
爬虫遇到头疼的验证码?Python实战讲解弹窗处理和验证码识别
大家好,欢迎来到 Crossin的编程教室 !
正文开始之前先通知一个福利:
618当当优惠码
可在当当自营图书每满100-50的基础上叠加
满200减40:
VMNBW8
自营图书专享(教材以及特例品除外)

当当小程序、APP均可使用
结算时选择【优惠码】输入 VMNBW8 即可
数量有限,先到先得
有效期:6.15~6.20
(详细使用方法及书单推荐:当当购书优惠叠加码)
前言
在我们写爬虫的过程中,目标网站常见的干扰手段就是设置验证码等,本就将基于Selenium实战讲解如何处理弹窗和验证码,爬取的目标网站为某仪器预约平台

可以看到登录所需的验证码构成比较简单,是彩色的标准数字配合简单的背景干扰
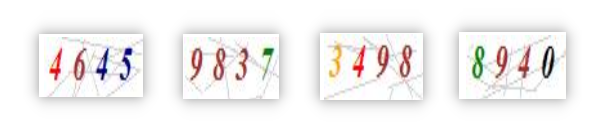
因此这里的验证码识别不需要借助人工智能的手段,可直接利用二值法对图片处理后交给谷歌的识别引擎tesseract-OCR即可获得图中的数字。
注:selenium 和 tesseract 的配置读者可自行搜索,本文不做介绍)
Python实战
首先导入所需模块
import re
# 图片处理
from PIL import Image
# 文字识别
import pytesseract
# 浏览器自动化
from selenium import webdriver
import time解决弹出框问题
先尝试打开示例网站
url = 'http://lims.gzzoc.com/client'
driver = webdriver.Chrome()
driver.get(url)
time.sleep(30)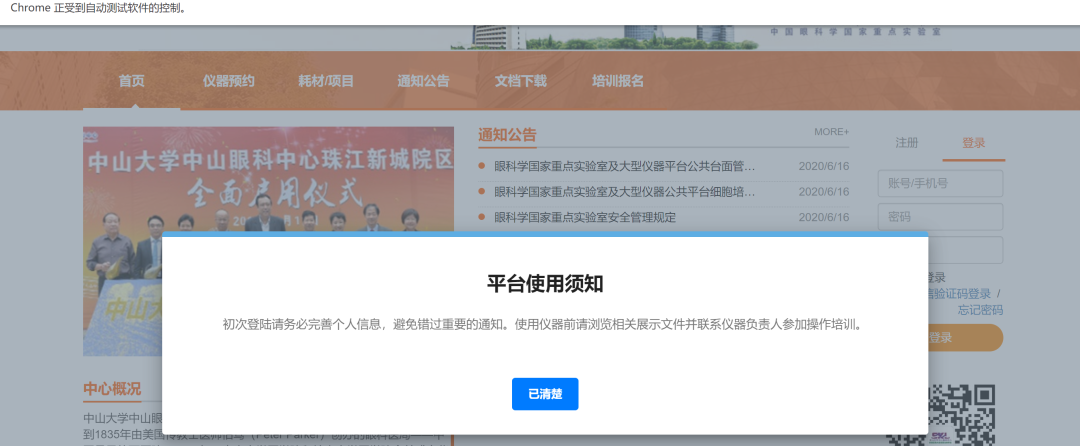
有趣的地方出现了,网站显示了一个我们前面没有看到的弹窗,简单说一下弹窗的知识点,初学者可以将弹出框简单分为alert和非alert
alert式弹出框
alert(message)方法用于显示带有一条指定消息和一个 OK 按钮的警告框confirm(message)方法用于显示一个带有指定消息和 OK 及取消按钮的对话框prompt(text,defaultText)方法用于显示可提示用户进行输入的对话框
看一下这个弹出框的js是怎么写的:
 看起来似乎是alert式弹出框,那么直接用
看起来似乎是alert式弹出框,那么直接用driver.switch_to.alert吗?先不急
非传统alert式弹出框的处理
弹出框位于 div层,跟平常定位方法一样弹出框是嵌套的 iframe层,需要切换iframe弹出框位于嵌套的 handle,需要切换窗口
