki ruler使用会有更多的使用场景,建议配合《Loki告警的正确姿势》一起食用
运算优先级
LogQL的运算优先级也保持了常规的数学操作顺序,即如下规则:
^
*, /, %
+, -
==,!=, <=, <, >=, >
and, unless
or

END
 点击屏末 | 阅读原文 | 即刻学习
点击屏末 | 阅读原文 | 即刻学习