
构建基于Docker的ELK日志分析服务
通过构建基于Docker的ELK日志分析服务,进一步增强对日志文件的分析、检索能力

容器化部署
所谓ELK指的是ElasticSearch、Logstash、Kibana,其中ElasticSearch用于数据的存储、检索,Logstash用于数据的结构化处理,Kibana则进行可视化展示。这里直接通过Docker Compose搭建ELK服务,值得一提的是需保证ElasticSearch、Logstash、Kibana各组件的版本完全一致
# Compose 版本
version: '3.8'
# 定义Docker服务
services:
# ElasticSearch 服务
ElasticSearch-Service:
build:
# 指定dockerfile的路径
context: ./ESDockerFile
# 指定dockerfile的文件名
dockerfile: Dockerfile
# 设置dockerfile所构建镜像的名称、tag
image: es-ik:7.12.0
container_name: ElasticSearch-Service
ports:
- 9200:9200
- 9300:9300
environment:
- "ES_JAVA_OPTS=-Xms2g -Xmx2g"
- "discovery.type=single-node"
- "TZ=Asia/Shanghai"
volumes:
# ES数据目录
- /Users/zgh/Docker/ELK/ES/data:/usr/share/elasticsearch/data
# ES日志目录
- /Users/zgh/Docker/ELK/ES/logs:/usr/share/elasticsearch/logs
# Logstash 服务
Logstash-Service:
image: logstash:7.12.0
container_name: Logstash-Service
ports:
- 5044:5044
environment:
- "xpack.monitoring.enabled=false"
- "TZ=Asia/Shanghai"
volumes:
# Logstash配置文件
- /Users/zgh/Docker/ELK/Logstash/conf/logstash.conf:/usr/share/logstash/pipeline/logstash.conf
# 自定义的索引模板文件
- /Users/zgh/Docker/ELK/Logstash/conf/customTemplate.json:/usr/share/logstash/config/customTemplate.json
# 日志文件所在目录
- /Users/zgh/Docker/ELK/Logstash/LocalLog:/home/Aaron/LocalLog
depends_on:
- ElasticSearch-Service
# Kibana 服务
Kibana-Service:
image: kibana:7.12.0
container_name: Kibana-Service
ports:
- 5601:5601
environment:
- "ELASTICSEARCH_HOSTS=http://ElasticSearch-Service:9200"
- "TZ=Asia/Shanghai"
depends_on:
- ElasticSearch-Service
同时为对中文分词提供更好的支持,这里以ElasticSearch官方镜像为基础重新构建安装了ik分词器的ES镜像,Dockerfile如下所示
# 基础镜像环境: ES 7.12.0
FROM elasticsearch:7.12.0
# 切换目录
WORKDIR /usr/share/elasticsearch/plugins
# 安装与ES版本相同的IK分词器
RUN elasticsearch-plugin install -b \
https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.0/elasticsearch-analysis-ik-7.12.0.zip