所以我们对这个弹出框进行元素审查
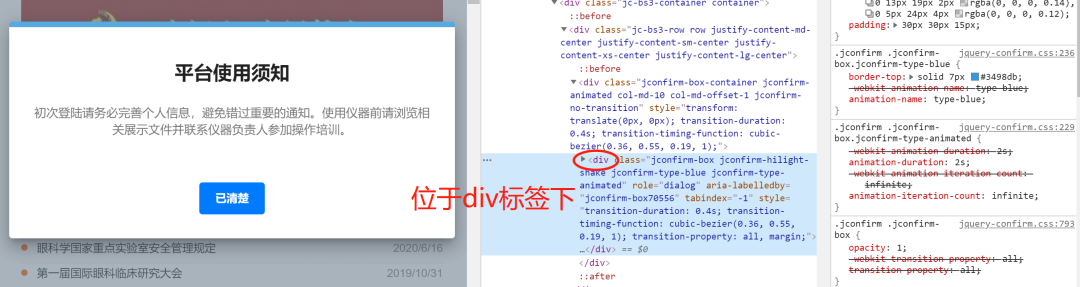
所以问题实际上很简单,直接定位按钮并点击即可
url = 'http://lims.gzzoc.com/client'
driver = webdriver.Chrome()
driver.get(url)
time.sleep(1)
driver.maximize_window() # 最大化窗口
driver.find_element_by_xpath("//div[@class='jconfirm-buttons']/button").click()获取图片位置并截图
二值法处理验证码的简单思路如下:
切割截取验证码所在的图片 转为灰度后二值法将有效信息转为黑,背景和干扰转为白色 处理后的图片交给文字识别引擎 输入返回的结果并提交
切割截取验证码的图片进一步思考解决策略:首先获取网页上图片的css属性,根据size和location算出图片的坐标;然后截屏;最后用这个坐标进一步去处理截屏即可(由于验证码js的特殊性,不能简单获取img的href后下载图片后读取识别,会导致前后不匹配)
img = driver.find_element_by_xpath('//img[@id="valiCode"]')
time.sleep(1)
location = img.location
size = img.size
# left = location['x']
# top = location['y']
# right = left + size['width']
# bottom = top + size['height']
left = 2 * location['x']
top = 2 * location['y']
right = left + 2 * size['width'] - 10
bottom = top + 2 * size['height'] - 10
driver.save_screenshot('valicode.png')
page_snap_obj = Image.open('valicode.png')
image_obj = page_snap_obj.crop((left, top, right, bottom))
image_obj.show()正常情况下直接使用注释的四行代码即可,但不同的电脑不同的浏览器,缩放倍率存在差异,因此如果截取出的图存在偏差这需要考虑乘上倍率系数。最后可以再加减数值进行微调
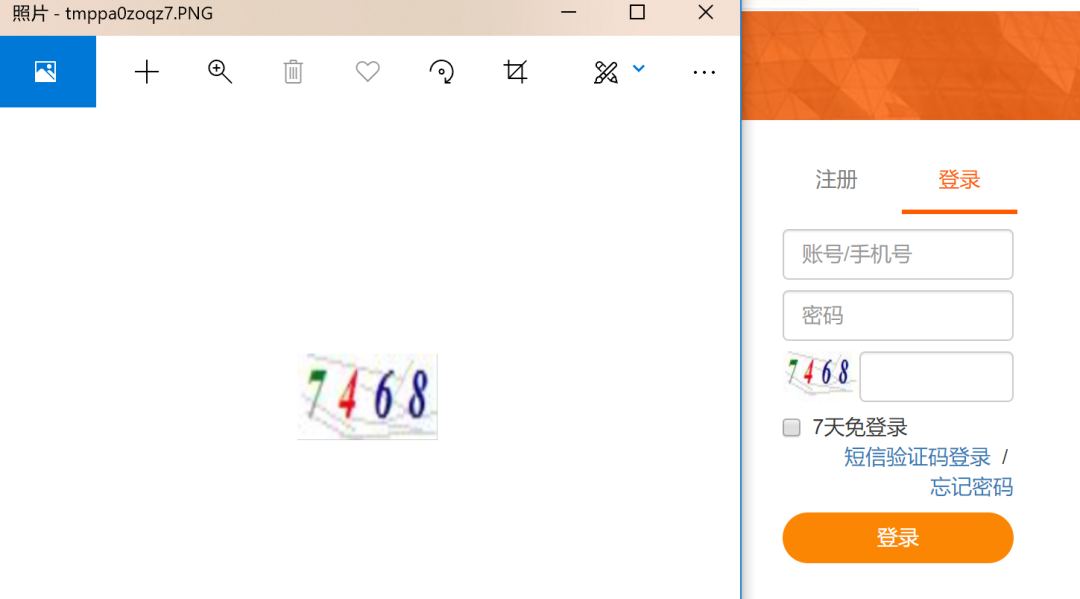
可以看到图片这成功截取出来了!