上述两文件的相对路径关系如下图所示

Logstash
配置
Logstash作为一款主流的日志处理框架,通过提供形式多样的插件极大地丰富了表现力。具体地,我们通过logstash.conf配置文件进行配置。如下所示
input {
file {
# 容器下的日志路径, 支持递归匹配路径
path => "/home/Aaron/LocalLog/**/*.*"
# 排除压缩文件类型
exclude => ["*.zip", "*.7z", "*.rar"]
# 使用read模式,一方面每次都会从文件开始处读取,另一方面读取完后会自动删除日志文件
mode => "read"
# 文件块大小, Unit: 字节。4194304字节 = 4MB
file_chunk_size => 4194304
# 检查文件的频率
stat_interval => "200 ms"
# 发现新文件的频率: stat_interval * discover_interval
discover_interval => 1
# 合并多行数据
codec => multiline {
# 正则表达式: 以时间信息开头
pattern => "^%{TIMESTAMP_ISO8601}"
# true: 否定正则表达式, 即如果不匹配的话
negate => true
# 当negate为true, 即正则表达式不匹配时, 当前日志归属于上一条日志
what => "previous"
# 检测多行的等待时间阈值,Unit: s
auto_flush_interval => 1
}
}
}
filter {
# 解析日志进行结构化
grok {
match => {
"message" => "%{TIMESTAMP_ISO8601:logtime} %{LOGLEVEL:level} %{WORD:componentId}\.%{WORD:segmentId} \[%{DATA:threaad}\] \[%{DATA:method}\] %{GREEDYDATA:message}"
}
# 重写message字段
overwrite => ["message"]
}
# 通过指定字段计算Hash值
fingerprint {
method => "MURMUR3"
source => ["logtime", "threaad", "message"]
concatenate_sources => "true"
target => "[@metadata][fingerprint]"
}
# 给SQL日志打标签
if [message] =~ "==> .*" or [message] =~ "<== .*" {
mutate {
# 对tags字段添加值
add_tag => ["SQL"]
}
}
# 解析时间并转存到 @timestamp 字段
date {
# logtime字段按ISO8601格式进行解析
match => ["logtime", "ISO8601"]
# 将解析后的时间存储到给定的目标字段
target => "@timestamp"
# 删除logtime字段
remove_field => ["logtime"]
}
# 解析日志名称并转存到logFile字段
mutate {
# 日志文件路径按/切分
split => { "path" => "/" }
# 添加logFile日志文件名字段
add_field => { "logFile" => "%{[path][-1]}" }
# 删除无用字段
remove_field => ["host", "@version", "path"]
}
}
output {
elasticsearch {
# ES地址
hosts => ["http://ElasticSearch-Service:9200"]
# 索引名称
index => "logstash-%{componentId}"
# 将计算出的Hash值作为文档ID
document_id => "%{[@metadata][fingerprint]}"
# 使能模板管理模板
manage_template => true
# 模板名称
template_name => "custom_template"
# 容器下的模板文件路径
template => "/usr/share/logstash/config/customTemplate.json"
}
# Only For Debug
# stdout {
# codec => rubydebug {
# # 是否输出元数据字段
# metadata => true
# }
# }
}
Plugin
这里对上述配置文件所使用的各种插件进行介绍
File
File作为Input Plugin输入插件的一种,用于实现通过日志文件读取日志信息。具体地
path:指定日志文件所在路径,支持递归 mode:在read模式下,一方面每次都会从文件开始处读取,另一方面读取完后会自动删除日志文件。这里由于我们处理的是静态的日志文件,故非常适合使用read模式 exclude:根据文件名(非路径)排除文件,这里选择排除压缩类型的文件 stat_interval:检查文件更新的频率 discover_interval:发现新文件的频率,该值是stat_interval配置项的倍数
Multiline
通常日志都是单行的,但由于异常错误的堆栈信息的存在,如下所示。日志中存在多行类型日志的可能性,故这里通过Codec Plugin编解码插件中的Multiline进行处理,将多行合并为一行
2021-08-12T17:42:31.850+08:00 ERROR hapddg.hapddgweb [http-nio-8080-exec-124] [c.a.t.common.e.GlobalExceptionHandler:49] unexpected exception
org.apache.catalina.connector.ClientAbortException: java.io.IOException: Broken pipe
at org.apache.catalina.connector.OutputBuffer.append(OutputBuffer.java:746)
at org.apache.catalina.connector.OutputBuffer.realWriteBytes(OutputBuffer.java:360)
... 109 common frames omitted
对于Multiline而言,其常见选项如下所示
pattern:正则表达式。上文配置中我们使用的模式为以时间信息开头 negate:是否对正则表达式的结果进行否定。上文配置为true,即不匹配pattern配置项指定的正则表达式视为多行并进行处理 what:其可选值有:previous、next。用于多行日志合并时,当前行视为归属于上一行还是下一行 auto_flush_interval:在处理当前行时检测多行的等待时间阈值(Unit: s)。该配置项无默认值,故如果不显式设置,则会发现处理日志文件时,输出结果会丢失最后一行日志
Grok
Filter Plugin过滤器插件中最重要的就属Grok了,我们就是通过它进行正则捕获实现对日志数据的结构化处理。Grok内置定义了多种常见的正则匹配模式,以大大方便我们日常的使用。对于内置模式的使用语法如下,其中PATTERN_NAME为Grok内置的匹配模式的名称,并通过capture_name对捕获的文本进行命名。由于默认情况下,捕获结果都是保存为字符串类型,所以可以通过可选地data_type进行类型转换。但仅支持int、float两种类型
# 语法格式
%{PATTERN_NAME:capture_name:data_type}
# 使用.*正则进行捕获,并以message命名
%{GREEDYDATA:message}
# 使用.*正则进行捕获,并以age命名,最后将数据类型转换为int
%{GREEDYDATA:age:int}
对于内置模式无法满足的场景,Grok也支持用户自定义正则进行匹配。语法格式及示例如下。其中reg_exp为正则表达式
# 语法格式
(?reg_exp)
# 使用.*正则进行捕获,并以message命名
(?.*)
这里就Grok中内置的常见模式进行介绍