验证码图片的进一步处理
这个阈值需要具体用Photoshop或者其他工具尝试,即找到一个像素阈值能够将灰度图片中真实数据和背景干扰分开,本例经测试阈值为205
img = image_obj.convert("L") # 转灰度图
pixdata = img.load()
w, h = img.size
threshold = 205
# 遍历所有像素,大于阈值的为黑色
for y in range(h):
for x in range(w):
if pixdata[x, y] < threshold:
pixdata[x, y] = 0
else:
pixdata[x, y] = 255根据像素二值结果重新生成图片
data = img.getdata()
w, h = img.size
black_point = 0
for x in range(1, w - 1):
for y in range(1, h - 1):
mid_pixel = data[w * y + x]
if mid_pixel < 50:
top_pixel = data[w * (y - 1) + x]
left_pixel = data[w * y + (x - 1)]
down_pixel = data[w * (y + 1) + x]
right_pixel = data[w * y + (x + 1)]
if top_pixel < 10:
black_point += 1
if left_pixel < 10:
black_point += 1
if down_pixel < 10:
black_point += 1
if right_pixel < 10:
black_point += 1
if black_point < 1:
img.putpixel((x, y), 255)
black_point = 0
img.show()图像处理前后对比如下
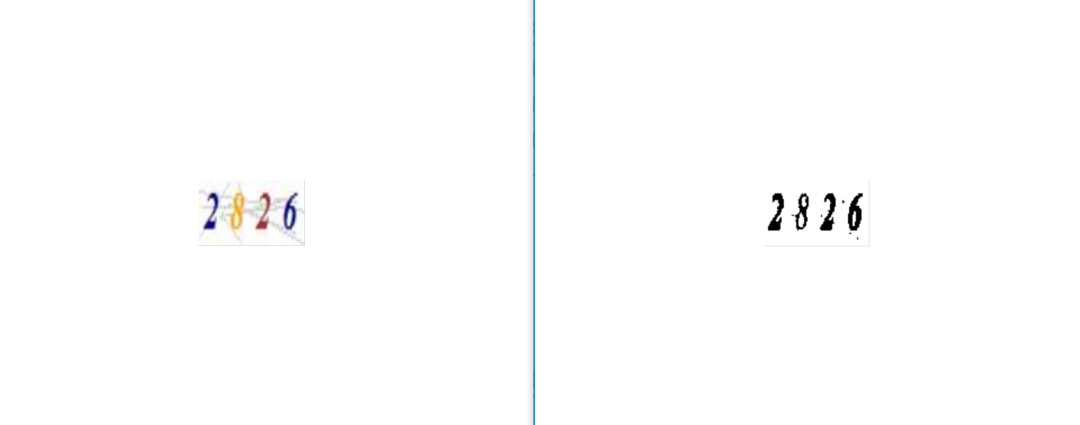