TIMESTAMP_ISO8601:匹配ISO8601格式的时间。例如:2021-08-12T17:33:47.498+08:00 LOGLEVEL:匹配日志级别 WORD: 匹配字符串,包括数字、大小写字母、下划线 DATA、GREEDYDATA:从这两个模式的正则表达式.*?和.*就可以看出,后者是前者的贪婪模式版本
现在我们就可以利用Grok处理日志了,假设一条日志的格式如下所示
2021-08-12T17:33:47.498+08:00 INFO hapddg.hapddgweb [ActiveMQ Session Task-483] [c.a.s.h.EventHandler:187] add event message to queue
直接利用Grok内置的模式对上述日志格式进行结构化处理,如下所示。其中match配置项用于定义待匹配的字段、匹配方式。与此同时,由于已经将message中所有信息均捕获到各个字段了。为避免重复存储,我们可以通过overwrite重写默认的message字段
# 解析日志进行结构化
grok {
match => {
"message" => "%{TIMESTAMP_ISO8601:logtime} %{LOGLEVEL:level} %{WORD:componentId}\.%{WORD:segmentId} \[%{DATA:threaad}\] \[%{DATA:method}\] %{GREEDYDATA:message}"
}
# 重写message字段
overwrite => ["message"]
}
Fingerprint
Fingerprint同样是一种Filter Plugin,其通过指定字段计算出一个指纹值。后续我们会将计算出的指纹值作为文档ID,来实现重复文档的去重
method:指定计算指纹信息的算法,支持SHA1、SHA256、SHA384、SHA512、MD5、MURMUR3等。这里我们选用MURMUR3,其作为一种非加密型哈希算法,由于计算快、碰撞低等特点被广泛应用于哈希检索等场景 source:利用哪些字段计算指纹信息 concatenate_sources:计算指纹前是否将source配置项指定的所有字段的名称、值拼接为一个字符串,默认值为false。如果为false,则将只会使用source配置项中指定的最后一个字段进行指纹信息计算。故这里需要显式设为true target:设置存储指纹值的字段名。这里使用了元数据字段
Logstash从1.5版本开始提供了一种特殊字段——@metadata元数据字段。@metadata中的内容不会对外进行输出(特殊条件下可以通过某种方式进行输出以便于调试)。故非常适合在Logstash DSL中作为临时字段使用。否则如果使用普通字段存储中间结果,还需要通过remove_field进行删除以避免对外输出。使用元数据字段也很简单,如果期望使用一个名为tempData1的元数据字段。则字段名即为[@metadata][tempData1]。当然其同样支持字段引用,通过[@metadata][tempData1]直接即可访问,而在字符串中的则可以通过%{[@metadata][tempData1]}方式进行字段引用。关于元字段的使用示例如下所示
filter{
mutate {
# 将message字段的值 存储到 [@metadata][tempData1] 字段中
add_field => { "[@metadata][tempData1]" => "%{[message]}" }
# 将 [@metadata][tempData1] 字段的值 存储到 outdata2 字段中
add_field => { "outdata2" => "%{[@metadata][tempData1]}" }
}
}
Mutate
Filter Plugin中的Mutate则可以对字段进行修改,包括但不限于split、join、rename、lowercase等操作。但需要注意的是在一个Mutate块内各操作不是按书写的顺序执行的,而是根据Mutate Plugin内部某种固定的预设顺序依次执行的。故如果期望控制各操作的执行顺序,可以定义多个Mutate块。因为各Mutate块的执行顺序是按书写顺序依次进行的。这里我们利用split对日志文件的path字段按路径分隔符进行切分,并通过下标-1访问数组中的最后一个元素取得日志文件名称,最后对原path字段进行删除
而对于各种不同类型的日志,我们期望能够进行分类、打标签。这样便于后续在检索日志时更加高效。具体地,对于SQL类型的日志而言,其结构特征为"==>"、"<=="开头。如下所示
2021-08-17T16:33:11.958+08:00 DEBUG hapddg.hapddgweb [http-nio-8080-exec-1] [c.a.t.m.a.A.deleteData:143] ==> Preparing: delete from tb_person where id in ( ? , ? , ? )
2021-08-17T16:44:11.958+08:00 DEBUG hapddg.hapddgweb [http-nio-8080-exec-1] [c.a.t.m.a.A.deleteData:143] ==> Parameters: 22(Integer), 47(Integer), 60(Integer)
2021-08-17T16:55:11.959+08:00 DEBUG hapddg.hapddgweb [http-nio-8080-exec-1] [c.a.t.m.a.A.deleteData:143] <== Updates: 3
这样即可结合Logstash条件判断语句、Mutate的add_tag操作实现对SQL日志打标签,其中值为"SQL"。此外Logstash还提供了 =~、!~ 运算符分别用于匹配正则、不匹配正则
# 给SQL日志打标签
if [message] =~ "==> .*" or [message] =~ "<== .*" {
mutate {
# 对tags字段添加值
add_tag => ["SQL"]
}
}
Date
由于Logstash输出的@timestamp字段值默认为其处理日志文件过程的当前时间,故这里我们需要将日志中记录的时间信息写入@timestamp字段,以便后续的搜索。这里选择Filter Plugin中的Date实现对于时间字符串的解析处理
match:指定时间字段及其对应的时间格式。其中,支持的时间格式有:ISO8601(例如:2021-08-17T16:55:11.959+08:00)、UNIX(Unix纪元以来的秒数)、UNIX_MS(Unix纪元以来的毫秒数)等 target:存储解析后时间信息的字段
Elasticsearch
当Logstash完成日志的结构化处理后,即可输出到ElasticSearch。这里直接选择Elasticsearch Plugin即可。如下所示,这里我们指定了ES的地址、索引、文档ID等信息。同时还在其中定义了一个名为custom_template的ES索引模板
elasticsearch {
# ES地址
hosts => ["http://ElasticSearch-Service:9200"]
# 索引名称
index => "logstash-%{componentId}"
# 将计算出的Hash值作为文档ID
document_id => "%{[@metadata][fingerprint]}"
# 使能模板管理模板
manage_template => true
# 模板名称
template_name => "custom_template"
# 容器下的模板文件路径
template => "/usr/share/logstash/config/customTemplate.json"
}
Rubydebug
前面提到默认情况下,元数据字段不会进行输出。但实际上在调试过程中可以通过Codec Plugin编解码插件中的Rubydebug使能输出元数据字段。下面即是在一个标准输出Stdout中包含元数据字段输出的示例
stdout {
codec => rubydebug {
# 是否输出元数据字段
metadata => true
}
}
Index Template索引模板