文字识别
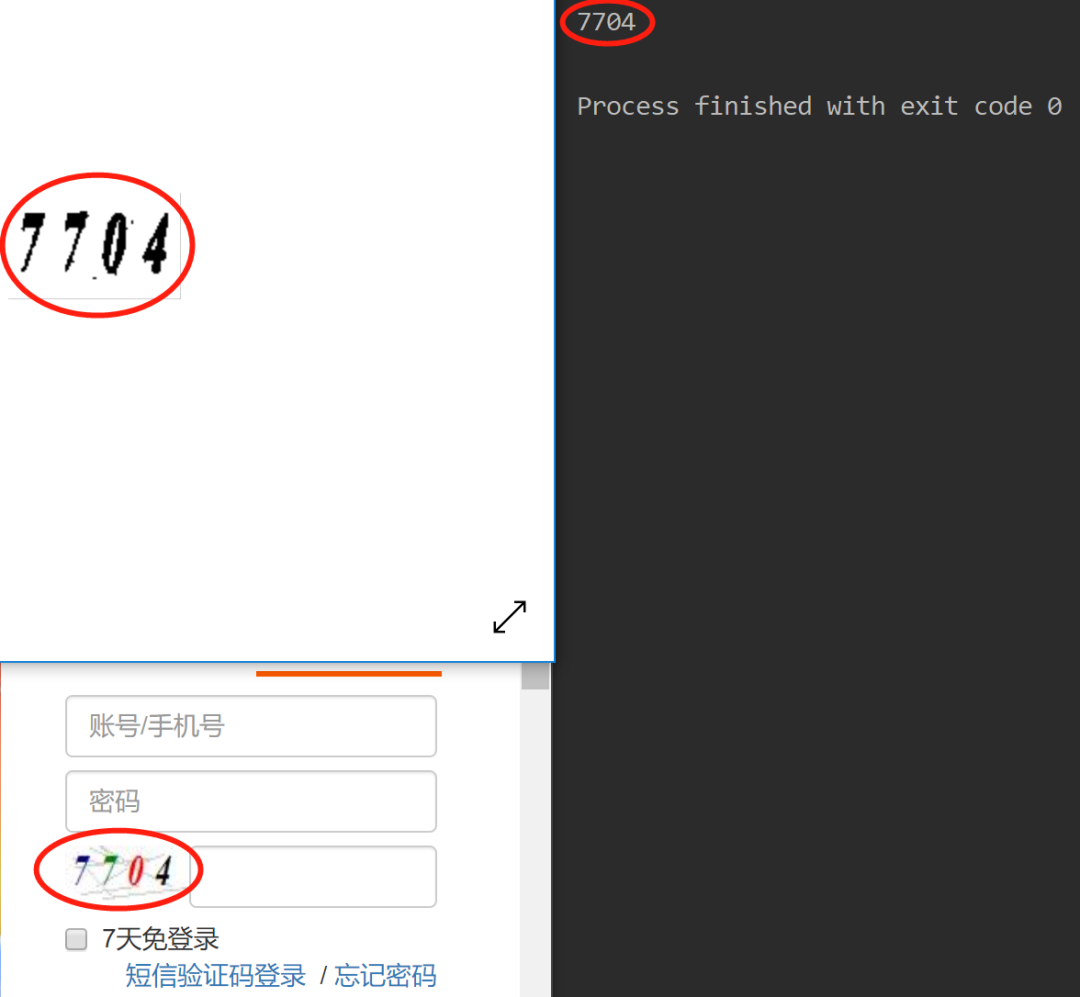
将处理后的图片就给谷歌的文字识别引擎就能完成识别
result = pytesseract.image_to_string(img)
# 可能存在异常符号,用正则提取其中的数字
regex = '\d+'
result = ''.join(re.findall(regex, result))
print(result)识别结果如下
提交账号密码、验证码等信息
在处理完验证码之后,现在我们就可以向网站提交账号密码、验证码等登陆所需信息
driver.find_element_by_name('code').send_keys(result)
driver.find_element_by_name('userName').send_keys('xxx')
driver.find_element_by_name('password').send_keys('xxx')
# 最后点击确定
driver.find_element_by_xpath("//div[@class='form-group login-input'][3]").click()需要注意的是,二值法识别验证码成功率不是100%,因此需要考虑到验证码识别错误,需要单击图片更换验证码重新识别,可以将上述代码拆解成多个函数后,用如下循环框架试错
while True:
try:
...
break
except:
driver.find_element_by_id('valiCode').click()为了方便理解,代码的书写没有以函数形式呈现,欢迎读者自行尝试修改!
小结
成功登录后就可以获得个人的cookies,接下来可以继续用selenium进行浏览器自动化或者把cookies传给requests,后面就能爬取需要的信息做分析或者实现一些自动化功能。爬虫的知识点有很多也很琐碎,我们会在以后的爬虫专题文章中持续分享!
如果文章对你有帮助,欢迎转发/点赞/收藏~
_往期文章推荐_