在Logstash的DSL配置文件中我们通过Elasticsearch Plugin定义了一个ES索引模板,并且通过template字段指定在Logstash容器下的索引模板文件路径。具体地,索引模板文件customTemplate.json的内容如下所示
{
"index_patterns" : "logstash-*",
"order": 20,
"settings":{
"index.refresh_interval": "1s",
"index.number_of_replicas": 0,
"index.lifecycle.name": "autoRemoveOldData"
},
"mappings":{
"properties" : {
"@timestamp" : {
"type" : "date"
},
"level" : {
"type" : "keyword",
"norms" : false
},
"componentId" : {
"type" : "keyword",
"norms" : false
},
"segmentId" : {
"type" : "keyword",
"norms" : false
},
"threaad" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 556
}
},
"norms" : false
},
"method" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 556
}
},
"norms" : false
},
"message" : {
"type" : "text",
"analyzer": "ik_max_word"
},
"logFile" : {
"type": "text",
"index" : false
},
"tags" : {
"type" : "keyword",
"norms" : false
}
}
}
}
部分配置项说明如下:
index_patterns:该模板匹配索引名称的通配符表达式 order:优先级,值越大优先级越高 index.refresh_interval:索引的刷新时间间隔 index.number_of_replicas:每个主分片的副本数 index.lifecycle.name:ILM索引生命周期中的策略名称
至此,ELK服务中的两个关键性配置文件均已介绍完毕,其在宿主机下的相关层次结构如下所示
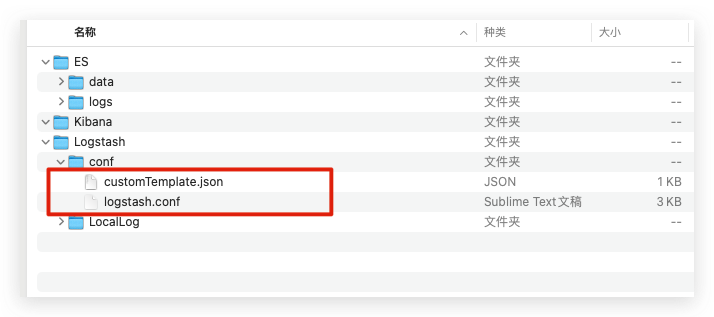
Kibana
本地化
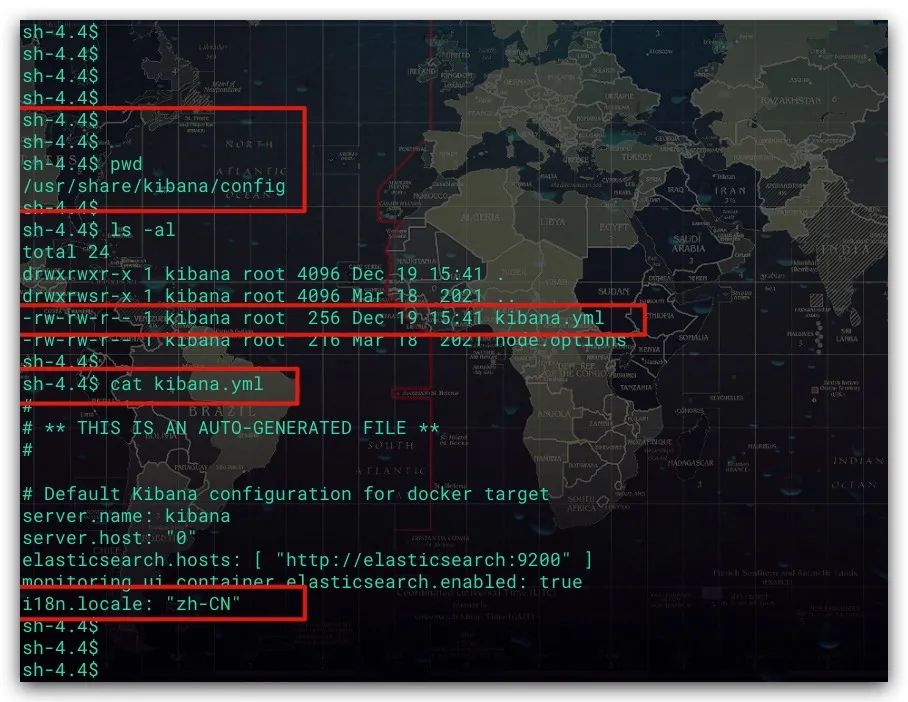
通过Docker Compose创建、启动ELK服务所需的各容器。进入Kibana容器,修改/usr/share/kibana/config路径下的配置文件kibana.yml,增加 i18n.locale: "zh-CN" 配置项
修改完毕后,重启Kibana容器。然后通过 http://localhost:5601 访问Kibana的Web页面。可以看到,页面语言已经被修改为中文
个性化配置
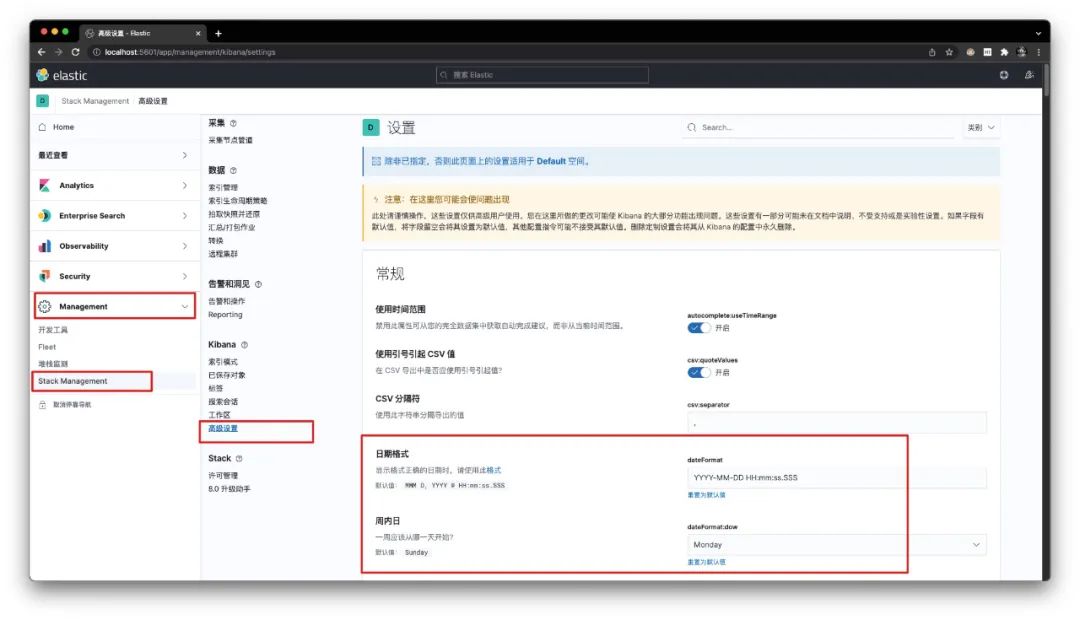
点击【Management】下的【Stack Management】,然后进入【高级设置】进行个性化修改、并保存。具体地:
将日期的显示格式修改为YYYY-MM-DD HH:mm:ss.SSS,并且将Monday周一作为一周的开始
去除不必要的元字段展示,仅保留 _source, _id, _index 字段
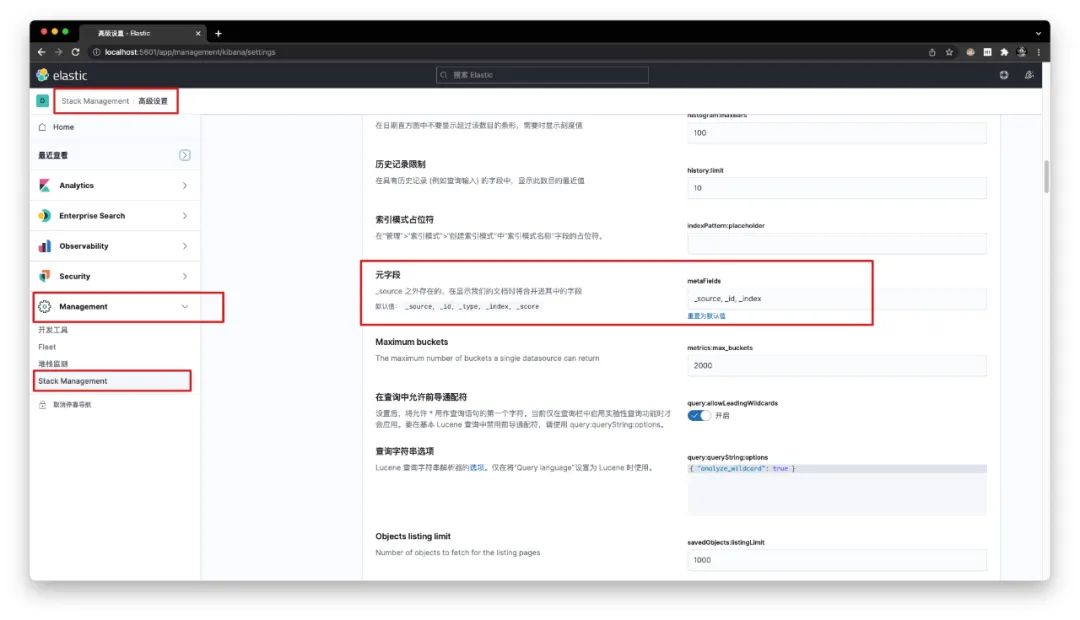
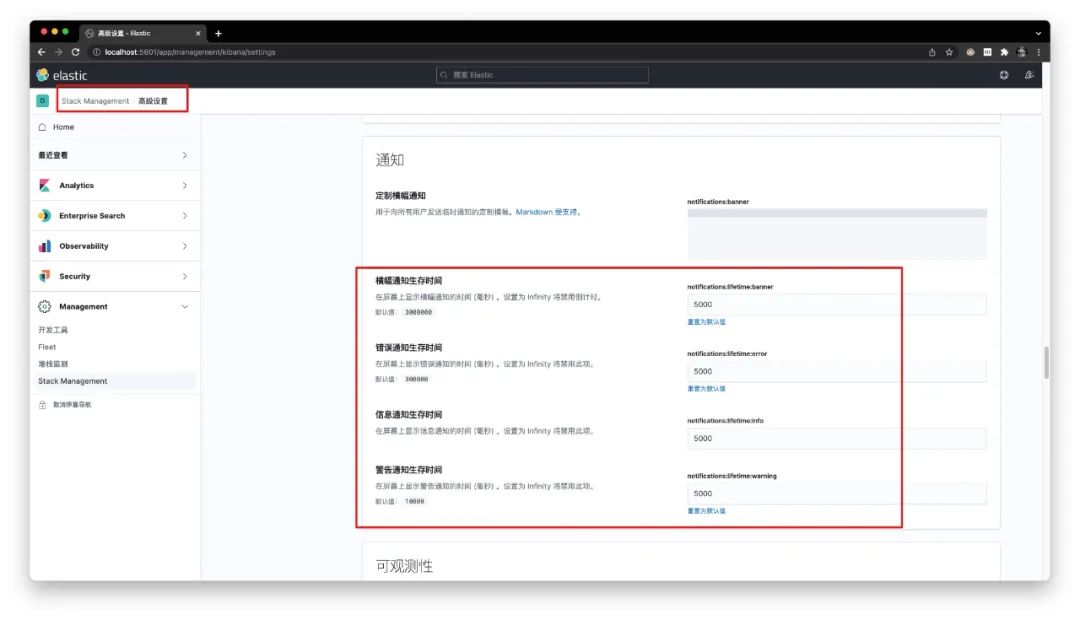
将各种通知信息的保留时间设为5秒
ILM索引生命周期管理
在上文的customTemplate.json索引模板文件中,我们通过index.lifecycle.name配置项定义、关联了一个名为autoRemoveOldData的ILM策略。可通过【Management】-【Stack Management】-【索引管理】-【索引模板】查看,如下所示

现在我们来创建该策略,通过【Management】-【开发工具】-【控制台】发送如下的PUT请求即可
# 创建名为autoRemoveOldData的策略:自动删除超过20天的索引
PUT _ilm/policy/autoRemoveOldData?pretty
{
"policy": {
"phases": {
"hot": {
"min_age": "0",
"actions": {}
},
"delete": {
"min_age": "20d",
"actions": {
"delete": {
"delete_searchable_snapshot": true
}
}
}
}
}
}
效果如下所示
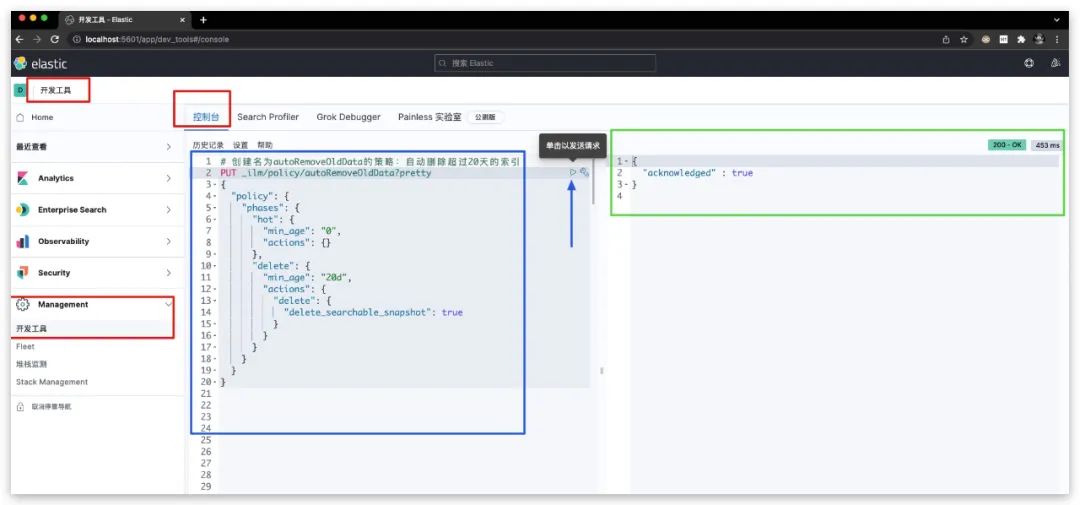
通过【Management】-【Stack Management】-【索引生命周期策略】查看,可以看到相应的ILM策略已经创建成功

建立索引模式
现在,将我们用于测试的日志文件aaron.log放入LocalLog目录下,已便让ELK分析日志
其中测试的日志文件aaron.log的内容如下所示
2021-08-12T17:33:47.498+08:00 INFO hapddg.hapddgweb [ActiveMQ Session Task-483] [c.a.s.h.EventHandler:187] add event message to queue
2021-08-12T17:42:31.850+08:00 ERROR hapddg.hapddgweb [http-nio-8080-exec-124] [c.a.t.common.e.GlobalExceptionHandler:49] unexpected exception
org.apache.catalina.connector.ClientAbortException: java.io.IOException: Broken pipe
at org.apache.catalina.connector.OutputBuffer.append(OutputBuffer.java:746)
at org.apache.catalina.connector.OutputBuffer.realWriteBytes(OutputBuffer.java:360)
... 109 common frames omitted
2021-08-12T18:22:01.959+08:00 INFO hapddg.hapddgweb [http-nio-8080-exec-137] [c.a.t.s.CallBackServiceImpl:71] sublist is empty
2021-08-12T18:25:02.146+08:00 DEBUG hapddg.hapddgweb [http-nio-8080-exec-135] [c.a.t.s.CallBackServiceImpl:72] query down result is ok
2021-08-12T18:29:02.356+08:00 INFO hapddg.hapddgweb [http-nio-8080-exec-137] [c.a.t.s.CallBackServiceImpl:73] start task
2021-08-17T16:33:11.958+08:00 DEBUG hapddg.hapddgweb [http-nio-8080-exec-1] [c.a.t.m.a.A.deleteData:143] ==> Preparing: delete from tb_person where id in ( ? , ? , ? )
2021-08-17T16:44:11.958+08:00 DEBUG hapddg.hapddgweb [http-nio-8080-exec-1] [c.a.t.m.a.A.deleteData:143] ==> Parameters: 22(Integer), 47(Integer), 60(Integer)
2021-08-17T16:55:11.959+08:00 DEBUG hapddg.hapddgweb [http-nio-8080-exec-1] [c.a.t.m.a.A.deleteData:143] <== Updates: 3
当ELK读取完日志文件后会自动将其进行删除,同时通过【Management】-【Stack Management】-【索引管理】-【索引】可以查看相应的索引、文档已经建立完毕

通过【Management】-【Stack Management】-【索引模式】来建立索引模式
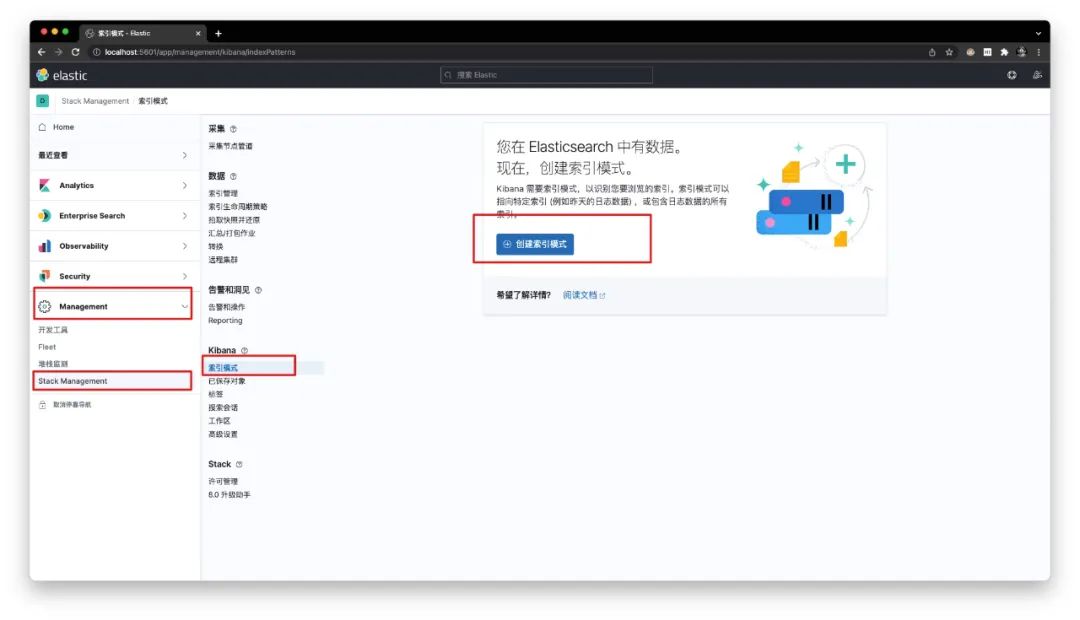
定义索引模式的名称为 logstash-*
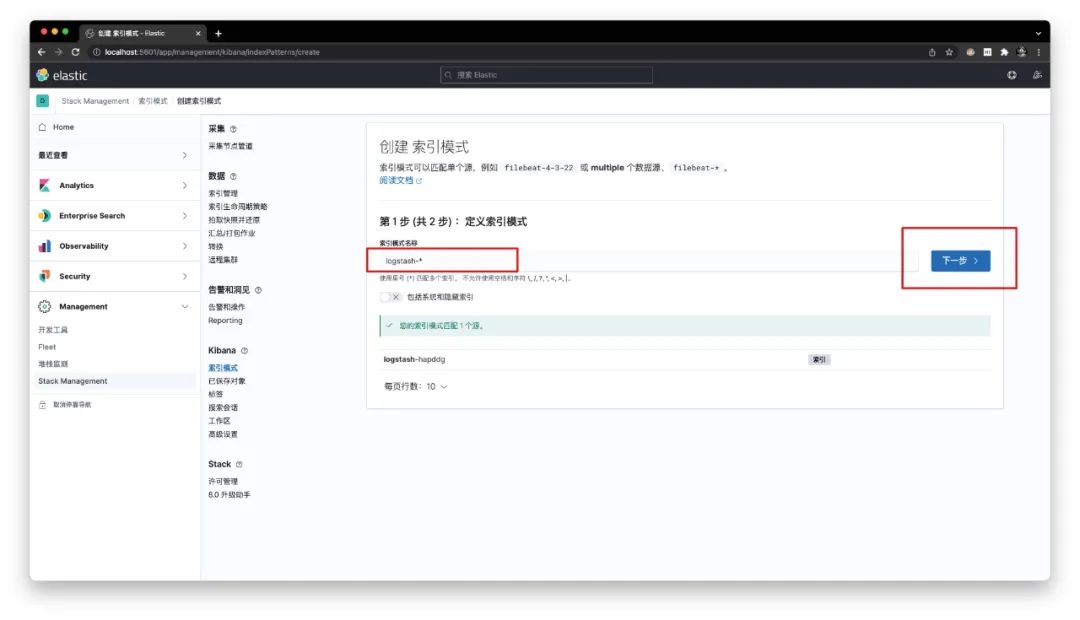
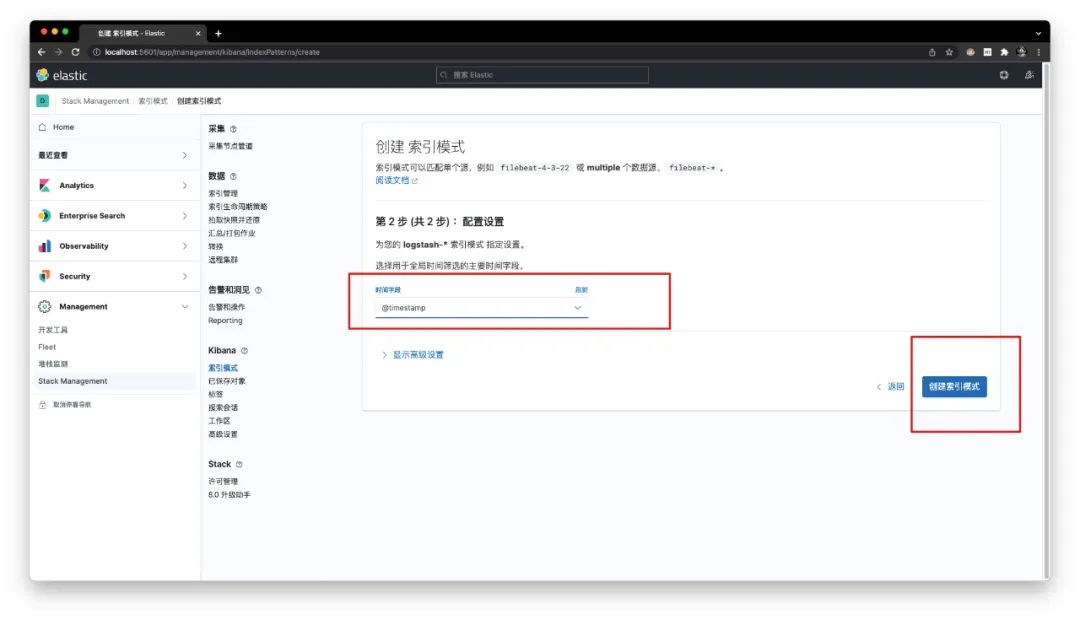
同时将 @timestamp 字段作为全局时间筛选的时间字段
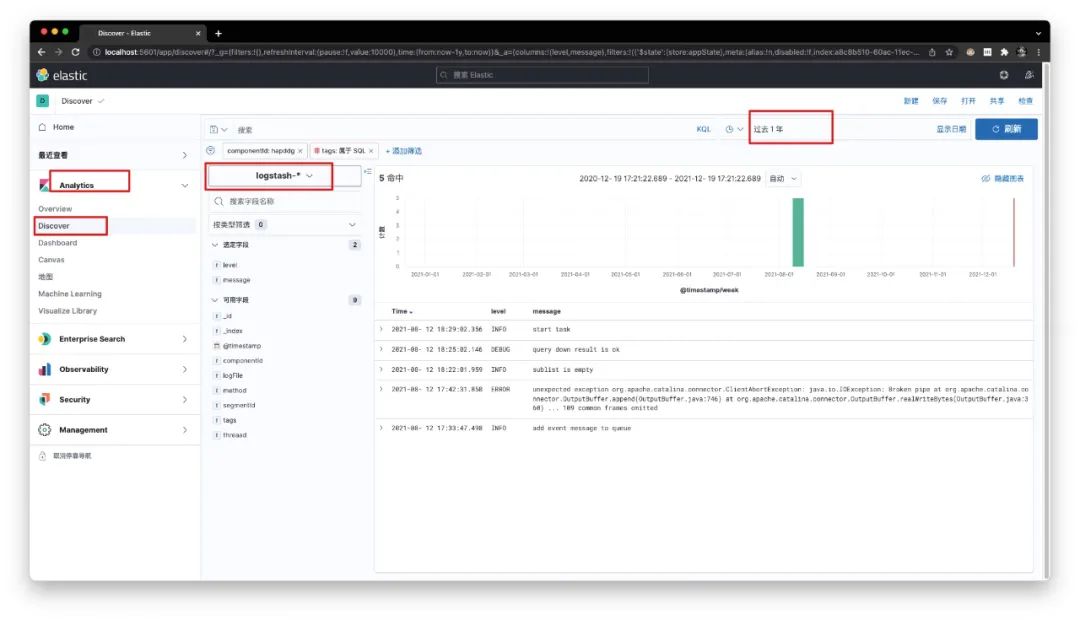
实践
只需第一次在Kibana中建立好索引模式即可,后续无需再次重复建立。现在通过【Analytics】-【Discover】即可进行日志的检索,效果如下所示
Note
Docker挂载Volume
挂载Volume前,一方面需要提前在宿主机下创建相应的目录、文件;另一方面需要将其加入Docker的File Sharing配置中,由于File Sharing对所配置目录的子目录同样会生效,故一般只需将父目录加入即可。设置方法如下所示
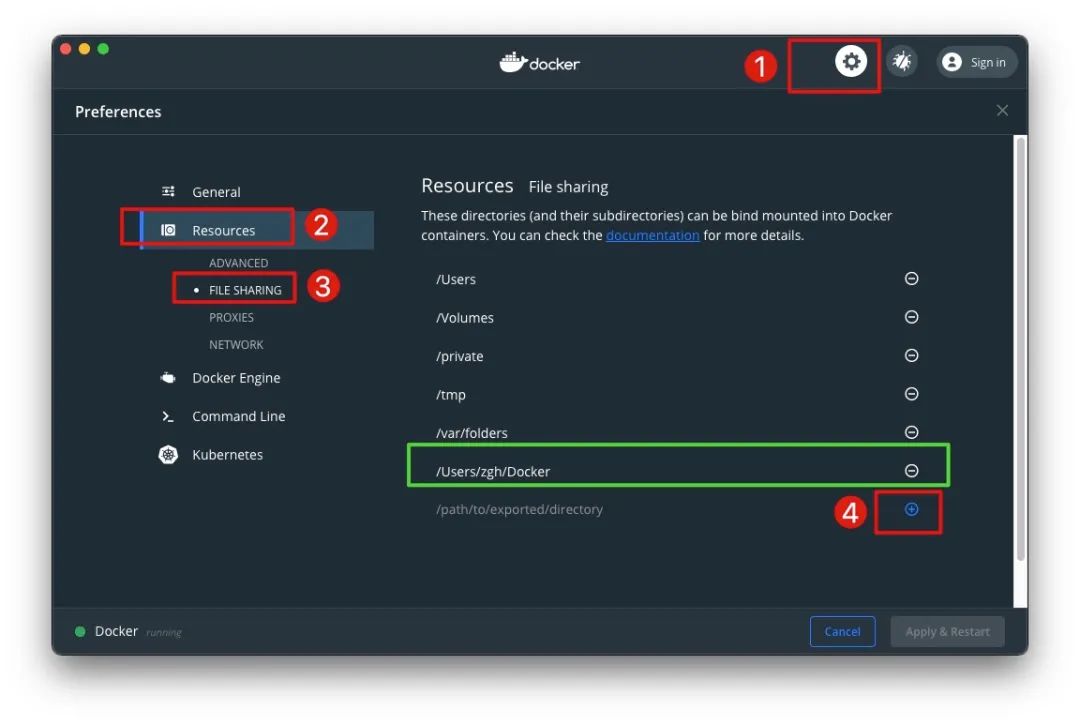
特别地,在Windows系统下挂载Volume时,需要注意路径的写法。例如,Windows系统的路径 D:\Docker\ELK 应该写为 /D/Docker/ELK
查看Logstash Plugin版本信息
进入Logstash容器后,可通过执行如下命令查看Logstash中各Plugin的版本信息
# 查看Logstash Plugin版本信息
/usr/share/logstash/bin/logstash-plugin list --verbose
调试Logstash Filter
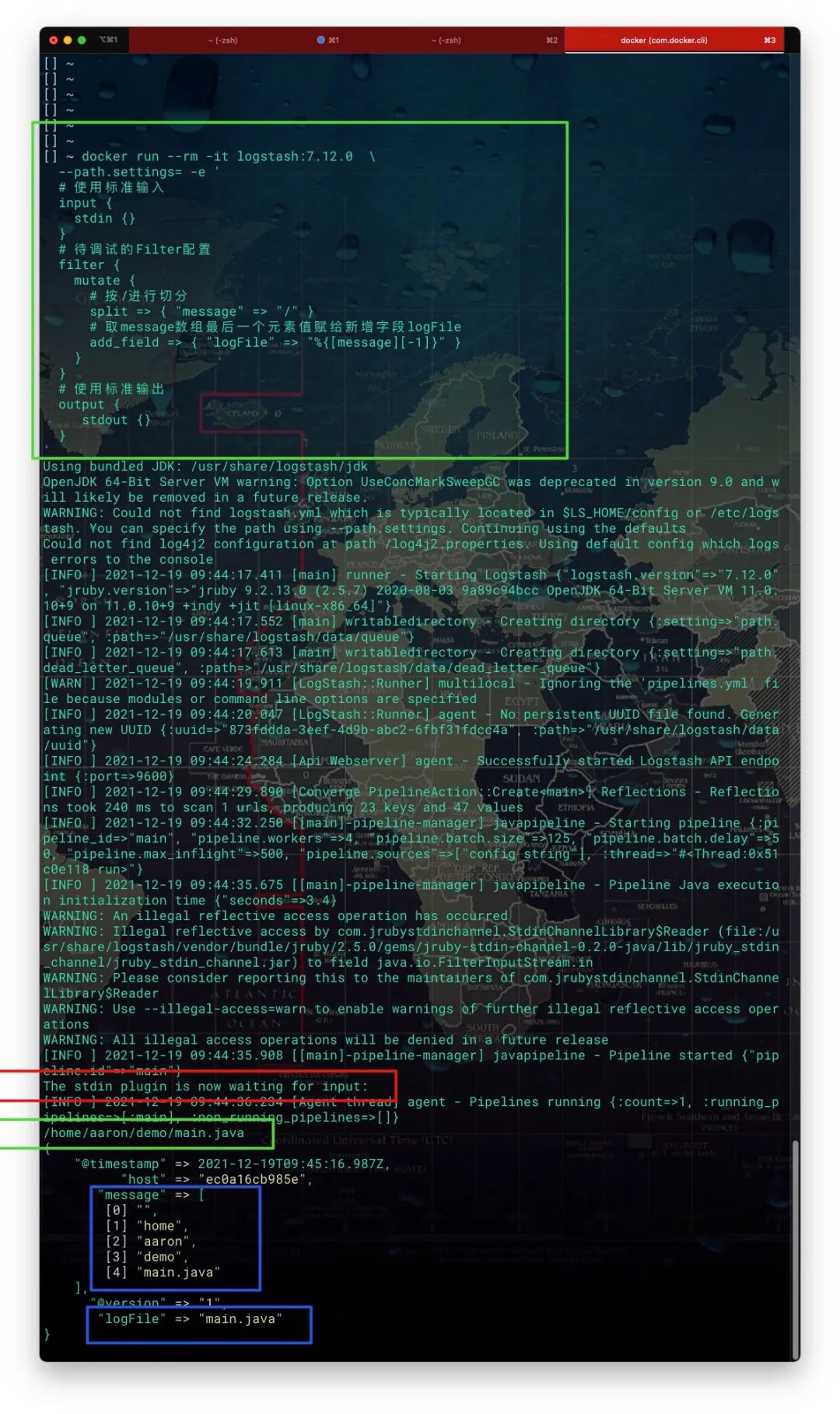
对于Logstash DSL中的Filter Plugin,可通过创建一个临时的Logstash容器进行调试。具体地,输入、输出分别使用标准输入、标准输出,过滤器则为待调试的Filter DSL。示例如下
docker run --rm -it logstash:7.12.0 \
--path.settings= -e '
# 使用标准输入
input {
stdin {}
}
# 待调试的Filter DSL
filter {
mutate {
# 按/进行切分
split => { "message" => "/" }
# 取message数组最后一个元素值赋给新增字段logFile
add_field => { "logFile" => "%{[message][-1]}" }
}
}
# 使用标准输出
output {
stdout {}
}
'
其中,选项说明如下:
rm:容器退出后自动被删除 it:为容器分配一个伪输入终端,并保持容器的标准输入打开
调试效果如下所示
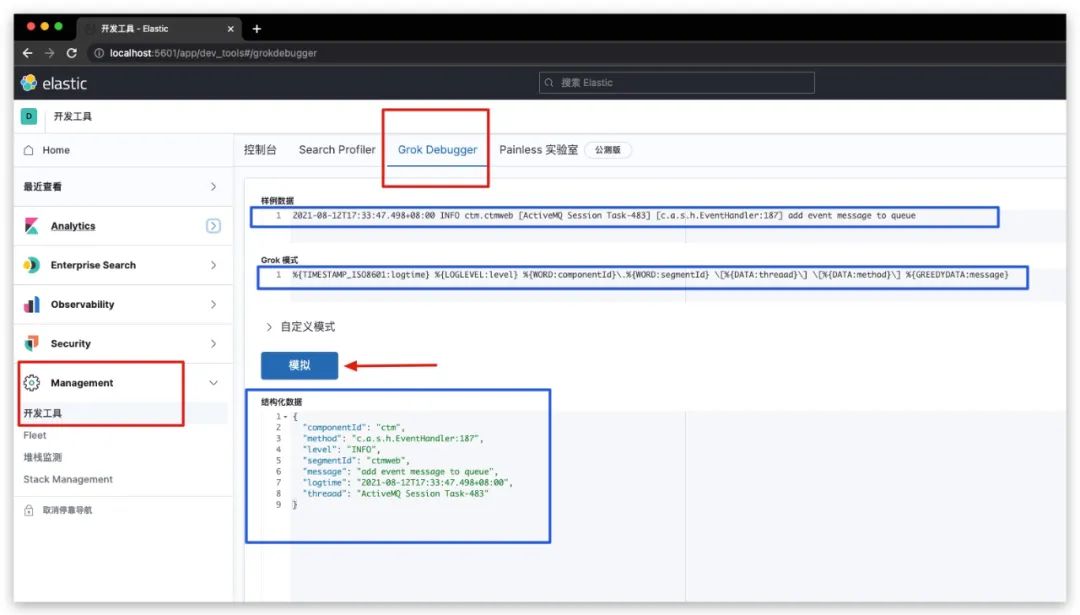
调试Grok
特别地,对于Filter Plugin中的Grok而言,Kibana还专门提供了一个在线调试工具——Grok Debugger。通过【Management】-【开发工具】-【Grok Debugger】进入即可使用,效果如下所示
参考文献
Grok内置模式的正则表达式:https://github.com/logstash-plugins/logstash-patterns-core/blob/main/patterns/legacy/grok-patterns ElasticSearch 7.12版官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.12/index.html Logstash 7.12版官方文档:https://www.elastic.co/guide/en/logstash/7.12/index.html